数据分析行业薪资的秘密,你想知道的都在这里(1)

第一部分,数据分析职位信息抓取
数据分析师的收入怎么样?哪些因素对于数据分析的薪资影响最大?哪些行业对数据分析人才的需求量最高?我想跳槽,应该选择大公司大平台还是初创的小公司?按我目前的教育程度,工作经验,和掌握的工具和技能,能获得什么样水平的薪资呢?
我们使用python抓取了2017年6月26日拉钩网站内搜索“数据分析”关键词下的450条职位信息。通过对这些职位信息的分析和建模来给你答案。
本系列文章共分为五个部分,分别是数据分析职位信息抓取,数据清洗及预处理,数据分析职位需求分析,数据分析职位薪影响因素分析,以及数据分析职位薪资建模及预测。这是第一篇:数据分析职位信息抓取。
数据抓取前的准备工作
首先我们需要获取职位信息的数据,方法是使用python进行抓取。整个抓取过程分为两部分,第一部分是抓取拉钩列表页中包含的职位信息,例如职位名称,薪资范围,学历要求,工作地点等。第二部分是抓取每个职位详情页中的任职资格和职位描述信息。然后我们将使用结巴分词和nltk对职位描述中的文字信息进行处理和信息提取。下面我们开始介绍每一步的操作过程。
首先,导入抓取和数据处理所需的库文件,这里不再赘述。
- #导入抓取所需库文件
- import requests
- import numpy as np
- import pandas as pd
- import json
- import time
- from bs4 import BeautifulSoup
然后设置头部信息和Cookie信息。
- #设置头部信息
- headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
- 'Accept':'text/html;q=0.9,*/*;q=0.8',
- 'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
- 'Connection':'close',
- 'Referer':'https://www.baidu.com/'
- }
- #设置Cookie信息
- cookie={'TrackID':'1_VWwvLYiy1FUr7wSr6HHmHhadG8d1-Qv-TVaw8JwcFG4EksqyLyx1SO7O06_Y_XUCyQMksp3RVb2ezA',
- '__jda':'122270672.1507607632.1423495705.1479785414.1479794553.92',
- '__jdb':'122270672.1.1507607632|92.1479794553',
- '__jdc':'122270672',
- '__jdu':'1507607632',
- '__jdv':'122270672|direct|-|none|-|1478747025001',
- 'areaId':'1',
- 'cn':'0',
- 'ipLoc-djd':'1-72-2799-0',
- 'ipLocation':'%u5317%u4EAC',
- 'mx':'0_X',
- 'rkv':'V0800',
- 'user-key':'216123d5-4ed3-47b0-9289-12345',
- 'xtest':'4657.553.d9798cdf31c02d86b8b81cc119d94836.b7a782741f667201b54880c925faec4b'}
抓取职位列表信息
设置要抓取的页面URL,拉钩的职位信息列表是JS动态加载的,不在所显示的页面URL中。所以直接抓取列表页并不能获得职位信息。这里我们使用Chrome浏览器里的开发者工具进行查找。具体方法是在商品详情页点击鼠标右键,选择检查,在弹出的开发者工具界面中选择Network,设置为禁用缓存(Disable cache)和只查看XHR类型的请求。然后刷新页面。一共有4个请求,选择包含positionAjax关键字的链接就是我们要抓取的URL地址。具体过程如下面截图所示。
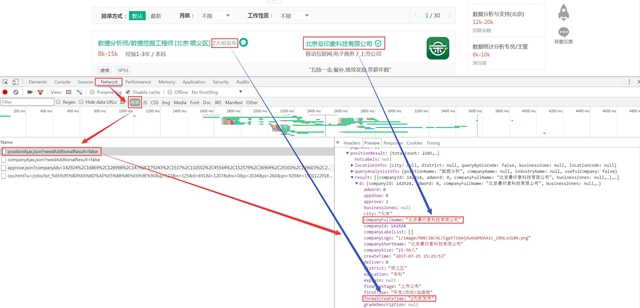
这里有一个问题,要抓取的URL地址中只有第一页的15个职位信息,并且URL参数中也没有包含页码。而我们要抓取的是全部30多页的职位列表。如何翻页呢?后面我们将解决这个问题。
- #设置抓取页面的URL
- url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
职位列表中包含了多个职位相关的信息,我们先建立一些空list用于存储这些信息。
- #创建list用于存储数据
- positionName=[]
- workYear=[]
- education=[]
- district=[]
- jobNature=[]
- salary=[]
- city=[]
- businessZones=[]
- companyLabelList=[]
- companySize=[]
- financeStage=[]
- industryField=[]
- secondType=[]
- positionId=[]
开始抓取列表页中的职位信息,建立一个30页的循环然后将页码作为请求参数与头部信息和Cookie一起传给服务器。获取返回的信息后对页面内容进行解码,然后从json数据中提取所需的职位信息,并保存在上一步创建的list中。用于后续的组表。这里的最后一个信息是职位id,也就是拉钩职位详情页URL中的一部分。通过这个id我们可以生成与列表页职位相对应的详情页URL。并从中提取任职资格和职位描述信息。
- #循环抓取列表页信息
- for x in range(1,31):
- #设置查询关键词及当前页码
- para = {'first': 'true','pn': x, 'kd': "数据分析"}
- #抓取列表页信息
- r=requests.get(url=url,headers=headers,cookies=cookie,params=para)
- #存储bytes型页面数据
- html=r.content
- #对页面内容进行解码
- html = html.decode()
- #将json串转化为dict
- html_json=json.loads(html)
- #逐层获取职位列表信息
- content=html_json.get('content')
- positionResult=content.get('positionResult')
- result=positionResult.get('result')
- #循环提取职位列表中的关键信息
- for i in result:
- #获取职位名称,工作年限,教育程度,城市及薪资范围等信息。
- positionName.append(i.get('positionName'))
- workYear.append(i.get('workYear'))
- education.append(i.get('education'))
- district.append(i.get('district'))
- jobNature.append(i.get('jobNature'))
- salary.append(i.get('salary'))
- city.append(i.get('city'))
- businessZones.append(i.get('businessZones'))
- companyLabelList.append(i.get('companyLabelList'))
- companySize.append(i.get('companySize'))
- financeStage.append(i.get('financeStage'))
- industryField.append(i.get('industryField'))
- secondType.append(i.get('secondType'))
- #获取职位的Id编码。
- positionId.append(i.get('positionId'))
设置一个当前的日期字段,用于标记数据获取的时间。
- #设置日期字段
- date=time.strftime('%Y-%m-%d',time.localtime(time.time()))
将前面抓取到的职位信息,以及当前的日期一起组成Dataframe。便于后续的处理和分析。
- #设置DataFrame表格顺序
- columns = ['date','positionName',
- 'workYear','education','jobNature','businessZones','salary','city','companyLabelList','companySize','financeStage','industryField','d
- istrict','secondType','positionId']
- #将获取到的字段信息合并为DataFrame
- table=pd.DataFrame({'date':date,
- 'positionName':positionName,
- 'workYear':workYear,
- 'education':education,
- 'jobNature':jobNature,
- 'businessZones':businessZones,
- 'salary':salary,
- 'city':city,
- 'companyLabelList':companyLabelList,
- 'companySize':companySize,
- 'financeStage':financeStage,
- 'industryField':industryField,
- 'district':district,
- 'secondType':secondType,
- 'positionId':positionId},
- columns=columns)
查看生成的数据表,其中包含了我们在列表页中抓取的信息,以及下一步要使用的职位id信息。
- #查看数据表
- table
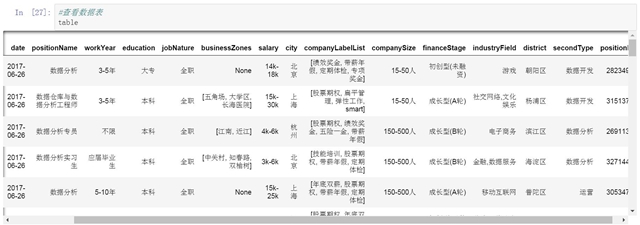
这里你可以保存一个版本,也可以忽略这一步,继续后面的职位详情页信息抓取。
- #存储数据表
- table.to_csv('lagou_' + date + '.csv')
抓取职位详情信息(职位描述)
抓取职位详情页的信息,首先需要通过拼接生成职位详情页的URL。我们预先写好URL的开始和结束部分,这两部分是固定的,抓取过程中不会发生变化 ,中间动态填充职位的id。
- #设置详情页的URL固定部分
- url1='https://www.lagou.com/jobs/'
- url2='.html'
创建一个list用于存储抓取到的职位描述信息。
- #创建job_detail用于存储职位描述
- job_detail=[]
从前面抓取的职位id(positionId)字段循环提取每一个id信息,与URL的另外两部分组成要抓取的职位详情页URL。并从中提取职位描述信息。这里的职位信息不是js动态加载的,因此直接抓取页面信息保存在之前创建的list中就可以了。
- #循环抓取详情页的职位描述
- for d in positionId:
- #更改positionId格式
- d=str(d)
- #拼接详情页URL
- url3=(url1 + d + url2)
- #抓取详情页信息
- r=requests.get(url=url3,headers=headers,cookies=cookie)
- #存储bytes型页面数据yu
- detail=r.content
- #创建 beautifulsoup 对象
- lagou_detail=BeautifulSoup(detail)
- #提取职位描述信息
- gwzz=lagou_detail.find_all('dd',attrs={'class':'job_bt'})
- for j in gwzz:
- gwzz_text=j.get_text()
- job_detail.append(gwzz_text)
查看并检查一下提取到的职位描述信息。然后将职位描述信息拼接到之前创建的Dataframe中。
- #查看职位描述信息
- job_detail

完整的职位抓取代码
以下是完整的抓取代码,步骤和前面介绍的略有不同,最后生成一个包含所有职位信息和描述的完整数据表。用于下一步的数据清洗,预处理,分析和建模的工作。
- def lagou(p):
- import requests
- import numpy as np
- import pandas as pd
- import json
- import time
- from bs4 import BeautifulSoup
- import jieba as jb
- import jieba.analyse
- headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
- 'Accept':'text/html;q=0.9,*/*;q=0.8',
- 'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
- 'Connection':'close',
- 'Referer':'https://www.jd.com/'
- }
- cookie={'TrackID':'1_VWwvLYiy1FUr7wSr6HHmHhadG8d1-Qv-TVaw8JwcFG4EksqyLyx1SO7O06_Y_XUCyQMksp3RVb2ezA',
- '__jda':'122270672.1507607632.1423495705.1479785414.1479794553.92',
- '__jdb':'122270672.1.1507607632|92.1479794553',
- '__jdc':'122270672',
- '__jdu':'1507607632',
- '__jdv':'122270672|direct|-|none|-|1478747025001',
- 'areaId':'1',
- 'cn':'0',
- 'ipLoc-djd':'1-72-2799-0',
- 'ipLocation':'%u5317%u4EAC',
- 'mx':'0_X',
- 'rkv':'V0800',
- 'user-key':'216123d5-4ed3-47b0-9289-12345',
- 'xtest':'4657.553.d9798cdf31c02d86b8b81cc119d94836.b7a782741f667201b54880c925faec4b'}
- url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
- positionName=[]
- workYear=[]
- education=[]
- district=[]
- jobNature=[]
- salary=[]
- city=[]
- businessZones=[]
- companyLabelList=[]
- companySize=[]
- financeStage=[]
- industryField=[]
- secondType=[]
- positionId=[]
- for x in range(1,31):
- para = {'first': 'true','pn': x, 'kd': p}
- r=requests.get(url=url,headers=headers,cookies=cookie,params=para)
- html=r.content
- html = html.decode()
- html_json=json.loads(html)
- content=html_json.get('content')
- positionResult=content.get('positionResult')
- result=positionResult.get('result')
- for i in result:
- positionName.append(i.get('positionName'))
- workYear.append(i.get('workYear'))
- education.append(i.get('education'))
- district.append(i.get('district'))
- jobNature.append(i.get('jobNature'))
- salary.append(i.get('salary'))
- city.append(i.get('city'))
- businessZones.append(i.get('businessZones'))
- companyLabelList.append(i.get('companyLabelList'))
- companySize.append(i.get('companySize'))
- financeStage.append(i.get('financeStage'))
- industryField.append(i.get('industryField'))
- secondType.append(i.get('secondType'))
- positionId.append(i.get('positionId'))
- url1='https://www.lagou.com/jobs/'
- url2='.html'
- job_detail=[]
- for d in positionId:
- d=str(d)
- url3=(url1 + d + url2)
- r=requests.get(url=url3,headers=headers,cookies=cookie)
- detail=r.content
- lagou_detail=BeautifulSoup(detail)
- gwzz=lagou_detail.find_all('dd',attrs={'class':'job_bt'})
- for j in gwzz:
- gwzz_text=j.get_text()
- job_detail.append(gwzz_text)
- date=time.strftime('%Y-%m-%d',time.localtime(time.time()))
- columns = ['date','positionName', 'workYear','education','jobNature','businessZones','salary','city','companyLabelList','companySize','financeStage','industryField','district','secondType','positionId','job_detail']
- table=pd.DataFrame({'date':date,
- 'positionName':positionName,
- 'workYear':workYear,
- 'education':education,
- 'jobNature':jobNature,
- 'businessZones':businessZones,
- 'salary':salary,
- 'city':city,
- 'companyLabelList':companyLabelList,
- 'companySize':companySize,
- 'financeStage':financeStage,
- 'industryField':industryField,
- 'district':district,
- 'secondType':secondType,
- 'positionId':positionId,
- 'job_detail':job_detail},
- columns=columns)
- table.to_csv('lagou_' + p + date + '.csv')
- lagou("数据分析")

到这里我们已经获取了拉钩网的450个数据分析职位信息及职位描述。我们将在后面的文章中对这450个职位信息进行分析和建模。
本文作者:王彦平
来源:51CTO
数据分析行业薪资的秘密,你想知道的都在这里(1)相关推荐
- 转行、入行必看!都2021年了,数据分析行业还值得进吗?
转行进数据分析已经十年了,表达一下我的个人看法. 私以为,数据分析行业是可以长期发展下去的,但是对于数据分析师的专业技能的要求会越来越严格. 一.原因分析 在互联网时代下诞生的不仅仅是一系列的智能产品 ...
- 2021年,从事数据分析行业前景如何?还能转行数据分析师吗?(下)
2021年,从事数据分析行业前景如何?还能转行数据分析师吗?(上) 在上期的话题中,我们一起分享探讨了以下几个话题: 1.2021年还学数据分析还来得及不?行业前景怎么样? 2.从一些小道消息上看到, ...
- 2013国内IT行业薪资对照表【技术岗】
2013国内IT行业薪资对照表[技术岗](转载) 说薪水,是所有人最关心的问题.我只想说如果想在薪水上面满意,在中国,没有哪里比垄断国企好.电力.烟草.通信才是应该努力的方向.但是像我们这种搞研发的进 ...
- 2013国内IT行业薪资对照表
===================================================== 1 华为 西电人最纠结的一个公司.西安今年要的人太少了,今年大行情不好,比08 09年惨多了 ...
- 2013国内IT行业薪资对照表【技术岗】(转载)
说薪水,是所有人最关心的问题.我只想说如果想在薪水上面满意,在中国,没有哪里比垄断国企好.电力.烟草.通信才是应该努力的方向.但是像我们这种搞研发的进IT行业似乎是注定的.IT外企也有很多很不错的,s ...
- python初级数据分析师薪资_学会数据分析,薪资翻倍?!
信息爆炸的时代,数据分析行业异常火爆,倍受众多人才的青睐.数据分析火爆的原因就是由于数据分析这一行业具有未来的前瞻性,正因为如此使得数据分析具有了十分广阔的前景. 其实,大部分人还不了解数据分析行业, ...
- python生物数据分析师职业技能_数据分析行业各个职业需要的技能是什么?
就目前而言,很多人看到了数据分析行业的光明前景,于是就想进入数据分析的行业中.但是,想成为一名合格的数据分析师,需要掌握很多的技能.那么一名合格的数据分析师需要掌握哪些技能呢?其实数据分析行业的职业是 ...
- 成都python数据分析师职业技能_数据分析师需要什么技能,数据分析行业都有什么职业?...
就目前而言,很多人看到了数据分析行业的光明前景,于是就想进入数据分析的行业中,但是,想成为一名合格的数据分析师,需要掌握很多的技能,那么一名合格的数据分析师需要掌握哪些技能呢?现在的数据分析行业中有数 ...
- python生物数据分析师职业技能_数据分析师需要什么技能,数据分析行业都有什么职业?...
就目前而言,很多人看到了数据分析行业的光明前景,于是就想进入数据分析的行业中,但是,想成为一名合格的数据分析师,需要掌握很多的技能,那么一名合格的数据分析师需要掌握哪些技能呢?现在的数据分析行业中有数 ...
最新文章
- 内存转换Image到Icon
- 最近在学C语言,非常痛苦,怎么办?
- Zeppelin源码
- Javascript中的深拷贝和浅拷贝
- sonar 使用问题 Unable to load component class org.sonar.scanner.report.ActiveRulesPublisher
- 全阶滑模观测器程序_滑模观测器转子估算程序
- 在Python中将列表转换为元组
- 8. Browser 对象 - History 对象(2)
- 经典java算法大全
- Arduino与Proteus仿真实例-TB6612FNG驱动直流电机仿真
- mysql写保护_简易修改注册表!小白都会去掉u盘写保护
- android+6+wifi密码,Android 如何查看Wifi密码
- Spark多行合并一行collect_list使用
- Windows 11的临时文件清理工具
- php中round(),PHP round( )用法及代码示例
- XILINX FPGA最小逻辑单元CLBs, Slices和LUT区别
- python列表输出序号_Python中打印列表的序号和内容
- hash和history路由的区别
- py征途3之填坑(pagerank个人详解)
- 【深入PHP 面向对象】读书笔记(四) - 对象与设计