SQL Server 2019中SQL表变量延迟编译
In an article, An overview of the SQL table variable, we explored the usage of SQL table variables in SQL Server in comparison with a temporary table. Let’s have a quick recap of the table variable:
在一篇有关SQL表变量的概述中 ,我们与临时表进行了比较,探讨了SQL Server中SQL表变量的用法。 让我们快速回顾一下表变量:
- We can define a table variable and use it similar to a temporary table with few differences. The table variable scope is within the batch 我们可以定义一个表变量,并使用它类似于临时表,几乎没有区别。 表变量范围在批处理之内
- The storage location of the table variable is in the TempDB system database 表变量的存储位置在TempDB系统数据库中
- SQL Server does not maintain statistics for it. Therefore, it is suitable for small result sets SQL Server不会为其维护统计信息。 因此,它适用于较小的结果集
- It does not participate in explicit transactions 它不参与显式交易
- We cannot define indexes on table variables except primary and unique key constraints 除了主键和唯一键约束外,我们无法在表变量上定义索引
SQL表变量问题 (Issues with SQL table variables)
Let me ask a few questions to set agenda for this article:
让我问几个问题来设置本文的议程:
- Have you seen any performance issues with queries using table variables? 您是否看到过使用表变量进行查询的性能问题?
- Do you see any issues in the execution plan of a query using these table variables? 使用这些表变量,您在查询的执行计划中是否看到任何问题?
Go through the article for getting the answer to these questions in a particular way.
浏览本文,以特定的方式获得这些问题的答案。
Once we define a SQL table variable in a query, SQL Server generates the execution plan while running the query. SQL Server assumes that the table variable is empty. We insert data in a table variable during runtime. We might have an optimized execution plan of the query because SQL Server could not consider the data in the table variable. It might cause performance issues with high resource utilization. We might have a similar execution plan even if we have a different number of rows in each execution.
一旦在查询中定义了SQL表变量,SQL Server就会在运行查询时生成执行计划。 SQL Server假定表变量为空。 我们在运行时将数据插入表变量中。 我们可能有一个优化的查询执行计划,因为SQL Server无法考虑表变量中的数据。 这可能会导致资源利用率高的性能问题。 即使每次执行中行数不同,我们也可能会有类似的执行计划。
Let’s view the table variable issue in SQL Server 2017 with the following steps:
让我们通过以下步骤查看SQL Server 2017中的表变量问题:
- Set Statistics IO ON and Set Statistics Time On to capture query IO and time statistics. It will help in performing a comparison of multiple query executions 将“统计信息IO”设置为“开”并将“统计时间”设置为“开”以捕获查询IO和时间统计信息。 它将有助于执行多个查询执行的比较
- Define a table variable @Person with columns [BusinessEntityID] ,[FirstName] and [LastName]
- 用[BusinessEntityID] , [FirstName]和[LastName]列定义表变量@Person
- Insert data into table variable @person from the [Person] table in the AdventureWorks sample database 将数据从AdventureWorks示例数据库中的[Person]表插入表变量@person中
- Join the table variable with another table and view the result of the join operation 将表变量与另一个表联接,并查看联接操作的结果
- View the actual execution plan of the query 查看查询的实际执行计划
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
DECLARE @Person TABLE
([BusinessEntityID] INT, [FirstName] VARCHAR(30), [LastName] VARCHAR(30)
);
INSERT INTO @PersonSELECT [BusinessEntityID], [FirstName], [LastName]FROM [AdventureWorks].[Person].[Person];
SELECT *
FROM @Person P1JOIN [AdventureWorks].[Person].[Person] P2 ON P1.[BusinessEntityID] = P2.[BusinessEntityID];
- Note: In this article, I use 注意:在本文中,我使用ApexSQL Plan for viewing execution plans.ApexSQL Plan查看执行计划。
In the above screenshot, we can note the following.
在上面的屏幕截图中,我们可以注意以下几点。
- Estimated number of rows: 1 预计的行数:1
- The actual number of rows: 19,972 实际行数:19,972
- Actual/estimated number of rows: 1997200% 实际/估计的行数:1997200%
Really! You can imagine the difference in the calculations. SQL Server missed the estimation of actual rows counts by 1997200% for the execution plan. You can see that SQL Server could not estimate the actual number of rows. The estimated number of rows is nowhere close to actual rows. It is a big drawback that does not provide an optimized execution plan.
真! 您可以想象计算中的差异。 SQL Server未按执行计划的实际行数估算1997200%。 您可以看到SQL Server无法估计实际的行数。 估计的行数与实际行数相差甚远。 这是一个很大的缺点,它没有提供优化的执行计划。
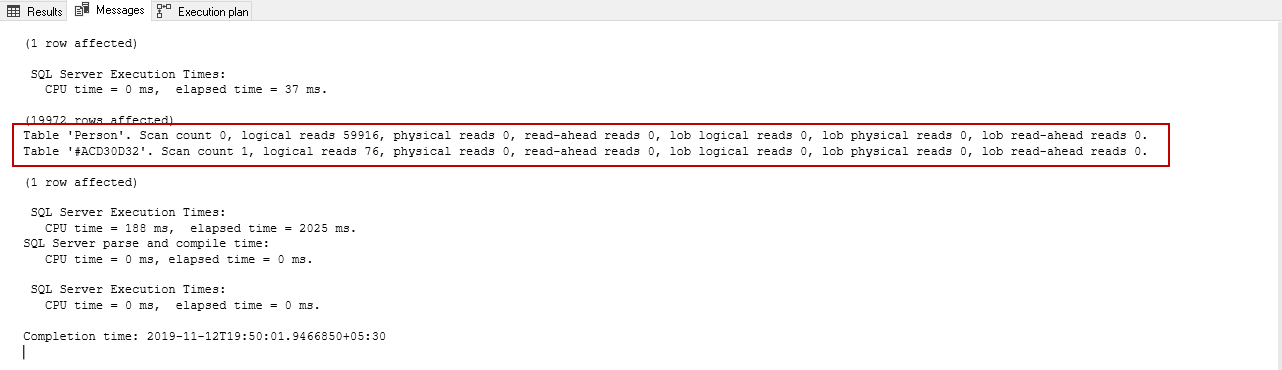
Let’s look at statistics in the message tab of SSMS. It took 59,992 logical reads (59916+76) for this query:
让我们在SSMS的消息选项卡中查看统计信息。 此查询进行了59,992逻辑读取(59916 + 76):
In SQL Server 2012 SP2 or later versions, we can use trace flag 2453. It allows SQL table variable recompilation when the number of rows changes. Execute the previous query with trace flag and observe query behavior. We can enable this trace flag at the global level using DBCC TRACEON(2453,-1) command as well:
在SQL Server 2012 SP2或更高版本中,我们可以使用跟踪标志2453。当行数更改时,它允许重新编译SQL表变量。 执行带有跟踪标志的上一个查询,并观察查询行为。 我们也可以使用DBCC TRACEON(2453,-1)命令在全局级别启用此跟踪标志:
DBCC TRACEON(2453);
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
DECLARE @Person TABLE
([BusinessEntityID] INT, [FirstName] VARCHAR(30), [LastName] VARCHAR(30)
);
INSERT INTO @PersonSELECT [BusinessEntityID], [FirstName], [LastName]FROM [AdventureWorks].[Person].[Person];
SELECT *
FROM @Person P1JOIN [AdventureWorks].[Person].[Person] P2 ON P1.[BusinessEntityID] = P2.[BusinessEntityID];
In the following screenshot of the execution plan after enabling the trace flag 2453, we can note the following:
在启用跟踪标志2453后的执行计划的以下屏幕截图中,我们可以注意以下几点:
- Estimated number of rows: 19,972 预计的行数:19,972
- The actual number of rows: 19,972 实际行数:19,972
- Actual/estimated number of rows: 100% 实际/估计的行数:100%
It improves the IO and Time statistics as well as compared to previous runs without the trace flag:
与以前的没有跟踪标志的运行相比,它改善了IO和时间统计信息:
Trace flag 2453 works similar to adding a query hint OPTION (RECOMPILE). The difference between the trace flag and OPTION(RECOMPILE) is the recompilation frequency. Let’s execute the previous query with the query hint OPTION (RECOMPILE) and view the actual execution plan:
跟踪标志2453的工作类似于添加查询提示OPTION(RECOMPILE )。 跟踪标志和OPTION(RECOMPILE)之间的差异是重新编译的频率。 让我们使用查询提示OPTION(RECOMPILE )执行上一个查询,并查看实际的执行计划:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
DECLARE @Person TABLE
([BusinessEntityID] INT, [FirstName] VARCHAR(30), [LastName] VARCHAR(30)
);
INSERT INTO @PersonSELECT [BusinessEntityID], [FirstName], [LastName]FROM [AdventureWorks].[Person].[Person];
SELECT *
FROM @Person P1JOIN [AdventureWorks].[Person].[Person] P2 ON P1.[BusinessEntityID] = P2.[BusinessEntityID]OPTION (RECOMPILE);
We can see that using query hint also improves the estimated number of rows for the SQL table variable statement:
我们可以看到,使用查询提示还可以提高SQL表变量语句的估计行数:
Trace flag recompiles the query once a predefined (internal) threshold changes for several rows while OPTION(RECOMPILE) compiles on each execution.
一旦预定义的(内部)阈值更改了几行,跟踪标志将重新编译查询,而OPTION(RECOMPILE)则在每次执行时进行编译。
SQL Server 2019中SQL表变量延迟编译 (SQL Table Variable Deferred Compilation in SQL Server 2019)
SQL Server 2017 introduced optimization techniques for improving query performance. These features are part of the Intelligent Query Processing (IQP) family.
SQL Server 2017引入了用于改善查询性能的优化技术。 这些功能是智能查询处理(IQP)系列的一部分。
In the following, image from SQL Server 2019 technical whitepaper, we can see new features introduced in SQL 2019:
下面是SQL Server 2019技术白皮书的图像,我们可以看到SQL 2019中引入的新功能:
SQL Server 2019 introduces the following new features and enhancements:
SQL Server 2019引入了以下新功能和增强功能:
- Table variable deferred compilation 表变量推迟编译
- Batch mode on a Row store 行存储中的批处理模式
- T-SQL scalar UDF Inlining T-SQL标量UDF内联
- Approximate Count Distinct 近似计数不同
- Row mode memory grant feedback 行模式内存授予反馈
Let’s explore the Table variable deferred compilation feature in SQL Server 2019. You can refer to SQL Server 2019 articles for learning these new features.
让我们探索SQL Server 2019中的Table变量延迟编译功能。您可以参考SQL Server 2019文章以学习这些新功能。
SQL Table变量推迟编译 (SQL Table variable deferred compilation)
Once SQL Server compiles a query with a table variable, it does not know the actual row count. It uses a fixed guess of estimated one row in a table variable. We have observed this behavior in the above example of SQL Server 2017.
SQL Server使用表变量编译查询后,将不知道实际的行数。 它使用表变量中估计行的固定猜测。 我们在上面SQL Server 2017示例中观察到了此行为。
SQL Server 2019 table variable deferred compilation, the compilation of the statement with a table variable is deferred until the first execution. It helps SQL Server to avoid fix guess of one row and use the actual cardinality. It improves the query execution plan and improves performance.
SQL Server 2019表变量推迟了编译,带有表变量的语句的编译被推迟到第一次执行。 它可以帮助SQL Server避免修正一行的猜测并使用实际基数。 它改善了查询执行计划并提高了性能。
To use this feature, we should have a database with compatibility level 150 in SQL Server 2019. If you have a database in another compatibility level, we can use the following query for changing it:
若要使用此功能,我们应该在SQL Server 2019中拥有一个兼容级别为150的数据库。如果您拥有另一个兼容级别的数据库,我们可以使用以下查询对其进行更改:
ALTER DATABASE [DatabaseName] SET COMPATIBILITY_LEVEL = 150;
We can use sp_helpdb command for verifying database compatibility level:
我们可以使用sp_helpdb命令来验证数据库兼容性级别:
Note: In this article, I use SQL Server 2019 general availability release announced on 4th November 2019 at Microsoft Ignite.
注意:在本文中,我使用Microsoft Ignite于2019年11月4日宣布SQL Server 2019常规可用性版本。
You should download the SQL 2019 General availability release and restore the AdventureWorks database before proceeding further with this article. We do not have a SQL 2019 version of this AdventureWorks database. You should change the database compatibility level after restoration.
您应先下载SQL 2019常规可用性版本并还原AdventureWorks数据库,然后再继续本文。 我们没有此AdventureWorks数据库SQL 2019版本。 恢复后,您应该更改数据库兼容性级别。
Execute the earlier query (without trace flag) in SQL Server 2019 database and view the actual execution plan. We do not require enabling any trace flag for SQL table variable deferred compilation.
在SQL Server 2019数据库中执行较早的查询(无跟踪标志),然后查看实际的执行计划。 我们不需要为SQL表变量延迟编译启用任何跟踪标志。
In the below screenshot, we can note the following:
在下面的屏幕截图中,我们可以注意以下几点:
- Estimated number of rows: 19,972 预计的行数:19,972
- The actual number of rows: 19,972 实际行数:19,972
- Actual/estimated number of rows: 100% 实际/估计的行数:100%
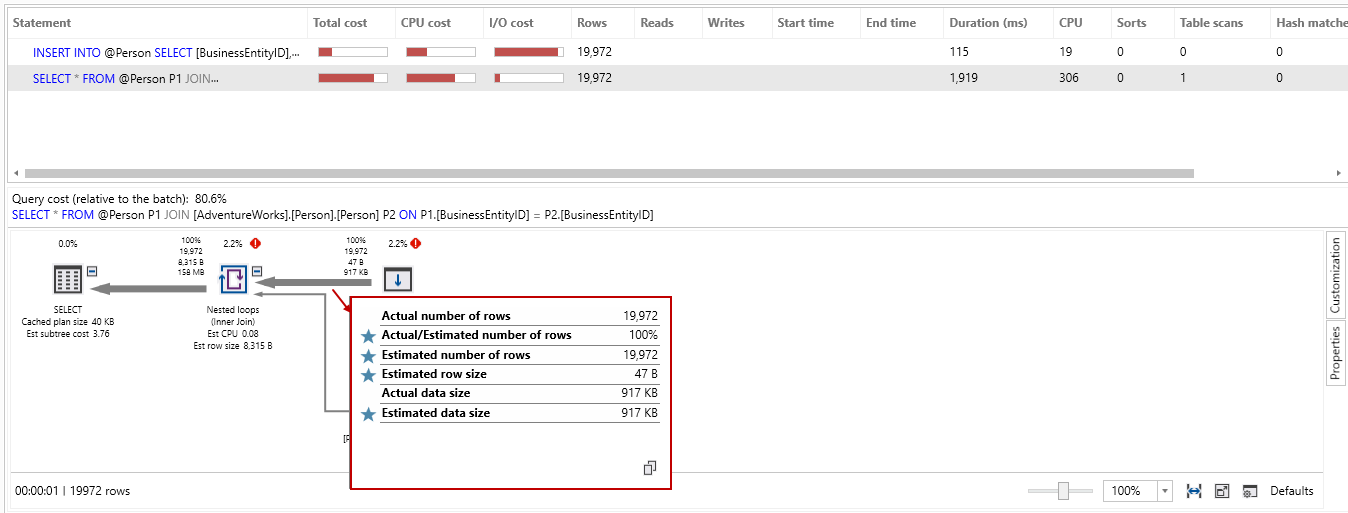
Bang on! The estimated and actual numbers of rows are the same. If we look at the statistics in SQL Server 2019, we can see it took 43,783 logical reads in comparison with 59,992 logical reads in SQL 2017. You might see more performance benefits while working with complex data and queries. My point is to show that SQL Server optimizer can match the estimation rows accurately:
! 估计的行数与实际的行数相同。 如果我们查看SQL Server 2019中的统计信息,我们可以看到与SQL 2017中的59,992个逻辑读取相比,它进行了43,783个逻辑读取。在处理复杂的数据和查询时,您可能会看到更多的性能优势。 我的观点是证明SQL Server优化程序可以准确地匹配估计行:
In the default behavior, it eliminates the requirement of:
在默认行为中,它消除了以下要求:
- Trace flag 2453 跟踪标记2453
- We can skip adding OPTION (RECOMPILE) at the statement level. It avoids any code changes, and SQL Server uses deferred compilation by default
- 我们可以跳过在语句级别添加OPTION(RECOMPILE) 。 它避免了任何代码更改,并且SQL Server默认情况下使用延迟编译
- explicit plan hints 明确的计划提示
结论 (Conclusion)
In this article, we explored the issues in query optimization with SQL table variables in SQL Server 2017 or before. It also shows the improvements in SQL Server 2019 using table variable deferred compilation. You might also face these issues. I would suggest downloading the general availability release and preparing yourself with enhancements and new features of SQL 2019.
在本文中,我们探讨了SQL Server 2017或更早版本中使用SQL表变量进行查询优化的问题。 它还显示了使用表变量延迟编译在SQL Server 2019中的改进。 您可能还会遇到这些问题。 我建议下载一般可用性版本,并为自己准备SQL 2019的增强功能和新功能。
翻译自: https://www.sqlshack.com/sql-table-variable-deferred-compilation-in-sql-server-2019/
SQL Server 2019中SQL表变量延迟编译相关推荐
- SQL截断增强功能:SQL Server 2019中的静默数据截断
In this article, we'll take a look into SQL truncate improvement in SQL Server 2019. 在本文中,我们将研究SQL S ...
- SQL Server 2019中的证书管理
介绍 (Introduction) Certificate Management in SQL Server 2019 has been enhanced a lot when compared wi ...
- SQL Server 2019中的行模式内存授予反馈
In this article, I'll be exploring another new feature with SQL Server 2019, row mode memory grant f ...
- SQL Server 2019中的图形数据库功能–第1部分
SQL Server 2017 introduced Graph database features where we can represent the complex relationship o ...
- 清空SQL Server数据库中所有表数据的方法(转)
清空SQL Server数据库中所有表数据的方法 其实删除数据库中数据的方法并不复杂,为什么我还要多此一举呢,一是我这里介绍的是删除数据库的所有数据,因为数据之间可能形成相互约束关系,删除操作可能陷入 ...
- 如何在SQL Server 2019中添加数据敏感度分类的命令
作者 | Jordan Sanders 翻译 | 火火酱.责编 | 晋兆雨 头图 | CSDN付费下载于视觉中国 为了确保数据库安全性和完整性,数据库管理员日常需要运行多种操作.因此,无论在何种情况下 ...
- SQL Server 2008中SQL增强之三:Merge(在一条语句中使用Insert,Update,Delete)
SQL Server 2008中SQL增强之三:Merge(在一条语句中使用Insert,Update,Delete) SQL Server 2008提供了一个增强的SQL命令Merge,用法参看MS ...
- SQL Server 2008中SQL应用系列及BI学习笔记系列--目录索引 @邀月
邀月 的数据库学习 http://www.cnblogs.com/downmoon/archive/2011/03/10/1980172.html SQL Server 2008中SQL应用系列及BI ...
- SQL Server 2008中SQL之WaitFor
SQL Server 2008中SQL应用系列--目录索引 在SQL Server 2005以上版本中,在一个增强的WaitFor命令,其作用可以和一个job相当.但使用更加简捷. 看MSDN: ht ...
最新文章
- mysql更新索引不影响业务_mysql索引更新要多久
- 初级php工程师应该具备什么,一名合格的PHP工程师需要掌握的知识结构
- 让oracle做定时任务【转】
- bzoj2538: [Ctsc2000]公路巡逻
- XML Tree(树形结构)
- MySQL过滤相同binlog_通过Linux命令过滤出binlog中完整的SQL语句
- spring boot 读取 application.properties 初始化bean
- Serial.println()和Serial.print() (Arduino编程)
- linux 命令api,linux命令行下字典,使用有道API
- ansible管理mysql安装初始化_[ansible]-ansible初始化mysql数据库
- ubuntu wifi固定ip_自制wifi遥控小车!ESP8266实践指南(二)
- 如何用python编程制作出表格_使用Python轻松制作漂亮的表格
- 基础编程题之奇数位(偶数位)都是奇数(偶数)
- java中自定义异常类
- dojo + jersey 上传图片到数据库
- Linux下有趣的命令
- WPF 引用 ttf文件
- ----发现一款可以代替双手的软件 “按键精灵”
- MongoDB和Compass安装教程
- 《你心柔软,却有力量》-林清玄--读书笔记