Python获取逐浪小说内容
本人喜欢在网上看小说,一直使用的是小说下载阅读器,可以自动从网上下载想看的小说到本地,比较方便。最近在学习Python的爬虫,受此启发,突然就想到写一个爬取小说内容的脚本玩玩。于是,通过在逐浪上面分析源代码,找出结构特点之后,写了一个可以爬取逐浪上小说内容的脚本。
具体实现功能如下:输入小说目录页的url之后,脚本会自动分析目录页,提取小说的章节名和章节链接地址。然后再从章节链接地址逐个提取章节内容。现阶段只是将小说从第一章开始,每次提取一章内容,回车之后提取下一章内容。其他网站的结果可能有不同,需要做一定修改。在逐浪测试过正常。
分享此代码,一是做个记录,方便自己以后回顾。二么也想抛砖引玉,希望各路大神不吝赐教。
下面是我用来测试的页面:http://book.zhulang.com/263736/
效果如下:
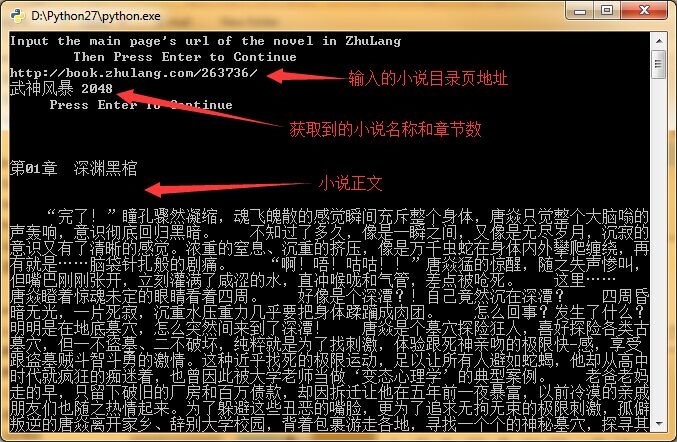
实现的源代码如下,请各位指教:
#-*-coding:utf8-*-
#!/usr/bin/python
# Python: 2.7.8
# Platform: Windows
# Program: Get Novels From Internet
# Author: wucl
# Description: Get Novels
# Version: 1.0
# History: 2015.5.27 完成目录和url提取
# 2015.5.28 完成目录中正则提取第*章,提取出章节链接并下载。在逐浪测试下载无误。from bs4 import BeautifulSoup
import urllib2,redef get_menu(url):"""Get chapter name and its url"""user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:39.0) Gecko/20100101 Firefox/39.0"headers = {'User-Agent':user_agent}req = urllib2.Request(url,headers = headers)page = urllib2.urlopen(req).read()soup = BeautifulSoup(page)novel = soup.find_all('title')[0].text.split('_')[0] # 提取小说名menu = []all_text = soup.find_all('a',target="_blank") # 提取记载有小说章节名和链接地址的模块regex=re.compile(ur'\u7b2c.+\u7ae0') # 中文正则匹配第..章,去除不必要的链接for title in all_text:if re.findall(regex,title.text):name = title.textx = [name,title['href']]menu.append(x) # 把记载有小说章节名和链接地址的列表插入列表中 return menu,noveldef get_chapter(name,url):"""Get every chapter in menu"""html=urllib2.urlopen(url).read()soup=BeautifulSoup(html)content=soup.find_all('p') # 提取小说正文return content[0].textif __name__=="__main__":url=raw_input("""Input the main page's url of the novel in ZhuLang\n Then Press Enter to Continue\n""")if url:menu,title=get_menu(url)print title,str(len(menu))+'\n Press Enter To Continue \n' # 输出获取到的小说名和章节数for i in menu:chapter=get_chapter(i[0],i[1])raw_input()print '\n'+i[0]+'\n' print chapterprint '\n'Python获取逐浪小说内容相关推荐
- python中的doc_基于Python获取docx/doc文件内容代码解析
这篇文章主要介绍了基于Python获取docx/doc文件内容代码解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 整体思路: 下载文件并修改后缀 ...
- python获取指定单元格内容_python读取excel表格指定位置的内容
今天是第一次写博客,对之前学以致用的内容做一些总结,以备日后忘了或者可以给别人提供一些帮助.话不多说,开始写内容. python读取excel表格指定位置的内容 需求:现在有一个excel表格,里面有 ...
- python美国股票数据api_【美股量化00篇】Python获取新浪接口美股实时数据
1.本篇以BABA(阿里巴巴)为例,在浏览器地址栏输入以下url,即可获取个股数据:阿里巴巴(BABA)实时数据hq.sinajs.cn import requests url = 'http:// ...
- 用python获取新浪历史分时数据
*注:文章所述内容,仅用于测试,请不要应用于商业目标,由此带来的风险,请自行承担. 新浪的历史分时数据,经过了压缩和base64处理,解码代码位于sf_sdk.js中,这一行: this.xh5_S_ ...
- python获取藏头诗内容_Watson使用指南(六)在微信公众号中实现识图作诗功能
本文章主要是写一下这个项目开发的过程及之间遇到的问题,作为记录,也希望以此为契机认识志同道合的朋友,一起学习交流. 目录: 概述 环境准备及相关账号申请 部署Python Flask应用到Bluemi ...
- python获取网页文本框内容_python识别html主要文本框
在抓取网页的时候只想抓取主要的文本框,例如 csdn 中的主要文本框为下图红色框: 抓取的思想是,利用 bs4 查找所有的 div,用正则筛选出每个 div 里面的中文,找到中文字数最多的 div 就 ...
- python爬取股票实时价格_【美股量化00篇】Python获取新浪接口美股实时数据
1.本篇以BABA(阿里巴巴)为例,在浏览器地址栏输入以下url,即可获取个股数据: http://hq.sinajs.cn/list=gb_baba (股票代码必须为小写字母,结果如下图所示) 阿里 ...
- python接收邮件内容启动程序_如何使用python获取电子邮件的文本内容?
在多部分电子邮件中,email.message.Message.get_payload()返回一个列表,其中包含每个部分的一个项目.最简单的方法是步行消息并获取每个部分的有效载荷: import em ...
- python获取excel单元格内容作为文件名_python——根据电子表格的数据自动查找文件...
最近刚接触python,找点小任务来练练手,希望自己在实践中不断的锻炼自己解决问题的能力. 经理最近又布置了一个很繁琐的任务给我:有一项很重大的项目做完了,但是要过审计(反正就是类似的审批之类的事情) ...
- python获取藏头诗内容_用Python作诗,生活仍有诗和远方
具体步骤: 使用爬虫爬取全唐诗,总共抓取了71000首. #使用urllib3的内置函数构建爬虫的安全验证,来应对网站的反爬虫机制 http = urllib3.PoolManager( cert_r ...
最新文章
- jQuery 1.9 移除了 $.browser 的替代方法
- AC日记——传染病控制 洛谷 P1041
- List集合2-LinkedList
- SQL查询入门(下篇)
- 378. Kth Smallest Element in a Sorted Matrix 有序矩阵中第K小的元素
- python 递归函数与循环的区别_提升Python效率之使用循环机制代替递归函数
- 查找最接近的元素c语言,查找最接近的元素
- Bioconda软件安装神器:多版本并存、环境复制、环境导出
- Matlab学习记录 1
- 免费网页模板提供站推荐
- MCU —— 数码管显示笔记
- 从零实现深度学习框架——Softmax回归简介
- Js 模式对话框(转)
- 【观察】打造产业数字引擎背后,紫光云价值使命的新跃迁
- keras深度学习之猫狗分类一
- java读取服务器文件_JAVA读取服务器端文件
- sketchup生成面域插件_什么插件这么神奇,SketchUp一秒搞定99%异形建模
- Android 视频录制工具类VideoRecordUtil
- Android事件传递
- 论文阅读:Beyond Synthetic Noise: Deep Learning on Controlled Noisy Labels(2017ICML)
热门文章
- 修改串口服务器,串口虚拟化 | 串口服务器Nport 5630 设置
- 计算机总是提醒更新,电脑关机的时候总是提示系统正在更新怎么办?
- 阿里云产品推荐——专有网络 VPC
- 在element框架中使用videojs-markers插件时,无法正常引入的坑
- setheading指令_set echo on/off,set term on/off,set feedback off,set heading off命令(转)
- spring boot layui table.render 加载不了cols
- 使用JSONObject比较Java复杂对象
- win10计算机删除了怎么恢复,Win10系统删除的文件怎么恢复?
- 迅捷PDF转换器怎样转换文件格式
- SPEA2_Python