date_histogram
用法
Date histogram的用法与histogram差不多,只不过区间上支持了日期的表达式。
{
"aggs":{"articles_over_time":{"date_histogram":{"field":"date","interval":"month"}}}
}interval字段支持多种关键字:`year`, `quarter`, `month`, `week`, `day`, `hour`, `minute`, `second`
当然也支持对这些关键字进行扩展使用,比如一个半小时可以定义成如下:
{"aggs":{"articles_over_time":{"date_histogram":{"field":"date","interval":"1.5h"}}}
}返回的结果可以通过设置format进行格式化:
{"aggs":{"articles_over_time":{"date_histogram":{"field":"date","interval":"1M","format":"yyyy-MM-dd"}}}}得到的结果如下:
{"aggregations":{"articles_over_time":{"buckets":[{"key_as_string":"2013-02-02","key":1328140800000,"doc_count":1},{"key_as_string":"2013-03-02","key":1330646400000,"doc_count":2},...]}}
}其中key_as_string是格式化后的日期,key显示了是日期时间戳,
time_zone时区的用法
在es中日期支持时区的表示方法,这样就相当于东八区的时间。
{"aggs":{"by_day":{"date_histogram":{"field":"date","interval":"day","time_zone":"+08:00"}}}
}offset 使用偏移值,改变时间区间
默认情况是从凌晨0点到午夜24:00,如果想改变时间区间,可以通过下面的方式,设置偏移值:
{"aggs":{"by_day":{"date_histogram":{"field":"date","interval":"day","offset":"+6h"}}}
}那么桶的区间就改变为:
"aggregations":{"by_day":{"buckets":[{"key_as_string":"2015-09-30T06:00:00.000Z","key":1443592800000,"doc_count":1},{"key_as_string":"2015-10-01T06:00:00.000Z","key":1443679200000,"doc_count":1}]}
}Missing Value缺省字段
当遇到没有值的字段,就会按照缺省字段missing value来计算:
{"aggs":{"publish_date":{"date_histogram":{"field":"publish_date","interval":"year","missing":"2000-01-01"}}}
}其他
对于其他的一些用法,这里就不过多赘述了,比如脚本、Order、min_doc_count过滤,extended_bounds等都是支持的。
按时间统计编辑
(测试数据:http://blog.csdn.net/wwd0501/article/details/78501842)如果搜索是在 Elasticsearch 中使用频率最高的,那么构建按时间统计的 date_histogram 紧随其后。为什么你会想用 date_histogram 呢?
假设你的数据带时间戳。 无论是什么数据(Apache 事件日志、股票买卖交易时间、棒球运动时间)只要带有时间戳都可以进行 date_histogram 分析。当你的数据有时间戳,你总是想在 时间 维度上构建指标分析:
- 今年每月销售多少台汽车?
- 这只股票最近 12 小时的价格是多少?
- 我们网站上周每小时的平均响应延迟时间是多少?
虽然通常的 histogram 都是条形图,但 date_histogram 倾向于转换成线状图以展示时间序列。 许多公司用 Elasticsearch _仅仅_ 只是为了分析时间序列数据。 date_histogram 分析是它们最基本的需要。
date_histogram 与 通常的 histogram 类似。 但不是在代表数值范围的数值字段上构建 buckets,而是在时间范围上构建 buckets。 因此每一个 bucket 都被定义成一个特定的日期大小 (比如, 1个月 或 2.5 天)。
可以用通常的 histogram 进行时间分析吗?
通常的 histogram 会把日期看做是数字,这意味着你必须以微秒为单位指明时间间隔。另外聚合并不知道日历时间间隔,使得它对于日期而言几乎没什么用处。
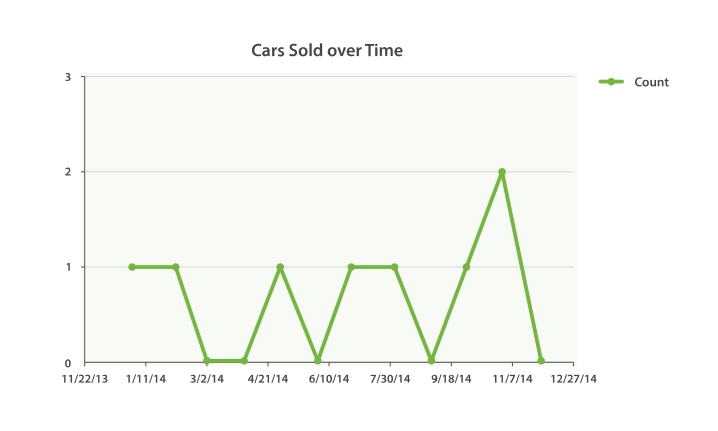
我们的第一个例子将构建一个简单的折线图来回答如下问题: 每月销售多少台汽车?
GET /cars/transactions/_search
{"size" : 0,"aggs": {"sales": {"date_histogram": {"field": "sold","interval": "month",  "format": "yyyy-MM-dd"
"format": "yyyy-MM-dd"  }}}
}
}}}
}
|
|
时间间隔要求是日历术语 (如每个 bucket 1 个月)。 |
|
|
我们提供日期格式以便 buckets 的键值便于阅读。 |
我们的查询只有一个聚合,每月构建一个 bucket。这样我们可以得到每个月销售的汽车数量。 另外还提供了一个额外的 format 参数以便 buckets 有 "好看的" 键值。 然而在内部,日期仍然是被简单表示成数值。这可能会使得 UI 设计者抱怨,因此可以提供常用的日期格式进行格式化以更方便阅读。
结果既符合预期又有一点出人意料(看看你是否能找到意外之处):
{..."aggregations": {"sales": {"buckets": [{"key_as_string": "2014-01-01","key": 1388534400000,"doc_count": 1},{"key_as_string": "2014-02-01","key": 1391212800000,"doc_count": 1},{"key_as_string": "2014-05-01","key": 1398902400000,"doc_count": 1},{"key_as_string": "2014-07-01","key": 1404172800000,"doc_count": 1},{"key_as_string": "2014-08-01","key": 1406851200000,"doc_count": 1},{"key_as_string": "2014-10-01","key": 1412121600000,"doc_count": 1},{"key_as_string": "2014-11-01","key": 1414800000000,"doc_count": 2}]
...
}
聚合结果已经完全展示了。正如你所见,我们有代表月份的 buckets,每个月的文档数目,以及美化后的 key_as_string 。
返回空 Buckets编辑
是的,结果没错。 我们的结果少了一些月份! date_histogram (和 histogram 一样)默认只会返回文档数目非零的 buckets。
这意味着你的 histogram 总是返回最少结果。通常,你并不想要这样。对于很多应用,你可能想直接把结果导入到图形库中,而不想做任何后期加工。
事实上,即使 buckets 中没有文档我们也想返回。可以通过设置两个额外参数来实现这种效果:
GET /cars/transactions/_search
{"size" : 0,"aggs": {"sales": {"date_histogram": {"field": "sold","interval": "month","format": "yyyy-MM-dd","min_doc_count" : 0, "extended_bounds" : { "min" : "2014-01-01","max" : "2014-12-31"}}}}
}
|
|
这个参数强制返回空 buckets。 |
|
|
这个参数强制返回整年。 |
这两个参数会强制返回一年中所有月份的结果,而不考虑结果中的文档数目。 min_doc_count 非常容易理解:它强制返回所有 buckets,即使 buckets 可能为空。
extended_bounds 参数需要一点解释。 min_doc_count 参数强制返回空 buckets,但是 Elasticsearch 默认只返回你的数据中最小值和最大值之间的 buckets。
因此如果你的数据只落在了 4 月和 7 月之间,那么你只能得到这些月份的 buckets(可能为空也可能不为空)。因此为了得到全年数据,我们需要告诉 Elasticsearch 我们想要全部 buckets, 即便那些 buckets 可能落在最小日期 之前 或 最大日期 之后 。
extended_bounds 参数正是如此。一旦你加上了这两个设置,你可以把得到的结果轻易地直接插入到你的图形库中,从而得到类似 图 37 “汽车销售时间图” 的图表。
图 37. 汽车销售时间图
- /**
- * Description:按时间统计聚合,用于各种图表数据的聚合
- * 按时间统计:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_looking_at_time.html
- * 例: 每月销售多少台汽车
- *
- * @author wangweidong
- * CreateTime: 2017年11月10日 上午10:17:54
- *
- * 返回空buckets处理:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_returning_empty_buckets.html
- *
- * extended_bounds 参数需要一点解释。 min_doc_count 参数强制返回空 buckets,但是 Elasticsearch 默认只返回你的数据中最小值和最大值之间的 buckets。
- 因此如果你的数据只落在了 4 月和 7 月之间,那么你只能得到这些月份的 buckets(可能为空也可能不为空)。
- 因此为了得到全年数据,我们需要告诉 Elasticsearch 我们想要全部 buckets, 即便那些 buckets 可能落在最小日期 之前 或 最大日期 之后 。
- */
- @Test
- public void dataHistogramAggregation() {
- try {
- String index = "cars";
- String type = "transactions";
- SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index).setTypes(type);
- DateHistogramAggregationBuilder field = AggregationBuilders.dateHistogram("sales").field("sold");
- field.dateHistogramInterval(DateHistogramInterval.MONTH);
- // field.dateHistogramInterval(DateHistogramInterval.days(10))
- field.format("yyyy-MM");
- field.minDocCount(0);//强制返回空 buckets,既空的月份也返回
- field.extendedBounds(new ExtendedBounds("2014-01", "2014-12"));// Elasticsearch 默认只返回你的数据中最小值和最大值之间的 buckets
- searchRequestBuilder.addAggregation(field);
- searchRequestBuilder.setSize(0);
- SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
- System.out.println(searchResponse.toString());
- Histogram histogram = searchResponse.getAggregations().get("sales");
- for (Histogram.Bucket entry : histogram.getBuckets()) {
- // DateTime key = (DateTime) entry.getKey();
- String keyAsString = entry.getKeyAsString();
- Long count = entry.getDocCount(); // Doc count
- System.out.println(keyAsString + ",销售" + count + "辆");
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
文章参考: https://www.elastic.co/guide/cn/elasticsearch/guide/current/_looking_at_time.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_returning_empty_buckets.html
date_histogram相关推荐
- elasticsearch date_histogram
(5)Date Histogram Aggregation 时间直方图聚合,专门对时间类型的字段做直方图聚合.这种需求是比较常用见得的,我们在统计时,通常就会按照固定的时间断(1个月或1年等)来做统计 ...
- es 按照时间分组 date_histogram
按照时间分组 sql java实现 sql http://ip:9200/_sql?sql=select count(cf.serial_no.raw),sum(cf.educate_amount) ...
- SpringBoot 操作 ElasticSearch 详解(万字长文)
点击上方"方志朋",选择"设为星标" 回复"666"获取新整理的面试文章 作者:超级小豆丁 http://www.mydlq.club/ar ...
- elasticsearch数据长期保存的方案
Elasticsearch的数据就存储在硬盘中.当我们的访问日志非常大时,kabana绘制图形的时候会非常缓慢.而且硬盘空间有限,不可能保存所有的日志文件.如果我们想获取站点每天的重要数据信息,比如每 ...
- 搜索引擎(Elasticsearch聚合分析)
2019独角兽企业重金招聘Python工程师标准>>> 学习目标 掌握聚合分析的查询语法. 掌握指标聚合.桶聚合的用法 聚合分析简介 ES聚合分析是什么? 聚合分析是数据库中重要的功 ...
- 万字长文:详解 Spring Boot 中操作 ElasticSearch
点击上方蓝色"程序猿DD",选择"设为星标" 回复"资源"获取独家整理的学习资料! 作者 | 超级小豆丁 来源 | http://www.m ...
- elasticearch 多种查询参数用法:
range过滤器查询范围 gt: > 大于 lt: < 小于 gte: >= 大于或等于 lte: <= 小于或等于 多个range 'query': {"bool& ...
- elasticsearch(7)聚合统计-分组聚合
原文:https://blog.csdn.net/sz85850597/article/details/82858831 elasticsearch(7)聚合统计-分组聚合 2018年09月26日 2 ...
- linux下ELK搭建好之后配置sentinl插件,进行邮件告警
ELK的环境搭建好之后,如何利用收集到的数据进行数据告警呢?在破解ELK之后,它本身提供一个监视器功能,配置偏向编写脚本.有一个更加方便的插件sentiel. 一.下载并安装sentinl插件 htt ...
- elasticsearch 客户端工具_万字长文:详解 Spring Boot 中操作 ElasticSearch
点击上方"小强的进阶之路",选择"星标"公众号 优质文章,及时送达 预计阅读时间: 15分钟 一.ElasticSearch 简介 1.简介 ElasticSe ...
最新文章
- linux sqlplus 密码有$
- 关于RGB屏调试的一些知识(转)
- Java面向对象(1)--对象的创建使用类的实例化
- Myeclipse修改设置Default VM Arguments
- 【转】75个最佳Web设计资源
- Vim 还是 Emacs
- 【路径规划】基于matlab GUI多种蚁群算法栅格地图路径规划【含Matlab源码 650期】
- 提高专业技能之 “完整DataSheet”
- 基于Edge插件+格式工厂下载B站上的喜欢视频
- 摄像头设计工程师面试技巧_系统设计面试准备的5个技巧
- html元素的默认样式,CSS重置,常见元素的默认样式
- uniapp,小程序,实现签名功能
- C# 串口接收的优化处理
- 苹果自带高德地图搜索周边功能
- excel多元回归-系数参数解读
- 下单账号与支付账号不一致,请核实后再支付 问题原因
- C语言高级部分总结,也是面试官会经常问的问题哦~
- ZCMU-1720-死亡如风,我要装逼
- Boosting和Bagging区别
- 微信小程序中的图片处理