一个完整推荐系统的设计实现-以百度关键词搜索推荐为例
- User Profile
- 基础推荐挖掘算法
- Ranking
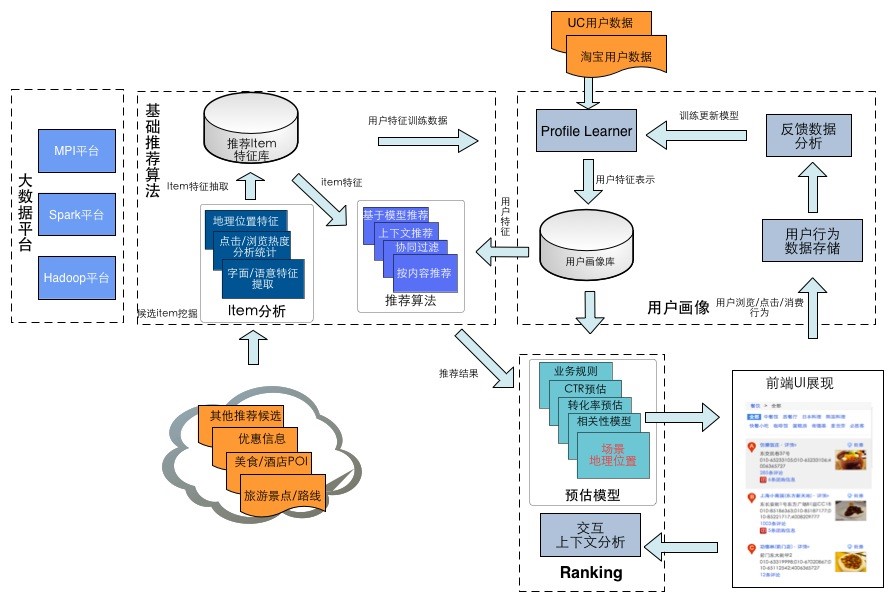
- 用户兴趣数据
- 用户的基础注册信息,背景信息:例如用户出生地,年龄,性别,星座,职业等。这些信息一般从用户注册信息中获取;例如高德,百度地图注册用户,淘宝注册用户等
- 用户行为反馈:包括显示的反馈(explicit)和隐藏(implicit)的反馈,显示的反馈包括用户的评分,点赞等操作,百度关键词搜索推荐工具上的点赞(正向显示反馈)和垃圾桶(负向显示反馈),淘宝上的评分;隐式反馈包括用户的浏览行为,例如在百度关键词搜索推荐上搜过那些词,淘宝上点击了那些页面,在高德上点击了那些POI等
- 用户交互偏好:例如用户喜欢使用哪些入口,喜欢哪些操作,以及从这些操作中分析出来的偏好,比如在高德地图上根据用户行为反馈分析出来的用户对美食的偏好:更喜欢火锅,粤菜,还是快餐
- 用户上下文信息:这些信息有些是分析出来的,例如在LBS中分析出来的用户的家在哪儿,公司在哪儿,经常活动的商圈,经常使用的路线等
- Content Based推荐: 按内容推荐,主要的工作是user profile, item profile的提取和维护,然后研究各种相似度度量方法(具体相似度度量参见博文:《推荐系统中的相似度度量》)
- 协同过滤:相当于应用了用户的行为进行推荐(区别于Content based算法),比较经典的算法包括传统的item-based/user-based算法(参见博文:《协同过滤中item-based与user-based选择依据》,《collaborative-filtering根据近邻推荐时需要考虑的3要素》),SVD,SVD++(具体原理及源码参见博文:《SVD因式分解实现协同过滤-及源码实现》)
- 上下文相关推荐:和传统推荐相比, 考虑更多上下文因素,LBS, 移动场景下使用比较多(具体参见博文:《context-aware-recommendation》)
- 基于图的关系挖掘推荐:主要是利用图论原理,根据item,user之间的数据,反馈关联关系,挖掘更深层次的关系进行推荐,该类方法一般效果都不错,当然资源要求也较高。具体参见博文:《级联二步图关系挖掘关键词推荐系统》,《频繁二项集合的hadoop实现》《itemrankrandom-walk-based-scoring-algorithm-for-recommener-system》
- Constrainted-based推荐:根据限制性条件进行演绎推荐
- 相关性: item与用户的相关性,这是大多数搜索和推荐任务的基石,例如在搜索中判定一个query和一个document的相关性,或是一个query 和 另一个query的相关性,或是在特征比较多的情况下, 一个user 和一个item 记录的相关性;实现方式可以很简单,例如传统的相似度度量方式(参见博文:《推荐系统中的相似度度量》),对于文本,业界使用简单的TF*IDF,或是BM25; 不过很多时候我们需要增加更多维度特征,包括推荐item本身的重要性,例如IDF,Pagerank(具体参见博文:《pagerank的经济学效用解释》),同时使用模型来提升相关性判断的准确性。使用模型的方式会更加复杂,但效果提升也非常明显。具体可参见博文:《集成树类模型及其在搜索推荐系统中的应用》,《分类模型在关键词推荐系统中的应用》,《adaboost》
- 推荐的上下文:例如推荐产品的入口,交互方式, 不同的入口,甚至同一入口的不同交互方式, 推荐的结果有可能都需要不一样; 在LBS生活服务中, 请求发生的时间, 地点也是推荐需要重点考虑的上下文因素,例如饭点对餐饮item的提权; 异地情况下对酒店等结果的加权等
- CTR预估:成熟的商业系统都会使用模型来完成CTR预估,或是转化预估
- 以及商业业务规则:例如黑白名单,或者强制调权。例如在百度关键词搜索推荐中,某些有比较高变现潜力的词, 就应该加权往前排; 比如在高德LBS服务中,有些海底捞的店点评评分较低, 但我们也应该往前排;或是在搜索引擎中,搜国家领导人的名字, 有些最相关的结果可能因为法律因素是需要屏蔽的
点击原文查看
一个完整推荐系统的设计实现-以百度关键词搜索推荐为例相关推荐
- 一个完整推荐系统的设计实现
工业界完整推荐系统的设计.结论是: 没有某种算法能够完全解决问题, 多重算法+交互设计, 才能解决特定场景的需求.下文也对之前的一些博文进行梳理,构成一个完整工业界推荐系统所具有的方方面面(主要以百度 ...
- 一个完整的交互设计步骤有哪些
本文由:"学设计上兔课网"原创,图片素材来自网络,仅供学习分享 一个完整的交互设计步骤有哪些?很多朋友在问交互设计过程中的步骤有哪些?一般而言,交互设计师都遵循类似的步骤进行设计, ...
- 百度关键词搜索量优化--搜索引擎关键词优化推广问题
网站关键词搜索流量优化提升是互联网网站访问流量的主要来源,也是网站最基本的访问来源之一.据调查研究,在这些流量来源中百度搜索引擎的来源占据主要流量部分.因此,对百度搜索引擎搜索流量的优化是至关重要的, ...
- 白杨SEO:百度算法更新大全合集49条(截至2021年9月),做百度关键词搜索排名必看!
百度重要算法更新大全[以下加粗重点看看] 要看图片公众号:白杨SEO优化教程上 1.李彦宏1997年就提交了一份名为"超链文件检索系统和方法"的专利申请.李彦宏提出了与传统信息检索 ...
- python搜索关键词自动提交_python+selenium实现百度关键词搜索自动化操作
缘起 之前公司找外面网络公司做某些业务相关关键词排名,了解了一下相关的情况,网络公司只需要我们提供网站地址和需要做的关键词即可,故猜想他们采取的方式应该是通过模拟用户搜索提升网站权重进而提升排名. 不 ...
- python百度关键词自动提交-python+selenium实现百度关键词搜索自动化操作
缘起 之前公司找外面网络公司做某些业务相关关键词排名,了解了一下相关的情况,网络公司只需要我们提供网站地址和需要做的关键词即可,故猜想他们采取的方式应该是通过模拟用户搜索提升网站权重进而提升排名. 不 ...
- FPGA--(verilog)一个完整工程的设计(包含设计块和激励块)及仿真
1. 模块设计完成之后,我们需要检验功能的正确性,通过设计激励块来完成测试.(可以把激励块理解成一个新的设计块,但是又和原来的设计块存在联系) 将激励块和测试块分开设计是一种良好的设计风格.激励块一般 ...
- 3天时间,给你一个完整的APP设计模型
第一步:需求梳理.分析 1.产品功能导图:Xmind 2.构思产品功能列表: 第二步:产品原型图绘制 产品功能需求梳理清楚之后,就可以绘制产品原型图.搞清楚各个功能板块如何在APP上排布. 同时根据具 ...
- 【UI入门必读】一个完整的UI设计流程是怎样的?
UI设计绝不是掌握几种软件技能或了解入门知识就可以的.想要做好UI设计,一定要多看多练,先借鉴,再原创.还应该多培养自己的设计思维和逻辑思维.这就需要在设计前清楚的知道UI设计的所有流程. UI设计一 ...
- selenium基础框架的封装(Python版)这篇帖子在百度关键词搜索的第一位了,有图为证,开心!...
百度搜索结果页地址:https://www.baidu.com/s?ie=utf-8&f=3&rsv_bp=1&rsv_idx=1&tn=baidu&wd=se ...
最新文章
- Javascript基础与面向对象基础~第四讲 Javascript中的类对象
- php javabean对象,Struts2 bean标签:创建并示例化一个JavaBean对象
- linux7.0怎么设置中文,CentOS 7 yum安装zabbix 设置中文界面
- 极速写作2017彻底卸载_如何将 Flash 从 Mac 和 Windows 系统中彻底卸载?
- 小米手机查看linux代码,如何识别小米设备-MIUI系统
- hdu2534-Score
- spss分析qpcr数据_手把手教你使用 SPSS 分析实时荧光定量数据
- android 钛备份,钛备份使用教程
- linux mariadb 升级,Mariadb数据库更新
- PHP自学---黑马程序员笔记【持续更新】
- LTE中 IMEI, GUTI, IMSI,S-TMSI等符号的含义
- HB100多普勒雷达+STM32L476VGTx测速系统的电路设计(滤波放大比较器)
- 【bzoj3065】: 带插入区间K小值 详解——替罪羊套函数式线段树
- python ImportError: cannot import name ' ×××'解决方法
- 初中计算机考试wps文字,初中信息技术WPS表格测试题.docx
- 【笑一笑,十年少】【囧一囧,眼神好】
- 天润融通入选最具活力云计算服务商,拔得呼叫中心领域头筹
- SMTPSendFailedException: 554
- Shotcut for Mac(视频编辑器)
- sketchup画球体
热门文章
- 魔百盒CM201-2,(ys)卡刷固件及教程
- 尾气冒黑烟是什么问题_尾气冒黑烟是坏了?教你通过尾气辨别爱车是否故障!...
- 转:MySQL 的 my.cnf 文件(解决 5.7.18 下没有 my-default.cnf )
- mysql 8.0 配置文件my.cnf中文注解
- 实战pixi+gsap,仿刹车动画
- Office Visio 2007 中文版 安装
- android P 锁屏初探 ——3 power键锁屏流程
- Android必备回顾:4、单例模式深究
- 计算机程序图标在哪,我的文档不见了 我的文档路径在哪 找回图标方法_电脑软硬件应用网_做中国最专业的计算机应用解决技术网站...
- 如何将DVD的vob视频格式转换成mp4格式