童家旺:如何用分表存储来提高性能
2019独角兽企业重金招聘Python工程师标准>>> 
来自支付宝资深数据库架构师童家旺给大家分享的关于数据存储性能优化的一点想法,他从自己的个人经验中总结了关于数据库存储的性能优化。

▲支付宝资深数据库架构师童家旺
首先,童家旺介绍了他认为的什么是优化:
第一、做任何事情最快的方法就是什么也不做。
第二、不访问不必要的数据:使用B*Tree/hash等方法定位必要的数据。使用column Store或分表的方式将数据分开存储。使用Bloom filter算法排除空值查询。
第三、合理的利用硬件来提升访问效率:使用缓存消除对数据的重复访问。使用批量处理来减少磁盘的Seek操作。使用批量处理来减少网络的Round Trip。使用SSD来提升磁盘访问效率。
响应时间和吞吐量之间的关系
1、性能。衡量完成特定任务的速度或效率。
2、响应时间。衡量系统与用户交互式多久能够发出响应。
3、吞吐量。衡量系统在单位时间里可以完成的任务量。

▲反应时间
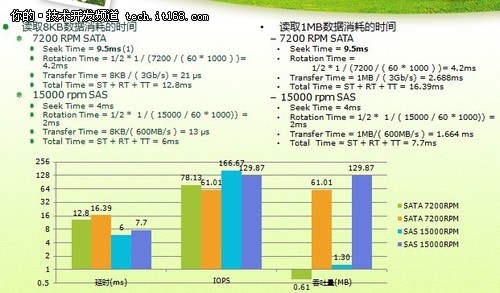
▲传统磁盘的访问特性
B*Tree优化数据访问介绍

▲B*Tree优化数据访问
B*Tree优化数据访问模拟场景

▲B*Tree优化数据访问模拟场景
童家旺通过阿里巴巴的真实应用场景介绍了如何用分表存储来提高性能。
一、场景介绍:
- 表VeryBigTable含有30个列
- 表的记录数为50,000,000条
- 平均每个用户为300条左右
- 其中有2个列属于详细描述字段,平均长度为2k
- 其它的列的总长度平均为250个字节
- 此表上的查询有两种模式
- 列出表中的主要信息(每次20条,不包含详细信息,90%的查询)
- 查看记录的详细信息(10%的查询)
- 保存与Oracle数据库,默认block_size(8k)
二、要求:
- 对此业务进行优化
- 分析数据,说服开发部门实施此优化
三、性能分析
1、每块记录数
8192 * 0.80(1) / 250 = 25.5 (主表)
8192 * 0.80 / 2000 = 3.27(详情表)
8192 * 0.80 / ( 2000 + 250 ) = 2.91
2、访问的逻辑IO(内存块访问)
List的查询代价
改进后=( 300/25.5 ) * y + 4 + x = 4 + x + 11.8y = 4(2) + 7(3) + 11.8 * 1.5(4) = 28.7
改进前=( 300/2.91 ) * y + 4 + x = 4 + x + 103.y = 4 + 7 + 103 * 1.5 = 165.5
3、访问涉及到的物理读(磁盘块访问)
List的查询代价(逻辑IO * ( 1 – 命中率 ))
改进后=28.7 * ( 1 – 0.85(5)) = 4.305
改进前=165.5 * ( 1 – 0.85 ) = 24.825
4、访问时间(ms)
改进前=逻辑IO时间+物理IO时间= 28.7 * 0.01(6) + 4.305 * 7(7) = 30.422ms
改进后=逻辑IO时间+物理IO时间= 165.5 * 0.01 + 24.825 * 7 = 175.43ms
场景
- Read Intensive (R/W 20倍以上)
- 业务可接受部分延迟(Delay)
- 每天访问量上亿次
- 系统IO压力巨大(本地内存无法容纳活跃数据)
要求
- 优化业务
方案
- 使用缓存来减少应用对后端的访问
注意事项
- 考虑缓存的刷新策略
- 考虑缓存的数据延迟对业务的影响
- 考虑缓存失效时,系统的支撑能力
参考缓存工具
MemCached, Tair, Redis
【编辑推荐】
- 主数据管理(MDM)的七个最佳实践
- SQL server的高可用性 SQL Mirror HA
- 浅谈一次恼火的死锁追踪经历
- DataReader链接关闭解惑篇
转载于:https://my.oschina.net/zyt1978/blog/670699
童家旺:如何用分表存储来提高性能相关推荐
- mysql分表存储_MySQL 分表存储的使用示例
分表存储是把记录保存在不同的表表会一个关联了在这里我们来看一篇关于MySQL 分表存储的使用示例,具体的例子如下文介绍. 一般我们项目中如果数据量特别大的话通常会考虑将某一表数据进行分表处理,例如:我 ...
- amazon rds 性能_Amazon S3 —云文件存储可提高性能并节省成本
amazon rds 性能 by Kangze Huang 黄康泽 Amazon S3 -云文件存储可提高性能并节省成本 (Amazon S3 - Cloud File Storage for Per ...
- access 分表存储_sharding:谁都能读懂的分库、分表、分区
本文通过大量图片来分析和描述分库.分表以及数据库分区是怎样进行的. 1.sharding前的初始数据分布 在本文中,我打算用高考考生相关信息作为实验数据.请无视表的字段是否符合现实,也请无视表的设计是 ...
- mysql数据库 分表存储分表查询
因为看到公司数据库商家的商品是存储在多个商品表的分表中,这里是有 0 - 9 共10个分表,就突然有了疑惑,怎么存的?查寻的时候怎么查的?怎么定位到这个商家的商品在某一个分表中? 这里简单的来记录一下 ...
- mysql年月分表_MySQL之按月拆分主表并按月分表写入数据提高数据查询速度
使用场景: 主表数据量特别大,为了提高查询的速度,可以考虑按月进行分表,要求就是当月的数据到当月表查询,上月的数据到上月表查询,当天的数据到主表来查询.这样在一定程度上也是提高了数据的查询速度 过程演 ...
- 2天,我把MySQL索引、事务、分库分表、锁、性能优化撸完了!
Java研发工程师必备技能非MySQL莫属,虽说易学好上手,但应对大厂面试,最容易遭遇滑铁卢.功败垂成的也是它. 上手简单,玩转难,才是这款开源数据库叱咤业界多年的真实写照. MySQL 8.0正式版 ...
- 也许是东半球直接底气的分库分表实践了
点击上方"方志朋",选择"设为星标" 做积极的人,而不是积极废人 背景 前不久发过两篇关于分表的文章: 一次分表踩坑实践的探讨 分表后需要注意的二三事 从标题可 ...
- MySQL 分库分表及其平滑扩容方案
作者:王克锋 出处:https://kefeng.wang/2018/07/22/mysql-sharding/ 众所周知,数据库很容易成为应用系统的瓶颈.单机数据库的资源和处理能力有限,在高并发的分 ...
- 数据库分表时OR Mapping方法
最近使用ADO.net Entity应用中遇到一个分表的应用,IDE中是不可视化支持这个的,为此使用了基于LINQ的方法解决了该问题. 数据库分表的意义和目的 分表技术顾名思义,就是把若干个存储相同类 ...
最新文章
- mbstowcs 和 wcstombs函数:C语言提供的宽字符和多字节字符转换函数
- 微软宣布推出Windows Embedded Compact 2013正式版
- 【计算机网络】聊一聊那些常见的网络通信的性能指标
- WCF常见问题及解决方案
- 香农编码二叉树c语言,shannon码的编码实验总结.docx
- python基础(16)之 日期
- mysql数据库如何配置服务_MySQL服务如何实现安装及配置
- pytorch得到中间层输出
- 使用数据库镜像保障高可用的数据库应用(下)
- 趣闻|论文不必参考任何文献?看到作者,网友大呼失敬了
- JAVA高性能I/O设计模式
- Java内存模型是什么
- Magic Swf2Gif(SWF转换GIF)绿色汉化版 V1.35
- 天才数学家连续拿下菲尔兹奖、新视野奖,专攻“最难的简单问题”,生活中还是个社牛...
- WEB应用组合——LAMP软件源码编译安装
- 记录一次帝国CMS模板被木马入侵后清理的过程,其他CMS类似【大佬勿喷】
- WSO2一般使用教程
- CV领域的对比学习综述(下)
- Type-C扩展坞支持的手机类型
- 【Unity开发小技巧】Unity打包IOS端APP