ElasticSearch学习(五):数据导入之Logstash
前面我们部署了ElasticSearch和Kibana,实现了ElasticSearch的基本操作和管理,还往ElasticSearch里面插入了几条数据以及进行了最简单的查询。ElasticSearch是用来干什么的呢?ElasticSearch是一个搜索引擎,用来搜索数据的啊。那数据从哪里来呢,总不能手动一条条地插入吧?我们现在的数据还保存在MySQL,并且数据是不断增长的,那么怎么将数据保存到ElasticSearch中呢?
官方提供了一个Logstash工具,是一个开源数据收集引擎,可以将不同来源的数据保存到ElasticSearch或者是hadoop等其他地方。
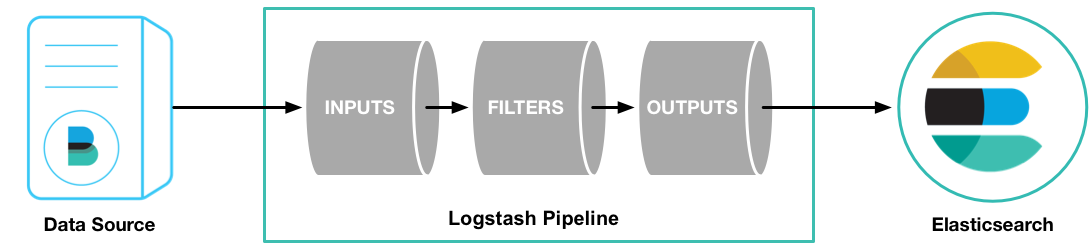
下面简单介绍一下Logstash从MySQL数据库导入到ElasticSearch,Logstash从Mysql数据库接收数据,经过filter过滤后输出到ElasticSearch中。
下载
还是安装到"~/elasticSearch"文件夹下。进入目录,下载Logstash压缩包
cd ~/elasticSerach/
wget -c https://artifacts.elastic.co/downloads/logstash/logstash-6.5.4.tar.gz下载完成后,解压到当前文件夹
tar -xvf logstash-6.5.4.tar.gz![]()
需要说明的是,Logstash更像是一个框架,而运行于Logstash上面的插件才是导入数据的关键。从数据库导入数据,需要用到"logstash-input-jdbc"插件,而导出数据到elasticsearch需要用到"logstash-output-elasticsearch"插件,但这些插件不用我们另外去下载了,在上面下载好的logstash包里已经包含了这些插件。可以通过下面的命令来查看已经安装好的插件
logstash-6.5.4/bin/logstash-plugin list配置
我们需要一个配置文件来配置Msql的连接信息、查询表的SQL语句、ElasticSearch的连接信息等。新建一个配置文件mysql.conf,放在/logstash-6.5.4/config/mysql目录下,内容如下:
input {
jdbc {
jdbc_driver_library => "/home/yangp/elasticSerach/logstash-6.5.4/config/mysql/mysql-connector-java-8.0.12.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.1.226:3306/mongcent_backstage?serverTimezone=Asia/Shanghai&characterEncoding=utf8&allowMultiQueries=true&useSSL=false"
jdbc_user => "root"
jdbc_password => "123"
schedule => "* * * * *"
statement => "SELECT * FROM sys_user"
}
}output {
elasticsearch {
hosts => ["http://192.168.1.196:9201"]
index => "user"
}
}
可以看到,mysql.conf的内容主要有两部分,分别是input和output。其中input是输入部分,这里我们设置为Mysql;output是输出部分,这里我们设置为elasticsearch。
先说一下input,我们配置了一个jdbc,实际上这里可以配置多个不同的输入。jdbc内部的配置跟java项目里的数据库连接信息差不多,jdbc_driver_library为Mysql的驱动jar包,需要下载放到自定义的位置;jdbc_connection_string即是mysql的url,注意要跟java项目里的一样,数据库表后面问号的那一串东西不要省略了;jdbc_user和jdbc_password分别为Mysql的账号密码;schedule为执行时间,上面的写法是每分钟执行一次;statement为执行的SQL语句,当然这个语句还有更复杂的写法,下面再说。
再来说一下output,这个就比较简单了,这里配置了elasticsearch一个输出节点,这里也可以同时配置多个输出,会将数据同时输出到多个地方。elasticsearch内部比较简单,hosts是elasticsearch的访问ip和端口;index是将上面数据库查到的数据保存到elasticsearch的user索引。这里要注意的是:如果之前在elasticsearch中建立过一个叫user的索引了,并且索引的type不是doc,那么在Logstash保存数据到user的时候会报错:
Rejecting mapping update to [user] as the final mapping would have more than 1 type
原因是logstash在同步的时候会自动创建一个doc类型的index,而elasticsearch中已存在的user的type不是doc,所以引起冲突。解决办法:删除原来的user索引。
运行
OK,现在我们的logstash-6.5.4/config/mysql目录下存在了mysql.conf,以及mysql的驱动jar包(这个自己下载复制过来),运行以下命令来运行logstash
./logstash-6.5.4/bin/logstash -f ./logstash-6.5.4/config/mysql/mysql.conf不出意外的话,就能看到下面的信息了,表示logstash正常启动了。
![]()
但是,现在数据还没有同步的,因为我们上面设置了每分钟执行一次同步,所以我们要等一下,直到看到下面的信息,数据才开始同步
![]()
没报错的话,去elasticsearch看看有没有同步数据过来了。去Kibana的Dev Tools里输入
GET user/_search
点击运行,就能看到从数据库中同步过去的数据了。
需要注意的时,现在是设置了每分钟同步一次,并且每次都是同步整个user表的数据。所以如果Logstash跑了好几分钟的话,会在elasticsearch里看到好几批重复的数据。赶紧的先把logstash停下来吧。
输入设置
上面我们对输入进行了一个简单的配置,将user表的所有数据导入到elasticsearch中。但实际上会碰到两个问题:一是user表可能非常大,不可能一次性导入,需要分批导入;二是数据不是固定的,是不断增长的,我们需要不停地把新的数据导入到elasticsearch中。针对这两个问题,JDBC插件都给出了解决方案:分页、记录增长字段。
使用递增列
先说说使用递增列。我们在mysql里使用的id是自增长的,所以只要记录上一次查询到的id,然后下一次查询时加个条件"where id > 上次获得的ID"就能查到还没导入的新数据。如果数据库不是采用自增的方式,那么可以使用插入时间来判断,原理是一样的"where createTime > 上次获取到的时间"
input {
jdbc {
//省略其他配置
statement => "SELECT * FROM news where id > :sql_last_value"
use_column_value => true
tracking_column => "id"
tracking_column_type => "numeric"
last_run_metadata_path => "/home/yangp/elasticSerach/logstash-6.5.4/config/mysql/newsId.txt"
}
}
如上所示,我们要将use_column_value设置为true,表示开启递增列功能;
tracking_column表示使用哪个字段,这里使用的是id,也可以设置为使用插入时间等;
tracking_column_type表示tracking_column设置的那个字段的类型,只能选择timestamp或者numeric,默认numeric,所以上面可以不写这个配置;
last_run_metadata_path为保存上次查询到id保存的文件,随便给个文件就好了;
:sql_last_value为保留字段,就是上次查询的tracking_column那个字段的值,也就是在last_run_metadata_path文件保存到的值,在这里是上次查询到的id。
设置好之后,每次运行后都会自动更新:sql_last_value的值,然后进行查询的时候会带上:sql_last_value,实现了只查询新增加数据的功能
分页
其实上面的设置已经可以满足90%以上的情况了,但是在一些情况下,比如第一次使用时数据库里已经存在大量数据了;或者在一分钟内数据的增长达到了几万、几十万甚至更多的,那么我们还是需要一个分页的功能,避免一次性查询太多的数据。
input {
jdbc {
//省略其他配置
jdbc_paging_enabled => true
jdbc_page_size => 10000
}
}
分页的配置很简单,只需要在后面加上上面两条配置就行了。
jdbc_paging_enabled设置为true,表示开启分页功能;
jdbc_page_size表示每页的大小,默认是10000,可以改成合适的值。
配置好上面之后,Logstash就会自动对查询结果进行分页,生成的sql如下:
SELECT count(*) AS `count` FROM (SELECT * FROM news where id > 0) AS `t1` LIMIT 1
SELECT * FROM (SELECT * FROM news where id > 0) AS `t1` LIMIT 10000 OFFSET 0
SELECT * FROM (SELECT * FROM news where id > 0) AS `t1` LIMIT 10000 OFFSET 10000
……
很明显是先对上面使用递增列的查询结果进行分页,对递增列是没有任何影响的。
输出设置
在上面的配置中,我们设置了将数据输出到elasticsearch中,但也存在一个问题就是在重复运行的时候,有数据重复了。这是因为导入数据的时候elasticsearch都自动生成了一个ID,如果我们将数据库中的ID作为elasticsearch中的文档id,那么这个问题就解决了。还有一个问题就是我们拥有两个elasticsearch节点,但是只把数据导入到其中一个节点中,此处应该做个负载均衡。
output {
stdout {}
elasticsearch {
hosts => ["http://192.168.1.196:9201","http://192.168.1.196:9202"]
index => "user"
document_id => "%{id}"
}
}
在上面的配置中,除了输出到elasticsearch之外,我们还增加了一个输出到stdout,也就是输出到命令窗口中。当获取到数据后,Logstash会同时将数据发送到窗口和elasticsearch中。
在elasticsearch的hosts配置中,我们把另一个节点的地址也加了进来,logstash会轮流向两个节点输出数据,实现负载均衡;
加了一个document_id配置,之前没有这个配置的时候,会自动生成一个id作为文档的ID,上面配置了将从数据库中查询到的id的值作为文档的ID,可以避免数据重复的问题。
下面是完整的配置:
input {
jdbc {
jdbc_driver_library => "/home/yangp/elasticSerach/logstash-6.5.4/config/mysql/mysql-connector-java-8.0.12.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.1.226:3306/news_current?serverTimezone=Asia/Shanghai&characterEncoding=utf8&allowMultiQueries=true&useSSL=false"
jdbc_user => "root"
jdbc_password => "root"
schedule => "* * * * *"
statement => "SELECT * FROM news where id > :sql_last_value"
use_column_value => true
tracking_column => "id"
last_run_metadata_path => "/home/yangp/elasticSerach/logstash-6.5.4/config/mysql/newsId.txt"
jdbc_paging_enabled => true
jdbc_page_size => 10000
}
}
output {
stdout {}
elasticsearch {
hosts => ["http://192.168.1.196:9201","http://192.168.1.196:9202"]
index => "user"
document_id => "%{id}"
}
}
最后
再次运行一下命令
./logstash-6.5.4/bin/logstash -f ./logstash-6.5.4/config/mysql/mysql.conf然后就是等待等待等待~~
![]()
到最后导入数据完成!开虚拟机导入90多万条数据,花了40多分钟,渣渣电脑
ElasticSearch学习(五):数据导入之Logstash相关推荐
- 超图学习之-数据导入
超图学习之-数据导入 第一次接触超图软件,所以记录录一下.如果有错误请大家一定指出谢谢 1.新建一个本地数据源 开始 → 数据源 → 新建 2.开始导入外部数据 开始 →数据 → 数据导入 3. 导如 ...
- 【ElasticSearch】 Hive数据导入到 es 的 项目 FastIndex
1.概述 https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247500894&idx=2&sn=75fc7035e ...
- arangodb mysql_ArangoDB数据导入
目录 1.arangoimp方法 参数解析 全局配置部分(Global configuration) --backslash-escape use backslash as the escape ch ...
- Elasticsearch 与mysql数据同步
这里写自定义目录标题 Elasticsearch 与mysql数据同步 安装logstash 启动 注意事项,很重要 Elasticsearch 与mysql数据同步 通过调用Elasticsearc ...
- 【Logstash】Logstash:把MySQL数据导入到Elasticsearch中
1.概述 转载:https://www.cnblogs.com/sanduzxcvbnm/p/12076487.html Logstash:把MySQL数据导入到Elasticsearch中 前提条件 ...
- 使用logstash将Oracle数据导入到Elasticsearch
今天总结一下如何使用logstash将Oracle数据导入到Elasticsearch,然后后面会分享怎么在KONGA中配置API接口给用户. 首先要安装好Logstash并且在服务端安装好Elast ...
- Mysql大批量数据导入ElasticSearch
注:笔者环境 ES6.6.2.linux centos6.9.mysql8.0.三个节点.节点内存64G.八核CPU 场景: 目前Mysql 数据库数据量约10亿,有几张大表1亿左右,直接在Mysql ...
- PSINS工具箱学习(一)下载安装初始化、SINS-GPS组合导航仿真、习惯约定与常用变量符号、数据导入转换、绘图显示
文章目录 一.前言 二.相关资源 三.下载安装初始化 1.下载PSINSyymmdd.rar工具箱文件 2.解压文件 3.初始化 4.启动工具箱导览 四.习惯约定与常用变量符号 1.PSINS全局变量 ...
- oracle数据库开多线程,学习笔记:Oracle表数据导入 DBA常用单线程插入 多线程插入 sql loader三种表数据导入案例...
天萃荷净 oracle之数据导入,汇总开发DBA在向表中导入大量数据的案例,如:单线程向数据库中插入数据,多线程向数据表中插入数据,使用sql loader数据表中导入数据案例 1.Oracle数据库 ...
- 五、数据导入与基本的 SELECT 语句
文章目录 一.数据导入指令 二.基本查询语句 2.1 SELECT ... 2.2 使用 SELECT 语句查询一个数据表 2.3 查询表中的一列或多列 三.单表查询 3.1 用 DISTINCT 关 ...
最新文章
- 信息技术计算机网络PPT,高中信息技术计算机网络ppt课件.ppt
- Response 输出文件流过程中的等待效果
- jquery easyui 弹出对话框被activex控件遮挡问题
- win10安装kafka
- 802.11ac标准简介
- 支持向量机SVM算法原理
- 隐藏频道_《TED频道》-隐藏真实自我
- Linux启动hbase的shell命令出现警告_系统启动优盘制作图文教程(Windows Linux 等)...
- 高考计算机专业最低分数线是多少,2021最低多少分可以稳上二本 高考二本分数线是多少...
- Xcode 项目忽略警告
- vim粘贴代码格式变乱
- ElementUI表格序号翻页后重置的解决办法
- java 502错误_Spring Boot连接超时导致502错误的实战案例
- 二分钟倒计时c语言编程,c语言分钟倒计时代码.docx
- win10 如何修改 C:\Users\用户名文件夹
- AutoVue教程:如何在64位Linux上安装AutoVue
- 多元化邮件插图成鲜活生命力,助力邮件营销转化!
- 如何访问sci-hub?(更新于2017年11月26日)
- 函数:GetDistance,计算两个经度纬度之间距离
- Vivado2016如何改变字体大小