做网站用UTF-8编码还是GB2312编码?
经常我们打开外国网站的时候出现乱码,又或者打开很多非英语的外国网站的时候,显示的都是口口口口口的字符, WordPress程序是用的UTF-8,很多cms用的是GB2312。
经常我们打开外国网站的时候出现乱码,又或者打开很多非英语的外国网站的时候,显示的都是口口口口口的字符,
WordPress程序是用的UTF-8,很多cms用的是GB2312。
● 为什么有这么多编码?
● UTF-8和GB2312有什么区别?
● 我们在国内做网站是用UTF-8编码格式还是GB2312编码格式好?
一. 各种编码的来历
可能很多同学一直对字符的各种编码方式懵懵懂懂,根本搞不清为什么他们有这么多编码。
ANSI编码
其实在很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为“字节”。
开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。
他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作。
遇上00×10,终端就换行,遇上0×07, 终端就向人们嘟嘟叫,例好遇上0×1b, 打印机就打印反白的字,或者终端就用彩色显示字母。他们看到这样很好,于是就把这些0×20以下的字节状态称为"控制码"。
他们又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文 字了。大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI 的"Ascii"编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
扩展ANSI编码
后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计 算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编 到了最后一个状态255。从128到255这一页的字符集被称“扩展字符集”。从此之后,贪婪的人类再没有新的状态可以用了,美国当时估计也没想到还有别 的国家要用计算机的。
GB2312编码
当天朝人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。天朝人民就不客气地把那些127号之后的奇异符号们直接取消掉。
规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。
在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的“全角”字符,而原来在127号以下的那些就叫"半角"字符了。于是就把这种 汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。
GBK 和 GB18030编码
但是天朝的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些天朝领导的名字要是打不出很麻烦的。于是我们不得不继续把 GB2312 没有用到的码位找出来老实不客气地用上。
后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是 不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,天朝民族的文化就可以在计算机时代中传承了。
在这个标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。
那时候凡是受过编程学习的程序员都要每天念下面这个咒语数百遍的折磨:
“一个汉字算两个英文字符!一个汉字算两个英文字符……”
UNICODE编码
因为当时各个国家都像天朝这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,连大陆和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,也分别采用了不同的编码方案:
当时的天朝人想让电脑显示汉字,就必须装上一个“汉字系统”。专门用来处理汉字的显示、输入的问题。
但是那个装台湾的人士写的程序就必须加装另一套支持 BIG5 编码的“倚天汉字系统”才可以用,装错了字符系统,显示就会乱了套!这怎么办?而且世界民族中还有那些暂时用不上电脑的穷苦人民,他们的文字又怎么办?
正在这时,天使及时出现了——一个叫 ISO (国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号 的编码!他们打算叫它 UCS, 俗称 UNICODE 。( Universal Multiple-Octet Coded Character Set )
在UNICODE 中,一个汉字算两个英文字符的时代已经快过去了。
无论是半角的英文字母,还是全角的汉字,它们都是统一的“一个字符”!同时,也都是统一的“两个字节"”
UTF-8和UTF-16
UNICODE 来到时,一起到来的还有计算机网络的兴起,UNICODE 如何在网络上传输也是一个必须考虑的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF8就是每次8个位传输数据,而UTF16就是每次16个位,只不过为了传输时的可靠性,从UNICODE到 UTF时并不是直接的对应,而是要过一些算法和规则来转换。
未来的UCS-4
如前所述,UNICODE 是用两个字节来表示为一个字符,他总共可以组合出65535不同的字符,这大概已经可以覆盖世界上所有文化的符号。如果还不够也没有关系,ISO已经准备 了UCS-4方案,说简单了就是四个字节来表示一个字符,这样我们就可以组合出21亿个不同的字符出来(最高位有其他用途),这大概可以用到天朝成立银河 联邦成立那一天吧!
二. 为什么有些网站打开有时候会是乱码
网页乱码是浏览器(如IE等)对HTML网页解释时形成的。
如果在浏览网站网页的代码写错语系(比较少见),有形如:
<HTML>
<HEAD>
<META CONTENT=“text/html;charset=ISO-8859-1”></HEAD>……
</HTML>
的语句,浏览器在显示此页时,就会出现乱码。因为浏览器会将此页语种辨认为“欧洲语系”。
解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
还有一种可能比较大,就是网页并没有标明他用的是何种语系,即没有
<META CONTENT=“text/html;charset=XXXXX“>,这一行。
而你的计算机默认也不是这种语系,比方我们访问某些日文网站,经常出现这个问题。这个主要是由于程序员是面向当地的人开发的网站,由于当地都是默认语系,所以没有乱码种情况,而你是外来人,你的操作系统本身默认不是当地的语系。所以要手动改语系。
至于出现口口口口口口这种情况
这是由于网站并没有采用UTF-8编码而是采用的当地的编码,如蒙古语的,阿拉伯语的编码,你的计算机中并没有这种编码,所以不能识别。
解决办法是,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下 的“查看”/“编码”/“自动选择”/蒙古),如为繁体中文则选择“查看”/“编码”/“自动选择”/阿拉伯语,其它语言依此类推选择相应的语系,这样可 消除网页乱码现象。
三. 目前开发网站用什么编码比较好
我们一般通俗的理解为:
UTF-8是世界性通用代码,也完美的支持中文编码,如果我们做的网站能让国外用户正常的访问,就最好用UTF-8。
GB2312属于中文编码,主要针对国内用户使用,如果国外用户访问GB2312编码的网站就会变乱码。
网友的反馈一般觉得是用UTF-8比GB2312要多很多,大家都比较赞同用UTF-8。
从一张外国网站的调查也可看得出:
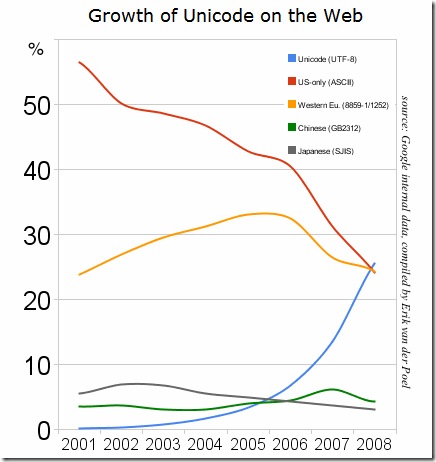
由此图可以看出,2001-2008年期间,GB2312编码的使用情况虽然幅度不大,但还是在稳定上升的;蓝色的线表示出用UTF-8的网站越来越多了。
我挑选了国内部分几个大的门户网站,看看他们用的是哪种编码格式:
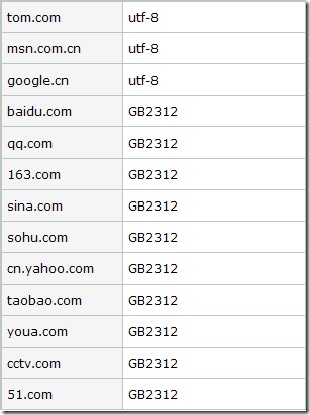
也许有同学就会问了为什么国内几个网站用GB2312反而更多些呢。
我也对这个疑问进行了思考,我觉得。应该有3种原因:
1. 国内这些网站本身历史也比较长,开始使用的就是 GB2312编码,现在改成 UTF-8(以前的网页)转换的难度和风险太大。
2. UTF-8编码的文件比GB2312更占空间一些,虽然目前的硬件环境下可以忽略,但是这些门户网站为了减少服务器负载基本上所有的页面都生成了静态 页,UTF-8保存起来文件会比较大,对于门户级别的网站每天生成的文件量还是非常巨大,带来的存储成本相应提高。
3. 由于UTF-8的编码比GB2312解码的网络传输数据量要大,对于门户级别的网站来说。这个无形之间就要增大带宽,用GB2312对网络流量无疑是最好的优化。
所以在新做站的情况下,建议还是选择UTF-8比较好。因为没有上面那些原因,兼容为上策。
转载于:https://www.cnblogs.com/gyjWEB/p/4600638.html
做网站用UTF-8编码还是GB2312编码?相关推荐
- unicode编码转gb2312编码并显示中文(cjava)
unicode编码转gb2312编码并显示中文(c&java) unicode编码与gb2312编码没有线性关系,只能通过使用编码表的方式查找. C语言 编码表中,前半部分是gb2312编码, ...
- 把UTF-8编码转换为GB2312编码
最近在做的广告系统中,碰到了一个问题,广告系统采用的UTF-8编码,而一些使用这套广告系统的频道页面使用的是GB2312编码.当然也有使用UTF-8编码的频道使用这套广告系统. 频道页面是通过嵌入类似 ...
- html显示蒙古语乱码,做网站用UTF-8编码还是GB2312编码?
经常我们打开外国网站的时候出现乱码,又或者打开很多非英语的外国网站的时候,显示的都是口口口口口的字符, WordPress程序是用的UTF-8,很多cms用的是GB2312. ● 为什么有这么多编码? ...
- 你还在为如何区分ASCII编码、GB2312编码、Unicod、UTF-8编码而烦恼吗,一篇文章让你柳暗花明...
字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特 ...
- linux 下URL中 UTF-8编码、GB2312编码与汉字之间的转换
下面是UTF-8编码的转换代码 #include <string.h> #include <stdio.h> #include <stdlib.h>/* 16进制字 ...
- html转换编码格式,html编码转换 html编码设置utf gbk编码转换图文教程
html编码转换 html编码设置utf gbk编码转换图文教程篇 常用HTML编码之urf-8编码转换为gb2312编码或者gb2312转换为utf-8编码快速转换设置,这里DIVCSS5介绍使用D ...
- Python 入门 26 —— ASCII 编码、Unicode 编码、 UTF-32、 UTF-16、 UTF-8、 GB2312 编码、 GBK 编码
计算机存储和处理信息都是以一个8位的二进制字节为单位的,例如:0b 1111 0000.一个字母.汉字等如何用一个二进制的数(编码)来表示呢.在计算机发展初期,因为没有人能预料到计算机会有现在这么大的 ...
- C++将UTF-8编码的文件转化为GB2312编码
C++将UTF-8编码的文件转化为GB2312编码 我需要对一个html网页进行解析,html是使用UTF-8编码的.但是,我使用的visual Studio 19是使用gb2312进行编码的.当读入 ...
- linux下查看文件编码及修改编码
linux下查看文件编码及修改编码 查看文件编码 在Linux中查看文件编码可以通过以下几种方式: 1.在Vim中可以直接查看文件编码 :set fileencoding 即可显示文件编码格式. 如果 ...
最新文章
- linux下chmod使用
- 什么是面向对象(OOP)
- (转)淘淘商城系列——dubbo监控中心
- 【paper and code】AC-GAN
- Dijkstra求最短路径例题
- React --获取服务器数据的两种方式(Axios和FetchJsonp)
- 阿里云为什么在十三年后重构调度系统?
- 快速排序实验报告 c语言,快速排序算法的C语言实现
- fastapi+tortoise单元测试
- 什么是工程思维和产品思维
- Zigbee应用之搭建开发环境
- 查找/分析Windows蓝屏DMP文件
- 桌面图标变白,任务栏图标变白
- elk报错:[syslogs] index has exceeded [1000000]
- 「真香系列」新物种首发亮相 聚划算爆款孵化玩法升级
- C++实现Win11万年历
- Java Date类获取当前年月日
- 2019纪中集训总结
- java斜椭圆_JAVA 任意椭圆方向画法
- Android系统硬件访问服务框架分析
热门文章
- 怎么做c语言的子程序,哪位师傅知道51单片机怎样编写子程序?C语言的。在主程序里调...
- python xlrd模块_Python中xlrd模块解析
- 2020-06-24 电子书网站http://www.itjiaocheng.com/mianfei/
- Java多线程(三)——多线程实现同步
- kubernetesV1.13.1一键部署脚本(k8s自动部署脚本)
- AIR Android开发--APK结构详解
- 在没有 IIS 的条件下运行 ASMX(WebService)
- cas client 更新ticket_cas sso单点登录系列6_cas单点登录防止登出退出后刷新后退ticket失效报500错...
- 如何用python控制设备实现自动_带你用 Python 实现自动化群控设备
- 如何使用计算机管理来为硬盘分区,电脑如何硬盘分区合理_电脑硬盘分区的基本步骤-win7之家...