python神经网络代码_11行Python代码建立神经网络
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
用11行Python代码写出一个神经网络
通过构造一个裸骨神经网络来解释反向传播的内部工作原理。
概览:对我而言,可以获得乐趣的玩具代码是学编程最有效的方法。这个教程通过一个非常简单又好玩的Python实例讲述反向传播。
补充:很多人询问我文章的后续部分,我也正在计划写下一篇。写完的时候我会在推特(@iamtrask)上面发出来。如果你喜欢这些内容欢迎关注我的推特,并感谢你们所有的反馈信息!
先把代码给出来:

然而,这个代码有点太简洁了……让我们把它分解成几个简单的小部分。
第一部分:迷你玩具神经网络
一个经过反向传播训练的神经网络会尝试用输入信息预测输出信息。输入输出
0010
1111
1011
0110
我们要根据输入里的三栏数据预测输出结果。这个问题的简单解决办法是分析输入和输出值之间的统计关系。如果我们采用这一方法,我们会发现最左边一栏的数据和结果有完美关联。反向传播,在它最简单的形态里,像我们所采用的方法一样分析统计关系并建模。让我们进行到下一步。
两层神经网络:
经过训练后的输出结果:
[[ 0.00966449]
[ 0.00786506]
[ 0.99358898]
[ 0.99211957]]变量定义
X输入的矩阵数据,每一行都是训练案例
y输出的矩阵数据,每一行都是训练案例
l0神经网络第一层,由输入的数据赋值
l1神经网络第二层,也称为隐藏层
syn0权重的第一层,全称是Synapse 0,链接l0层和l1层网络
*元素间的乘法,使相同维度的两个向量间相对应的值一对一地相乘,得到相同维度的最终向量
-元素间的减法,使相同维度的两个向量间相对应的值一对一地相减,得到相同维度的最终向量
x.dot(y)如果x和y是向量,这个变量就是一个点。如果两者都是矩阵,那它就代表矩阵-矩阵相乘。如果其中只有一个是矩阵,那么它就是矩阵和向量相乘
如你在“经过训练后的输出”中可见,这些代码运作正常!在我讲解过程之前,我建议你自己试试这段代码,对于它的运行有一个直观的感受。你应当能在ipython notebook里运行它(如果你别无选择也可以当作脚本运行,但我强烈建议用ipython notebook)。下面是几点要关注的重点:
在第一次迭代和最后一次迭代之后,比较l1的不同。
了解一下”nonlin”函数。就是它给我们输出了一个概率结果。
了解l1_error在迭代时如何改变的。
删除36行试试。秘密调料的关键就在此。
看看第39行。神经网络此前的所有准备都是为了运行这一行。
让我们分行讲解这段代码。
建议:在两个屏幕里把这篇博客打开,这样你可以边看代码边看下面的讲解。我写下面这段的时候就是这么做的。
Line 01:这一行导入numpy,是一个线性代数库。这是我们唯一需要的东西。
Line 04:这是我们的非线性部分。虽然它可以是其他数个函数,我们在这里把非线性部分映射至sigmoid函数。Sigmoid函数把任意值映射为0到1之间的数值。我们用它把数字转化成概率。它还有其他一些吸引人的属性可以用来训练神经网络。
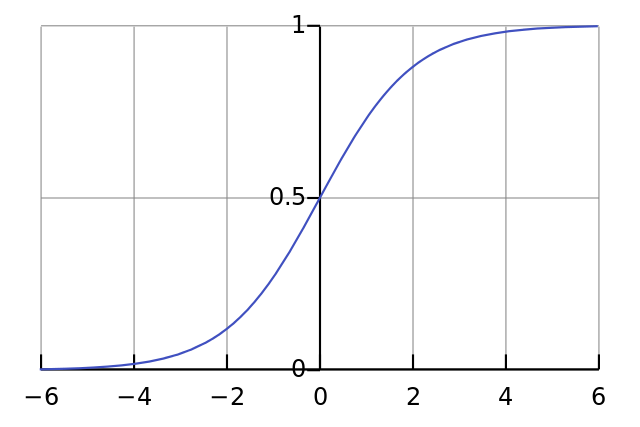
Line 05:注意,这行代码可以生成sigmoid的导数(当deriv=True的情况下)。sigmoid函数其中一个非常有用的特性就是输出可以用于计算导数。如果一个sigmoid函数的输出是”out”,那么它的导数就是out*(1-out)。非常高效。
如果你对导数不熟悉,可以把它当成sigmoid函数某个给定点的斜率(如你可以在上图所见,不同的点有不同的斜率)。如果你想更多地了解导数,可以去可汗学院看看在线课程。
Line 10:这行代码将我们输入的数据初始化为numpy矩阵。每一行都是一个独立的“训练案例”。每一列代表一个输入节点。这样,神经网络就有了3个输入节点和4个训练案例。
Line 16:这行代码初始化我们的输出数据。在这个例子里,我把数据用水平的方式呈现(一行四列)。”.T”是一个转换函数。在转换后,y矩阵变成四行一列。跟我们的输出结果一样,每一行是一个训练案例,每一列(也就是唯一的那一列)是输出节点。所以,我们的神经网络有3个输入和1个输出。
Line 20:用seed函数给出随机数是一个很好的训练。你的函数仍然是随机分布的,但每一次训练中函数都是以同样的方式分布。这可以让你更容易地看出你对神经网络造成的改变。
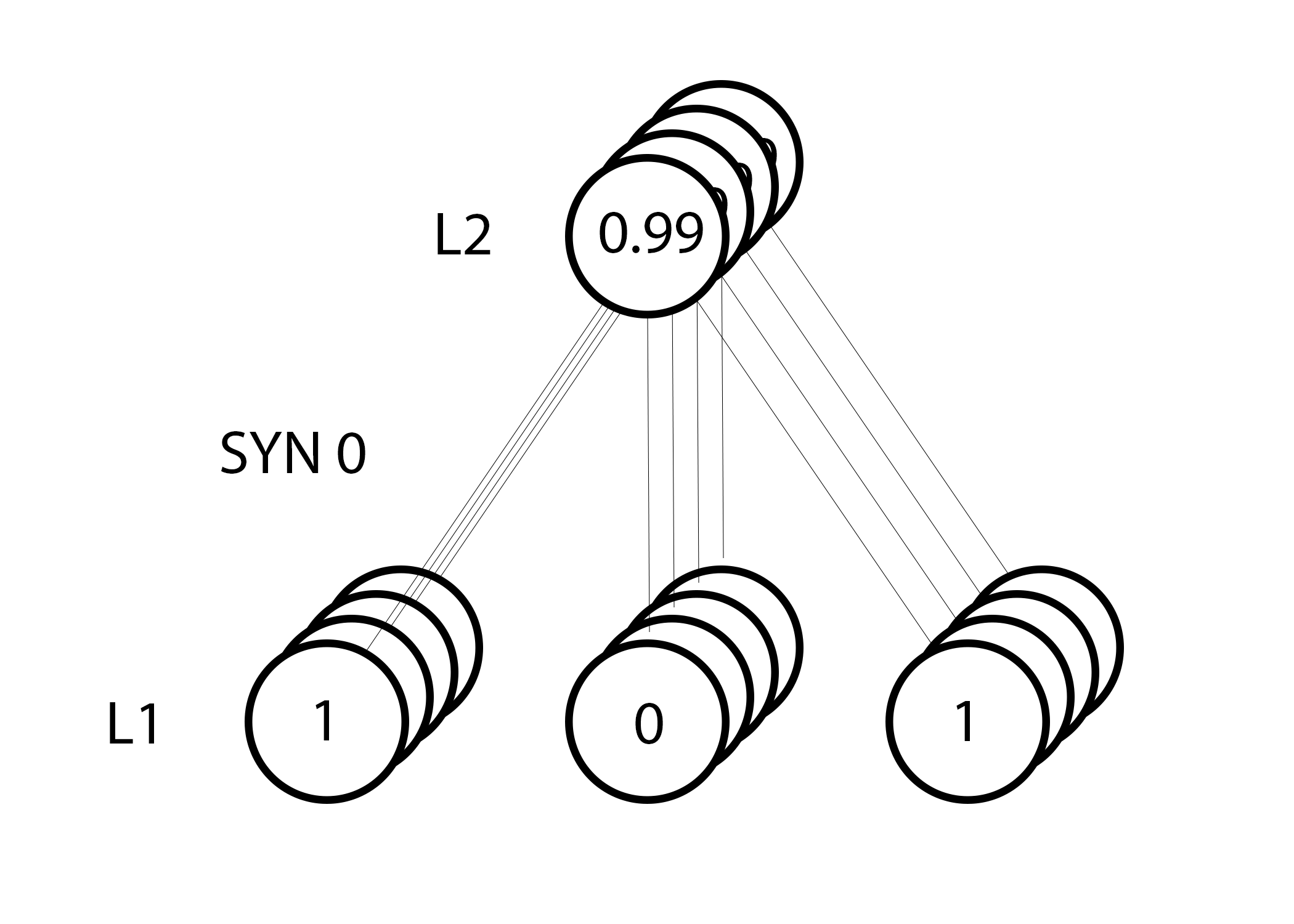
Line 23:这是我们给神经网络的权重矩阵。名字”syn0”代表着”synapse zero”(突触)。我们的神经网络只有两层(输入和输出),所以我们只需要一个权重函数来连接它们。它的维度是(3,1),因为我们给出3个输入值,获得一个输出值。另外一个理解它的方法是:l0的大小是3,而l1的大小是1。我们要把l0的每一个节点连接到l1的每一个节点上,所以需要一个(3,1)的矩阵。
此外还要注意它随机值的平均值是0。解释这个需要用到权重初始化的一些理论知识。目前我们只需要知道在权重初始化的时候把均值设成0是很好的点子。
另外一个注意的地方是所谓的“神经网络”其实只是这个矩阵。我们有“两层网络”分别是l0和l1,但它们都是数据集里面的临时数据。我们并不储存它们。所有的学习结果都储存在syn0矩阵里。
Line 25:这里开始我们的神经网络训练代码。for循环多次迭代训练代码使我们的神经网络对于数据集产生最优的输出。
Line 28:因为我们的第一层网络l0仅是我们的输入数据。在此我们准确地描述它一下。X含有4个训练案例(4行)。我们在这里将把这些数据都一起处理。这样的做法称为批量处理训练(full batch training)。我们有4行不同的l0数据,但你也可以把这所有的四行当成一个训练案例。在这里两种方法没有差别。(如果需要,我们可以在这里加载1000或者10000行数据而不需要改变代码。)
Line 29:这是我们的预测步骤。简单说,我们让神经网络“尝试”地根据输入数据给出输出数据。然后我们分析它的结果,在迭代的时候做出调整,使每次都做得更好一些。
这一行代码包含两个步骤。第一个矩阵用l0乘以syn0。第二步将输出结果用sigmoid函数处理。想一下下面每个矩阵的维度:
(4 x 3) dot (3 x 1) = (4 x 1)
矩阵的相乘是有序的,等式中间的矩阵的维度必须保持一致。最终得出的矩阵维度来自于第一个矩阵的行数和第二个矩阵的列数。
由于我们加载了4个训练案例,最终我们得出4个猜测的答案,一个(4x1)的矩阵。每个输出值都代表神经网络对于一个给定输入值的猜测。这样也许可以更直观地了解为什么我们可以给训练案例“载入”一个随机的数值。矩阵相乘仍然可以进行计算。
Line 32:现在,l1已经对每个输入给出了一个“猜测”。那么我们就可以把正确答案从y中提取出来和l1的猜测数据进行对比,看看神经网络做得如何。l1_error是一个正数或负数的向量,反映预测值和真实值的差距。
Line 36:我们要进入最棒的部分了!这是这段代码的“神秘调料”!在这一行里有很多的信息,所以我们把它分为两个部分讲解。
第一部分:变量

如果l1代表下图中的三个点,那上面这行代码会给出下图中几条直线的斜率。注意对于非常大的数值(绿点 x=2)和非常小的数值(紫点 x= -1)有比较缓的斜率。斜率最大的点是蓝色 x=0处。这个变量至关重要。另外请注意所有的导数都在0和1之间。
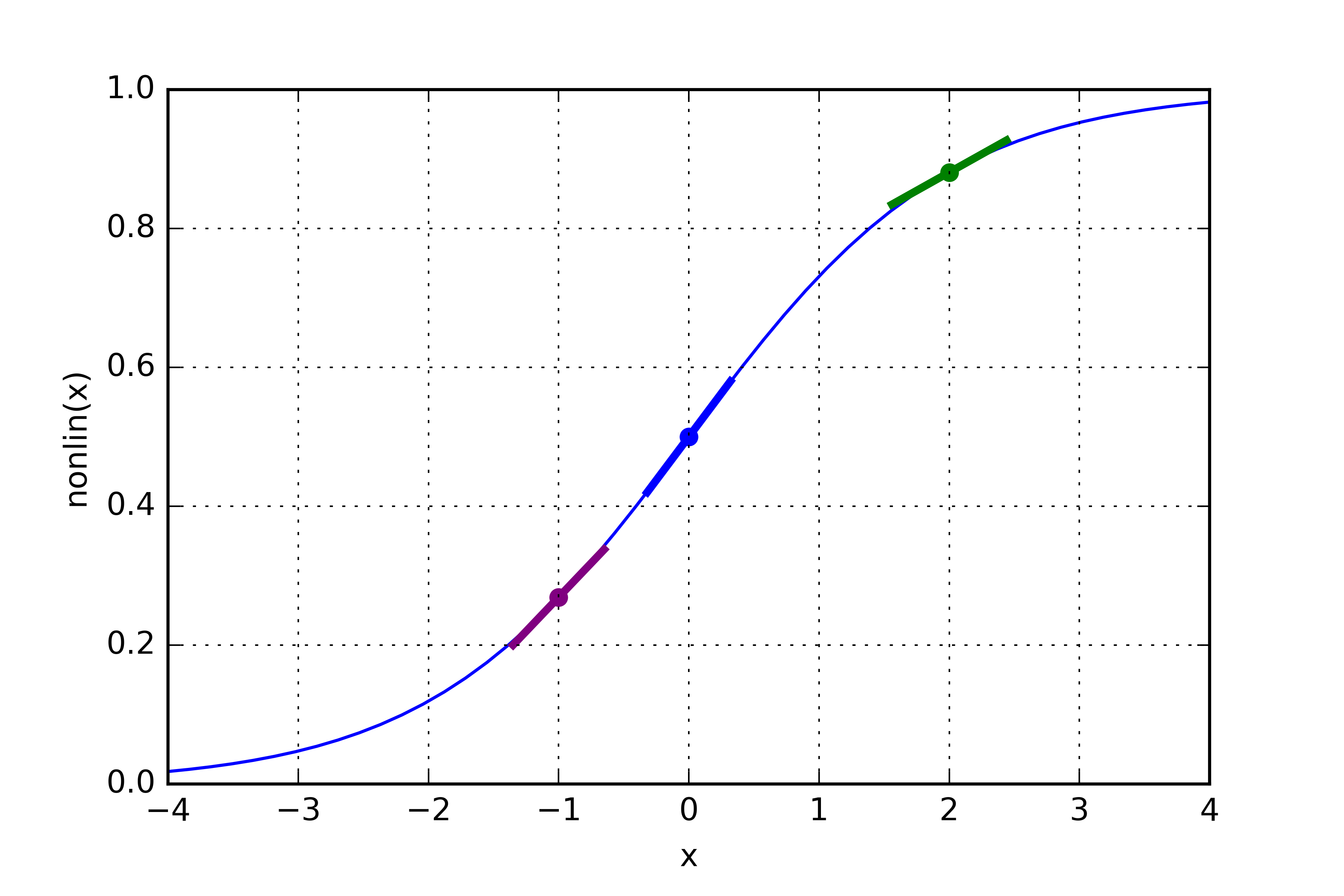
整段代码:误差加权导数

数学上有更多更精确的表述方法,但我认为误差加权导数这个说法最为直观。l1_error是一个(4,1)的矩阵。nonlin(l1,True)返回一个(4,1)的矩阵。我们将两个矩阵逐元素相乘,结果储存在l1_delta的(4,1)矩阵中。
把“斜率”和误差相乘,是在减少高可信度的预测误差。我们再看一下sigmoid图。如果斜率非常缓(趋近于0),那么神经网络的值要么非常大,要么非常小。这说明神经网络对这个结果非常信任。相对地,如果神经网络猜测值介于(0,0.5)的点,那么说明它不是那么地确定。我们会更加着重于处理这些不太确定的预测,把非常可信的预测乘以一个接近0的数来忽略掉它们。
Line 39:我们现在已经准备好更新神经网络了!我们看看单一训练的例子。
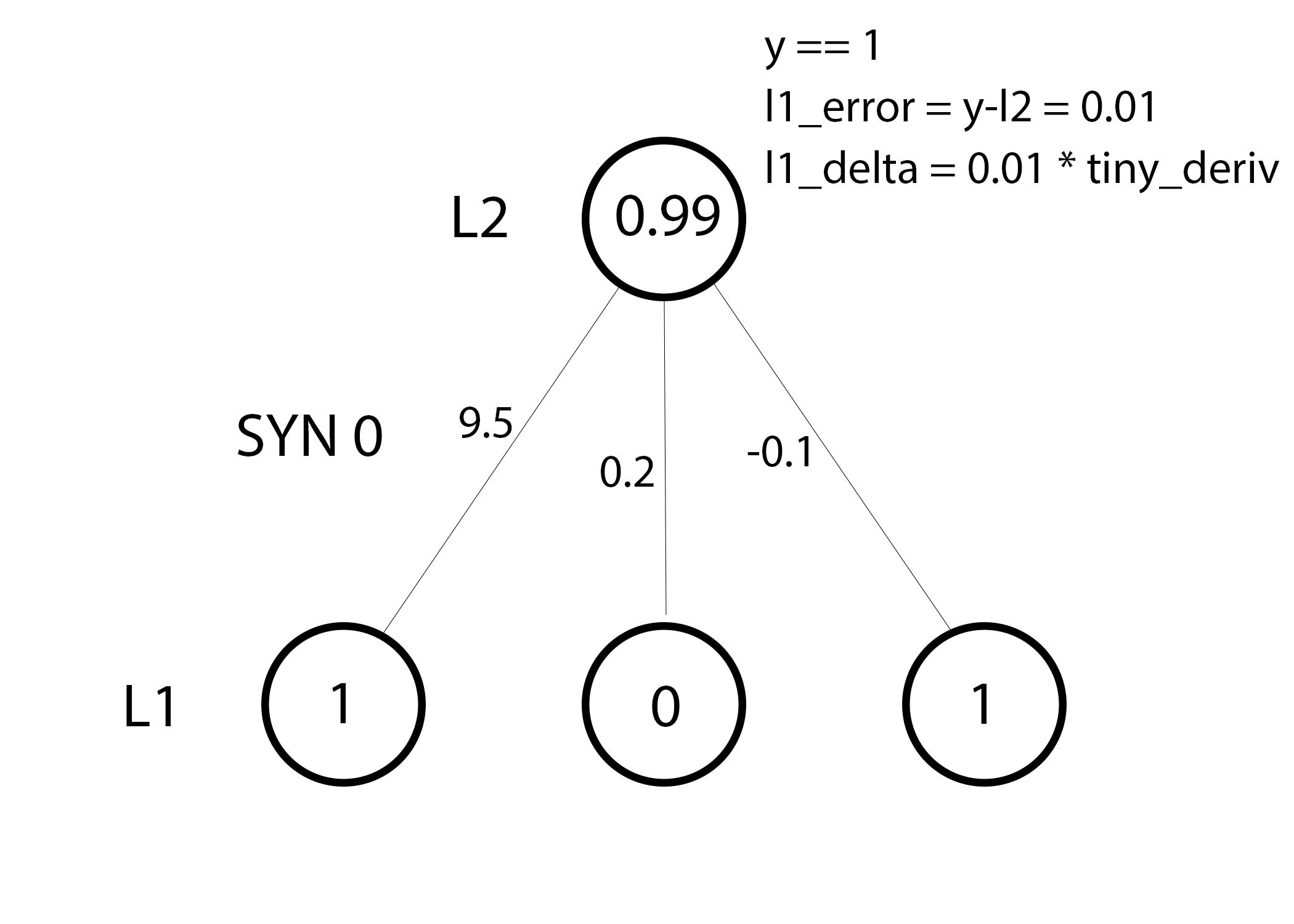
在这一个训练案例里,我们已经准备好更新所有的权重。我们现在把最左边的权重更新为9.5。
weight_update = input_value * l1_delta
对于最左边的权重,上式等于1.0*l1_delta。显然这对于9.5的增加非常微小。为什么我们只用这么小的一个数值?当预测结果的置信度已经非常高,预测结果很大程度上是正确的。一个很小的误差和一个很小的斜率意味着一个非常非常小的更正。考虑到所有的权重,这对于图中三个量都是很小很小的增加。
英文原文:http://iamtrask.github.io/2015/07/12/basic-python-network/
译者:shambala
python神经网络代码_11行Python代码建立神经网络相关推荐
- web python识花_7行Python代码,搭建可以识花的机器学习App|视频教程
你想学Python,却不知如何着手,那你需要一种更加有趣的学习方式. Siraj Raval是一位人工智能领域的编程高手,毕业于哥伦比亚大学,曾任职于 Twilio 和 Meetup,他通过制作教程类 ...
- python100行代码-100行Python代码自动抢火车票!
今年你不妨自己写一段代码来抢回家的火车票,是不是很Cool. 先准备好: 1)12306网站用户名和密码 2)chrome浏览器及下载chromedriver 3)下载Python代码,来自网络整理 ...
- python必背100代码-100行Python代码实现一款高精度免费OCR工具
近期Github开源了一款基于Python开发.名为 Textshot 的截图工具,刚开源不到半个月已经500+Star. 很多人学习python,不知道从何学起. 很多人学习python,掌握了基本 ...
- 遗传算法解决TSP问题 Python实现【160行以内代码】
简述 之前通过遗传算法(Genetic Algorithm )+C++实现解决TSP问题 写了一些基本的原理.并且给出了C++版本代码. 相比于近300行的C++程序,Python只用了160行就解决 ...
- Python实战2 - 200行Python代码实现2048(控制台)
Python实战系列用于记录实战项目中的思路,代码实现,出现的问题与解决方案以及可行的改进方向 本文为第2篇–200行Python代码实现2048 一.分析与函数设计 1.1 游戏玩法 2048这款游 ...
- python200行代码_200行Python代码实现2048
200行Python代码实现2048 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面 ...
- python满天星效果图_50行Python代码绘制满天星
今天用50行Python代码绘制了星空满天的动图.解释下为什么要做这样一件事,因为昨天是青年节,希望通过这样的方式去表达出每个年轻人都像是星空中的一颗星星,散发这自己的光芒照亮整个夜空.效果如下: u ...
- python火车票购买程序代码_100行Python代码实现自动抢火车票(附源码)
前言 又要过年了,今年你不妨自己写一段代码来抢回家的火车票,是不是很Cool.下面话不多说了,来一起看看详细的介绍吧. 先准备好: 12306网站用户名和密码 chrome浏览器及下载chromedr ...
- python自动修图_3 行 Python 代码 5 秒抠图的 AI 神器,根本无需 PS
原标题:3 行 Python 代码 5 秒抠图的 AI 神器,根本无需 PS 文 | 苏克 1900@高级农名工 曾几何时,「抠图」是一个难度系数想当高的活儿,但今天要介绍的这款神工具,只要 3 行代 ...
最新文章
- SAP IQ02 将A序列号改成B序列号后,无修改记录?
- 放大缩小html文字,jquery放大缩小文字
- SonarQube代码质量管理工具安装与使用(sonarqube5.1.2 + sonar-runner-dist-2.4 + MySQL5.x)
- 共享一个简单的 Javacript Helper library
- html下拉列表用ul,Vue.js做select下拉列表的实例(ul-li标签仿select标签)
- 如何在Java中转义JSON字符串-Eclipse IDE技巧
- jmeter之录制控制器与代理的使用
- Linux 文件与目录管理 | 菜鸟笔记收录
- 洛谷P1690 贪婪的Copy 题解
- 深度学习入门笔记(四):神经网络
- HDU 5935 2016CCPC杭州 C: Car
- Android.mk 使用 环境 小结
- keepalived高可用配置注意事项
- android 系统宏定义,Android.mk宏定义demo【转】
- 用JavaScript+HTML实现双色球随机摇号效果
- 2021-05-19 C语言逻辑取反! 学习
- 百度地图api-个性化地图-主题更换
- SQL Server Reporting Services
- scp+oracle备份
- MobaXterm 详细安装使用教程 官网