【学习周报】注意力机制的工作原理和主流方法。
学习目标
- 深度学习Attention模型
- 深度学习花书第16章
学习内容
- Attention模型和机制、基本思想。
- 花书结构化概率模型
学习时间
- 9.5 ~ 9.10
深度学习Attention模型
引言
近年来,注意力模型在深度学习的各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理等各种不同类型的任务中,都扮演着重要的角色。
人类的视觉注意力
从命名方式不难看出,注意力模型这一命名的由来借鉴了人类的注意力机制,首先简单介绍一下人类视觉的选择性注意力机制。
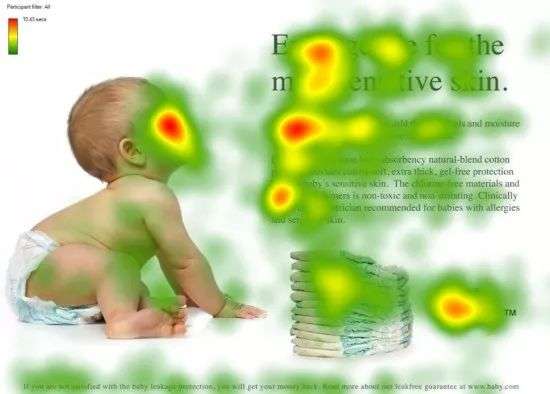
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描图像的全局来获得需要重点关注的目标区域,然后对这些区域投入更多的注意力资源以关注到目标的细节信息,而抑制其它无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类的视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
上图展示了人类在看到一幅图像时是如何分配注意力资源的,其中红色区域表示视觉系统更关注的目标,对于图片所示的场景,人们会把更多的注意力投入到婴儿的脸部、文本的标题以及文章举句首等。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
Encoder-Decoder框架
目前为止,大多数注意力模型依附于Encoder-Decoder框架,而事实上,注意力模型可以看作是一种通用的思想,它本身并不依赖于特定的框架。
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景非常广泛。下图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
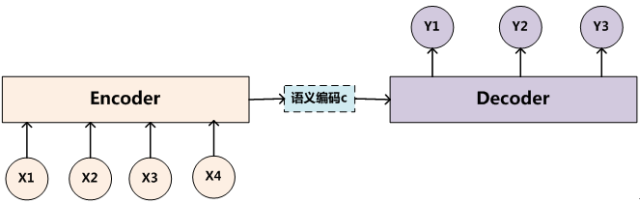
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。
对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
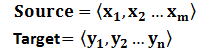
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
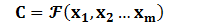
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息 y1,y2......yi−1y_1,y_2......y_{i-1}y1,y2......yi−1 来生成i时刻要生成的单词 yiy_iyi :
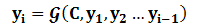
每个yiy_iyi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域Encoder-Decoder的应用领域相当广泛。
另外,Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
Attention模型
上一小节展示的框架并没有体现出“注意力机制”,所以可以把它看作是注意力不集中的分心模型,原因如下:
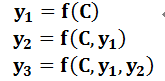
其中 fff 是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。
而语义编码C是由句子Source的每个单词经过Encoder编码产生的,这意味着不论是生成哪个单词,y1,y2y_1,y_2y1,y2 还是 y3y_3y3,其实句子Source中任意单词对生成某个目标单词 yiy_iyi 来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2) (Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词 yiy_iyi 的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的 CiC_iCi 。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的 CiC_iCi 。增加了注意力模型的Encoder-Decoder框架理解起来如下图所示。
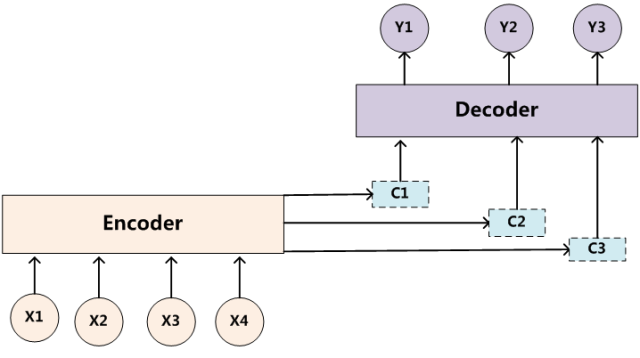
生成目标句子单词的过程成了下面的形式:
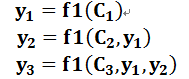
而每个CiC_iCi可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

其中,f2f_2f2 函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,f2f_2f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;ggg 代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,ggg 函数就是对构成元素加权求和,即下列公式:
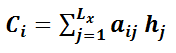
其中,LxL_xLx 代表输入句子Source的长度,aija_{ij}aij 代表在Target输出第i个单词时Source输入句子中第 jjj 个单词的注意力分配系数,而 hjh_jhj 则是Source输入句子中第j个单词的语义编码。假设下标 iii 就是上面例子所说的“ 汤姆” ,那么 LxL_xLx 就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)h_1=f(“Tom”),h_2=f(“Chase”),h_3=f(“Jerry”)h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”) 分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是 0.6,0.2,0.2,所以 ggg 函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示 CiC_iCi 的形成过程如下:
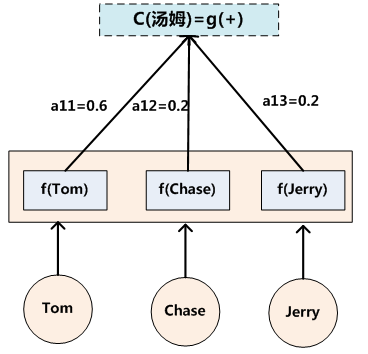
另一个问题是:生成目标句子的某个单词,比如“汤姆”的时候,如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
为了便于说明,我们假设对非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则框架转换为下图所示:
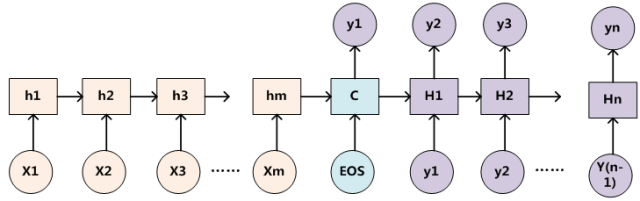
那么注意力分配概率分布值的通用计算过程如下:
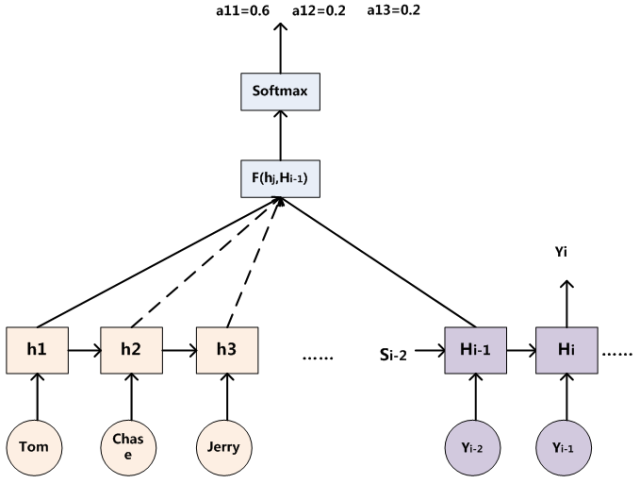
对于采用RNN的Decoder来说,在时刻 iii,如果要生成 YiY_iYi 单词,我们可以知道Target在生成 YiY_iYi 之前的时刻 i−1i-1i−1 时,隐层节点 i−1i-1i−1 时刻的输出值 Hi−1H_{i-1}Hi−1 ,而我们的目的是要计算生成 YiY_iYi 时输入句子中的单词“Tom”、“Chase”、“Jerry”对 YiY_iYi 来说的注意力分配概率分布,那么可以用Target输出句子 i−1i-1i−1 时刻的隐层节点状态 Hi−1H_{i-1}Hi−1 去和输入句子Source中每个单词对应的RNN隐层节点状态 hjh_jhj 进行对比,即通过函数 F(hj,Hi−1)F(h_j,H_{i-1})F(hj,Hi−1) 来获得目标单词 YiY_iYi 和每个输入单词对应的对齐可能性,这个 FFF 函数在不同论文里可能会采取不同的方法,然后函数 FFF 的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
绝大多数Attention模型都是采取上述的计算框架来计算注意力分配概率分布信息,区别只是在 FFF 的定义上可能有所不同。
Attention机制的本质思想
如果把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。
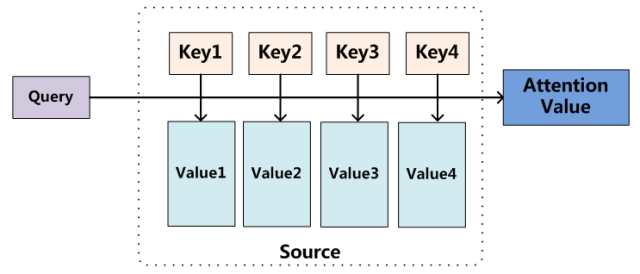
我们可以这样来看待Attention机制:将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可将其本质思想改写为如下公式:
Attention(Query,Source)=∑i=1LxSimilarity(Query,Keyi)∗ValueiAttention(Query,Source)=\sum_{i=1}^{L_x}Similarity(Query,Key_i)*Value_iAttention(Query,Source)=∑i=1LxSimilarity(Query,Keyi)∗Valuei
其中 LxL_xLx 代表 Source 的长度。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
也可以将Attention机制看作一种软寻址(Soft Addressing): Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。所以不少研究人员将Attention机制看作软寻址的一种特例,这也是非常有道理的。
Attention机制的具体计算过程,可以将其归纳为两部分:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为下图展示的三个阶段:
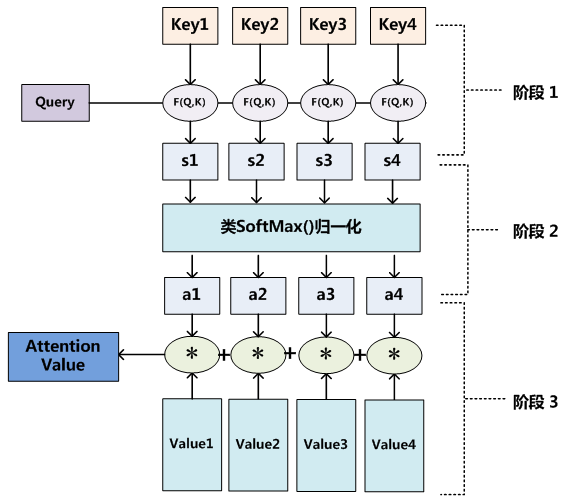
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个KeyiKey_iKeyi,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
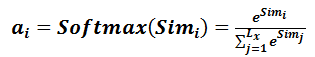
第二阶段的计算结果 $a_i$ 即为 $value_i$ 对应的权重系数,然后进行加权求和即可得到Attention数值:

通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
softmax 的 python3 实现(一维向量):
import numpy as npdef softmax(x):"""Compute softmax values for each sets of scores in x."""e_x = np.exp(x - np.max(x))return e_x / e_x.sum()
#test example
scores = [3.0, 1.0, 0.2]
print(softmax(scores))[ 0.8360188 0.11314284 0.05083836]
Self Attention模型
Self Attention也经常被称为intra Attention(内部Attention),最近几年也获得了比较广泛的使用,比如Google最新的机器翻译模型内部大量采用了Self Attention模型。
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的。比如对于“英-中”机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。而Self Attention指的并不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化。
如果是常规的Target不等于Source情形下的注意力计算,本质上是目标语单词和源语单词之间的一种单词对齐机制。如果是Self Attention机制,就需要弄明白通过Self Attention到底学到了哪些规律或者抽取出了哪些特征,或者说引入Self Attention有什么增益或者好处。以机器翻译中的Self Attention来说明,图a、图b可视化表示Self Attention在同一个英语句子内单词间产生的联系。

图a

图b
从上两张图可以看出,Self Attention可以捕获同一个句子中单词之间的一些句法特征(比如图a 展示的有一定距离的短语结构)或者语义特征(比如图b 展示的its的指代对象Law)。
很明显,引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序进行序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。
Attention机制的应用
Attention机制在深度学习的各种应用领域都有广泛的使用场景。除了上文的自然语言处理领域中机器翻译任务外,下面分别从图像处理领域和语音识别选择典型应用实例来对其应用做简单说明。
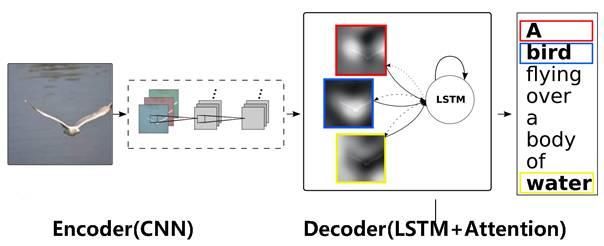
图c 图片描述任务的Encoder-Decoder框架
图片描述(Image-Caption) 是一种典型的图文结合的深度学习应用,输入一张图片,人工智能系统输出一句描述句子,语义等价地描述图片所示内容。很明显这种应用场景也可以使用Encoder-Decoder框架来解决任务目标,此时Encoder输入部分是一张图片,一般会用CNN来对图片进行特征抽取,Decoder部分使用RNN或者LSTM来输出自然语言句子(参考图c)。
此时如果加入Attention机制能够明显改善系统输出效果,Attention模型在这里起到了类似人类视觉选择性注意的机制,在输出某个实体单词的时候会将注意力焦点聚焦在图片中相应的区域上。图d 给出了根据给定图片生成句子“A person is standing on a beach with a surfboard.”过程时每个单词对应图片中的注意力聚焦区域。

图d 图片生成句子中每个单词时的注意力聚焦区域
图e 给出了另外四个例子形象地展示了这种过程,每个例子上方左侧是输入的原图,下方句子是人工智能系统自动产生的描述语句,上方右侧图展示了当AI系统产生语句中划横线单词的时候,对应图片中聚焦的位置区域。比如当输出单词dog的时候,AI系统会将注意力更多地分配给图片中小狗对应的位置。

图e 图像描述任务中Attention机制的聚焦作用
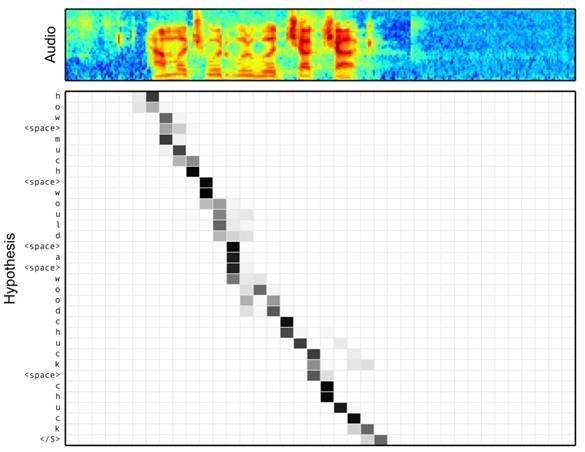
图f 语音识别中音频序列和输出字符之间的Attention
语音识别的任务目标是将语音流信号转换成文字,所以也是Encoder-Decoder的典型应用场景。Encoder部分的Source输入是语音流信号,Decoder部分输出语音对应的字符串流。
图f 可视化地展示了在Encoder-Decoder框架中加入Attention机制后,当用户用语音说句子 how much would a woodchuck chuck 时,输入部分的声音特征信号和输出字符之间的注意力分配概率分布情况,颜色越深代表分配到的注意力概率越高。从图中可以看出,在这个场景下,Attention机制起到了将输出字符和输入语音信号进行对齐的功能。
总结
上述内容仅仅选取了不同AI领域的几个典型Attention机制应用实例,Encoder-Decoder加Attention架构由于其卓越的实际效果,目前在深度学习领域里得到了广泛的使用,了解并熟练使用这一架构对于解决实际问题会有极大帮助。
花书学习笔记
结构化概率模型——深度学习第十六章
结构化概率模型(Structured Probabilistic model) 就是利用图论(graph theory) 中的图来表示概率分布中相互之间作用的随机变量的关系。深度学习经常面对的问题是如何理解具有丰富结构的高维数据的问题,例如图片、语音、文本等等。除了经典的分类问题如图像识别、语音识别等,有的时候我们还要处理比分类更复杂的任务,如分布密度估计(density estimation) ,降噪(denoising),填补损失数据(missing value imputation),取样(sampling) 等等。我们无法仅仅用一个大型的查找表(look-up table)来处理这些问题,例如假如我们要模拟具有n个元素每个元素可以取k个不同值的随机向量 x⃗\vec{x}x 的分布,我们如果采用查找表就需要 knk^nkn 个参数,我们需要很大的存储空间,需要海量的数据才能防止过拟合,而且预测或者取样的时间也会很长。
使用大型查找表的问题在于我们要模拟所有变量之间的相互关系,但实际问题中常常只有某些变量和其他变量发生直接作用,而图(graph)就可以很好的表示随机变量之间的作用关系,其中每个节点(node)代表了一个随机变量,而每条边(edge)代表了两个随机变量之间有直接作用,而连接不相邻节点的路径(path)就代表了简介相互作用。图可以分为两种:有向图(directed graph) 和无向图(undirected graph)。
有向图又被称作信念网络(belief network) 或者贝叶斯网络(bayesian network),图中的边是有方向的,即从一个节点指向另一个节点,其方向代表了条件概率分布,例如从a指向b的边代表了b的概率分布依赖于a的值。一个简单的有向图如下图所示:
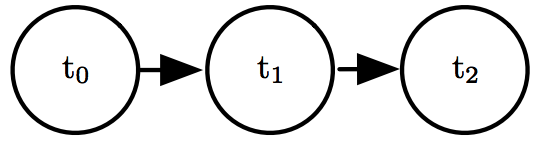
上图对应的概率分布可以表示为 p(t0,t1,t2)=p(t0)p(t1∣t0)p(t2∣t1)p(t_0,t_1,t_2)=p(t_0)p(t_1|t_0)p(t_2|t_1)p(t0,t1,t2)=p(t0)p(t1∣t0)p(t2∣t1) ,一般的图的概率分布可通用 p(x)=∏ip(xi∣PaG(xi))p(x)=\prod_ip(x_i|Pa_{G}(x_i))p(x)=∏ip(xi∣PaG(xi)) 来表示,其中 PaG(xi)Pa_{G}(x_i)PaG(xi) 代表了图G中节点 xix_ixi 的所有父节点即指向它的节点。和查找表方法相比较,假如条件概率最多出现m个变量,则有向图复杂度为 O(km)O(k^m)O(km) ,假如我们设计的模型 m≪nm\ll nm≪n ,则其效率远高于查找表方法。
有向图适用于信息流动方向比较明确的问题,而对于其他因果律不明确的问题,我们需要用无向图来表示,无向图也被叫做马尔科夫随机场(Markowv random fields) 或马尔科夫网络(Markov Network)。在无向图中,边是没有方向的,且不代表条件概率,一个简单的无向图如下图所示:
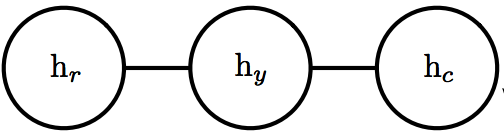
对于无向图,如果一个子集包含的所有点两两之间均相互连接,则这个集合叫做团(clique),简记做 CCC ,用 ϕ(C)\phi (C)ϕ(C) 来表示团 CCC 的所有变量的联合概率分布,则整个图的非归一化的概率分布(unnormalized probability distribution)可表示为 p~(x)=∏C∈Gϕ(C)\tilde{p}(x)=\prod_{C\in G} \phi (C)p~(x)=∏C∈Gϕ(C) ,为了使概率归一化,我们需要引入配分函数(partition function) Z=∫p~(x)dxZ=\int \tilde{p}(x)dxZ=∫p~(x)dx ,归一化后的概率即可表示为 p(x)=1Zp~(x)p(x)=\frac{1}{Z}\tilde{p}(x)p(x)=Z1p~(x) 。由于Z的形式是积分形式,通常很难计算,所以第18章会讲怎样用近似方法求配分函数。
处理具体问题时,常常需要假设对于所有的 xxx , p~(x)>0\tilde{p}(x) > 0p~(x)>0 ,一个可以保证这一条件的模型是基于能量的模型(energy-based model),即 p~(x)=exp(−E(x))\tilde{p}(x) = exp(-E(x))p~(x)=exp(−E(x)) ,由于取指数后总是正值,这保证了所有状态的概率大于零。基于能量的模型也被称作玻尔兹曼机(Boltzmann machine)。
当我们想从模型中取样时,对于有向图,我们可以利用 原始采样法(Ancestral Sampling),即对图中的变量进行拓扑排序(topological ordering),使得对于所有 i,ji,ji,j ,满足假如 xix_ixi 是xjx_jxj 的父节点,则 j>ij>ij>i 。这样,我们就可以先取样 x1∼P(x1)x_1 \sim P(x_1)x1∼P(x1) ,然后取样 P(x2∣PaG(x2))P(x_2|Pa_G(x_2))P(x2∣PaG(x2)) ,以此类推,最后取样 P(xn∣PaG(xn))P(x_n|Pa_G(x_n))P(xn∣PaG(xn)) 。
而对于无向图,我们无法进行拓扑排序,通常采取的方法是吉布斯采样(Gibbs Sampling)。Gibbs Sampling是一种马尔科夫链蒙特卡洛算法(Markov Chain Monte Carlo,简称MCMC),其基本思想是假设我们有n个变量,初始的样本表示为 (x1(0),x2(0),...,xn(0))(x_1^{(0)}, x_2^{(0)}, ..., x_n^{(0)})(x1(0),x2(0),...,xn(0)) ,之后迭代取样时每个变量取自依赖于现有其他变量值的条件概率分布,即第 iii 次迭代取样时,
x1(i)∼p(X1=x1∣X2=x2(i−1),...,Xn=xn(i−1))x_1^{(i)}\sim p(X_1=x_1|X_2=x_2^{(i-1)},...,X_n=x_n^{(i-1)})x1(i)∼p(X1=x1∣X2=x2(i−1),...,Xn=xn(i−1))
x2(i)∼p(X2=x2∣X1=x1(i−1),...,Xn=xn(i−1))x_2^{(i)}\sim p(X_2=x_2|X_1=x_1^{(i-1)},...,X_n=x_n^{(i-1)})x2(i)∼p(X2=x2∣X1=x1(i−1),...,Xn=xn(i−1))
…
xn(i)∼p(Xn=xn∣X1=x1(i−1),...,Xn−1=xn−1(i−1))x_n^{(i)}\sim p(X_n=x_n|X_1=x_1^{(i-1)},...,X_{n-1}=x_{n-1}^{(i-1)})xn(i)∼p(Xn=xn∣X1=x1(i−1),...,Xn−1=xn−1(i−1))
依此迭代直到取样趋近于真实分布,详细内容见下一章蒙特卡洛算法。
假设我们有许多观察到的变量 v⃗\vec{v}v ,有些有相互作用而有些没有,且我们事先不知道这些相互关系,我们该如何训练出合适的图来表示它们之间的关系呢?一种方法被称作结构化学习\预测(Structured Learning),本质上是一种贪心搜索算法(greedy search),即先试验几种结构的图,看哪种训练误差最小且模型复杂度较低,然后再在这种结构上试验添加或去除某些边并选取其中效果最好的结构再如此循环下去。这种算法的缺点是需要不断的搜索模型结构而且需要多次训练,另一种更常见的方法是引入一些隐藏变量 h⃗\vec{h}h,则观察变量 viv_ivi 与 vjv_jvj 的关系通过 viv_ivi 与 h⃗\vec{h}h 以及 h⃗\vec{h}h 与 vjv_jvj 之间的依赖关系而间接的表示出来。我们可以选取固定的图的结构,令隐藏变量与观察变量相连接,并且通过梯度下降算法求得代表这些连接强弱的参数。
模型训练结束后,如何用模型进行对于某些节点的边缘分布(marginal distribution) 或条件概率分布(conditional distribution) 进行推断也是一大难题,所以常常需要我们进行近似推断,深度学习中常用到变分推断(variational inference),即寻找接近真实分布 p(h⃗∣v⃗)p(\vec{h}|\vec{v})p(h∣v) 的近似分布 q(h⃗∣v⃗)q(\vec{h}|\vec{v})q(h∣v) 。
实际上概率图也可以用深度学习中的计算图来代表,而我们的观察变量构成输入层,隐藏变量构成隐藏层,层与层之间的链接即代表概率图中的边。一个例子是受限玻尔兹曼机(restricted Boltzmann machine,简称RBM),即网络中仅有隐藏变量与观察变量的连接,而观察变量间没有连接,隐藏变量间也没有连接,如下图所示:
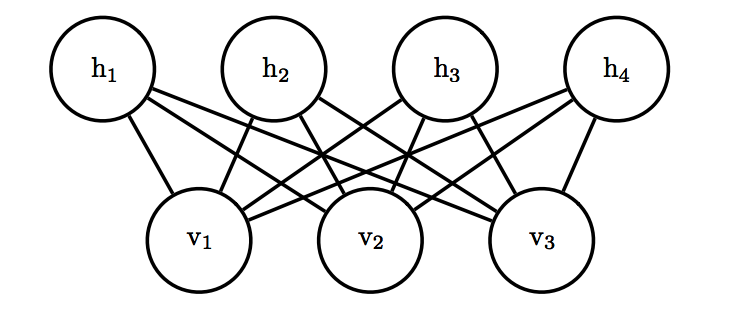
其能量函数可表示为 E(v⃗,h⃗)=−b⃗Tv⃗−c⃗Th⃗−v⃗TWh⃗E(\vec{v},\vec{h})=-\vec{b}^T\vec{v}-\vec{c}^T\vec{h}-\vec{v}^TW\vec{h}E(v,h)=−bTv−cTh−vTWh ,其中 b⃗,c⃗,W\vec{b},\vec{c}, Wb,c,W 为网络所需要学习的参数。
由于RBM中仅有 v⃗\vec{v}v 与 h⃗\vec{h}h 间的连接,Gibbs sampling的过程就更简单了,我们可以同时sample所有的 h⃗\vec{h}h ,然后再同时sample所有的 v⃗\vec{v}v 依次交替进行。另外能量函数的导数为 ∂∂Wi,jE(v⃗,h⃗)=−vihj\frac{\partial}{\partial W_{i,j}}E(\vec{v},\vec{h})=-v_ih_j∂Wi,j∂E(v,h)=−vihj ,方便运算,所以我们可以很高效的进行训练。
下一周将进行蒙特卡罗方法学习。
【学习周报】注意力机制的工作原理和主流方法。相关推荐
- Android开发:图文分析 Handler通信机制 的工作原理
前言 在Android开发的多线程应用场景中,Handler机制十分常用 下面,将图文详解 Handler机制 的工作原理 目录 1. 定义 一套 Android 消息传递机制 2. 作用 在多线程的 ...
- 理解并取证:以太通道的动态协商机制的工作原理
理解并取证:以太通道的动态协商机制的工作原理 取自博主<思科CCNP交换技术详解与实验指南>试读版 3.1理解以太通道的理论部分 3.1.1提出以太通道的原因.以太通道的作用和功能 3.1 ...
- 哨兵 (sentinal) 机制的工作原理
哨兵 (sentinal) 机制的工作原理 什么是哨兵机制? Redis的哨兵(sentinel) 系统用于管理多个 Redis 服务器,该系统执行以下三个任务: 监控(Monitori ...
- 大道至简----多示例学习与注意力机制的巧妙结合
大道至简----多示例学习与注意力机制的巧妙结合 谈谈<Attention-based deep multiple instance learning> ICML 2018 分享一篇十分简 ...
- Springboot事件监听机制:工作原理
目录 前言 1.观察者模式 1.1观察者模式的核心元素 1.2观察者模式的工作流程 2.springboot事件监听机制的基本工作原理 2.1事件发布器是什么时候在哪里产生的呢? 2.2事件监听器是什 ...
- 模电学习笔记 (一) 晶体三极管工作原理
大家好,我是一名从事硬件电路设计的小工程师一名.我决心从今天开始撰写自己的博客,一方面是为了对知识进行总结记录,加深理解与认识,另一方面希望大家可以多多批评指正,同时结识更多志同道合的朋友,一起学习进 ...
- php的工作原理,PHP的运行机制和工作原理的内容
这篇文章给大家介绍的内容是关于PHP的运行机制和工作原理的内容,有着一定的参考价值,有需要的朋友可以参考一下. 一.PHP设计理念及特点 多进程模型:由于PHP是多进程模型,不同请求间互不干涉,这样保 ...
- [深度学习学习笔记]注意力机制-Attentional mechanism
注意力机制最早在自然语言处理和机器翻译对齐文本中提出并使用,并取得了不错的效果.在计算机视觉领域,也有一些学者探索了在视觉和卷积神经网络中使用注意力机制来提升网络性能的方法.注意力机制的基本原理很 ...
- 学习总结——注意力机制(transformer、DETR)
学习总结--注意力机制 初探注意力 通道注意力 空间注意力 CV中基本注意力机制 NLP中的注意力机制 自注意力机制 DETR 参考文献 初探注意力 我们知道图片可以通过提取特征进行分类.目标检测等后 ...
最新文章
- 70美元桌面电脑,树莓派400:键盘式集成开发板
- python文本操作
- MAMP mac下启动Mysql
- Django 的缓存机制
- 基于labview的温湿度数据采集_【零偏原创】基于FPGA的多路SPI接口并行数据采集系统...
- android—获取网络数据
- 【Java并发编程】之二:线程中断
- 微服务的简介和技术栈,太牛逼了!
- android 音量调节流程分析,Android 4.4 音量调节流程分析(二)
- Qt配置OpenCV教程,无需复杂的编译过程,(详细版)
- 服务器 异常自动关机,服务器自动关机
- 微信小程序上线,后台接口失效问题
- CVE-2013-3893 IE浏览器UAF漏洞分析
- 栅栏CyclicBarrier
- 工程经济有何难,思维导图来助阵
- java 文件上传漏洞_文件上传漏洞(绕过姿势)
- 新手入门——计算机概论
- M3操作系统汇编理解
- 基于javaweb+jsp的高校科研项目管理系统(JavaWeb MySQL JSP Bootstrap Servlet SSM SpringBoot)
- office 365 ppt创意方法(拆字动画)