solr6.6初探之主从同步
1.关于solr索引数据同步
通常情况下,单节点部署的solr应用很难在并发量很大的情况下"久存",那么多节点部署提高Solr应用的负载量和响应时间势在必行。
solr索引同步有以下特点:
·影响复制的配置由单个文件solrconfig.xml控制
·支持配置文件和索引文件的复制
·跨平台工作,配置相同
·与Solr紧密结合;管理页面提供了对复制各个方面更细粒度控制
·基于java的复制特性作为请求处理程序实现。因此,配置复制类似于任何正常的请求处理程序。
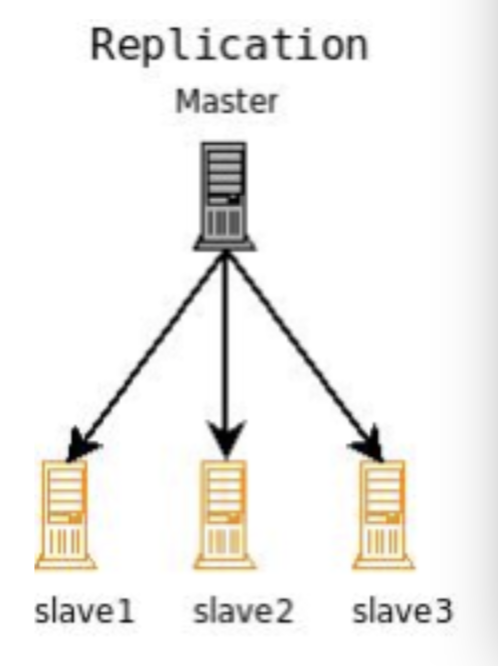 当主节点索引更新时,所变更的数据会拷贝到所有子节点上
当主节点索引更新时,所变更的数据会拷贝到所有子节点上
2.配置ReplicationHandler
在运行主从复制之前,应该设置处理程序初始化的参数:
·replicateAfter :SOLR会自行在以下操作行为发生后执行复制,有效的值为commit, optimize, startup
·backAfter:solr在以下操作后会发生备份,有效的值为commit, optimize, startup
·maxnumberofbackup:一个整数值,决定了该节点在接收备份命令时将保留的最大备份数量。
·maxNumberOfBackups :指定要保留多少备份。这可以用来删除除最近的N个备份。
·commitReserveDuration:如果提交非常频繁并且您的网络速度很慢,可以调整这个参数来保留增量索引的周期时间,默认是10秒
在${core.home}/conf/solrConfig.xml中进行主节点配置实例:
<requestHandler name="/replication" class="solr.ReplicationHandler"><lst name="master"><str name="replicateAfter">commit</str><str name="backupAfter">optimize</str><str name="confFiles">schema.xml,stopwords.txt,elevate.xml</str><str name="commitReserveDuration">00:00:10</str></lst><int name="maxNumberOfBackups">2</int><lst name="invariants"><str name="maxWriteMBPerSec">16</str></lst></requestHandler>
从节点配置:
·masterUrl:主节点的地址,从节点通过replication参数来发送同步指令
·pollInterval:设置抓取间隔时间,用HH:mm:ss的格式设置
·compression 可选值:external,internal(局域网推荐使用此值)
<requestHandler name="/replication" class="solr.ReplicationHandler"><lst name="slave"><!-- fully qualified url for the replication handler of master. It ispossible to pass on this as a request param for the fetchindex command --><str name="masterUrl">http://remote_host:port/solr/core_name/replication</str><!-- Interval in which the slave should poll master. Format is HH:mm:ss .If this is absent slave does not poll automatically.But a fetchindex can be triggered from the admin or the http API --><str name="pollInterval">00:00:20</str><!-- THE FOLLOWING PARAMETERS ARE USUALLY NOT REQUIRED--><!-- To use compression while transferring the index files. The possiblevalues are internal|external. If the value is 'external' make surethat your master Solr has the settings to honor the accept-encoding header.See here for details: http://wiki.apache.org/solr/SolrHttpCompressionIf it is 'internal' everything will be taken care of automatically.USE THIS ONLY IF YOUR BANDWIDTH IS LOW.THIS CAN ACTUALLY SLOWDOWN REPLICATION IN A LAN --><str name="compression">internal</str><!-- The following values are used when the slave connects to the master todownload the index files. Default values implicitly set as 5000ms and10000ms respectively. The user DOES NOT need to specify these unless thebandwidth is extremely low or if there is an extremely high latency --><str name="httpConnTimeout">5000</str><str name="httpReadTimeout">10000</str><!-- If HTTP Basic authentication is enabled on the master, then the slavecan be configured with the following --><str name="httpBasicAuthUser">username</str><str name="httpBasicAuthPassword">password</str></lst></requestHandler>
注意:从节点masterUrl属性应当配置为主节点的地址
3.关于solr主从复制之repeater模式
在上述配置中有一个弊端:
·一主多从模式,主节点存在宕机的风险,那么从节点会群龙无首(solr暂时未提供主节点选举策略)
·从节点很多的情况下,会严重拉低主节点的性能(占有主节点服务器网络资源,占有磁盘I/O,提升CPU占有率等)
solr这里提供了一套机制,就是repeater(中转器模式),简单来说将一定量的solr服务器配置成即是主节点又是从节点的模式:
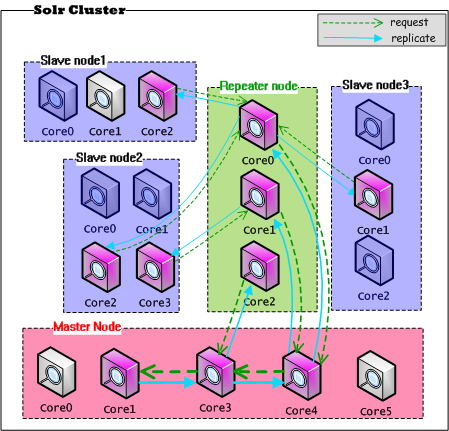
由图我们看到 从节点访问repeater(中转器)即可,因此从而减轻了主节点的压力,也一定程度上了解决单点故障。
配置实例如下:
<requestHandler name="/replication" class="solr.ReplicationHandler"><lst name="master"><str name="replicateAfter">commit</str><str name="confFiles">schema.xml,stopwords.txt,synonyms.txt</str></lst><lst name="slave"><str name="masterUrl">http://master.solr.company.com:8983/solr/core_name/replication</str><str name="pollInterval">00:00:60</str></lst></requestHandler>
从节点的masterUrl属性改成reapter的地址,另外replicateAfter必须设置为commit
solr6.6初探之主从同步相关推荐
- 使用MySQL Proxy解决MySQL主从同步延迟
MySQL的主从同步机制非常方便的解决了高并发读的应用需求,给Web方 面开发带来了极大的便利.但这种方式有个比较大的缺陷在于MySQL的同步机制是依赖Slave主动向Master发请求来获取数据的, ...
- mysql 8.0配置主从同步_MySQL8.0.19开启GTID主从同步CentOS8
前言本次搭建目标为1主2从MySQL主从同步结构.采用CentOS8作为操作系统,IP为[10.0.0.211,10.0.0.212,10.0.0.213].MySQL版本为8.0.19,端口均采用3 ...
- Linux下的redis的持久化,主从同步及哨兵
redis持久化 Redis是一种内存型数据库,一旦服务器进程退出,数据库的数据就会丢失, 为了解决这个问题,Redis提供了两种持久化的方案,将内存中的数据保存到磁盘中,避免数据的丢失. RDB持久 ...
- mysql数据库主从同步过程详述(三)
续mysql数据库主从同步过程详述(二) 在此说明下:在最后试验过程中,当查看从库状态的时候,IO_Running显示为no,从error_log中看到如下报错提示: 120523 0:55:31 ...
- mysql 主从同步不一致_MySQL 主从同步延迟的原因及解决办法
mysql 用主从同步的方法进行读写分离,减轻主服务器的压力的做法现在在业内做的非常普遍. 主从同步基本上能做到实时同步.我从别的网站借用了主从同步的原理图. 在配置好了, 主从同步以后, 主服务器会 ...
- pika主从同步原理
pika主从同步 主要为了分析探索一下pika是如何实现主从同步的,pika的主从同步的原理与redis的同步方案还不相同,本文主要是为了分析其主从同步的相关流程(pika基于3.4版本). pika ...
- 项目性能优化(MySQL读写分离、MySQL主从同步、Django实现MySQL读写分离)
当项目中数据库表越来越多,数据量也逐渐增多时,需要做数据库的安全和性能的优化.对于数据库的优化,可以选择使用MySQL读写分离实现. 1.MySQL主从同步 1.主从同步机制 1.1.主从同步介绍和优 ...
- Mysql主从同步延迟问题及解决方案
主从同步出现的延迟问题原因及解决方案 对于主从正常执行,相应的延迟几乎是不存在的.但是在高QPS下,主从同步却出现了比较明显的延迟情况. _______________________________ ...
- MySQL主从同步问题集
http://blog.chinaunix.net/uid-8786588-id-3771613.html 在InnoDB引擎下发现,Mysql的主从热备存在数据不一致的问题,一些数据没有成功同步到备 ...
最新文章
- Dubbo 稳定性案例:Nacos 注册中心可用性问题复盘
- 医学数据挖掘学习项目:他克莫司
- 流量暴涨擒凶记(转)
- shiro受权时没有走对应的realm的授权解决方案
- 速学c++(1)-c++简介
- Flink1.12.0使用过程中遇到的异常
- 【Python算法】分类与预测——logistic回归分析
- Android开机自动启动程序设置
- KETTLE集群搭建
- 用字符串模拟两个大数的相加
- 0903 - Firebase Analytics PK Google Analytics
- matlab线性回归s和2,数据回归分析和拟合的matlab实现2.doc
- 转载——关于bp神经网络
- 使用selenium + pytest + allure做WBE UI自动化
- oracle 简版客户端instantclient使用 oledb ODAC组件使用
- NPOI iTextSharp导出Excel并加水印
- 在ensp中配置交换机interface GigabitEthernet 1/0/1报错
- 强大的Pidgin,Pidgin的使用
- 【喜讯】PerfMa再获高瓴创投领投1.5亿A++轮融资
- javascript实现下拉列表框模糊查询