Arimo利用Alluxio的内存能力提升深度学习模型的结果效率(Time-to-Result)
深度学习算法通常被一些具体应用所采用,其中比较显著的应用领域包括计算机视觉、机器翻译、文本挖掘、欺诈检测等。深度学习的方法在大模型加大数据的场景下效果显著。与此同时,被设计用来处理大数据的分布式计算平台(如Spark)也日益应用广泛。因此,通过在Spark平台上开发深度学习计算框架,深度学习的应用领域可以变得更加广泛,企业完全可以在已有的Spark基础设施上使用深度学习。
1.利用Alluxio协处理器进行基于Spark的分布式深度学习
在2015 Strata + Hadoop World NYC上,我们发布了有史以来第一个可扩展的、基于Spark和Alluxio的分布式深度学习框架,我们把它称为Alluxio协处理器(Co-Processor on Alluxio(“Co-Proccessor”))。它包含了前馈神经网络,卷积神经网络(CNN)以及循环神经网络(RNN)的实现。协处理器为Alluxio增加了一定的计算功能。具体来说,其运行一个本地进程监控衍生的目录并且收集它们。该设计思路是不仅将Alluxio用作Spark的workers之间的常用存储层,还将其用作一个模型更新者以支持大模型的训练。通过Alluxio的分布式内存执行模型,该协处理器框架为单机无法处理的巨大模型提供了一种可扩展的处理方式。
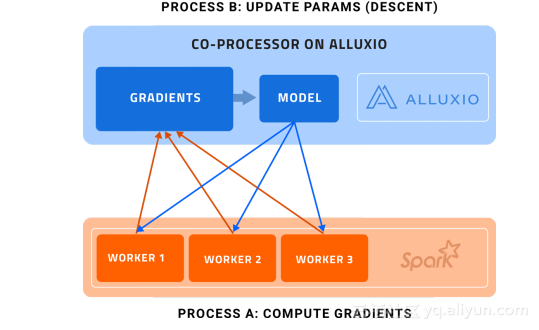
图1. Alluxio架构上的协处理器
进程A(计算梯度):Spark的workers计算梯度,处理数据的并行划分
进程B(更新参数):Alluxio执行(梯度)下降操作,更新主模型
每个Spark的worker都只处理一批训练数据中的一部分,计算梯度,并发送回协处理器上的参数服务器。参数服务器不仅仅收集梯度信息,同时会作为一个协处理器执行(梯度)下降操作,然后更新存储在Alluxio上的模型(进程B)。值得注意的是,进程A和B基本上是异步发生的。
这样的设计让我们避免了:
- 将聚合梯度发送回Spark的workers
- 将更新过的模型发送给wokers,因为Spark workers现在能够直接访问Alluxio上的更新过的模型了。
这种方案的结果是,通过减少Spark workers和参数服务器的通信开销,能够将模型训练过程显著地加速60%。
2.持续开发
火热的开源深度学习框架如Tensorflow自身具有一套分布式模型训练体系架构,通常使用一个GPU集群来对训练数据的不同部分同时计算梯度。然而,这些训练框架对大规模数据集做ETL的能力还非常有限。
一个方法是使用Spark预处理数据为Tensorflow服务器所用。然而,这样做的缺点是会导致很低的生产率。
问题1:训练数据生成过程中的瓶颈
在Arimo,我们每天都跟大规模时间序列数据打交道。大规模数据和复杂的学习问题通常涉及密集的、耗时的ETL处理,而时间序列数据又尤其富于挑战性。这种类型数据的建模要求:(1)随着时间生成大量的子序列和它们关联的标签 (2)将子序列重塑为多维张量。
现有的做法是运行一个长时间的Spark批处理作业将原始数据完全转化为合适的、可进行深度学习训练的形式。一个长时间的批处理作业对我们的流水线式的生产并不是最优的,因为我们需要等到所有数据划分在被发送去训练之前都处理完毕。一个更加理想的模式是立即将已经完整的数据分区流传输到训练阶段。
问题2:训练数据迁移过程中的瓶颈
为了将训练数据在Spark和Tensorflow之间移动,我们通常需要将整个处理后的数据集合持久化到HDFS或者其他分布式文件系统中。这就不可避免地在写数据和读数据中制造了两次磁盘IO瓶颈。以时间序列建模来说,这个问题在训练数据达原始数据的数十倍之大时是极其严重的。
问题3:训练数据过程中的巨大浪费
一个有趣且重要的现象是,我们实际上不需要一次性拿到100%的训练数据才能训练出更好的模型。这意味着首先生成整个训练数据然后再进行批处理的方法极为浪费。这个想法促使我们放弃批处理方法,转而采用一种更加高效的流式方法。
3.解决方案:采用协处理器并发生成小批次训练数据流并从Spark向Tensorflow进行传递
通过避免磁盘IO和利用以内存为中心的共享文件系统Alluxio的优势,我们可以将数据从Spark向Tensorflow服务器之间更快地移动。让我们看下图:
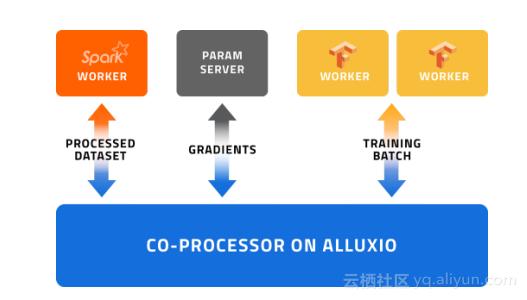
1.利用协同处理,子序列和标签的准备在数据帧创建后可以马上开始进行。所以当我们执行其它无关操作的时候,这部分训练数据就已经悄悄地被准备好并按序排好,等待后续模型训练的使用。
2.Alluxio的内存级速度存储缓解了我们将训练数据持久化到HDFS的需要,从而减少了磁盘IO。
这个方法性能高、优雅且非常有效。浪费得到了最小化,甚至通过协处理器可以得到消除。我们在后台悄悄地生成批数据,然后训练模型不断消耗已经排序好的批次数据,直到模型效果令人满意为止。在数据生成和导入(feed)阶段之间,数据总是排好序并且被缓冲的。计算密集型的数据准备阶段只有当模型训练停止的时候才会停止。
流线型和无浪费,这种基于Alluxio的方法就是我们所认为的大规模数据准备和模型训练的“丰田标准”。
4.总结
深度学习模型在当模型很大和在大规模数据集上训练时表现良好。为了加速模型的训练过程,我们已经实现了在Spark和Tensorflow之间作为常用存储层的Alluxio。
我们利用协处理器的内存级存储速度和协处理能力来避免磁盘IO瓶颈,并且为训练数据预处理和整体模型更新实现了并发。初始结果表明,这种方法能够将模型训练过程加速最多60%。
我们期待着将Alluxio用于其它的用例以及产品集成。
版权申明:本文由南京大学顾荣等专家翻译整理自Alluxio公司技术博客,由Alluxio公司授权云栖社区及CSDN首发(联合),版权归Alluxio公司所有,未经版权所有者同意请勿转载。
Arimo利用Alluxio的内存能力提升深度学习模型的结果效率(Time-to-Result)相关推荐
- 提升深度学习模型性能及网络调参
提升深度学习模型性能及网络调参 https://www.toutiao.com/a6637086018950398472/ 图像处理与机器视觉 2018-12-25 10:42:00 深度学习有很多的 ...
- 提升深度学习模型的表现,你需要这20个技巧
选自machielearningmastery 机器之心编译 作者:Jason Brownlee 参与:杜夏德.陈晨.吴攀.Terrence.李亚洲 本文原文的作者 Jason Brownlee 是一 ...
- 提升深度学习模型泛化性的方法
一个好的深度学习模型的目标是将训练数据很好地推广到问题领域的任何数据.这使我们可以对模型从未见过的数据进行将来的预测. 首先,当模型泛化性差的时候,我们需要找到其原因,当训练集能够很好地拟合,但是测试 ...
- docker 训练深度学习_利用RGB图像训练MultiModality的深度学习模型进行图像分割
▼更多精彩推荐,请关注我们▼ Dragonfly软件的一个特色功能就是可以让用户自己方便快速地训练深度学习的模型,实现图像分割等工作的智能完成.关于Dragonfly里面深度学习工具和智能分割向导工具 ...
- 如何提升深度学习性能?数据、算法、模型一个都不能少
https://www.toutiao.com/i6635808175893250564/ 2018-12-17 12:04:48 该文来自DataCastle数据城堡(DataCastle2016) ...
- 理解学习率以及如何提升深度学习的性能
https://www.toutiao.com/a6698879109432345100/ 作者:Hafidz Zulkifli编译:ronghuaiyang 导读 把学习率用好,也能提升深度学习模型 ...
- 服务器上训练深度学习模型anaconda+cuda+cudnn+pycharm
这个最好: centos系统搭建深度学习环境_百度搜索 https://www.baidu.com/s?wd=centos%E7%B3%BB%E7%BB%9F%E6%90%AD%E5%BB%BA%E6 ...
- OpenCV-图像着色(采用DNN模块导入深度学习模型)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 实现原理 图像着色最早是应用在图像修复方面,将一些过去的黑白旧照根据预设色盘上色,得到色彩饱满的 ...
- 深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化
作者 | 车漾(阿里云高级技术专家).顾荣(南京大学 副研究员) 导读:Alluxio 项目诞生于 UC Berkeley AMP 实验室,自开源以来经过 7 年的不断开发迭代,支撑大数据处理场景的数 ...
最新文章
- java 原子量_Java線程:新特征-原子量
- java泛型中的标记,Java泛型中的标记符含义
- 电源模块的9个主要性能指标及其作用
- 趣图:21 副 GIF 动图让你了解各种数学概念
- 梯度消失与梯度爆炸----解决方案(一)
- 使用纯CSS实现圣诞节雪花图案
- 大师兄科研网_挑战杯经验分享会与你话科研
- linux usb拔出防止抖动,Linux 下监控USB设备拔插事件
- Oracle 安装 与 卸载 以及 使用 plsqldev
- oracle sqlldr命令6,oracle sqlldr命令
- IDEA使用教程之创建一个工程(一)
- 金仓数据库KingbaseES之libpq通过服务名连接数据库
- AtCoder Beginner Contest 065(CD)
- Cherno C++ P61 C++的命名空间
- 数据结构(三)—— 树(1):树与树的表示
- Excel怎么将文本格式数值转换为可计算的数值型
- linux统计单拷贝基因家族,基因家族收缩和扩张分析
- Redis在手,跟我走
- gta5怎么设置画质最好_GTA5:如何让你的游戏画质更好,游戏更顺手,一波设置教给大家!...
- 鸿图霸业nbsp;谁与争锋