storm的并发机制与实践
基本概念
- Nodes:服务器,配置了storm集群,有安装nimbus的node,以及安装supervisor的node
- Workers(JVM虚拟机):一个服务器上相互独立运行的JVM进程,一个服务器node可以配置一个或者多个worker,一个topology会分配到一个或者多个worker运行,如下图:
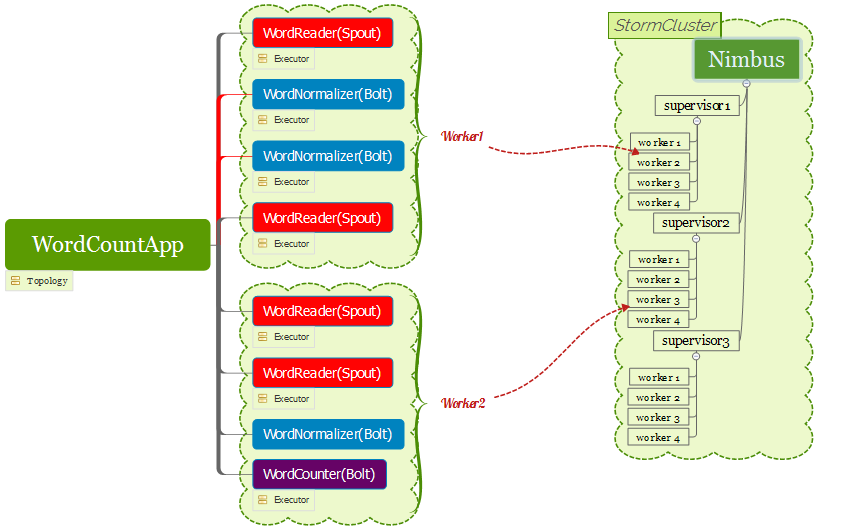
注意:worker只存在于supervisor服务器 - Task:任务,就是spout或bolt的实例,他们的nextTuple方法会被executor线程调用执行
- Executor:一个worker(jvm进程)中的java线程,可以同时执行多个task,默认情况下,并行度设置几,即有几个task,会默认给每个task分配一个executor线程去执行它
单词计数流程如下:

默认配置
默认情况下,storm的并发度为1,以下是单词计数案例的topology执行过程

可以看到在一台服务器上有一个worker(JVM进程),里面跑了4个java线程,每个线程执行一个task实例,一共4个task实例,包括3个bolt和一个spout,即每个任务在这个jvm不同线程中执行,并发为线程级
配置executor和task
增加一个spout以后,图例如下,将会造成2倍的数据流入,产出

设置为1个服务器2个worker(JVM进程)
单词分割bolt配置如下(设置单词分割bolt有两个executor线程来执行4个单词分割实例)
builder.setBolt(SPLIT_BOLT_ID,splitBolt,2).setNumTasks(4).shufferGrouping(SENTENCE_SPOUT_ID);
单词计数bolt配置如下(设置单词计数bolt有4个executor线程来执行4个单词分割实例,分组方式为按字段分组,相同单词进入同一个bolt实例)
builder.setBolt(COUNT_BOLT_ID,countBolt,4).fieldGrouping(SPLIT_BOLT_ID,new Fields("word"));
综合上述图例如下:

数据流分组方式
并发版本单词计数拓扑中,单词分割bolt指定了4个task,数据流分组将决定每个tuple分发到哪个task
storm定义了七种内置数据流分组方式
Shuffle grouping(随机分组):这种方式随机分发tuple到不同bolt实例,每个bolt实例收到相同数量tuple,类似于kafka不同分区消息均衡算法
Fields grouping(按字段分组):根据指定字段的值进行分组,比如单词切割以后发到计数bolt,not如果分发到计数bolt1,则下一个not肯定会分发到计数bolt1而不会到计数bolt2,即not单词只可能存在于bolt1
注意:如果是fieldgrouping一共有3种句子,大批量发送,然后有3个bolt实例分割,不一定绝对是每个bolt实例每一种句子,还是可能出现一个休息的bolt,另外两个里面一个有2种句子,一个一种
Fields grouping(按字段分组):根据指定字段的值进行分组,比如单词切割以后发到计数bolt,not如果分发到计数bolt1,则下一个not肯定会分发到计数bolt1而不会到计数bolt2,即not单词只可能存在于bolt1
Globle grouping(全局分组):这种分组方式会将所有的tuple都流入到同一个bolt实例,至于这个bolt实例到底选取哪个,storm将根据最小的task ID来选取接收数据的task(bolt示例)
注意:由上面的理论可以知道,当使用全局分组的时候,设置bolt实例的并发度是没有意义的,因为所有的tuple都会流入同一个bolt实例,当然这也将导致问题:所有的tuple流入一个JVM实例,导致storm集群中某个jvm或者服务器出现性能瓶颈、故障、甚至挂掉
Local or shuffle grouping(本地或随机分组):类似于随机分组。如果当前worker(JVM进程)中有下一个流入的bolt,则当前bolt会将tuple分发给同一个服务器上的同一个worker(JVM进程)中的下一个bolt实例,如果没有,则和随机分组结果相同。这种分组方式key减少网络传输,进而提高拓扑性能
All grouping(全复制分组)
None grouping(不分组)
Direct grouping(指向型分组)
分组实践
实践:查看如果采用随机分组会对单词计数结果造成差错(对比随机分组和按字段分组),仍然针对单词计数案例:spout和其他bolt全部都并行度1,wordcountbolt单词计数bolt并行度3,因为只有并行度>1,分组实践才有意义
测试句子:
private String[] sentences={"my dog has fleas","i like cold beverages","do not always play games","i do not like fleas","do you know his name"};
计数bolt代码:
/*** tuple:word,count*/
@Slf4j
public class WordCountBolt extends BaseRichBolt {private OutputCollector collector;private HashMap<String,Long> countMap = null;/*** 实例化一个hashmap实例,用来存储单词和对应计数* 大部分实例变量通常是在prepare()中进行实例化,这个设计模式是由topology部署方式决定的* 当topology发布时,所有的bolt和spout组件首先会进行序列化,然后通过网络发送到集群中,如果spout或者bolt在序列化之前(如构造函数中生成)实例化了* 任何无法序列化的实例变量,在进行序列化时会抛出notSerializableException异常,topology就会部署失败,本例中,hashmap是可序列化的,因此在构造函* 数中进行实例化也是安全的,但是:通常情况下最好在构造函数中对基本数据类型和可序列化对象进行赋值和实例化,在prepare方法中对不可序列化对象实例化* @param map* @param topologyContext* @param outputCollector*/public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {this.collector = outputCollector;this.countMap = new HashMap<String, Long>();System.out.println("wordCountBolt 的prepare()方法的taskId"+topologyContext.getThisTaskId()+"对象引用地址:"+this);}/*** 将单词和单词计数作为一个tuple发射到后面* @param tuple*/public void execute(Tuple tuple) {String word=tuple.getStringByField("word");Long count=this.countMap.get(word);if(count==null){count=0L;}count++;this.countMap.put(word,count);printReport();this.collector.emit(new Values(word,count));}private void printReport(){log.info("--------------------------begin-------------------");Set<String> words = countMap.keySet();for(String word : words){log.info("@word-count-bolt@: " + word + " ---> " + countMap.get(word));}log.info("--------------------------end---------------------");}public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {outputFieldsDeclarer.declare(new Fields("word","count"));}
}- 随机分组 Shuffle grouping 拓扑代码如下:
public class WordCountTopology {private static final String SENTENCE_SPOUT_ID="sentence-spout";private static final String SPLIT_BOLT_ID="split-bolt";private static final String COUNT_BOLT_ID="count-bolt";private static final String REPORT_BOLT_ID="report-bolt";private static final String TOPOLOGY_NAME="word-count-topology";public static void main(String[] args) throws InterruptedException {TopologyBuilder builder=new TopologyBuilder();builder.setSpout(SENTENCE_SPOUT_ID,new SentenceSpout());builder.setBolt(SPLIT_BOLT_ID,new SplitSentenceBolt()).shuffleGrouping(SENTENCE_SPOUT_ID);builder.setBolt(COUNT_BOLT_ID,new WordCountBolt(),3).shuffleGrouping(SPLIT_BOLT_ID);builder.setBolt(REPORT_BOLT_ID,new ReportBolt(),1).globalGrouping(COUNT_BOLT_ID);Config config = new Config();LocalCluster cluster = new LocalCluster();cluster.submitTopology(TOPOLOGY_NAME,config, builder.createTopology());Thread.sleep(TimeUnit.SECONDS.toMillis(20));cluster.killTopology(TOPOLOGY_NAME);cluster.shutdown();}
}取消在reportBolt打印,在wordcount打印,看看是不是出现了多实例拥有相同单词,不同个数
单词计数bolt打印结果如下:
可以看到不同单词出现在了不同的计数bolt实例中,且数量不同,这样将导致在下一步发送到打印bolt的时候,出现覆盖,比如一个单词计数实例是线程2计数单词do,还有一个单词计数实例是线程4计数do,将出现一起发送到printBolt的时候,线程2控制执行的单词计数实例的do的1次覆盖线程4执行的单词计数实例的do的2次,导致最终对do出现计数1次的结果
- 按字段分组 Fields grouping 拓扑代码如下:
public static void main(String[] args) throws InterruptedException {TopologyBuilder builder=new TopologyBuilder();builder.setSpout(SENTENCE_SPOUT_ID,new SentenceSpout());builder.setBolt(SPLIT_BOLT_ID,new SplitSentenceBolt()).shuffleGrouping(SENTENCE_SPOUT_ID);builder.setBolt(COUNT_BOLT_ID,new WordCountBolt(),3).fieldsGrouping(SPLIT_BOLT_ID,new Fields("word"));builder.setBolt(REPORT_BOLT_ID,new ReportBolt(),1).globalGrouping(COUNT_BOLT_ID);Config config = new Config();LocalCluster cluster = new LocalCluster();cluster.submitTopology(TOPOLOGY_NAME,config, builder.createTopology());Thread.sleep(TimeUnit.SECONDS.toMillis(20));cluster.killTopology(TOPOLOGY_NAME);cluster.shutdown();}
单词计数bolt打印结果如下:

可以看到单词计数准确,并没有出现同一个单词出现在不同单词计数bolt实例中
参考文章:
1、http://www.tianshouzhi.com/api/tutorials/storm/15
storm的并发机制与实践相关推荐
- Storm 05_Storm并发机制通信机制
一.Storm并发机制 Worker processes Executors (threads) Tasks Worker – 进程 一个Topology拓扑会包含一个或多个Worker(每个Work ...
- Storm程序的并发机制原理总结
文章目录 目录 前言: 1.概念 2.配置并行度 总结: 目录 前言: 为了在以后的实践中提高Storm程序执行的效率,我们还是有必要了解下对应的Storm程序的并发机制.(哈哈,虽然以博主小菜鸟的水 ...
- 用实例的方式去理解storm的并发度
什么是storm的并发度 一个topology(拓扑)在storm集群上最总是以executor和task的形式运行在suppervisor管理的worker节点上.而worker进程都是运行在jvm ...
- Strom程序的并发机制,配置并行度(代码实现)、动态改变并行度,local or shuffle分组,分组的概念以及分组类型
1.Storm程序的并发机制 1.1.概念 Workers (JVMs): 在一个物理节点上可以运行一个或多个独立的JVM 进程.一个Topology可以包含一个或多个worker(并行的跑在不同 ...
- storm消息可靠机制(ack)的原理和使用
关于storm的基础,参照我这篇文章:流式计算storm 关于并发和并行,参照我这篇文章:并发和并行 关于storm的并行度解释,参照我这篇文章:storm的并行度解释 关于storm的流分组策略,参 ...
- 阿提拉公司 java_Atitit 文件上传 架构设计 实现机制 解决方案 实践java php c#.net js javascript c++ python...
Atitit 文件上传 架构设计 实现机制 解决方案 实践 java php c#.net js javascript c++ python 1 . 上传的几点要求 2 1 .1. 本地预览 2 1 ...
- Java并发机制的底层实现原理
Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和CPU的指令.本章我们将 ...
- Java高并发编程(二):Java并发机制的底层实现机制
Java代码在编译后会变成Java字节码,字节码在之后被类加载机制加载到JVM中,JVM执行字节码,最终需要转换为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和CPU的指令. ...
- Java并发机制底层实现原理-volatile
章节目录 volatile的实现原理与应用 1.volatile的实现原理与应用 Java source code->Java class->JVM->汇编指令->cpu执行 ...
最新文章
- 科大星云诗社动态20211212
- C++将带ui界面的qt工程封装为动态库dll
- 64位 linux 32位连接器,意法半导体为 32 位微控制器发布了一款自由的 Linux 集成开发环境...
- 说说基于网络的五种IO模型
- 网络基础---IP编址
- CSS3/ 弹性布局flex
- java jsch 调用shell_Java-Jsch-Shell脚本执行后退出
- 小白知识摘录__环境变量
- ASP.NET组件与开发之复合控件的事件处理
- myBatis + SpringMVC上传、下载文件
- 设计模式之单实例模式(Singleton)
- 图解微服务技术架构体系
- ghostscript的坑
- 【FastDFS】分布式文件系统FastDFS之FastDHT文件去重
- 代理软件使用拨号不可用,使用wifi正常使用 解决 win10
- 柯特斯公式的matlab代码,牛顿-柯特斯公式C语言的实现.pdf
- 人机智能交互技术教学进度表(2017-2018-1)含测试 机器人方向本科限选课程
- python画公主_【图片】来几张公主的手绘【勇敢的公主吧】_百度贴吧
- python 画三角函数_Python计算三角函数之asin()方法的使用
- solidity 入门