多元时间序列回归模型_多元时间序列分析和预测:将向量自回归(VAR)模型应用于实际的多元数据集...
多元时间序列回归模型
Multivariate Time Series Analysis
多元时间序列分析
A univariate time series data contains only one single time-dependent variable while a multivariate time series data consists of multiple time-dependent variables. We generally use multivariate time series analysis to model and explain the interesting interdependencies and co-movements among the variables. In the multivariate analysis — the assumption is that the time-dependent variables not only depend on their past values but also show dependency between them. Multivariate time series models leverage the dependencies to provide more reliable and accurate forecasts for a specific given data, though the univariate analysis outperforms multivariate in general[1]. In this article, we apply a multivariate time series method, called Vector Auto Regression (VAR) on a real-world dataset.
单变量时间序列数据仅包含一个时间相关的变量,而多元时间序列数据则包含多个时间相关的变量。 我们通常使用多元时间序列分析来建模和解释变量之间有趣的相互依存关系和共同运动。 在多变量分析中,假定时间相关变量不仅取决于它们的过去值,而且还显示它们之间的依赖关系。 多元时间序列模型利用依存关系为特定的给定数据提供更可靠,更准确的预测,尽管单变量分析通常优于多元变量[1]。 在本文中,我们在现实世界的数据集上应用了一种称为向量自动回归(VAR)的多元时间序列方法。
Vector Auto Regression (VAR)
向量自回归(VAR)
VAR model is a stochastic process that represents a group of time-dependent variables as a linear function of their own past values and the past values of all the other variables in the group.
VAR模型是一个随机过程,将一组时间相关变量表示为它们自己的过去值以及该组中所有其他变量的过去值的线性函数。
For instance, we can consider a bivariate time series analysis that describes a relationship between hourly temperature and wind speed as a function of past values [2]:
例如,我们可以考虑一个双变量时间序列分析,该分析描述了每小时温度和风速之间的关系,该关系是过去值的函数[2]:
temp(t) = a1 + w11* temp(t-1) + w12* wind(t-1) + e1(t-1)
temp(t)= a1 + w11 * temp(t-1)+ w12 * wind(t-1)+ e1(t-1)
wind(t) = a2 + w21* temp(t-1) + w22*wind(t-1) +e2(t-1)
wind(t)= a2 + w21 * temp(t-1)+ w22 * wind(t-1)+ e2(t-1)
where a1 and a2 are constants; w11, w12, w21, and w22 are the coefficients; e1 and e2 are the error terms.
其中a1和a2是常数; w11,w12,w21和w22是系数; e1和e2是误差项。
Dataset
数据集
Statmodels is a python API that allows users to explore data, estimate statistical models, and perform statistical tests [3]. It contains time series data as well. We download a dataset from the API.
Statmodels是python API,允许用户浏览数据,估计统计模型并执行统计测试[3]。 它还包含时间序列数据。 我们从API下载数据集。
To download the data, we have to install some libraries and then load the data:
要下载数据,我们必须安装一些库,然后加载数据:
import pandas as pdimport statsmodels.api as smfrom statsmodels.tsa.api import VARdata = sm.datasets.macrodata.load_pandas().datadata.head(2)The output shows the first two observations of the total dataset:
输出显示了总数据集的前两个观察值:

The data contains a number of time-series data, we take only two time-dependent variables “realgdp” and “realdpi” for experiment purposes and use “year” columns as the index of the data.
数据包含许多时间序列数据,出于实验目的,我们仅采用两个与时间相关的变量“ realgdp”和“ realdpi”,并使用“ year”列作为数据索引。
data1 = data[["realgdp", 'realdpi']]data1.index = data["year"]output:
输出:

Let's visualize the data:
让我们可视化数据:
data1.plot(figsize = (8,5))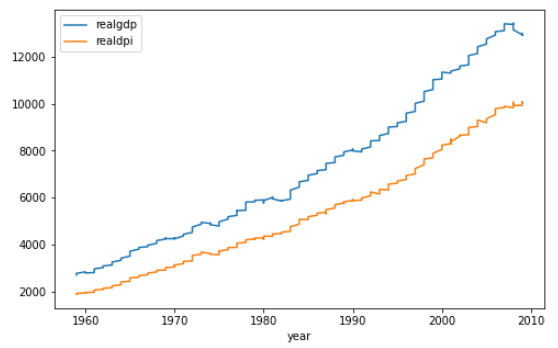
Both of the series show an increasing trend over time with slight ups and downs.
这两个系列都显示出随着时间的推移呈上升趋势,并有轻微的起伏。
Stationary
固定式
Before applying VAR, both the time series variable should be stationary. Both the series are not stationary since both the series do not show constant mean and variance over time. We can also perform a statistical test like the Augmented Dickey-Fuller test (ADF) to find stationarity of the series using the AIC criteria.
应用VAR之前,两个时间序列变量均应为固定值。 两个序列都不是平稳的,因为两个序列都没有显示出恒定的均值和随时间变化。 我们还可以执行统计测试(如增强迪基-富勒检验(ADF)),以使用AIC标准查找系列的平稳性。
adfuller_test = adfuller(data1['realgdp'], autolag= "AIC")print("ADF test statistic: {}".format(adfuller_test[0]))print("p-value: {}".format(adfuller_test[1]))output:
输出:

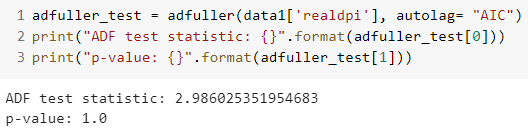
In both cases, the p-value is not significant enough, meaning that we can not reject the null hypothesis and conclude that the series are non-stationary.
在这两种情况下,p值都不足够显着,这意味着我们不能拒绝原假设并得出结论该序列是非平稳的。
Differencing
差异化
As both the series are not stationary, we perform differencing and later check the stationarity.
由于两个系列都不平稳,因此我们进行微分,然后检查平稳性。
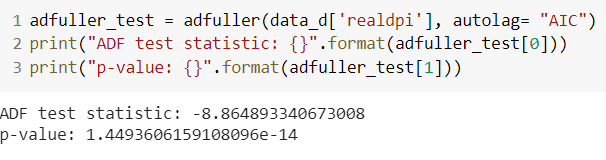
data_d = data1.diff().dropna()The “realgdp” series becomes stationary after first differencing of the original series as the p-value of the test is statistically significant.
由于测试的p值具有统计意义,因此“ realgdp”系列在对原始系列进行第一次求差后将变得平稳。

The “realdpi” series becomes stationary after first differencing of the original series as the p-value of the test is statistically significant.
由于原始的p值在统计上具有显着性,因此“ realdpi”系列在与原始系列进行首次差异化处理后就变得稳定了。
Model
模型
In this section, we apply the VAR model on the one differenced series. We carry-out the train-test split of the data and keep the last 10-days as test data.
在本节中,我们将VAR模型应用于一个差分序列。 我们对数据进行火车测试拆分,并保留最后10天作为测试数据。
train = data_d.iloc[:-10,:]test = data_d.iloc[-10:,:]Searching optimal order of VAR model
搜索VAR模型的最优阶
In the process of VAR modeling, we opt to employ Information Criterion Akaike (AIC) as a model selection criterion to conduct optimal model identification. In simple terms, we select the order (p) of VAR based on the best AIC score. The AIC, in general, penalizes models for being too complex, though the complex models may perform slightly better on some other model selection criterion. Hence, we expect an inflection point in searching the order (p), meaning that, the AIC score should decrease with order (p) gets larger until a certain order and then the score starts increasing. For this, we perform grid-search to investigate the optimal order (p).
在VAR建模过程中,我们选择采用信息准则赤池(AIC)作为模型选择标准来进行最佳模型识别。 简单来说,我们根据最佳AIC得分选择VAR的阶数(p)。 通常,AIC会因过于复杂而对模型进行惩罚,尽管复杂模型在某些其他模型选择标准上可能会稍好一些。 因此,我们期望在搜索阶数(p)时出现拐点,这意味着,随着阶数(p)的增大,AIC分数应减小,直到达到某个阶数,然后分数才开始增加。 为此,我们执行网格搜索以研究最佳阶数(p)。
forecasting_model = VAR(train)results_aic = []for p in range(1,10): results = forecasting_model.fit(p) results_aic.append(results.aic)In the first line of the code: we train VAR model with the training data. Rest of code: perform a for loop to find the AIC scores for fitting order ranging from 1 to 10. We can visualize the results (AIC scores against orders) to better understand the inflection point:
在代码的第一行:我们使用训练数据训练VAR模型。 其余代码:执行for循环以找到适合订单的AIC得分,范围从1到10。我们可以可视化结果(针对订单的AIC得分),以更好地了解拐点:
import seaborn as snssns.set()plt.plot(list(np.arange(1,10,1)), results_aic)plt.xlabel("Order")plt.ylabel("AIC")plt.show()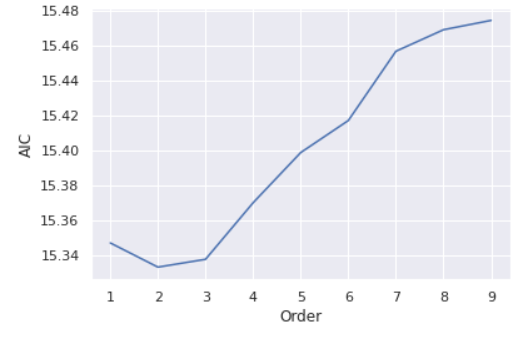
From the plot, the lowest AIC score is achieved at the order of 2 and then the AIC scores show an increasing trend with the order p gets larger. Hence, we select the 2 as the optimal order of the VAR model. Consequently, we fit order 2 to the forecasting model.
从图中可以看到,最低的AIC得分约为2,然后,随着p的增大,AIC得分呈上升趋势。 因此,我们选择2作为VAR模型的最优顺序。 因此,我们将订单2拟合到预测模型。
let's check the summary of the model:
让我们检查一下模型的摘要:
results = forecasting_model.fit(2)results.summary()The summary output contains much information:
摘要输出包含许多信息:

Forecasting
预测
We use 2 as the optimal order in fitting the VAR model. Thus, we take the final 2 steps in the training data for forecasting the immediate next step (i.e., the first day of the test data).
我们使用2作为拟合VAR模型的最佳顺序。 因此,我们在训练数据中采取最后的2个步骤来预测下一步(即测试数据的第一天)。

Now, after fitting the model, we forecast for the test data where the last 2 days of training data set as lagged values and steps set as 10 days as we want to forecast for the next 10 days.
现在,在拟合模型之后,我们预测测试数据,其中训练数据的最后2天设置为滞后值,步长设置为10天,因为我们希望在接下来的10天进行预测。
laaged_values = train.values[-2:]forecast = pd.DataFrame(results.forecast(y= laaged_values, steps=10), index = test.index, columns= ['realgdp_1d', 'realdpi_1d'])forecastThe output:
输出:

We have to note that the aforementioned forecasts are for the one differenced model. Hence, we must reverse the first differenced forecasts into the original forecast values.
我们必须注意,上述预测是针对一种差异模型的。 因此,我们必须将最初的差异预测反转为原始预测值。
forecast["realgdp_forecasted"] = data1["realgdp"].iloc[-10-1] + forecast_1D['realgdp_1d'].cumsum()forecast["realdpi_forecasted"] = data1["realdpi"].iloc[-10-1] + forecast_1D['realdpi_1d'].cumsum() output:
输出:

The first two columns are the forecasted values for 1 differenced series and the last two columns show the forecasted values for the original series.
前两列是1个差异序列的预测值,后两列显示原始序列的预测值。
Now, we visualize the original test values and the forecasted values by VAR.
现在,我们通过VAR可视化原始测试值和预测值。
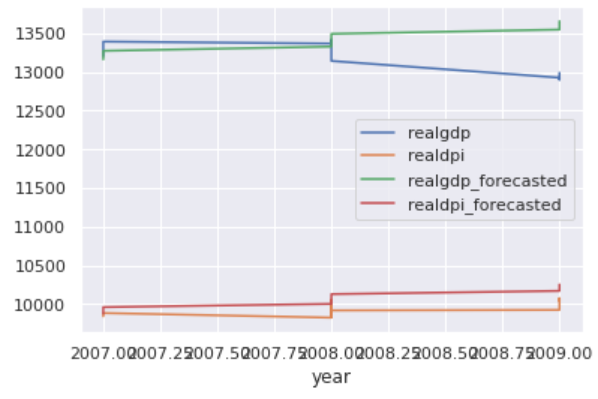
The original realdpi and the forecasted realdpi show a similar pattern throwout the forecasted days. For realgdp: the first half of the forecasted values show a similar pattern as the original values, on the other hand, the last half of the forecasted values do not follow similar pattern.
原始的realdpi和预测的realdpi显示出相似的模式,从而排除了预测的天数。 对于realgdp:预测值的前半部分显示与原始值相似的模式,另一方面,预测值的后半部分没有遵循相似的模式。
To sum up, in this article, we discuss multivariate time series analysis and applied the VAR model on a real-world multivariate time series dataset.
综上所述,在本文中,我们讨论了多元时间序列分析,并将VAR模型应用于实际的多元时间序列数据集。
You can also read the article — A real-world time series data analysis and forecasting, where I applied ARIMA (univariate time series analysis model) to forecast univariate time series data.
您还可以阅读这篇文章- 真实的时间序列数据分析和预测 ,在这里我应用了ARIMA(单变量时间序列分析模型)来预测单变量时间序列数据。
[1] https://homepage.univie.ac.at/robert.kunst/prognos4.pdf
[1] https://homepage.univie.ac.at/robert.kunst/prognos4.pdf
[2] https://www.aptech.com/blog/introduction-to-the-fundamentals-of-time-series-data-and-analysis/
[2] https://www.aptech.com/blog/introduction-to-the-fundamentals-of-time-series-data-and-analysis/
[3] https://www.statsmodels.org/stable/index.html
[3] https://www.statsmodels.org/stable/index.html
翻译自: https://towardsdatascience.com/multivariate-time-series-forecasting-456ace675971
多元时间序列回归模型
http://www.taodudu.cc/news/show-997473.html
相关文章:
- 数据分析和大数据哪个更吃香_处理数据,大数据甚至更大数据的17种策略
- 批梯度下降 随机梯度下降_梯度下降及其变体快速指南
- 生存分析简介:Kaplan-Meier估计器
- 使用r语言做garch模型_使用GARCH估计货币波动率
- 方差偏差权衡_偏差偏差权衡:快速介绍
- 分节符缩写p_p值的缩写是什么?
- 机器学习 预测模型_使用机器学习模型预测心力衰竭的生存时间-第一部分
- Diffie Hellman密钥交换
- linkedin爬虫_您应该在LinkedIn上关注的8个人
- 前置交换机数据交换_我们的数据科学交换所
- 量子相干与量子纠缠_量子分类
- 知识力量_网络分析的力量
- marlin 三角洲_带火花的三角洲湖:什么和为什么?
- eda分析_EDA理论指南
- 简·雅各布斯指数第二部分:测试
- 抑郁症损伤神经细胞吗_使用神经网络探索COVID-19与抑郁症之间的联系
- 如何开始使用任何类型的数据? - 第1部分
- 机器学习图像源代码_使用带有代码的机器学习进行快速房地产图像分类
- COVID-19和世界幸福报告数据告诉我们什么?
- lisp语言是最好的语言_Lisp可能不是数据科学的最佳语言,但是我们仍然可以从中学到什么呢?...
- python pca主成分_超越“经典” PCA:功能主成分分析(FPCA)应用于使用Python的时间序列...
- 大数据平台构建_如何像产品一样构建数据平台
- 时间序列预测 时间因果建模_时间序列建模以预测投资基金的回报
- 贝塞尔修正_贝塞尔修正背后的推理:n-1
- php amazon-s3_推荐亚马逊电影-一种协作方法
- 简述yolo1-yolo3_使用YOLO框架进行对象检测的综合指南-第一部分
- 数据库:存储过程_数据科学过程:摘要
- cnn对网络数据预处理_CNN中的数据预处理和网络构建
- 消解原理推理_什么是推理统计中的Z检验及其工作原理?
- 大学生信息安全_给大学生的信息
多元时间序列回归模型_多元时间序列分析和预测:将向量自回归(VAR)模型应用于实际的多元数据集...相关推荐
- R语言实现向量自回归VAR模型
澳大利亚在2008 - 2009年全球金融危机期间发生了这种情况.政府发布了一揽子刺激计划,其中包括2008年12月的现金支付,恰逢圣诞节支出.因此,零售商报告销售强劲,经济受到刺激,收入增加了. 最 ...
- 【时间序列】最完整的时间序列分析和预测(含实例及代码)
时间序列 在生产和科学研究中,对某一个或者一组变量 进行观察测量,将在一系列时刻所得到的离散数字组成的序列集合,称之为时间序列. pandas生成时间序列 过滤数据 重采样 插值 滑窗 数据平稳性与 ...
- 回归模型分类(自回归AR模型、向量自回归VAR模型等)
- 决策树模型回归可视化分析_【时间序列分析】在论文中用向量自回归(VAR)模型时应注意哪些问题?...
在论文的写作中,向量自回归(VAR)模型是经常用的一个模型,同时它也是多维时间序列模型的最核心内容之一. 首先要清楚,VAR模型主要是考察多个变量之间的动态互动关系,从而解释各种经济冲击对经济变量形成 ...
- Stata广义矩量法GMM面板向量自回归PVAR模型选择、估计、Granger因果检验分析投资、收入和消费数据
最近我们被客户要求撰写关于广义矩量法GMM的研究报告,包括一些图形和统计输出. 摘要 面板向量自回归(VAR)模型在应用研究中的应用越来越多.虽然专门用于估计时间序列VAR模型的程序通常作为标准功能包 ...
- 语言时间序列年月日_R语言系列 时间序列分析
[免责声明:本文用于教学] 时间序列分析 基础操作 数据输入 d <- c(10,15,10,10,12,10,7,7,10,14,8,17,14,18,3,9,11,10,6,12,14,10 ...
- 【2022新书】机器学习在金融时间序列分析与预测中的应用
来源:专知 本文为书籍介绍,建议阅读5分钟 这本书是一个真实世界案例的集合,说明了如何处理具有挑战性和波动的金融时间序列数据,以更好地理解他们的过去行为和对他们的未来运动的可靠预测. 这本书是一个真实 ...
- 【机器学习】交通数据的时间序列分析和预测实战
今天又给大家带来一篇实战案例,本案例旨在运用之前学习的时间序列分析和预测基础理论知识,用一个实际案例数据演示这些方法是如何被应用的. 本文较长,建议收藏!由于篇幅限制,文内精简了部分代码,但不影响阅读 ...
- 《统计学》学习笔记之时间序列分析和预测
鄙人学习笔记 文章目录 时间序列分析和预测 时间序列及其分解 时间序列的描述性分析 时间序列预测的程序 确定时间序列成分 选择预测方法 预测方法的评估 平稳序列的预测 简单平均法 移动平均法 指数平滑 ...
最新文章
- 机器学习入门必读:6种简单实用算法及学习曲线、思维导图
- 大型银行数据中心用户安全管理
- DataTable分页控件设计(适用于Gridview和Repeater)
- LVS的DR工作模型解析
- 快速上手RaphaelJS--RaphaelJS_Starter翻译(二)
- Python 之字典常用方法
- 结尾的单词_22个以“ez”结尾的西语单词,你掌握了吗?
- css 透明叠加_细品CSS(二)
- Language modeling tutorial in torchtext
- dz php表单发送邮件,php 发送邮件
- 用Hough投票做物体检测的3篇文献
- pandas实现分类汇总,查找不重复的一 一对应数据
- AppStore_隐私政策
- Mac版Lync无法登陆问题(登录设置)
- 2016民用安防2.0时代重新起航
- 勾股定理,西方称为毕达哥拉斯定理
- 猿如意|初识CSDN的开发者工具合集
- Google浏览器调试技巧
- java 7 反射_【7】java 反射详解
- python爬取豆瓣电影评论_python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法...