Tips: Disk Performance On FreeBSD
http://www.tagidea.com/reader/SA_Notes
Disk I/O 读写性能:
[9:42am] ~#diskinfo -c /dev/mfid0
/dev/mfid0
512 # sectorsize
598879502336 # mediasize in bytes (558G)
1169686528 # mediasize in sectors
72809 # Cylinders according to firmware.
255 # Heads according to firmware.
63 # Sectors according to firmware.I/O command overhead:
time to read 10MB block 0.747839 sec = 0.037 msec/sector
time to read 20480 sectors 2.280335 sec = 0.111 msec/sector
calculated command overhead = 0.075 msec/sectorDisk 基准性能
[9:43am] ~#diskinfo -t /dev/mfid0
/dev/mfid0
512 # sectorsize
598879502336 # mediasize in bytes (558G)
1169686528 # mediasize in sectors
72809 # Cylinders according to firmware.
255 # Heads according to firmware.
63 # Sectors according to firmware.Seek times:
Full stroke: 250 iter in 1.914729 sec = 7.659 msec
Half stroke: 250 iter in 16.605638 sec = 66.423 msec
Quarter stroke: 500 iter in 16.228270 sec = 32.457 msec
Short forward: 400 iter in 2.160201 sec = 5.401 msec
Short backward: 400 iter in 2.676456 sec = 6.691 msec
Seq outer: 2048 iter in 1.070053 sec = 0.522 msec
Seq inner: 2048 iter in 12.475401 sec = 6.092 msec
Transfer rates:
outside: 102400 kbytes in 1.110726 sec = 92192 kbytes/sec
middle: 102400 kbytes in 0.526613 sec = 194450 kbytes/sec
inside: 102400 kbytes in 1.565801 sec = 65398 kbytes/sec
Quick and Dirty MySQL Performance Troubleshooting
提交: å «æ 18 , 2009, 8:09am CEST 由 tonnyom
Quick and Dirty MySQL Performance Troubleshooting
Author:Jeremy Zawodny
from: his Blog如何快速简单进行MySQL 的Performance Troubleshooting呢,Jeremy提供了以下思路和经验:
一,检查是否是硬件瓶颈
使用工具:top vmstat iostat
top - 看看是什么进程在消耗CPU,如果不是MySQL,那就单独找解决方案(限制使用或者迁移服务).如果是MySQL,可能就需要进一步检查.
vmstat - 查看CPU和内存的使用情况,主要是在峰值时CPU wio的数值.
iostat - 查看磁盘子系统繁忙情况,观察Blk_wrtn/s和Blk_read/s 数值.
二,检查MySQL
需要快速检查并主要关注的是:
1,当前每秒有多少查询量被处理
使用 SHOW PROCESSLIST 命令 或者 SHOW GLOBAL STATUS 查看.
还有可以通过一些工具,比如:
innotopmytop
2,当前有多少客户端连接
3,当前有多少慢查询
打开mysql slow query log 以及配置long_query_time 参数值
4,是否有什么异常日志
打开MySQL’s error log
做完以上步骤之后,接着就分析数据库引擎的状态数据,现在多数都是选择InnoDB,所以查看命令可以用 SHOW ENGINE INNODB.最需要关心的是输出最后几行,一般来说缓冲池的命中率越高越好.
最后Jeremy表示,MySQL 多数故障或者性能下降发生之前,通过定期的执行以上操作,以及完善自身的监控系统,和做好日常状态统计,就可以及时的发现并有针对性的去解决这些问题(比如升级硬件,修复应用BUG,优化MySQL参数等等).
Linux 内核高危漏洞
提交: å «æ 17 , 2009, 4:36am CEST 由 tonnyom

链接:
archives.neohapsis.com/archives/fulldisclosure/2009-08/0174.html
演示代码:
www.securityfocus.com/data/vulnerabilities/exploits/wunderbar_emporium-3.tgz
PS: 流行也有流行的坏处,那就是被大家研究透了,假想FreeBSD 也和Linux 发展一样,恐怕也很难独善其身.
Linux System and Performance Monitoring(总结篇)
提交: å «æ 14 , 2009, 5:39am CEST 由 tonnyom
Linux System and Performance Monitoring(总结篇)
Date: 2009.07.21
Author: Darren Hoch
译: Tonnyom[AT]hotmail.com结束语: 这是该译文的最后一篇,在这篇中,作者提供了一个案例环境,用之前几篇所阐述的理论以及涉及到的工具,对其进行一个整体的系统性能检查.对大家更好理解系统性能监控,进行一次实战演习.
BTW:在中文技术网站上,类似内容的文章,大体是来自该作者06-07年所著论文,此译文是建立在作者为OSCON 2009重写基础上的.所以部分内容可能会存在重复雷同,特此说明下.附录 A: 案例学习 - 性能监控之循序渐进
某一天,一个客户打电话来需要技术帮助,并抱怨平常15秒就可以打开的网页现在需要20分钟才可以打开.
具体系统配置如下:
RedHat Enterprise Linux 3 update 7
Dell 1850 Dual Core Xenon Processors, 2 GB RAM, 75GB 15K Drives
Custom LAMP software stack(译注:Llinux+apache+mysql+php 环境)性能分析之步骤
1. 首先使用vmstat 查看大致的系统性能情况:
# vmstat 1 10
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 249844 19144 18532 1221212 0 0 7 3 22 17 25 8 17 18
0 1 249844 17828 18528 1222696 0 0 40448 8 1384 1138 13 7 65 14
0 1 249844 18004 18528 1222756 0 0 13568 4 623 534 3 4 56 37
2 0 249844 17840 18528 1223200 0 0 35200 0 1285 1017 17 7 56 20
1 0 249844 22488 18528 1218608 0 0 38656 0 1294 1034 17 7 58 18
0 1 249844 21228 18544 1219908 0 0 13696 484 609 559 5 3 54 38
0 1 249844 17752 18544 1223376 0 0 36224 4 1469 1035 10 6 67 17
1 1 249844 17856 18544 1208520 0 0 28724 0 950 941 33 12 49 7
1 0 249844 17748 18544 1222468 0 0 40968 8 1266 1164 17 9 59 16
1 0 249844 17912 18544 1222572 0 0 41344 12 1237 1080 13 8 65 13分析:
1,不会是内存不足导致,因为swapping 始终没变化(si 和 so).尽管空闲内存不多(free),但swpd 也没有变化.
2,CPU 方面也没有太大问题,尽管有一些运行队列(procs r),但处理器还始终有50% 多的idle(CPU id).
3,有太多的上下文切换(cs)以及disk block从RAM中被读入(bo).
4,CPU 还有平均20% 的I/O 等待情况.结论:
从以上总结出,这是一个I/O 瓶颈.2. 然后使用iostat 检查是谁在发出IO 请求:
# iostat -x 1
Linux 2.4.21-40.ELsmp (mail.example.com) 03/26/2007avg-cpu: %user %nice %sys %idle
30.00 0.00 9.33 60.67Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 7929.01 30.34 1180.91 14.23 7929.01 357.84 3964.50 178.92 6.93 0.39 0.03 0.06 6.69
/dev/sda1 2.67 5.46 0.40 1.76 24.62 57.77 12.31 28.88 38.11 0.06 2.78 1.77 0.38
/dev/sda2 0.00 0.30 0.07 0.02 0.57 2.57 0.29 1.28 32.86 0.00 3.81 2.64 0.03
/dev/sda3 7929.01 24.58 1180.44 12.45 7929.01 297.50 3964.50 148.75 6.90 0.32 0.03 0.06 6.68avg-cpu: %user %nice %sys %idle
9.50 0.00 10.68 79.82Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 0.00 1195.24 0.00 0.00 0.00 0.00 0.00 0.00 43.69 3.60 0.99 117.86
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda3 0.00 0.00 1195.24 0.00 0.00 0.00 0.00 0.00 0.00 43.69 3.60 0.99 117.86avg-cpu: %user %nice %sys %idle
9.23 0.00 10.55 79.22Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 0.00 1200.37 0.00 0.00 0.00 0.00 0.00 0.00 41.65 2.12 0.99 112.51
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda3 0.00 0.00 1200.37 0.00 0.00 0.00 0.00 0.00 0.00 41.65 2.12 0.99 112.51分析:
1,看上去只有/dev/sda3 分区很活跃,其他分区都很空闲.
2,差不多有1200 读IOPS,磁盘本身是支持200 IOPS左右(译注:参考之前的IOPS 计算公式).
3,有超过2秒,实际上没有一个读磁盘(rkb/s).这和在vmstat 看到有大量I/O wait是有关系的.
4,大量的read IOPS(r/s)和在vmstat 中大量的上下文是匹配的.这说明很多读操作都是失败的.结论:
从以上总结出,部分应用程序带来的读请求,已经超出了I/O 子系统可处理的范围.3. 使用top 来查找系统最活跃的应用程序
# top -d 1
11:46:11 up 3 days, 19:13, 1 user, load average: 1.72, 1.87, 1.80
176 processes: 174 sleeping, 2 running, 0 zombie, 0 stopped
CPU states: cpu user nice system irq softirq iowait idle
total 12.8% 0.0% 4.6% 0.2% 0.2% 18.7% 63.2%
cpu00 23.3% 0.0% 7.7% 0.0% 0.0% 36.8% 32.0%
cpu01 28.4% 0.0% 10.7% 0.0% 0.0% 38.2% 22.5%
cpu02 0.0% 0.0% 0.0% 0.9% 0.9% 0.0% 98.0%
cpu03 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 100.0%
Mem: 2055244k av, 2032692k used, 22552k free, 0k shrd, 18256k buff
1216212k actv, 513216k in_d, 25520k in_c
Swap: 4192956k av, 249844k used, 3943112k free 1218304k cachedPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14939 mysql 25 0 379M 224M 1117 R 38.2 25.7% 15:17.78 mysqld
4023 root 15 0 2120 972 784 R 2.0 0.3 0:00.06 top
1 root 15 0 2008 688 592 S 0.0 0.2 0:01.30 init
2 root 34 19 0 0 0 S 0.0 0.0 0:22.59 ksoftirqd/0
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
4 root 10 -5 0 0 0 S 0.0 0.0 0:00.05 events/0分析:
1,占用资源最多的好像就是mysql 进程,其他都处于完全idle 状态.
2,在top(wa) 看到的数值,和在vmstat 看到的wio 数值是有关联的.结论:
从以上总结出,似乎就只有mysql 进程在请求资源,因此可以推论它就是导致问题的关键.4. 现在已经确定是mysql 在发出读请求,使用strace 来检查它在读请求什么.
# strace -p 14939
Process 14939 attached - interrupt to quit
read(29, "3123713663371222%42012P/d", 20) = 20
read(29, "ata1/strongmail/log/strongmail-d"..., 399) = 399
_llseek(29, 2877621036, [2877621036], SEEK_SET) = 0
read(29, "112413663371223%42012P/da", 20) = 20
read(29, "ta1/strongmail/log/strongmail-de"..., 400) = 400
_llseek(29, 2877621456, [2877621456], SEEK_SET) = 0
read(29, "112353663371224%42012P/da", 20) = 20
read(29, "ta1/strongmail/log/strongmail-de"..., 396) = 396
_llseek(29, 2877621872, [2877621872], SEEK_SET) = 0
read(29, "112453663371225%42012P/da", 20) = 20
read(29, "ta1/strongmail/log/strongmail-de"..., 404) = 404
_llseek(29, 2877622296, [2877622296], SEEK_SET) = 0
read(29, "3123623663371226%42012P/d", 20) = 20分析:
1,大量的读操作都在不断寻道中,说明mysql 进程产生的是随机IO.
2,看上去似乎是,某一sql 查询导致读操作.结论:
从以上总结出,所有的读IOPS 都是mysql 进程在执行某些读查询时产生的.5. 使用mysqladmin 命令,来查找是哪个慢查询导致的.
# ./mysqladmin -pstrongmail processlist
+----+------+-----------+------------+---------+------+----------+----------------------------------------
| Id | User | Host | db | Command | Time | State | Info
+----+------+-----------+------------+---------+------+----------+----------------------------------------
| 1 | root | localhost | strongmail | Sleep | 10 | |
| 2 | root | localhost | strongmail | Sleep | 8 | |
| 3 | root | localhost | root | Query | 94 | Updating | update `failures` set
`update_datasource`='Y' where database_id='32' and update_datasource='N' and |
| 14 | root | localhost | | Query | 0 | | show processlist分析:
1,MySQL 数据库里,似乎在不断的运行table update查询.
2,基于这个update 查询,数据库是对所有的table 进行索引.结论:
从以上总结出,MySQL里这些update 查询问题,都是在尝试对所有table 进行索引.这些产生的读请求正是导致系统性能下降的原因.后续
把以上这些性能信息移交给了相关开发人员,用于分析他们的PHP 代码.一个开发人员对代码进行了临时性优化.某个查询如果出错了,也最多到100K记录.数据库本身考虑最多存在4百万记录.最后,这个查询不会再给数据库带来负担了.
References
• Ezlot, Phillip – Optimizing Linux Performance, Prentice Hall, Princeton NJ 2005 ISBN – 0131486829
• Johnson, Sandra K., Huizenga, Gerrit – Performance Tuning for Linux Servers, IBM Press, Upper Saddle River NJ 2005 ISBN 013144753X
• Bovet, Daniel Cesati, Marco – Understanding the Linux Kernel, O’Reilly Media, Sebastoppl CA 2006, ISBN 0596005652
• Blum, Richard – Network Performance Open Source Toolkit, Wiley, Indianapolis IN 2003, ISBN 0-471-43301-2
• Understanding Virtual Memory in RedHat 4, Neil Horman, 12/05 [people.redhat.com]
• IBM, Inside the Linux Scheduler, [www.ibm.com]
• Aas, Josh, Understanding the Linux 2.6.8.1 CPU Scheduler, [josh.trancesoftware.com]
• Wieers, Dag, Dstat: Versatile Resource Statistics Tool, [dag.wieers.com]
Linux System and Performance Monitoring(Network篇)
提交: å «æ 13 , 2009, 10:01am CEST 由 tonnyom
Linux System and Performance Monitoring(Network篇)
Date: 2009.07.21
Author: Darren Hoch
译: Tonnyom[AT]hotmail.com8.0 Network 监控介绍
在所有的子系统监控中,网络是最困难的.这主要是由于网络概念很抽象.当监控系统上的网络性能,这有太多因素.这些因素包括了延迟,冲突,拥挤和数据包丢失.
这个章节讨论怎么样检查Ethernet(译注:网卡),IP,TCP的性能.
8.1 Ethernet Configuration Settings(译注:网卡配置的设置)
除非很明确的指定,几乎所有的网卡都是自适应网络速度.当一个网络中有很多不同的网络设备时,会各自采用不同的速率和工作模式.
多数商业网络都运行在100 或 1000BaseTX.使用ethtool 可以确定这个系统是处于那种速率.
以下的例子中,是一个有100BaseTX 网卡的系统,自动协商适应至10BaseTX 的情况.
# ethtool eth0
Settings for eth0:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Advertised auto-negotiation: Yes
Speed: 10Mb/s
Duplex: Half
Port: MII
PHYAD: 32
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: pumbg
Wake-on: d
Current message level: 0x00000007 (7)
Link detected: yes以下示范例子中,如何强制网卡速率调整至100BaseTX:
# ethtool -s eth0 speed 100 duplex full autoneg off
# ethtool eth0
Settings for eth0:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Advertised auto-negotiation: No
Speed: 100Mb/s
Duplex: Full
Port: MII
PHYAD: 32
Transceiver: internal
Auto-negotiation: off
Supports Wake-on: pumbg
Wake-on: d
Current message level: 0x00000007 (7)
Link detected: yes8.2 Monitoring Network Throughput(译注:网络吞吐量监控)
接口之间的同步并不意味着仅仅有带宽问题.重要的是,如何管理并优化,这2台主机之间的交换机,网线,或者路由器.测试网络吞吐量最好的方式就是,在这2个系统之间互相发送数据传输并统计下来,比如延迟和速度.
8.2.0 使用iptraf 查看本地吞吐量
iptraf 工具 [iptraf.seul.org),提供了每个网卡吞吐量的仪表盘.]
#iptraf -d eth0
Figure 1: Monitoring for Network Throughput

从输出中可看到,该系统发送传输率(译注:Outgoing rates)为 61 mbps,这对于100 mbps网络来说,有点慢.
8.2.1 使用netperf 查看终端吞吐量
不同于iptraf 被动的在本地监控流量,netperf 工具可以让管理员,执行更加可控的吞吐量监控.对于确定从客户端工作站到一个高负荷的服务器端(比如file 或web server),它们之间有多少吞吐量是非常有帮助的.netperf 工具运行的是client/server 模式.
完成一个基本可控吞吐量测试,首先netperf server 必须运行在服务器端系统上:
server# netserver
Starting netserver at port 12865
Starting netserver at hostname 0.0.0.0 port 12865 and family AF_UNSPECnetperf 工具可能需要进行多重采样.多数基本测试就是一次标准的吞吐量测试.以下例子就是,一个LAN(译注:局域网) 环境下,从client 上执行一次30秒的TCP 吞吐量采样:
从输出可看出,该网络的吞吐量大致在89 mbps 左右.server(192.168.1.215) 与client 在同一LAN 中.这对于100 mbps网络来说,性能非常好.
client# netperf -H 192.168.1.215 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.230 (192.168.1.230) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec87380 16384 16384 30.02 89.46
从LAN 切换到具备54G(译注:Wireless-G是未来54Mbps无线网联网标准)无线网络路由器中,并在10 英尺范围内测试时.该吞吐量就急剧的下降.在最大就为54 MBits的可能下,笔记本电脑可实现总吞吐量就为14 MBits.
client# netperf -H 192.168.1.215 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.215 (192.168.1.215) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec87380 16384 16384 30.10 14.09
如果在50英尺范围内呢,则进一步会下降至5 MBits.
# netperf -H 192.168.1.215 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.215 (192.168.1.215) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec87380 16384 16384 30.64 5.05
如果从LAN 切换到互联网上,则吞吐量跌至1 Mbits下了.
# netperf -H litemail.org -p 1500 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
litemail.org (72.249.104.148) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec87380 16384 16384 31.58 0.93
最后是一个VPN 连接环境,这是所有网络环境中最槽糕的吞吐量了.
# netperf -H 10.0.1.129 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
10.0.1.129 (10.0.1.129) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec87380 16384 16384 31.99 0.51
另外,netperf 可以帮助测试每秒总计有多少的TCP 请求和响应数.通过建立单一TCP 连接并顺序地发送多个请求/响应(ack 包来回在1个byte 大小).有点类似于RDBMS 程序在执行多个交易或者邮件服务器在同一个连接管道中发送邮件.
以下例子在30 秒的持续时间内,模拟TCP 请求/响应:
client# netperf -t TCP_RR -H 192.168.1.230 -l 30
TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET
to 192.168.1.230 (192.168.1.230) port 0 AF_INET
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec16384 87380 1 1 30.00 4453.80
16384 87380在输出中看出,这个网络支持的处理速率为每秒4453 psh/ack(包大小为1 byte).这其实是理想状态下,因为实际情况时,多数requests(译注:请求),特别是responses(译注:响应),都大于1 byte.
现实情况下,netperf 一般requests 默认使用2K大小,responses 默认使用32K大小:
client# netperf -t TCP_RR -H 192.168.1.230 -l 30 -- -r 2048,32768
TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.230 (192.168.1.230) port 0 AF_INET
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec16384 87380 2048 32768 30.00 222.37
16384 87380这个处理速率减少到了每秒222.
8.2.2 使用iperf 评估网络效率
基于都是需要在2端检查连接情况下,iperf 和netperf 很相似.不同的是,iperf 更深入的通过windows size和QOS 设备来检查TCP/UDP 的效率情况.这个工具,是给需要优化TCP/IP stacks以及测试这些stacks 效率的管理员们量身定做的.
iperf 作为一个二进制程序,可运行在server 或者client 任一模式下.默认使用50001 端口.
首先启动server 端(192.168.1.215):
server# iperf -s -D
Running Iperf Server as a daemon
The Iperf daemon process ID : 3655
------------------------------------------------------------
Server listening on TCP port 5001
TCP window size: 85.3 KByte (default)
------------------------------------------------------------在以下例子里,一个无线网络环境下,其中client 端重复运行iperf,用于测试网络的吞吐量情况.这个环境假定处于被充分利用状态,很多主机都在下载ISO images文件.
首先client 端连接到server 端(192.168.1.215),并在总计60秒时间内,每5秒进行一次带宽测试的采样.
client# iperf -c 192.168.1.215 -t 60 -i 5
------------------------------------------------------------
Client connecting to 192.168.1.215, TCP port 5001
TCP window size: 25.6 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.224.150 port 51978 connected with
192.168.1.215 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0- 5.0 sec 6.22 MBytes 10.4 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 5.0-10.0 sec 6.05 MBytes 10.1 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 10.0-15.0 sec 5.55 MBytes 9.32 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 15.0-20.0 sec 5.19 MBytes 8.70 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 20.0-25.0 sec 4.95 MBytes 8.30 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 25.0-30.0 sec 5.21 MBytes 8.74 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 30.0-35.0 sec 2.55 MBytes 4.29 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 35.0-40.0 sec 5.87 MBytes 9.84 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 40.0-45.0 sec 5.69 MBytes 9.54 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 45.0-50.0 sec 5.64 MBytes 9.46 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 50.0-55.0 sec 4.55 MBytes 7.64 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 55.0-60.0 sec 4.47 MBytes 7.50 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-60.0 sec 61.9 MBytes 8.66 Mbits/sec这台主机的其他网络传输,也会影响到这部分的带宽采样.所以可以看到总计60秒时间内,都在4 - 10 MBits 上下起伏.
除了TCP 测试之外,iperf 的UDP 测试主要是评估包丢失和抖动.
接下来的iperf 测试,是在同样的54Mbit G标准无线网络中.在早期的示范例子中,目前的吞吐量只有9 Mbits.
# iperf -c 192.168.1.215 -b 10M
WARNING: option -b implies udp testing
------------------------------------------------------------
Client connecting to 192.168.1.215, UDP port 5001
Sending 1470 byte datagrams
UDP buffer size: 107 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.224.150 port 33589 connected with 192.168.1.215 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 11.8 MBytes 9.90 Mbits/sec
[ 3] Sent 8420 datagrams
[ 3] Server Report:
[ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams
[ 3] 0.0-10.0 sec 6.50 MBytes 5.45 Mbits/sec 0.480 ms 3784/ 8419 (45%)
[ 3] 0.0-10.0 sec 1 datagrams received out-of-order从输出中可看出,在尝试传输10M 的数据时,实际上只产生了5.45M.却有45% 的包丢失.
8.3 Individual Connections with tcptrace
tcptrace 工具提供了对于某一具体连接里,详细的TCP 相关信息.该工具使用libcap 来分析某一具体TCP sessions.该工具汇报的信息,有时很难在某一TCP stream被发现.这些信息
包括了有:
1,TCP Retransmissions(译注:IP 转播) - 所有数据大小被发送所需的包总额
2,TCP Windows Sizes - 连接速度慢与小的windows sizes 有关
3,Total throughput of the connection - 连接的吞吐量
4,Connection duration - 连接的持续时间8.3.1 案例学习 - 使用tcptrace
tcptrace 工具可能已经在部分Linux 发布版中有安装包了,该文作者通过网站,下载的是源码安装包 [dag.wieers.com] 需要libcap 基于文件输入方式使用.在tcptrace 没有选项的情况下,默认每个唯一的连接过程都将被捕获.
以下例子是,使用libcap 基于输入文件为bigstuff:
# tcptrace bigstuff
1 arg remaining, starting with 'bigstuff'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004146108 packets seen, 145992 TCP packets traced
elapsed wallclock time: 0:00:01.634065, 89413 pkts/sec analyzed
trace file elapsed time: 0:09:20.358860
TCP connection info:
1: 192.168.1.60:pcanywherestat - 192.168.1.102:2571 (a2b) 404> 450 2: 192.168.1.60:3356 - ftp.strongmail.net:21 (c2d) 35> 21 3: 192.168.1.60:3825 - ftp.strongmail.net:65023 (e2f) 5> 4 (complete)
4: 192.168.1.102:1339 - 205.188.8.194:5190 (g2h) 6> 6 5: 192.168.1.102:1490 - cs127.msg.mud.yahoo.com:5050 (i2j) 5> 5 6: py-in-f111.google.com:993 - 192.168.1.102:3785 (k2l) 13> 14上面的输出中,每个连接都有对应的源主机和目的主机.tcptrace 使用-l 和-o 选项可查看某一连接更详细的数据.
以下的结果,就是在bigstuff 文件中,#16 连接的相关统计数据:
# tcptrace -l -o1 bigstuff
1 arg remaining, starting with 'bigstuff'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004146108 packets seen, 145992 TCP packets traced
elapsed wallclock time: 0:00:00.529361, 276008 pkts/sec analyzed
trace file elapsed time: 0:09:20.358860
TCP connection info:
32 TCP connections traced:
TCP connection 1:
host a: 192.168.1.60:pcanywherestat
host b: 192.168.1.102:2571
complete conn: no (SYNs: 0) (FINs: 0)
first packet: Sun Jul 20 15:58:05.472983 2008
last packet: Sun Jul 20 16:00:04.564716 2008
elapsed time: 0:01:59.091733
total packets: 854
filename: bigstuff
a->b: b->a:
total packets: 404 total packets: 450
ack pkts sent: 404 ack pkts sent: 450
pure acks sent: 13 pure acks sent: 320
sack pkts sent: 0 sack pkts sent: 0
dsack pkts sent: 0 dsack pkts sent: 0
max sack blks/ack: 0 max sack blks/ack: 0
unique bytes sent: 52608 unique bytes sent: 10624
actual data pkts: 391 actual data pkts: 130
actual data bytes: 52608 actual data bytes: 10624
rexmt data pkts: 0 rexmt data pkts: 0
rexmt data bytes: 0 rexmt data bytes: 0
zwnd probe pkts: 0 zwnd probe pkts: 0
zwnd probe bytes: 0 zwnd probe bytes: 0
outoforder pkts: 0 outoforder pkts: 0
pushed data pkts: 391 pushed data pkts: 130
SYN/FIN pkts sent: 0/0 SYN/FIN pkts sent: 0/0
urgent data pkts: 0 pkts urgent data pkts: 0 pkts
urgent data bytes: 0 bytes urgent data bytes: 0 bytes
mss requested: 0 bytes mss requested: 0 bytes
max segm size: 560 bytes max segm size: 176 bytes
min segm size: 48 bytes min segm size: 80 bytes
avg segm size: 134 bytes avg segm size: 81 bytes
max win adv: 19584 bytes max win adv: 65535 bytes
min win adv: 19584 bytes min win adv: 64287 bytes
zero win adv: 0 times zero win adv: 0 times
avg win adv: 19584 bytes avg win adv: 64949 bytes
initial window: 160 bytes initial window: 0 bytes
initial window: 2 pkts initial window: 0 pkts
ttl stream length: NA ttl stream length: NA
missed data: NA missed data: NA
truncated data: 36186 bytes truncated data: 5164 bytes
truncated packets: 391 pkts truncated packets: 130 pkts
data xmit time: 119.092 secs data xmit time: 116.954 secs
idletime max: 441267.1 ms idletime max: 441506.3 ms
throughput: 442 Bps throughput: 89 Bps8.3.2 案例学习 - 计算转播率
几乎不可能确定说哪个连接会有严重不足的转播问题,只是需要分析,使用tcptrace 工具可以通过过滤机制和布尔表达式来找出出问题的连接.一个很繁忙的网络中,会有很多的连接,几乎所有的连接都会有转播.找出其中最多的一个,这就是问题的关键.
下面的例子里,tcptrace 将找出那些转播大于100 segments(译注:分段数)的连接:
# tcptrace -f'rexmit_segs>100' bigstuff
Output filter: ((c_rexmit_segs>100)OR(s_rexmit_segs>100))
1 arg remaining, starting with 'bigstuff'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004146108 packets seen, 145992 TCP packets traced
elapsed wallclock time: 0:00:00.687788, 212431 pkts/sec analyzed
trace file elapsed time: 0:09:20.358860
TCP connection info:
16: ftp.strongmail.net:65014 - 192.168.1.60:2158 (ae2af) 18695> 9817在这个输出中,是#16 这个连接里,超过了100 转播.现在,使用以下命令查看关于这个连接的其他信息:
# tcptrace -l -o16 bigstuff
arg remaining, starting with 'bigstuff'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004146108 packets seen, 145992 TCP packets traced
elapsed wallclock time: 0:00:01.355964, 107752 pkts/sec analyzed
trace file elapsed time: 0:09:20.358860
TCP connection info:
32 TCP connections traced:
================================
TCP connection 16:
host ae: ftp.strongmail.net:65014
host af: 192.168.1.60:2158
complete conn: no (SYNs: 0) (FINs: 1)
first packet: Sun Jul 20 16:04:33.257606 2008
last packet: Sun Jul 20 16:07:22.317987 2008
elapsed time: 0:02:49.060381
total packets: 28512
filename: bigstuff
ae->af: af->ae:unique bytes sent: 25534744 unique bytes sent: 0
actual data pkts: 18695 actual data pkts: 0
actual data bytes: 25556632 actual data bytes: 0
rexmt data pkts: 1605 rexmt data pkts: 0
rexmt data bytes: 2188780 rexmt data bytes: 0计算转播率:
rexmt/actual * 100 = Retransmission rate1605/18695* 100 = 8.5%
这个慢连接的原因,就是因为它有8.5% 的转播率.
8.3.3 案例学习 - 计算转播时间
tcptrace 工具有一系列的模块展示不同的数据,按照属性,其中就有protocol(译注:协议),port(译注:端口),time等等.Slice module使得你可观察在一段时间内的TCP 性能.你可以在一系列的转发过程中,查看其他性能数据,以确定找出瓶颈.
以下例子示范了,tcptrace 是怎样使用slice 模式的:
# tcptrace –xslice bigfile
以上命令会创建一个slice.dat 文件在现在的工作目录中.这个文件内容,包含是每15秒间隔内转播的相关信息:
# ls -l slice.dat
-rw-r--r-- 1 root root 3430 Jul 10 22:50 slice.dat
# more slice.dat
date segs bytes rexsegs rexbytes new active
--------------- -------- -------- -------- -------- -------- --------
22:19:41.913288 46 5672 0 0 1 1
22:19:56.913288 131 25688 0 0 0 1
22:20:11.913288 0 0 0 0 0 0
22:20:26.913288 5975 4871128 0 0 0 1
22:20:41.913288 31049 25307256 0 0 0 1
22:20:56.913288 23077 19123956 40 59452 0 1
22:21:11.913288 26357 21624373 5 7500 0 1
22:21:26.913288 20975 17248491 3 4500 12 13
22:21:41.913288 24234 19849503 10 15000 3 5
22:21:56.913288 27090 22269230 36 53999 0 2
22:22:11.913288 22295 18315923 9 12856 0 2
22:22:26.913288 8858 7304603 3 4500 0 18.4 结论
监控网络性能由以下几个部分组成:
1,检查并确定所有网卡都工作在正确的速率.
2,检查每块网卡的吞吐量,并确认其处于服务时的网络速度.
3,监控网络流量的类型,并确定适当的流量优先级策略.
Linux System and Performance Monitoring(I/O篇)
提交: å «æ 12 , 2009, 9:40am CEST 由 tonnyom
Linux System and Performance Monitoring(I/O篇)
Date: 2009.07.21
Author: Darren Hoch
译: Tonnyom[AT]hotmail.com6.0 I/O 监控介绍
磁盘I/O 子系统是Linux 系统中最慢的部分.这个主要是归于CPU到物理操作磁盘之间距离(译注:盘片旋转以及寻道).如果拿读取磁盘和内存的时间作比较就是分钟级到秒级,这就像 7天和7分钟的区别.因此本质上,Linux 内核就是要最低程度的降低I/O 数.本章将诉述内核在磁盘和内存之间处理数据的这个过程中,哪些地方会产生I/O.
6.1 读和写数据 - 内存页
Linux 内核将硬盘I/O 进行分页,多数Linux 系统的默认页大小为4K.读和写磁盘块进出到内存都为4K 页大小.你可以使用time 这个命令加-v 参数,来检查你系统中设置的页大小:
# /usr/bin/time -v date
<snip>
Page size (bytes): 4096
<snip>6.2 Major and Minor Page Faults(译注:主要页错误和次要页错误)
Linux,类似多数的UNIX 系统,使用一个虚拟内存层来映射硬件地址空间.当一个进程被启动,内核先扫描CPU caches和物理内存.如果进程需要的数据在这2个地方都没找到,就需要从磁盘上读取,此时内核过程就是major page fault(MPF).MPF 要求磁盘子系统检索页并缓存进RAM.
一旦内存页被映射进内存的buffer cache(buff)中,内核将尝试从内存中读取或写入,此时内核过程就是minor page fault(MnPF).与在磁盘上操作相比,MnPF 通过反复使用内存中的内存页就大大的缩短了内核时间.
以下的例子,使用time 命令验证了,当进程启动后,MPF 和 MnPF 的变化情况.第一次运行进程,MPF 会更多:
# /usr/bin/time -v evolution
<snip>
Major (requiring I/O) page faults: 163
Minor (reclaiming a frame) page faults: 5918
<snip>第二次再运行时,内核已经不需要进行MPF了,因为进程所需的数据已经在内存中:
# /usr/bin/time -v evolution
<snip>
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 5581
<snip>6.3 The File Buffer Cache(译注:文件缓存区)
文件缓存区就是指,内核将MPF 过程最小化,MnPF 过程最大化.随着系统不断的产生I/O,buffer cache也将不断的增加.直到内存不够,以及系统需要释放老的内存页去给其他用户进程使用时,系统就会丢弃这些内存页.结果是,很多sa(译注:系统管 理员)对系统中过少的free memory(译注:空闲内存)表示担心,实际上这是系统更高效的在使用caches.
以下例子,是查看/proc/meminfo 文件:
# cat /proc/meminfo
MemTotal: 2075672 kB
MemFree: 52528 kB
Buffers: 24596 kB
Cached: 1766844 kB
<snip>可以看出,这个系统总计有2GB (Memtotal)的可用内存.当前的空闲内存为52MB (MemFree),有24 MB内存被分配磁盘写操作(Buffers),还有1.7 GB页用于读磁盘(Cached).
内核这样是通过MnPF机制,而不代表所有的页都是来自磁盘.通过以上部分,我们不可能确认系统是否处于瓶颈中.
6.4 Type of Memory Pages
在Linux 内核中,memory pages有3种,分别是:
1,Read Pages - 这些页通过MPF 从磁盘中读入,而且是只读.这些页存在于Buffer Cache中以及包括不能够修改的静态文件,二进制文件,还有库文件.当内核需要它们时,将读取到内存中.如果内存不足,内核将释放它们回空闲列表中.程 序再次请求时,则通过MPF 再次读回内存.
2,Dirty Pages - 这些页是内核在内存中已经被修改过的数据页.当这些页需要同步回磁盘上,由pdflush 负责写回磁盘.如果内存不足,kswapd (与pdflush 一起)将这些页写回到磁盘上并释放更多的内存.
3,Anonymous Pages - 这些页属于某个进程,但是没有任何磁盘文件和它们有关.他们不能和同步回磁盘.如果内存不足,kswapd 将他们写入swap 分区上并释放更多的内存("swapping" pages).
6.5 Writing Data Pages Back to Disk
应用程序有很多选择可以写脏页回磁盘上,可通过I/O 调度器使用 fsync() 或 sync() 这样的系统函数来实现立即写回.如果应用程序没有调用以上函数,pdflush 进程会定期与磁盘进行同步.
# ps -ef | grep pdflush
root 186 6 0 18:04 ? 00:00:00 [pdflush]7.0 监控 I/O
当觉得系统中出现了I/O 瓶颈时,可以使用标准的监控软件来查找原因.这些工具包括了top,vmstat,iostat,sar.它们的输出结果一小部分是很相似,不过每个也都提供了各自对于性能不同方面的解释.以下章节就将讨论哪些情况会导致I/O 瓶颈的出现.
7.1 Calculating IO's Per Second(译注:IOPS 的计算)
每个I/O 请求到磁盘都需要若干时间.主要是因为磁盘的盘边必须旋转,机头必须寻道.磁盘的旋转常常被称为"rotational delay"(RD),机头的移动称为"disk seek"(DS).一个I/O 请求所需的时间计算就是DS加上RD.磁盘的RD 基于设备自身RPM 单位值(译注:RPM 是Revolutions Perminute的缩写,是转/每分钟,代表了硬盘的转速).一个RD 就是一个盘片旋转的
半圆.如何计算一个10K RPM设备的RD 值呢:
1, 10000 RPM / 60 seconds (10000/60 = 166 RPS)
2, 转换为 166分之1 的值(1/166 = 0.006 seconds/Rotation)
3, 单位转换为毫秒(6 MS/Rotation)
4, 旋转半圆的时间(6/2 = 3MS) 也就是 RD
5, 加上平均3 MS 的寻道时间 (3MS + 3MS = 6MS)
6, 加上2MS 的延迟(6MS + 2MS = 8MS)
7, 1000 MS / 8 MS (1000/8 = 125 IOPS)每次应用程序产生一个I/O,在10K RPM磁盘上都要花费平均 8MS.在这个固定时间里,磁盘将尽可能且有效率在进行读写磁盘.IOPS 可以计算出大致的I/O 请求数,10K RPM 磁盘有能力提供120-150 次IOPS.评估IOPS 的效能,可用每秒读写I/O 字节数除以每秒读写IOPS 数得出.
7.2 Random vs Sequential I/O(译注:随机/顺序 I/O)
per I/O产生的KB 字节数是与系统本身workload相关的,有2种不同workload的类型,它们是sequential和random.
7.2.1 Sequential I/O(译注:顺序IO)
iostat 命令提供信息包括IOPS 和每个I/O 数据处理的总额.可使用iostat -x 查看.顺序的workload是同时读顺序请求大量的数据.这包括的应用,比如有商业数据库(database)在执行大量的查询和流媒体服务.在这个 workload 中,KB per I/O 的比率应该是很高的.Sequential workload 是可以同时很快的移动大量数据.如果每个I/O 都节省了时间,那就意味了能带来更多的数据处理.
# iostat -x 1
avg-cpu: %user %nice %sys %idle
0.00 0.00 57.1 4 42.86Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 12891.43 0.00 105.71 0.00 1 06080.00 0.00 53040.00 1003.46 1099.43 3442.43 26.49 280.00
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 12857.14 0.00 5.71 0.00 105782.86 0.00 52891.43 18512.00 559.14 780.00 490.00 280.00
/dev/sda3 0.00 34.29 0.00 100.00 0.00 297.14 0.00 148.57 2.97 540.29 594.57 24.00 240.00avg-cpu: %user %nice %sys %idle
0.00 0.00 23.53 76.47Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 17320.59 0.00 102.94 0.00 142305.88 0.00 71152.94 1382.40 6975.29 952.29 28.57 294.12
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 16844.12 0.00 102.94 0.00 138352.94 0.00 69176.47 1344.00 6809.71 952.29 28.57 294.12
/dev/sda3 0.00 476.47 0.00 0.00 0.00 952.94 0.00 1976.47 0.00 165.59 0.00 0.00 276.47评估IOPS 的效能,可用每秒读写I/O 字节数除以每秒读写IOPS 数得出,比如
rkB/s 除以 r/s
wkB/s 除以 w/s53040/105 = 505KB per I/O
71152/102 = 697KB per I/O
在上面例子可看出,每次循环下,/dev/sda 的per I/O 都在增加.7.2.2 Random I/O(译注:随机IO)
Random的worklaod环境下,不依赖于数据大小的多少,更多依赖的是磁盘的IOPS 数.Web和Mail 服务就是典型的Random workload.I/O 请求内容都很小.Random workload是同时每秒会有更多的请求数产生.所以,磁盘的IOPS 数是关键.
# iostat -x 1
avg-cpu: %user %nice %sys %idle
2.04 0.00 97.96 0.00Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 633.67 3.06 102.31 24.49 5281.63 12.24 2640.82 288.89 73.67 113.89 27.22 50.00
/dev/sda1 0.00 5.10 0.00 2.04 0.00 57.14 0.00 28.57 28.00 1.12 55.00 55.00 11.22
/dev/sda2 0.00 628.57 3.06 100.27 24.49 5224.49 12.24 2612.24 321.50 72.55 121.25 30.63 50.00
/dev/sda3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00avg-cpu: %user %nice %sys %idle
2.15 0.00 97.85 0.00Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 41.94 6.45 130.98 51.61 352.69 25.81 3176.34 19.79 2.90 286.32 7.37 15.05
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 41.94 4.30 130.98 34.41 352.69 17.20 3176.34 21.18 2.90 320.00 8.24 15.05
/dev/sda3 0.00 0.00 2.15 0.00 17.20 0.00 8.60 0.00 8.00 0.00 0.00 0.00 0.00计算方式和之前的公式一致:
2640/102 = 23KB per I/O
3176/130 = 24KB per I/O(译注:对于顺序I/O来说,主要是考虑读取大量数据的能力即KB per request.对于随机I/O系统,更需要考虑的是IOPS值)
7.3 When Virtual Memory Kills I/O
如果系统没有足够的RAM 响应所有的请求,就会使用到SWAP device.就像使用文件系统I/O,使用SWAP device 代价也很大.如果系统已经没有物理内存可用,那就都在SWAP disk上创建很多很多的内存分页,如果同一文件系统的数据都在尝试访问SWAP device,那系统将遇到I/O 瓶颈.最终导致系统性能的全面崩溃.如果内存页不能够及时读或写磁盘,它们就一直保留在RAM中.如果保留时间太久,内核又必须释放内存空间.问题来 了,I/O 操作都被阻塞住了,什么都没做就被结束了,不可避免地就出现kernel panic和system crash.
下面的vmstat 示范了一个内存不足情况下的系统:
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
17 0 1250 3248 45820 1488472 30 132 992 0 2437 7657 23 50 0 23
11 0 1376 3256 45820 1488888 57 245 416 0 2391 7173 10 90 0 0
12 0 1582 1688 45828 1490228 63 131 1348 76 2432 7315 10 90 0 10
12 2 3981 1848 45468 1489824 185 56 2300 68 2478 9149 15 12 0 73
14 2 10385 2400 44484 1489732 0 87 1112 20 2515 11620 0 12 0 88
14 2 12671 2280 43644 1488816 76 51 1812 204 2546 11407 20 45 0 35这个结果可看出,大量的读请求回内存(bi),导致了空闲内存在不断的减少(free).这就使得系统写入swap device的块数目(so)和swap 空间(swpd)在不断增加.同时看到CPU WIO time(wa)百分比很大.这表明I/O 请求已经导致CPU 开始效率低下.
要看swaping 对磁盘的影响,可使用iostat 检查swap 分区
# iostat -x 1
avg-cpu: %user %nice %sys %idle
0.00 0.00 100.00 0.00Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 1766.67 4866.67 1700.00 38933.33 31200.00 19466.67 15600.00 10.68 6526.67 100.56 5.08 3333.33
/dev/sda1 0.00 933.33 0.00 0.00 0.00 7733.33 0.00 3866.67 0.00 20.00 2145.07 7.37 200.00
/dev/sda2 0.00 0.00 4833.33 0.00 38666.67 533.33 19333.33 266.67 8.11 373.33 8.07 6.90 87.00
/dev/sda3 0.00 833.33 33.33 1700.00 266.67 22933.33 133.33 11466.67 13.38 6133.33 358.46 11.35 1966.67在这个例子中,swap device(/dev/sda1) 和 file system device(/dev/sda3)在互相作用于I/O. 其中任一个会有很高写请求(w/s),也会有很高wait time(await),或者较低的服务时间比率(svctm).这表明2个分区之间互有联系,互有影响.
7.4 结论
I/O 性能监控包含了以下几点:
1,当CPU 有等待I/O 情况时,那说明磁盘处于超负荷状态.
2,计算你的磁盘能够承受多大的IOPS 数.
3,确定你的应用是属于随机或者顺序读取磁盘.
4,监控磁盘慢需要比较wait time(await) 和 service time(svctm).
5,监控swap 和系统分区,要确保virtual memory不是文件系统I/O 的瓶颈.
Linux System and Performance Monitoring(Memory篇)
提交: å «æ 11 , 2009, 8:59am CEST 由 tonnyom
Linux System and Performance Monitoring(Memory篇)
Date: 2009.07.21
Author: Darren Hoch
译: Tonnyom[AT]hotmail.com5.0 Virtual Memory介绍
虚拟内存就是采用硬盘对物理内存进行扩展,所以对可用内存的增加是要相对在一个有效范围内的.内核会写当前未使用内存块的内容到硬盘上,此时这部分 内存被用于其它用途.当再一次需要原始内容时,此时再读回到内存中.这对于用户来说,是完全透明的;在Linux 下运行的程序能够看到,也仅仅是大量的可用内存,同时也不会留意到,偶尔还有部分是驻留在磁盘上的.当然,在硬盘上进行读和写,都是很慢的(大约会慢上千 倍),相对于使用真实内存的话,因此程序无法运行的更快.用硬盘的一部分作为Virtual Memory,这就被称为"swap space"(译注:交换空间).
5.1 Virtual Memory Pages
虚拟内存被分为很多 pages(译注:页),在X86架构中,每个虚拟内存页为 4KB.当内核写内存到磁盘或者读磁盘到内存,这就是一次写内存到页的过程.内核通常是在swap 分区和文件系统之间进行这样的操作.
5.2 Kernel Memory Paging
内存分页在正常情况下总是活跃的,与memory swapping(译注:内存交换)之间不要搞错了.内存分页是指内核会定期将内存中的数据同步到硬盘,这个过程就是Memory Paging.日复一日,应用最终将会消耗掉所有的内存空间.考虑到这点,内核就必须经常扫描内存空间并且收回其中未被使用的内存页,然后再重新分配内存 空间给其他应用使用.
5.3 The Page Frame Reclaim Algorithm(PFRA)(译注:页框回收算法)
PFRA 就是OS 内核用来回收并释放内存空间的算法.PFRA 选择哪个内存页被释放是基于内存页类型的.页类型有以下几种:
Unreclaimable –锁定的,内核保留的页面
Swappable –匿名的内存页
Syncable –通过硬盘文件备份的内存页
Discardable –静态页和被丢弃的页除了第一种(Unreclaimable)之外其余的都可以被PFRA进行回收.
与PFRA 相关的,还包括kswapd 内核线程以及Low On Memory Reclaiming(LMR算法) 这2种进程和实现.
5.4 kswapd
kswapd 进程负责确保内存空间总是在被释放中.它监控内核中的pages_high和pages_low阀值.如果空闲内存的数值低于 pages_low,则每次 kswapd 进程启动扫描并尝试释放32个free pages.并一直重复这个过程,直到空闲内存的数值高于 pages_high.
kswapd 进程完成以下几个操作:
1,如果该页处于未修改状态,则将该页放置回空闲列表中.
2,如果该页处于已修改状态并可备份回文件系统,则将页内容写入到磁盘.
3,如果该页处于已修改状态但没有任何磁盘备份,则将页内容写入到swap device.# ps -ef | grep kswapd
root 30 1 0 23:01 ? 00:00:00 [kswapd0]5.5 Kernel Paging with pdflush
pdflush 进程负责将内存中的内容和文件系统进行同步操作.也就是说,当一个文件在内存中进行修改后, pdflush 将负责写回到磁盘上.
# ps -ef | grep pdflush
root 28 3 0 23:01 ? 00:00:00 [pdflush]
root 29 3 0 23:01 ? 00:00:00 [pdflush]当内存中存在10% 的脏页,pdflush 将被启动同步脏页回文件系统里.这个参数值可以通过 vm.dirty_background_ratio 来进行调整.
(译注:
Q:什么是脏页?
A:由于内存中页缓存的缓存作用,写操作实际上都是延迟的.当页缓存中的数据比磁盘存储的数据还要更新时,那么该数据就被称做脏页.)# sysctl -n vm.dirty_background_ratio
10在多数环境下,Pdflush与PFRA是独立运行的,当内核调用LMR时,LMR 就触发pdflush将脏页写入到磁盘里.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
在2.4 内核下,一个高负荷的内存环境中,系统将遇到交换过程中不断的崩溃.这是因为PFRA 从一个运行进程中,偷取其中一个内存页并尝试使用.导致结果就是,这个进程如果要回收那个页时,要是没有就会尝试再去偷取这个页,这样一来,就越来越糟糕 了.在2.6 内核下,使用"Swap token"修复了这个BUG,用来防止PFRA 不断从一个进程获取同一个页.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++5.6 案例学习:大量的入口I/O
vmstat 工具报告里除了CPU 使用情况,还包括了虚拟内存.以下就是vmstat 输出中关于虚拟内存的部分:
Table 2: The vmstat Memory Statistics
Field Description
Swapd The amount of virtual memory in KB currently in use. As free memory reaches low thresholds, more data is paged to the swap device.
当前虚拟内存使用的总额(单位:KB).空闲内存达到最低的阀值时,更多的数据被转换成页到交换设备中.
Free The amount of physical RAM in kilobytes currently available to running applications.
当前内存中可用空间字节数.
Buff The amount of physical memory in kilobytes in the buffer cache as a result of read() and write() operations.
当前内存中用于read()和write()操作的缓冲区中缓存字节数
Cache The amount of physical memory in kilobytes mapped into process address space.
当前内存中映射到进程地址空间字节数
So The amount of data in kilobytes written to the swap disk.
写入交换空间的字节数总额
Si The amount of data in kilobytes written from the swap disk back into RAM.
从交换空间写回内存的字节数总额
Bo The amount of disk blocks paged out from the RAM to the filesystem or swap device.
磁盘块页面从内存到文件或交换设备的总额
Bi The amount of disk blocks paged into RAM from the filesystem or swap device.
磁盘块页面从文件或交换设备到内存的总额以下 vmstat 的输出结果,就是演示一个在I/O 应用中,虚拟内存在高负荷情况下的环境
# vmstat 3
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
3 2 809192 261556 79760 886880 416 0 8244 751 426 863 17 3 6 75
0 3 809188 194916 79820 952900 307 0 21745 1005 1189 2590 34 6 12 48
0 3 809188 162212 79840 988920 95 0 12107 0 1801 2633 2 2 3 94
1 3 809268 88756 79924 1061424 260 28 18377 113 1142 1694 3 5 3 88
1 2 826284 17608 71240 1144180 100 6140 25839 16380 1528 1179 19 9 12 61
2 1 854780 17688 34140 1208980 1 9535 25557 30967 1764 2238 43 13 16 28
0 8 867528 17588 32332 1226392 31 4384 16524 27808 1490 1634 41 10 7 43
4 2 877372 17596 32372 1227532 213 3281 10912 3337 678 932 33 7 3 57
1 2 885980 17800 32408 1239160 204 2892 12347 12681 1033 982 40 12 2 46
5 2 900472 17980 32440 1253884 24 4851 17521 4856 934 1730 48 12 13 26
1 1 904404 17620 32492 1258928 15 1316 7647 15804 919 978 49 9 17 25
4 1 911192 17944 32540 1266724 37 2263 12907 3547 834 1421 47 14 20 20
1 1 919292 17876 31824 1275832 1 2745 16327 2747 617 1421 52 11 23 14
5 0 925216 17812 25008 1289320 12 1975 12760 3181 772 1254 50 10 21 19
0 5 932860 17736 21760 1300280 8 2556 15469 3873 825 1258 49 13 24 15根据观察值,我们可以得到以下结论:
1,大量的disk pages(bi)被写入内存,很明显在进程地址空间里,数据缓存(cache)也在不断的增长.
2,在这个时间点上,空闲内存(free) 始终保持在17MB,即使数据从硬盘读入而在消耗RAM.
3,为了维护空闲列表, kswapd 从读/写缓存区(buff)中获取内存并分配到空闲列表里.很明显可以看到buffer cache(buff) 在逐渐的减少中.
4, 同时kswapd 进程不断的写脏页到swap device(so)时,很明显虚拟内存的利用率是在逐渐的增加中(swpd).
5.7 结论
监控虚拟内存性能由以下几个部分组成:
1,当系统中出现较少的页错误,获得最好的响应时间,是因为memory caches(译注:内存高速缓存)比disk caches更快(译注:磁盘高速缓存).
2,较少的空闲内存,是件好事情,那意味着缓存的使用更有效率.除非在不断的写入swap device和disk.
3,如果系统不断报告,swap device总是繁忙中,那就意味着内存已经不足,需要升级了.
Linux System and Performance Monitoring(CPU篇)
提交: å «æ 10 , 2009, 9:41am CEST 由 tonnyom
Linux System and Performance Monitoring(CPU篇)
Date: 2009.07.21
Author: Darren Hoch
译: Tonnyom[AT]hotmail.com 2009.08.10前言: 网上其实有很多关于这方面的文章,那为什么还会有此篇呢,有这么几个原因,是我翻译的动力,第一,概念和内容虽然老套,但都讲得很透彻,而且还很全面.第 二,理论结合实际,其中案例分析都不错.第三,不花哨,采用的工具及命令都是最基本的,有助于实际操作.但本人才疏学浅,译文大多数都是立足于自己对原文 的理解,大家也可以自己去OSCAN 上找原文,如果有什么较大出入,还望留言回复,甚是感激!
1.0 性能监控介绍
性能优化就是找到系统处理中的瓶颈以及去除这些的过程,多数管理员相信看一些相关的"cook book"就可以实现性能优化,通常通过对内核的一些配置是可以简单的解决问题,但并不适合每个环境,性能优化其实是对OS 各子系统达到一种平衡的定义,这些子系统包括了:
CPU
Memory
IO
Network这些子系统之间关系是相互彼此依赖的,任何一个高负载都会导致其他子系统出现问题.比如:
大量的页调入请求导致内存队列的拥塞
网卡的大吞吐量可能导致更多的 CPU开销
大量的CPU开销又会尝试更多的内存使用请求
大量来自内存的磁盘写请求可能导致更多的 CPU 以及 IO问题所以要对一个系统进行优化,查找瓶颈来自哪个方面是关键,虽然看似是某一个子系统出现问题,其实有可能是别的子系统导致的.
1.1 确定应用类型
基于需要理解该从什么地方来入手优化瓶颈,首先重要的一点,就是理解并分析当前系统的特点,多数系统所跑的应用类型,主要为2种:
IO Bound(译注:IO 范畴): 在这个范畴中的应用,一般都是高负荷的内存使用以及存储系统,这实际上表示IO 范畴的应用,就是一个大量数据处理的过程.IO 范畴的应用不对CPU以及网络发起更多请求(除非类似NAS这样的网络存储硬件).IO 范畴的应用通常使用CPU 资源都是为了产生IO 请求以及进入到内核调度的sleep 状态.通常数据库软件(译注:mysql,oracle等)被认为是IO 范畴的应用类型.
CPU Bound(译注:CPU 范畴): 在这个范畴中的应用,一般都是高负荷的CPU 占用. CPU 范畴的应用,就是一个批量处理CPU 请求以及数学计算的过程.通常web server,mail server,以及其他类型服务被认为是CPU 范畴的应用类型.
1.2 确定基准线统计
系统利用率情况,一般随管理员经验以及系统本身用途来决定.唯一要清楚的就是,系统优化希望达成什么效果,以及哪些方面是需要优化,还有参考值是什么?因此就建立一个基准线,这个统计数据必须是系统可用性能状态值,用来比较不可用性能状态值.
在以下例子中,1个系统性能的基准线快照,用来比较当高负荷时的系统性能快照.
# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
1 0 138592 17932 126272 214244 0 0 1 18 109 19 2 1 1 96
0 0 138592 17932 126272 214244 0 0 0 0 105 46 0 1 0 99
0 0 138592 17932 126272 214244 0 0 0 0 198 62 40 14 0 45
0 0 138592 17932 126272 214244 0 0 0 0 117 49 0 0 0 100
0 0 138592 17924 126272 214244 0 0 0 176 220 938 3 4 13 80
0 0 138592 17924 126272 214244 0 0 0 0 358 1522 8 17 0 75
1 0 138592 17924 126272 214244 0 0 0 0 368 1447 4 24 0 72
0 0 138592 17924 126272 214244 0 0 0 0 352 1277 9 12 0 79# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
2 0 145940 17752 118600 215592 0 1 1 18 109 19 2 1 1 96
2 0 145940 15856 118604 215652 0 0 0 468 789 108 86 14 0 0
3 0 146208 13884 118600 214640 0 360 0 360 498 71 91 9 0 0
2 0 146388 13764 118600 213788 0 340 0 340 672 41 87 13 0 0
2 0 147092 13788 118600 212452 0 740 0 1324 620 61 92 8 0 0
2 0 147360 13848 118600 211580 0 720 0 720 690 41 96 4 0 0
2 0 147912 13744 118192 210592 0 720 0 720 605 44 95 5 0 0
2 0 148452 13900 118192 209260 0 372 0 372 639 45 81 19 0 0
2 0 149132 13692 117824 208412 0 372 0 372 457 47 90 10 0 0从上面第一个结果可看到,最后一列(id) 表示的是空闲时间,我们可以看到,在基准线统计时,CPU 的空闲时间在79% - 100%.在第二个结果可看到,系统处于100%的占用率以及没有空闲时间.从这个比较中,我们就可以确定是否是CPU 使用率应该被优化.
2.0 安装监控工具
多数 *nix系统都有一堆标准的监控命令.这些命令从一开始就是*nix 的一部分.Linux 则通过基本安装包以及额外包提供了其他监控工具,这些安装包多数都存在各个Linux 发布版本中.尽管还有其他更多的开源以及第三方监控软件,但本文档只讨论基于Linux 发布版本的监控工具.
本章将讨论哪些工具怎样来监控系统性能.
Tool Description Base Repository
vmstat all purpose performance tool yes yes
mpstat provides statistics per CPU no yes
sar all purpose performance monitoring tool no yes
iostat provides disk statistics no yes
netstat provides network statistics yes yes
dstat monitoring statistics aggregator no in most distributions
iptraf traffic monitoring dashboard no yes
netperf Network bandwidth tool no In some distributions
ethtool reports on Ethernet interface configuration yes yes
iperf Network bandwidth tool no yes
tcptrace Packet analysis tool no yes3.0 CPU 介绍
CPU 利用率主要依赖于是什么资源在试图存取.内核调度器将负责调度2种资源种类:线程(单一或者多路)和中断.调度器去定义不同资源的不同优先权.以下列表从优先级高到低排列:
Interrupts(译注:中断) - 设备通知内核,他们完成一次数据处理的过程.例子,当一块网卡设备递送网络数据包或者一块硬件提供了一次IO 请求.
Kernel(System) Processes(译注:内核处理过程) - 所有内核处理过程就是控制优先级别.
User Processes(译注:用户进程) - 这块涉及"userland".所有软件程序都运行在这个user space.这块在内核调度机制中处于低优先级.
从上面,我们可以看出内核是怎样管理不同资源的.还有几个关键内容需要介绍,以下部分就将介绍context(译注:上下文切换),run queues(译注:运行队列)以及utilization(译注:利用率).
3.1 上下文切换
多数现代处理器都能够运行一个进程(单一线程)或者线程.多路超线程处理器有能力运行多个线程.然而,Linux 内核还是把每个处理器核心的双核心芯片作为独立的处理器.比如,以Linux 内核的系统在一个双核心处理器上,是报告显示为两个独立的处理器.
一个标准的Linux 内核可以运行50 至 50,000 的处理线程.在只有一个CPU时,内核将调度并均衡每个进程线程.每个线程都分配一个在处理器中被开销的时间额度.一个线程要么就是获得时间额度或已抢先 获得一些具有较高优先级(比如硬件中断),其中较高优先级的线程将从区域重新放置回处理器的队列中.这种线程的转换关系就是我们提到的上下文切换.
每次内核的上下文切换,资源被用于关闭在CPU寄存器中的线程和放置在队列中.系统中越多的上下文切换,在处理器的调度管理下,内核将得到更多的工作.
3.2 运行队列
每个CPU 都维护一个线程的运行队列.理论上,调度器应该不断的运行和执行线程.进程线程不是在sleep 状态中(译注:阻塞中和等待IO中)或就是在可运行状态中.如果CPU 子系统处于高负荷下,那就意味着内核调度将无法及时响应系统请求.导致结果,可运行状态进程拥塞在运行队列里.当运行队列越来越巨大,进程线程将花费更多 的时间获取被执行.
比较流行的术语就是"load",它提供当前运行队列的详细状态.系统 load 就是指在CPU 队列中有多少数目的线程,以及其中当前有多少进程线程数目被执行的组合.如果一个双核系统执行了2个线程,还有4个在运行队列中,则 load 应该为 6. top 这个程序里显示的load averages 是指1,5,15 分钟以内的load 情况.
3.3 CPU 利用率
CPU 利用率就是定义CPU 使用的百分比.评估系统最重要的一个度量方式就是CPU 的利用率.多数性能监控工具关于CPU 利用率的分类有以下几种:
User Time(译注:用户进程时间) - 关于在user space中被执行进程在CPU 开销时间百分比.
System Time(译注:内核线程以及中断时间) - 关于在kernel space中线程和中断在CPU 开销时间百分比.
Wait IO(译注:IO 请求等待时间) - 所有进程线程被阻塞等待完成一次IO 请求所占CPU 开销idle的时间百分比.
Idle(译注:空闲) - 一个完整空闲状态的进程在CPU 处理器中开销的时间百分比.
4.0 CPU 性能监控
理解运行队列,利用率,上下文切换对怎样CPU 性能最优化之间的关系.早期提及到,性能是相对于基准线数据的.在一些系统中,通常预期所达到的性能包括:
Run Queues - 每个处理器应该运行队列不超过1-3 个线程.例子,一个双核处理器应该运行队列不要超过6 个线程.
CPU Utiliation - 如果一个CPU 被充分使用,利用率分类之间均衡的比例应该是
65% - 70% User Time
30% - 35% System Time
0% - 5% Idle TimeContext Switches - 上下文切换的数目直接关系到CPU 的使用率,如果CPU 利用率保持在上述均衡状态时,大量的上下文切换是正常的.
很多Linux 上的工具可以得到这些状态值,首先就是 vmstat 和 top 这2个工具.
4.1 vmstat 工具的使用
vmstat 工具提供了一种低开销的系统性能观察方式.因为 vmstat 本身就是低开销工具,在非常高负荷的服务器上,你需要查看并监控系统的健康情况,在控制窗口还是能够使用vmstat 输出结果.这个工具运行在2种模式下:average 和 sample 模式.sample 模式通过指定间隔时间测量状态值.这个模式对于理解在持续负荷下的性能表现,很有帮助.下面就是
vmstat 运行1秒间隔的示例:
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 104300 16800 95328 72200 0 0 5 26 7 14 4 1 95 0
0 0 104300 16800 95328 72200 0 0 0 24 1021 64 1 1 98 0
0 0 104300 16800 95328 72200 0 0 0 0 1009 59 1 1 98 0Table 1: The vmstat CPU statistics
Field Description
r The amount of threads in the run queue. These are threads that are runnable, but the CPU is not available to execute them.
当前运行队列中线程的数目.代表线程处于可运行状态,但CPU 还未能执行.
b This is the number of processes blocked and waiting on IO requests to finish.
当前进程阻塞并等待IO 请求完成的数目
in This is the number of interrupts being processed.
当前中断被处理的数目
cs This is the number of context switches currently happening on the system.
当前kernel system中,发生上下文切换的数目
us This is the percentage of user CPU utilization.
CPU 利用率的百分比
sys This is the percentage of kernel and interrupts utilization.
内核和中断利用率的百分比
wa This is the percentage of idle processor time due to the fact that ALL runnable threads are blocked waiting on IO.
所有可运行状态线程被阻塞在等待IO 请求的百分比
id This is the percentage of time that the CPU is completely idle.
CPU 空闲时间的百分比4.2 案例学习:持续的CPU 利用率
在这个例子中,这个系统被充分利用
# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
3 0 206564 15092 80336 176080 0 0 0 0 718 26 81 19 0 0
2 0 206564 14772 80336 176120 0 0 0 0 758 23 96 4 0 0
1 0 206564 14208 80336 176136 0 0 0 0 820 20 96 4 0 0
1 0 206956 13884 79180 175964 0 412 0 2680 1008 80 93 7 0 0
2 0 207348 14448 78800 175576 0 412 0 412 763 70 84 16 0 0
2 0 207348 15756 78800 175424 0 0 0 0 874 25 89 11 0 0
1 0 207348 16368 78800 175596 0 0 0 0 940 24 86 14 0 0
1 0 207348 16600 78800 175604 0 0 0 0 929 27 95 3 0 2
3 0 207348 16976 78548 175876 0 0 0 2508 969 35 93 7 0 0
4 0 207348 16216 78548 175704 0 0 0 0 874 36 93 6 0 1
4 0 207348 16424 78548 175776 0 0 0 0 850 26 77 23 0 0
2 0 207348 17496 78556 175840 0 0 0 0 736 23 83 17 0 0
0 0 207348 17680 78556 175868 0 0 0 0 861 21 91 8 0 1根据观察值,我们可以得到以下结论:
1,有大量的中断(in) 和较少的上下文切换(cs).这意味着一个单一的进程在产生对硬件设备的请求.
2,进一步显示某单个应用,user time(us) 经常在85%或者更多.考虑到较少的上下文切换,这个应用应该还在处理器中被处理.
3,运行队列还在可接受的性能范围内,其中有2个地方,是超出了允许限制.
4.3 案例学习:超负荷调度
在这个例子中,内核调度中的上下文切换处于饱和
# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
2 1 207740 98476 81344 180972 0 0 2496 0 900 2883 4 12 57 27
0 1 207740 96448 83304 180984 0 0 1968 328 810 2559 8 9 83 0
0 1 207740 94404 85348 180984 0 0 2044 0 829 2879 9 6 78 7
0 1 207740 92576 87176 180984 0 0 1828 0 689 2088 3 9 78 10
2 0 207740 91300 88452 180984 0 0 1276 0 565 2182 7 6 83 4
3 1 207740 90124 89628 180984 0 0 1176 0 551 2219 2 7 91 0
4 2 207740 89240 90512 180984 0 0 880 520 443 907 22 10 67 0
5 3 207740 88056 91680 180984 0 0 1168 0 628 1248 12 11 77 0
4 2 207740 86852 92880 180984 0 0 1200 0 654 1505 6 7 87 0
6 1 207740 85736 93996 180984 0 0 1116 0 526 1512 5 10 85 0
0 1 207740 84844 94888 180984 0 0 892 0 438 1556 6 4 90 0根据观察值,我们可以得到以下结论:
1,上下文切换数目高于中断数目,说明kernel中相当数量的时间都开销在上下文切换线程.
2,大量的上下文切换将导致CPU 利用率分类不均衡.很明显实际上等待io 请求的百分比(wa)非常高,以及user time百分比非常低(us).
3,因为CPU 都阻塞在IO请求上,所以运行队列里也有相当数目的可运行状态线程在等待执行.
4.4 mpstat 工具的使用
如果你的系统运行在多处理器芯片上,你可以使用 mpstat 命令来监控每个独立的芯片.Linux 内核视双核处理器为2 CPU's,因此一个双核处理器的双内核就报告有4 CPU's 可用.
mpstat 命令给出的CPU 利用率统计值大致和 vmstat 一致,但是 mpstat 可以给出基于单个处理器的统计值.
# mpstat –P ALL 1
Linux 2.4.21-20.ELsmp (localhost.localdomain) 05/23/200605:17:31 PM CPU %user %nice %system %idle intr/s
05:17:32 PM all 0.00 0.00 3.19 96.53 13.27
05:17:32 PM 0 0.00 0.00 0.00 100.00 0.00
05:17:32 PM 1 1.12 0.00 12.73 86.15 13.27
05:17:32 PM 2 0.00 0.00 0.00 100.00 0.00
05:17:32 PM 3 0.00 0.00 0.00 100.00 0.004.5 案例学习: 未充分使用的处理量
在这个例子中,为4 CPU核心可用.其中2个CPU 主要处理进程运行(CPU 0 和1).第3个核心处理所有内核和其他系统功能(CPU 3).第4个核心处于idle(CPU 2).
使用 top 命令可以看到有3个进程差不多完全占用了整个CPU 核心.
# top -d 1
top - 23:08:53 up 8:34, 3 users, load average: 0.91, 0.37, 0.13
Tasks: 190 total, 4 running, 186 sleeping, 0 stopped, 0 zombie
Cpu(s): 75.2% us, 0.2% sy, 0.0% ni, 24.5% id, 0.0% wa, 0.0% hi, 0.0%
si
Mem: 2074736k total, 448684k used, 1626052k free, 73756k buffers
Swap: 4192956k total, 0k used, 4192956k free, 259044k cachedPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
15957 nobody 25 0 2776 280 224 R 100 20.5 0:25.48 php
15959 mysql 25 0 2256 280 224 R 100 38.2 0:17.78 mysqld
15960 apache 25 0 2416 280 224 R 100 15.7 0:11.20 [httpd]
15901 root 16 0 2780 1092 800 R 1 0.1 0:01.59 top
1 root 16 0 1780 660 572 S 0 0.0 0:00.64 init# mpstat –P ALL 1
Linux 2.4.21-20.ELsmp (localhost.localdomain) 05/23/200605:17:31 PM CPU %user %nice %system %idle intr/s
05:17:32 PM all 81.52 0.00 18.48 21.17 130.58
05:17:32 PM 0 83.67 0.00 17.35 0.00 115.31
05:17:32 PM 1 80.61 0.00 19.39 0.00 13.27
05:17:32 PM 2 0.00 0.00 16.33 84.66 2.01
05:17:32 PM 3 79.59 0.00 21.43 0.00 0.0005:17:32 PM CPU %user %nice %system %idle intr/s
05:17:33 PM all 85.86 0.00 14.14 25.00 116.49
05:17:33 PM 0 88.66 0.00 12.37 0.00 116.49
05:17:33 PM 1 80.41 0.00 19.59 0.00 0.00
05:17:33 PM 2 0.00 0.00 0.00 100.00 0.00
05:17:33 PM 3 83.51 0.00 16.49 0.00 0.0005:17:33 PM CPU %user %nice %system %idle intr/s
05:17:34 PM all 82.74 0.00 17.26 25.00 115.31
05:17:34 PM 0 85.71 0.00 13.27 0.00 115.31
05:17:34 PM 1 78.57 0.00 21.43 0.00 0.00
05:17:34 PM 2 0.00 0.00 0.00 100.00 0.00
05:17:34 PM 3 92.86 0.00 9.18 0.00 0.0005:17:34 PM CPU %user %nice %system %idle intr/s
05:17:35 PM all 87.50 0.00 12.50 25.00 115.31
05:17:35 PM 0 91.84 0.00 8.16 0.00 114.29
05:17:35 PM 1 90.82 0.00 10.20 0.00 1.02
05:17:35 PM 2 0.00 0.00 0.00 100.00 0.00
05:17:35 PM 3 81.63 0.00 15.31 0.00 0.00你也可以使用 ps 命令通过查看 PSR 这列,检查哪个进程在占用了哪个CPU.
# while :; do ps -eo pid,ni,pri,pcpu,psr,comm | grep 'mysqld'; sleep 1;
done
PID NI PRI %CPU PSR COMMAND
15775 0 15 86.0 3 mysqld
PID NI PRI %CPU PSR COMMAND
15775 0 14 94.0 3 mysqld
PID NI PRI %CPU PSR COMMAND
15775 0 14 96.6 3 mysqld
PID NI PRI %CPU PSR COMMAND
15775 0 14 98.0 3 mysqld
PID NI PRI %CPU PSR COMMAND
15775 0 14 98.8 3 mysqld
PID NI PRI %CPU PSR COMMAND
15775 0 14 99.3 3 mysqld4.6 结论
监控 CPU 性能由以下几个部分组成:
1,检查system的运行队列,以及确定不要超出每个处理器3个可运行状态线程的限制.
2,确定CPU 利用率中user/system比例维持在70/30
3,当CPU 开销更多的时间在system mode,那就说明已经超负荷并且应该尝试重新调度优先级
4,当I/O 处理得到增长,CPU 范畴的应用处理将受到影响
sa 的职位定义
提交: å «æ 10 , 2009, 3:39am CEST 由 tonnyom
sa 的职位定义包括但不限于:
Making the system available to others
Monitoring the usage of the system
Maintaining a certain level of performance
Planning for future processing needs相关文章
- 无相关文章
Energy Efficiency for Information Technology-IT能效
提交: å «æ 6 , 2009, 3:23am CEST 由 finalbsd
《IT能效》 读后
近几年,数据中心的能耗已经翻番,并且如果不改善将会剧烈的增长。这个问题是由多方面因素造成的。计算的增长导致了遍布全球的成千上万的数据中心塞 满了无数的x86服务器。数据量在增长,同时应用程序对服务器性能需求也在增长。随着技术的进步,新的生产工艺使得晶体管可以变得更小,从而促进了高密度 计算的发展,但是高密度计算产生了更多的热量,因此也需要更多的冷却。 所有这些导致了数据中心能耗的增长。
无数的x86服务器
计算的发展从几百台大型机(mainframe)到数以千计的分布式中型机(midrange),再到现在几乎任何企业都能看到的无数的x86服务 器。更多的服务器不仅消耗更多的电,而且系统密度的增加导致产生了更多的热量,从而需要冷却。大型企业还有一套支持所有这些x86机器的系统和应用程序, 这也导致了需要更多的电,而且这些都没有结束的迹象。
根据以往历史,电力和冷却设备的成本相比硬件成本来说是相当小的。但是今天,这些设备、服务器电力、服务器冷却、基本建设投资、折旧损失、以及维护 的总成本已经和硬件总成本相当。而且,取决于数据中心的位置,这种情况很快会被改变。在高利用率的地方,比如欧洲、北美。一台x86服务器耗费的电力成本 在三年内将超过服务器本身的成本。
根据美国环保署(EPA), 2000-2006年间,数据中心的能耗已经翻倍,据此推断,IT电力需求在5年内需要再建10座1000MW燃煤火力发电站或者核电站。今天的数据中心 为了冷却以及服务器运行,面临着耗尽所有电力的危险。 注:我国秦山核电站总装机容量为2900MW。
EPA同时预言,未来10年,电力故障以及电力管制将影响美国多达90%的数据中心。
相关文章
- 无相关文章
带你深入了解Web站点数据库的分布存储【转帖】
提交: ä¸æ 24 , 2009, 11:51am CEST 由 finalbsd
转自� [database.csdn.net]
在Web 2.0时代,网站将会经常面临着快速增加的访问量,但是我们的应用如何满足用户的访问需求,而且基本上我们看到的情况都是性能瓶颈都是在数据库上,这个不 怪数据库,毕竟要满足很大访问量确实对于任何一款数据库都是很大的压力,不论是商业数据库Oracle、MS sql Server、DB2之类,还是开源的MySQL、PostgreSQL,都是很大的挑战,解决的方法很简单,就是把数据分散在不同的数据库上(可以是硬 件上的,也可以是逻辑上的),本文就是主要讨论如何数据库分散存储的的问题。
目前主要分布存储的方式都是按照一定的方式进行切分,主要是垂直切分(纵向)和水平切分(横向)两种方式,当然,也有两种结合的方式,达到更贴切的切分粒度。
1. 垂直切分(纵向)数据是数据库切分按照网站业务、产品进行切分,比如用户数据、博客文章数据、照片数据、标签数据、群组数据等等每个业务一个独立的数据库或者数据库服务器。
2. 水平切分(横向)数据是把所有数据当作一个大产品,但是把所有的平面数据按照某些Key(比如用户名)分散在不同数据库或者数据库服务器上,分散对数据访问的压力,这种方式也是本文主要要探讨的。
本文主要针对的的 MySQL/PostgreSQL 类的开源数据库,同时平台是在 linux/FreeBSD,使用 php/Perl/Ruby/Python 等脚本语言,搭配 Apache/Li [httpd] 等Web服务器 的平台下面的Web应用,不讨论静态文件的存储,比如视频、图片、CSS、JS,那是另外一个话题。
说明:下面将会反复提到的一个名次“节点”(Node),指的是一个数据库节点,可能是物理的一台数据库服务器,也可能是一个数据库,一般情况是指一台数据库服务器,并且是具有 Master/Slave 结构的数据库服务器,我们查看一下图片,了解这样节点的架构:
一、基于散列的分布方式
1. 散列方式介绍
基于散列(Hash)的分布存储方式,主要是依赖主要Key和散列算法,比如以用户为主的应用主要的角色就是用户,那么做Key的就可以是用户ID 或者是用 户名、邮件地址之类(该值必须在站点中随处传递),使用这个唯一值作为Key,通过对这个Key进行散列算法,把不同的用户数据分散在不同的数据库节点 (Node)上。
我们通过简单的实例来描述这个问题:比如有一个应用,Key是用户ID,拥有10个数据库节点,最简单的散列算法是我们 用户ID数模以我们所有节点数,余数就是对应的节点机器,算法:所在节点 = 用户ID % 总节点数,那么,用户ID为125的用户所在节点:125 % 10 = 5,那么应该在名字为5的节点上。同样的,可以构造更为强大合理的Hash算法来更均匀的分配用户到不同的节点上。
2. 散列分布存储方式的扩容
我们知道既然定义了一个散列算法,那么这些Key就会按部就班的分散到指定节点上,但是如果目前的所有节点不够满足要求怎么办?这就存在一个扩容的问题,扩容首当其冲的就是要修改散列算法,同时数据也要根据散列算法进修迁移或者修改。
(1) 迁移方式扩容:修 改散列算法以后,比如之前是10个节点,现在增加到20个节点,那么Hash算法就是[模20],相应的存在一个以前的节点被分配的数据会比较多,但是新 加入的节点数据少的不平衡的状态,那么可以考虑使用把以前数据中的数据按照Key使用新的Hash算法进行运算出新节点,把数据迁移到新节点,缺点但是这 个成本相应比较大,不稳定性增加;好处是数据比较均匀,并且能够充分利用新旧节点。
(2) 充分利用新节点:增 加新节点以后,Hash算法把新加入的数据全部Hash到新节点上,不再往旧节点上分配数据,这样不存在迁移数据的成本。优点是只需要修改Hash算法, 无须迁移数据就能够简单的增加节点,但是在查询数据的时候,必须使用考虑到旧Key使用旧Hash算法,新增加的Key使用新的Hash算法,不然无法查 找到数据所在节点。缺点很明显,一个是Hash算法复杂度增加,如果频繁的增加新节点,算法将非常复杂,无法维护,另外一个方面是旧节点无法充分利用资源 了,因为旧节点只是单纯的保留旧Key数据,当然了,这个也有合适的解决方案。
总结来说,散列方式分布数据,要新增节点比较困难和繁琐,但是也有很多适合的场合,特别适合能够预计到未来数据量大小的应用,但是普遍 Web2.0 网站都无法预计到数据量。
二、基于全局节点分配方式
1. 全局节点分配方式介绍
就是把所有Key信息与数据库节点之间的映射关系记录下来,保存到全局表中,当需要访问某个节点的时候,首先去全局表中查找,找到以后再定位到相应节点。全局表的存储方式一般两种:
(1) 采用节点数据库本身(MySQL/PostgreSQL)存储节点信息,能够远程访问,为了保证性能,同时配合使用 Heap(MEMORY) 内存表,或者是使用 Memcached 缓存方式来缓存,加速节点查找
(2) 采用 BDB(BerkeleyDB)、DBM/GDBM/NDBM 这类本地文件数据库,基于 key=>value 哈希数据库,查找性能比较高,同时结合 APC、Memcached 之类的缓存加速。
第 一种存储方式是容易查询(包括远程查询),缺点是性能不太好(这个是所有关系型数据库的通病);第二种方式的有点是本地查询速度很快(特别是hash型数 据库,时间复杂度是O(1),比较快),缺点是无法远程使用,并且无法在多台机器中间同步共享数据,存在数据一致的情况。
我们来描述实施 大概结构:假如我们有10个数据库节点,一个全局数据库用于存储Key到节点的映射信息,假设全局数据库有一个表叫做 AllNode ,包含两个字段,Key 和 NodeID,假设我们继续按照上面的案例,用户ID是Key,并且有一个用户ID为125的用户,它对应的节点,我们查询表获得:
Key NodeID
13 2
148 5
22 9
125 6可以确认这个用户ID为125的用户,所在的节点是6,那么就可以迅速定位到该节点,进行数据的处理。
我们来查看一下分布存储结构图:
2. 全局节点分布方式的扩容
全局节点分配方式同样存在扩容的问题,不过它早就考虑到这个问题,并且这么设计就是为了便于扩容,主要的扩容方式是两种:
(1) 通过节点自然增加来分配Key到节点的映射扩容
这 种是最典型、最简单、最节约机器资源的扩容方式,大致就是按照每个节点分配指定的数据量,比如一个节点存储10万用户数据,第一个节点存储0-10w用户 数据,第二个节点存储10w-20w用户数据,第三个节点存储20w-30w用户信息,依此类推,用户增加到一定数据量就增加节点服务器,同时把Key分 配到新增加的节点上,映射关系记录到全局表中,这样可以无限的增加节点。存在的问题是,如果早期的节点用户访问频率比较低,而后期增加的节点用户访问频率 比较高,则存在节点服务器负载不均衡的现象,这个也是可以想方案解决的。
(2) 通过概率算法来映射Key到节点的的扩容
这种方式是在既然有的节点基础上,给每个节点设定一个被分配到Key的概率,然后分配Key的时候,按照每个节点被指定的概率进行分配,如果每个节点平均的数据容量超过了指定的百分比,比如50%,那么这时候就考虑增加新节点,那么新节点增加Key的概率要大于旧节点。
一般情况下,对于节点的被分配的概率也是记录在数据库中的,比如我们把所有的概率为100,共有10个节点,那么设定每个节点被分配的数据的概率为10,我们查看数据表结构:
NodeID Weight
1 10
2 10
3 10现在新加入了一个 节点,新加入的节点,被分配Key的几率要大于旧节点,那么就必须对这个新加入的节点进行概率计算,计算公式:10х+у=100, у>х,得出:у{10...90},х{1...9},x是单个旧节点的概率,旧节点的每个节点的概率是一样的,y是新节点的概率,按照这个计算 公式,推算出新节点y的概率的范围,具体按照具体不同应用的概率公式进行计算。
三、存在的问题
现在我们来分析和解决一下我们上面两种分布存储方式的存在的问题,便于在实际考虑架构的时候能够避免或者是融合一些问题和缺点。
1. 散列和全局分配方式都存在问题
(1) 散列方式扩容不是很方便,必须修改散列算法,同时可能还需要对数据进行迁移,它的优点是从Key定位一个节点非常快,O(1)的时间复杂度,而且基本不需要查询数据库,节约响应时间。
(2) 全局分配方式存在的问题最明显的是单点故障,全局数据库down掉将影响所有应用。另外一个问题是查询量大,对每个Key节点的操作都必须经过全局数据库,压力很大,优点是扩容方便,增加节点简单。
2. 分布存储带来的搜索和统计问题
(1) 一般搜索或统计都是对所有数据进行处理,但因为拆分以后,数据分散在不同节点机器上,无法进行全局查找和统计。解决方案一是对主要的基础数据存储在全局表中,便于查找和统计,但这类数据不宜太多,部分核心数据。
(2) 采用站内搜索引擎来索引和记录全部数据,比如采用 Lucene 等开源索引系统进行所有数据的索引,便于搜索。 对于统计操作可以采用后台非实时统计,可采用遍历所有节点的方式,但效率低下。
3. 性能优化问题
(1) 散列算法,节点概率和分配等为了提高性能都可以使用编译语言开发,做成lib或者是所有php扩展形式。
(2) 对于采用 MySQL 的情况,可以采用自定义的数据库连接池,采用 Apache Module 形式加载,能够自由定制的采用各种连接方式。
(3) 对于全局数据或都频繁访问的数据,可以采用APC、Memcache、DBM、BDB、共享内存、文件系统等各种方式进行缓存,减少数据库的访问压力。
(4) 采用数据本身的强大处理机制,比如 MySQL5 的表分区或者是 MySQL5 的Cluster 。另外建议在实际架构中采用InnoDB表引擎作为主要存储引擎,MyISAM作为一些日志、统计数据等场合,不论在安全、可靠性、速度都有保障。
相关文章
- 无相关文章
Nordic Meet on Nagios 2009
提交: å æ 16 , 2009, 11:33am CEST 由 tonnyom
把今年NMN2009 相关的内容,打个包传上来,与大家分享下!
nordicmeetonnagios.op5.org
Nmn2009.rar
相关文章
- 无相关文章
Kernel reports EDAC i5000: SPD Protocol Error, Bits= 0x40000
提交: å æ 11 , 2009, 11:11am CEST 由 joe
Problem:
The kernel repeatedly prints errors messages similar to the following:
EDAC i5000 MC0: NON-FATAL Errors found!!! 1st NON-FATAL Err Reg= 0x40000
EDAC i5000: SPD Protocol Error, Bits= 0x40000Description:
This is caused by the optional IPMI card and the i5000_edac kernel module trying to access the platforms EDAC (Error Detection and Correction) information at the same time.Solution:
The workaround for this problem is to prevent the i5000_edac module from loading. To do this, add the following line to the /etc/modprobe.d/blacklist file:blacklist i5000_edac
Last update: 2008-08-21 11:29
Author: ASL
相关文章- 无相关文章
Nginx模块一致性hash的patch
提交: å æ 9 , 2009, 9:53am CEST 由 finalbsd

小威作品:
Consistent Hashing 如下所示:首先求出所有备选服务器(节点)的哈希值,并将其
配置到0~232的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并
映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器
上。如果超过232仍然找不到服务器,就会保存到第一台服务器上.详细文档这里下载: nginx_hasnginx_upstream_hash 增加一致性hash
相关文章- 无相关文章
check_memcached_conns
提交: äºæ 15 , 2009, 11:10am CEST 由 tonnyom
应某人需求,简单写了个nagios的 nrpe plugins.用来监控当前memcached 连接数
对于nagios上monitor memcached,还有很多种方式,常见的一般是检查网络超时,检查命中率,检查当前使用率等等.
比较成熟的有p5-Nagios-Plugins-Memcached.
check_memcached_conns.rar
http://www.monitoringexchange.org/cgi-bin/page.cgi?g=Detailed%2F3106.html;d=1
相关文章
- 无相关文章
《负载均衡的开源解决方案--HAProxy》 PPT
提交: åæ 14 , 2009, 4:26am CEST 由 finalbsd

在Chinaunix.net 上海技术沙龙上演讲的PPT。CU上管理员贴出的有修改、有删节,具体原因未知。应朋友要求,这里贴出原版。
因为是演讲稿不是书,所以内容不可能非常详尽。
负载均衡的开源解决方案--HAProxy.ppt
相关文章- 2009-02-28 -- HAProxy">[http-check支持返回内容检查的补丁">HAProxy] http-check支持返回内容检查的补丁
- 2009-02-19 -- 给haproxy写的一个patch
- 2008-06-26 -- 一个IP能建立的最大连接数是多少?
keepalived权威指南
提交: åæ 13 , 2009, 3:11pm CEST 由 finalbsd
根据自己的研究和使用经验写的, 可自由分发,但希望给我反馈,使这份文档更完善起来,目前的内容可能还不是非常完善。Keepalived权威指南.pdf
相关文章
- 无相关文章
读cat源码
提交: åæ 13 , 2009, 10:10am CEST 由 i_amok
围观地址:
http://www.scribd.com/doc/14179946/Cat
相关文章- 无相关文章
date.c源码初读
提交: ä¸æ 31 , 2009, 9:51am CEST 由 i_amok
i_amk:作品:
围观地点如下:
http://www.scribd.com/doc/13802411/Date
相关文章
- 无相关文章
Linux下显示硬件信息(二)--lshw
提交: ä¸æ 17 , 2009, 5:27am CET 由 finalbsd
lshw
lshw(Hardware Lister)是另外一个可以查看硬件信息的工具,不仅如此,它还可以用来做一些硬件的benchmark。
这个工具其实就是用/proc里面读取一些文件来显示相关的信息,它用到了如下文件和目录(下的文件):
/proc/cpuinfo 显示CPU信息
/proc/bus/pci 显示pci信息
/proc/scsi 显示scsi信息
/proc/net/dev 显示网络设备信息
/proc/kcore 从内存映像读取相关信息
/proc/ide 显示IDE设备信息
/proc/devices
/proc/mounts
/proc/fstab下载和安装:
-------------------------------------------------------------
cd /tmp
wget [ezix.org]
tar lshw-B.02.14.tar.gz
cd lshw-B.02.14
make && make install
-------------------------------------------------------------
用法:
1.最简单的用法:
# lshw
和dmidecode一样,输出一大堆的东西。
2. 以html/xml格式输出
# lshw -html >info.html
# lshw -xml >info.xml3. 显示设备列表,输出包括设备路径(path)、类别(class)以及简单描述
# lshw -short
4. 显示设备列表,输出包括总线信息、SCSI、USB、IDE、PCI地址等。
# lshw -businfo
5. 显示指定类别的设备
# lshw -C class
# lshw -class class
这里的class可以通过lshw -short来查看。比如
# lshw -C memory
相对来说lshw相信的信息比较简单,没有dmidecode丰富。
相关文章- 2009-03-17 -- Linux下硬件信息查看(一)–dmidecode
Linux下硬件信息查看(一)--dmidecode
提交: ä¸æ 17 , 2009, 3:57am CET 由 finalbsd
Dmidecode
dmidecode以一种可读的方式dump出机器的DMI(Desktop Management Interface)信息。这些信息包括了硬件以及BIOS,既可以得到当前的配置,也可以得到系统支持的最大配置,比如说支持的最大内存数等。
DMI有人也叫SMBIOS(System Management BIOS),这两个标准都由DMTF(Desktop Management Task Force)开发。dmidecode的输出格式一般如下:
----------------------------------------
Handle 0x0002
DMI type 2, 8 bytes
Base Board Information
Manufacturer:Intel
Product Name: C440GX+
Version: 727281-0001
Serial Number: INCY92700942
----------------------------------------
其中的前三行都称为记录头(recoce Header), 其中包括了:
1、recode id(handle): DMI表中的记录标识符,这是唯一的,比如上例中的Handle 0x0002。
2、dmi type id: 记录的类型,譬如说:BIOS,Memory,上例是type 2,即"Base Board Information"
3、recode size: DMI表中对应记录的大小,上例为8 bytes.(不包括文本信息,所有实际输出的内容比这个size要更大。)
记录头之后就是记录的值:
4、decoded values: 记录值可以是多行的,比如上例显示了主板的制造商(manufacturer)、model、version以及serial Number。
dmidecode的使用方法
1. 最简单的的显示全部dmi信息:
# dmidecode
这样将输出所有的dmi信息,你可能会被一大堆的信息吓坏,通常可以使用下面的方法。
2.更精简的信息显示:
# dmidecode -q
-q(--quite) 只显示必要的信息,这个很管用哦。
3.显示指定类型的信息:
通常我只想查看某类型,比如CPU,内存或者磁盘的信息而不是全部的。这可以使用-t(--type TYPE)来指定信息类型:
# dmidecode -t bios
# dmidecode -t bios, processor (这种方式好像不可以用,必须用下面的数字的方式)
# dmidecode -t 0,4 (显示bios和processor)
dmidecode到底支持哪些type?
这些可以在man dmidecode里面看到:
文本参数支持:
bios, system, baseboard, chassis, processor, memory, cache, connector, slot
数字参数支持很多:(见附录)
4.通过关键字查看信息:
比如只想查看序列号,可以使用:
# dmidecode -s system-serial-number
-s (--string keyword)支持的keyword包括:
-------------------------------------------------------------------------------------
bios-vendor,bios-version, bios-release-date,
system-manufacturer, system-product-name, system-version, system-serial-number,
baseboard-manu-facturer,baseboard-product-name, baseboard-version, baseboard-serial-number, baseboard-asset-tag,
chassis-manufacturer, chas-sis-version, chassis-serial-number, chassis-asset-tag,
processor-manufacturer, processor-version.
-------------------------------------------------------------------------------------
5.示例
5.1 查看当前内存和支持的最大内存
Linux下,可以使用free或者查看meminfo来获得当前的物理内存:
# free
total used free shared buffers cached
Mem: 8182532 8010792 171740 0 148472 4737896
-/+ buffers/cache: 3124424 5058108
Swap: 4192956 3304 4189652
# grep MemTotal /proc/meminfo
MemTotal: 8182532 kB
这里显示了当前服务器的物理内存是8GB。
服务器到底能扩展到多大的内存?#dmidecode -t 16
# dmidecode 2.7
SMBIOS 2.4 present.Handle 0x0013, DMI type 16, 15 bytes.
Physical Memory Array
Location: System Board Or Motherboard
Use: System Memory
Error Correction Type: Multi-bit ECC
Maximum Capacity: 64 GB (可扩展到64GB)
Error Information Handle: Not Provided
Number Of Devices: 4
但是,事实不一定如此,因此插槽可能已经插满了。也就是我们还必须查清这里的8G到底是4*2GB, 2*4GB还是其他?
如果是4*2GB,那么尽管可以扩展到64GB,但是插槽已经插满,无法扩展了:
#dmidecode -t 17
# dmidecode 2.7
SMBIOS 2.4 present.Handle 0x0015, DMI type 17, 27 bytes.
Memory Device
Array Handle: 0x0013
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB 【插槽1有1条2GB内存】
Form Factor: DIMM
Set: None
Locator: DIMM00
Bank Locator: BANK
Type: Other
Type Detail: Other
Speed: 667 MHz (1.5 ns)
Manufacturer:
Serial Number: BZACSKZ001
Asset Tag: RAM82
Part Number: MT9HTF6472FY-53EA2Handle 0x0017, DMI type 17, 27 bytes.
Memory Device
Array Handle: 0x0013
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB 【插槽2有1条2GB内存】
Form Factor: DIMM
Set: None
Locator: DIMM10
Bank Locator: BANK
Type: Other
Type Detail: Other
Speed: 667 MHz (1.5 ns)
Manufacturer:
Serial Number: BZACSKZ001
Asset Tag: RAM83
Part Number: MT9HTF6472FY-53EA2Handle 0x0019, DMI type 17, 27 bytes.
Memory Device
Array Handle: 0x0013
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB 【插槽3有1条2GB内存】
Form Factor: DIMM
Set: None
Locator: DIMM20
Bank Locator: BANK
Type: Other
Type Detail: Other
Speed: 667 MHz (1.5 ns)
Manufacturer:
Serial Number: BZACSKZ001
Asset Tag: RAM84
Part Number: MT9HTF6472FY-53EA2Handle 0x001B, DMI type 17, 27 bytes.
Memory Device
Array Handle: 0x0013
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB 【插槽4有1条2GB内存】
Form Factor: DIMM
Set: None
Locator: DIMM30
Bank Locator: BANK
Type: Other
Type Detail: Other
Speed: 667 MHz (1.5 ns)
Manufacturer:
Serial Number: BZACSKZ001
Asset Tag: RAM85
Part Number: MT9HTF6472FY-53EA2
根据上面输出可以发现,如果要扩展,只有将上面的内存条换成16GB的,才能达到4*16GB=64GB的最大支持内存。
附录:
dmidecode支持的数字参数:
Type Information
----------------------------------------
0 BIOS
1 System
2 Base Board
3 Chassis
4 Processor
5 Memory Controller
6 Memory Module
7 Cache
8 Port Connector
9 System Slots
10 On Board Devices
11 OEM Strings
12 System Configuration Options
13 BIOS Language
14 Group Associations
15 System Event Log
16 Physical Memory Array
17 Memory Device
18 32-bit Memory Error
19 Memory Array Mapped Address
20 Memory Device Mapped Address
21 Built-in Pointing Device
22 Portable Battery
23 System Reset
24 Hardware Security
25 System Power Controls
26 Voltage Probe
27 Cooling Device
28 Temperature Probe
29 Electrical Current Probe
30 Out-of-band Remote Access
31 Boot Integrity Services
32 System Boot
33 64-bit Memory Error
34 Management Device
35 Management Device Component
36 Management Device Threshold Data
37 Memory Channel
38 IPMI Device
39 Power Supply
相关文章- 2009-03-17 -- Linux下显示硬件信息(二)–lshw
KeePass和PuTTY的结合使用--自动登陆
提交: ä¸æ 12 , 2009, 5:45am CET 由 finalbsd
KeePass 是常用的密码设置和保存工具,PuTTY 是常用的服务器登陆工具,我们常常的操作是在KeePass 里面保存密码,登陆的时候将密码CP出来,用PuTTY 进行登陆,但其实KeePass 里面已经可以直接调用PuTTY ,双击就可以自动输入密码登陆了,起码省略了打开PuTTY ,CP密码,Paste之,然后登陆的几个步骤,配置如下:
1.PuTTY配置
PuTTY的配置很简单,这里关键要用到session name,这里假设的session name为login Server如图: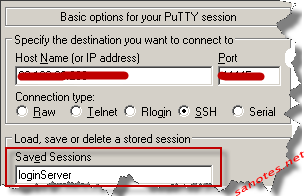
2.KeePass的配置:
如图:AddEntry,其中几项设置:
发件人 sanotes.net -Title: 使用PuTTY中的session名.(不是要登陆的IP地址)
-Username: 登陆的用户名
-Password: 密码
-URL: 这是关键,这里将直接调用putty,配置如:cmd://putty.exe -l {USERNAME} -load {TITLE} -pw {PASSWORD}
1). cmd://表示使用命令行的putty.exe,这个必须和KeePass放在同一个目录,如果不在同一目录,可以使用KeePass提供的宏{APPDIR}来设置putty.exe的具体路径。URL其实还可以是别的比如 [www.example.com] 或者是ssh://等。
2). 后面就是putty的命令行设置了:
2.1) -l {USERNAME} 指定用户名,{USERNAME}是KeePass提供的宏,就是上面说的Username配置;
2.2) -pw {PASSWORD} 类似用户名,指定密码;
2.3) -load {TITLE} 其中的{TITLE}也是Keepass提供的宏,就是指PuTTY 中的session名。现在保存下配置,然后CTRL+U就可以很畅快的登陆服务器了,不需要输入任何东西了。hoho
相关文章- 无相关文章
SSH很快,scp巨慢的问题
提交: ä¸æ 11 , 2009, 5:52am CET 由 finalbsd
不久前遇到一个很诡异的问题,SSH很快,scp巨慢,查了很久没查出根源所在,几乎崩溃。幸好今天tonnyom找到了答案,哈哈,太强大了!!
2.9 - sftp/scp fails at connection, but ssh is OK.
sftp and/or scp may fail at connection time if you have shell initialization (.profile, .bashrc, .cshrc, etc) which produces output for non-interactive sessions. This output confuses the sftp/scp client. You can verify if your shell is doing this by executing:ssh yourhost /usr/bin/true
If the above command produces any output, then you need to modify your shell initialization.
发现在.bashrc里面因为程序员需要在secureCRT上显示标签,加入了:
echo -ne "e]2;${USER}@${HOSTNAME}a"去掉一切OK。
但是使用secureCRT又需要标签的同志是无法忍受的,因此设置的方法改为:
在/etc/sysconfig/bash-prompt-default里面加入:
echo -ne "e]2;${USER}@${HOSTNAME}a"相关文章
- 无相关文章
NetScaler中使用ACL做IP访问限制
提交: ä¸æ 10 , 2009, 6:39am CET 由 finalbsd

NetScaler 中的ACL规则有点类似Iptables ,匹配的顺序也是先匹配第一条规则,如果匹配到了,后面的规则会直接跳过。当然匹配的顺序还与priority有关,越低越先匹配:
比如有这样的需求,仅允许如下IP访问:
1. 192.168.1.0/24
2. 172.16.1.0/24
其他都拒绝。
访问的目的地址是10.10.1.1-10add ns acl whitelist ALLOW -srcIP = 192.168.1.1-192.168.1.255 -destIP = 10.10.1.1-10.10.1.10 -destPort = 80 -protocol TCP -priority 1 -kernelstate SFAPPLIED61
add ns acl whitelist2 ALLOW -srcIP = 172.16.1.1-172.16.1.255 -destIP = 10.10.1.1-10.10.1.10 -destPort = 80 -protocol TCP -priority 2 -kernelstate SFAPPLIED61
add ns acl badip DENY -destIP = 10.10.1.1-10.10.1.10 -destPort = 80 -protocol TCP -priority 3 -kernelstate SFAPPLIED61
apply ns acls
如上,priority 分别为1,2,3先检查允许的,其他都DENY。
需要注意的地方有:
1.priority的设置一定要符合它的匹配顺序;
2.配置完之后要将 -kernelstate设置为SFAPPLIED61而不是NOTAPPLIED(这要在CLI设置或者在GUI配置里Commit),否则不会生效。
3.NS的ACL是全局的,也就是说无法针对某个Vserver来绑定ACL,这和Content Switch类似。我们只能针对Vserver的VIP来进行配置。
相关文章- 2008-06-26 -- 一个IP能建立的最大连接数是多少?
Tips: Disk Performance On FreeBSD相关推荐
- Remote Development Tips and Tricks
目录 SSH tips# Configuring key based authentication# Quick start: Using SSH keys# Improving your secur ...
- 曙光服务器bios 虚拟化,中科曙光虚拟化培训教程汇总:Troubleshooting Storage Performance for ESXi...
<中科曙光虚拟化培训教程汇总:Troubleshooting Storage Performance for ESXi>由会员分享,可在线阅读,更多相关<中科曙光虚拟化培训教程汇总: ...
- 简要安装FreeBSD 6.2及配置桌面环境[zz]
简要安装FreeBSD 6.2及配置桌面环境[zz]June 25th, 2007 这里的安装过程其实也很简单,在这里我不打算讲解虚拟机 vmware 上的安装(因为和实际的环境相差不大.同时,这个安 ...
- sysctl优化linux网络
引自:http://blog.chinaunix.net/space.php?uid=20746343&do=blog&id=730129 sysctl优化linux网络 1, 优 ...
- 【运维实战】1.FastDFS分布式的文件存储系统入门介绍与实践
本章目录 0x00 基础介绍 0.前言 1.简介 2.特性 3.架构 Tracker Server Storage Server Client 4.存储策略 5.过程剖析 文件上传 - Upload ...
- 网络故障的技术一些东东
IT 精品杂志 一个互联网的时代,一个知识以几何速度增长的时代,当人们在讨论知识的快速扩展会给人们带来什么的时候,知识的增长的速度不为人类意识的缓慢而依旧快速增加着.我们能做的有什么--,只能是接受, ...
- ubuntu 装在ssd_如何在Ubuntu中调整SSD以提高性能
ubuntu 装在ssd There are lots of tips out there for tweaking your SSD in Linux and lots of anecdotal r ...
- Vmware Links(转自VMware-land)
这一阵子在专研虚拟机的VSS备份,无意中发现了VMware-land 很好的网站,不知道为什么无法访问,难道也被和谐掉了??? 以下内容是从Google的页面缓存弄出来的,在Google搜索http: ...
- linux,unix,bsd命令收集
这是一份收集Unix/Linux/BSD命令和任务的文档,它有助于高级用户或IT工作.它是一份简明扼要的实用指南,当然读者应该知道他/她在干什么. Unix Toolbox 版本:12 你可以到 ht ...
最新文章
- Linux入门第四集!Jar包的入门、使用、部署!怎么打Jar包?
- Charles使用1
- ajax和rxjs,javascript – RxJS 5 Observable和Angular2 http:调用ajax一次,保存结果,随后的ajax调用使用缓存结果...
- Spark Executor解析
- Java并发编程实战~Guarded Suspension模式
- 统计学习方法笔记(李航)———第三章(k近邻法)
- Kendo UI开发教程(9): Kendo UI Validator 概述
- mysql重新构建自增长_mysql 建表后 重新构建 自增字段 (保留 原有字段结构)
- 物联网架构-Nginx负载均衡
- 不小心发现谷歌 Firebase 消息服务的漏洞,获奖3万+美元
- java 单元测试 异步_java - 如何使用CountdownLatch对异步代码进行单元测试同步 - 堆栈内存溢出...
- Windows 8 Directx 开发学习笔记(七)水波纹的实现
- ORB_SLAM2中的疑难杂症
- web安全day26:今天,算是把linux的用户管理弄明白了
- expdp 字符集从ZHS16GBK到AL32UTF8
- Linux宝库名人轶事栏目 | 智能化之边缘计算浅析
- Hibernate中Java对象的生命周期
- PostgreSQL 删除表格
- java简单记事本代码_Java实现的简易记事本
- mayapython常用模块_Maya入门之在Maya 中使用 Python 的基础知识有那些
热门文章
- Notes Twenty-third days-渗透攻击-红队-红队自研
- OpenWrt设置路由器联网(无线)
- 什么是零知识证明?Tokenview
- sklearn笔记29 线性回归 天猫双十一销量预测
- 如何关闭百度网盘超级会员自动续费服务?
- python如何开发网站_如何用Python写一个小网站?
- 燃起图与燃尽图,故事地图和产品线路图分析
- 华为桌面小程序在哪里_微信Windows版更新至3.0:批量管理联系人,小程序可添加至桌面...
- vulnhub靶机ME AND MY GIRLFRIEND: 1
- matlab计算aqi代码,AQI计算第一课,爬取全部城市AQI数据的代码一样但是只能爬出第一个城市的数据是怎么回事?...