Hadoop学习之旅三:MapReduce
MapReduce编程模型
在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的诸如Web请求日志、爬虫抓取的文档之类的数据需要处理,由于数据量巨大,只能将其分散在成百上千台机器上处理,如何处理并行计算、如何分发数据、如何处理错误,所有这些问题综合在一起,需要大量的代码处理,因此也使得原本简单的运算变得难以处理。
为了解决上述复杂的问题,Google设计一个新的抽象模型,使用这个抽象模型,只要表述想要执行的简单运算即可,而不必关心并行计算、容错、数据分布、负载均衡等复杂的细节,这些问题都被封装在了一个库里面。设计这个抽象模型的灵感来自Lisp和许多其他函数式语言的Map和Reduce原语,为了加深理解,现以Python的Map和Reduce为例演示如下:
Python内置了map函数,该函数接受两个参数,第一个参数是一个函数对象,第二个参数是一个序列,执行map函数后,序列中的每个元素都会被按照第一个参数指定的函数制定的规则执行一遍后生成一个新的序列,请看如下:
def char2int(c):return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[c]if __name__ == '__main__':result = map(char2int,'123456')print(list(result))python中的字符串本身也是序列,执行map函数后,每个子字符串适应char2int指定的规则,生成了一个新的序列 [1, 2, 3, 4, 5, 6]。
python还有reduce函数,该函数同样接受两个参数,第一个参数也是函数对象,假设名为f,该函数必须接受两个参数,第二参数是要处理的序列,执行reduce函数后,首先,f函数处理序列中的头两个元素,把处理的结果和序列中的第三个元素再次作为参数处理,直到处理完所有的序列里的元素:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)请看示例:
from functools import reducedef char2int(c):return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[c]def calculate(x, y):return x* 10 + yif __name__ == '__main__': result = reduce(calculate, map(char2int,'123456'))print(result)其输出结果是123456,执行上面的map和reduce,结果就是将一个字符串转行为了数字,map首先将序列中的每个子字符串转换为数字,redcue遍历map生成的临时序列,并将临时序列中的元素依次按照函数calculate制定的规则处理,且将第一次处理的结果作为下次处理的一个输入参数。
Hadoop中的MapReduce
执行流程
Hadoop中的MapReduce编程模型借鉴了函数式语言中的map和reduce函数,并且将执行过程放在了多个计算机上并行执行,大概的流程如下:
- 源数据分片
- map函数在集群中并行处理分片
- 对map任务执行产生的结果分区,每个分区的数据交给一个reduce处理
数据分片
Hadoop将源文件分片,然后将分片分发到集群中的节点上等待map函数对其进行处理,每个分片的大小应以趋向于HDFS的一个block的大小为宜,如果分的太小,管理分片和构建map任务将会花去较长时间,如果分的太大,可能会出现一个分片的数据存放在两台节点中的情况,这样执行map任务时数据必须在不同的节点中通过网络进行传递,浪费了时间。
执行map任务
Hadoop会在放置分片的节点上执行map任务,将执行后产生的文件放到本地磁盘,但不是放到HDFS中,因为这个文件仅仅是中间结果,还要将其传递给reduce任务处理,没有必要存放在HDFS,因为存放在HDFS的话需要节点直接通过网络传递数据以备份多份,从而造成了空间和时间的浪费。如果map任务失败了,hadoop会从新分配节点执行。
不知道是不是有读者会想到SETI@home,这是一个寻找外星文明的科学计划,方法是分析射电望远镜数据,但是由于数据量巨大,所有组织者在全球寻找了很多自愿者,自愿者在自己机器上安装一个软件,该软件会下载数据并且在电脑空闲时分析数据并将结果提交。笔者曾经也想为寻找外星人贡献一份力量,于是也下载了软件,运行了一段时间,它还提供一个电脑屏保,显示的是当前正在处理的数据,包括动态的柱形图等,还挺有意思,最后笔者感觉电脑很卡,无情的放弃了寻找外星人的远大理想,那时候我还有点愧疚,担心会不会外星人就隐藏在因为我卸载软件而没有分析到的那部分我已经下载的数据,现在想想那时还是图样图森破,人家一定有记录,超过一定时间没有提交一定会把任务重新分配给别的自愿者的。SETI@home和Hadoop的分布式计算非常非常的像,不同的是SETI@home把分片发给了节点,节点会根据软件安装时设定好的程序分析这些分片。而Hadoop是把分析规则(用户自定义的map和reduce)分配给具有分片的节点上,然后用这个规则分析分片。
执行reduce任务
如果有多个reduce任务,每个map任务会将输出结果分区,即为每个reduce任务创建一个分区,每个分区由一些键值对组成,reduce完成处理后将数据写入HDFS。请看如下图(来自《Hadoop权威指南》):
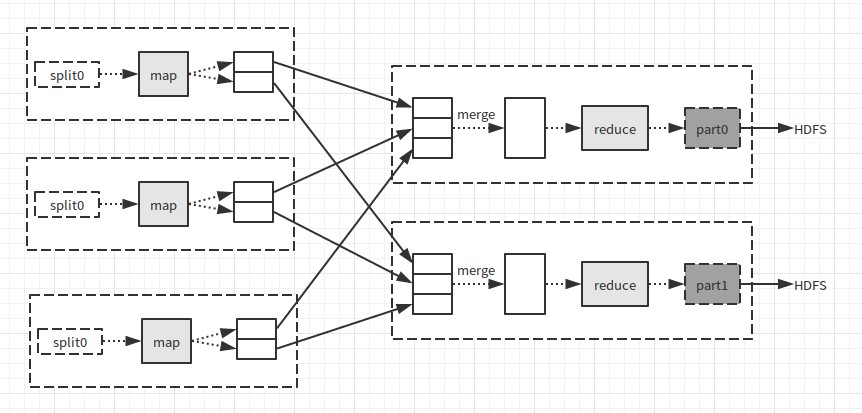
其中,虚线框表示节点,虚线箭头表示节点内部的数据传输,实线箭头表示节点直接的数据传输。
一个MapReduce程序示例
《Hadoop实战》中的第一个程序,分析美国从1975年到1999年之间的专利引用情况,源文件下载地址:http://www.nber.org/patents/Cite75_99.txt,格式如下:
"CITING","CITED"
3858241,956203
3858241,1324234
3858241,3398406
3858241,3557384
3858241,3634889
3858242,1515701
3858242,3319261
3858242,3668705
3858242,3707004
3858243,2949611
3858243,3146465
3858243,3156927
3858243,3221341
3858243,3574238
3858243,3681785
3858243,3684611
3858244,14040其中,第一列为引用专利编号,第二列为被引用专利编号,我们的目的是统计专利被哪些专利引用了,最后生成文件格式如下:
1 33964859,4647229
10000 3539112第一列为专利号,第二列为引用第一列的专利的专利的专利号。程序如下:
package joey.cnblogs.patent;import java.io.IOException;
import java.util.Iterator;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class PatentJob {public static class Map extends Mapper<Text, Text, Text, Text> {@Overridepublic void map(Text key, Text value, Context context)throws IOException, InterruptedException {context.write(value, key);} }public static class Reduce extends Reducer<Text, Text, Text, Text> {@Overridepublic void reduce(Text key, Iterator<Text> values, Context context) throws IOException, InterruptedException {String citing = "";while(values.hasNext()){if(citing.length() > 0){citing += ",";}citing += values.next().toString();} context.write(key, new Text(citing));}}public static void run(String inputPath, String outputPath) throws IOException, ClassNotFoundException, InterruptedException{Configuration conf = new Configuration();Job job = new Job(conf, "PatentJob"); job.setJarByClass(PatentJob.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setInputFormatClass(KeyValueTextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(inputPath));FileOutputFormat.setOutputPath(job, new Path(outputPath));job.waitForCompletion(true);}public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {run(args[0], args[1]);}
}关于如何在伪分布式上面运行程序以及如何从HDFS上面读取写入文件请参考我写的前两篇文章:Hadoop学习之旅一:Hello Hadoop和Hadoop学习之旅二:HDFS。现说明编写MapReduce程序的几个比较重要的点:
参数类型
map接收类型为K1,V1;map的输出类型为K2,V2;reduce的接收类型为K2,List[V2];reduce的输出类型为K3,V3,也就是说reduce的输入类型必须和map的输出类型一致。通常可以看见很多XXXWritable之类的,对应标准的XXX,加了Wriable后缀说明这个类型和Hadoop序列化有关,String对应的类型叫Text,定规则的人也比较奇葩把,为什么不叫StringWritable呢?如果大家要在map或reduce函数中使用自己的类型,请别忘了让这个类型符合hadoop序列化的要求,至于怎么做在次不做讨论,无非就是继承一个XXX类,或实现XXX接口之类的。
map的输入类型
map的输入类型有由job.setInputFormat函数指定,如果此处指定KeyValueTextInputFormat,那么每个map任务将执行源文件中的一行数据,且以被分隔符分割的第一个字符串为key值,如果此处指定了TextInputFormat(TextInputFormat也是默认的InputFormat),那么map任务每次还是执行源文件中的一行,但是key为该行在文件中的字节偏移量,所以K1的类型宜为LongWritable,还有一个处理文本文件的InputFormat是NLineInputFormat,看名字就知道大概什么意思。剩下的是一些处理二进制文件的InputFormat,此处暂时不再探讨,估计以后也不会再探讨了,Java实在是太难用了,受不了,而且也不会有公司让我这样的菜鸟去搞大数据的。
关于combiner函数
combiner函数可以减少reduce的负担,以及减少数据在节点中的传输量,因为combiner是在map任务所在节点执行的,对map的输出进行合并,执行后的结果才会发送给reduce所在节点,combiner的实现通常和reduce是一样的。需要注意的是,不是所有的场景都适合combiner,比如求平均值就不适合(出自《Hadoop权威指南》):
mean(0,20,10,25,15) = 14
mean(mean(0,20,10), mean(25,15)) = mean(10,20) = 15后记
上面那个程序,其实是有问题的,我第一次编译的时候没有使用@Override关键字,结果和我想象的不同,后来加了@Override后发现reduce方法编译失败了,我实在是想不到有什么错,对自己的智商都有所怀疑了,如果谁有兴趣运行一下并发现问题的话请告诉我,不甚感激。
比起C#,Java真的很难用,我用C#做东西,几乎不看文档就能猜到类库的意图,Java很是费劲,最无语的是Hadoop中新API和旧API中的命名,同一个名字一会儿是类,一会儿又是接口,还有好几个类新API和旧API中的名字都一样,命名空间不同,很容易搞混的,真的很服了。
参考资料
- 《Hadoop权威指南》
- 《Hadoop实战》
- 网易云课堂:大数据工程师
- MapReduce: Simplified Data Processing on Large Clusters
- 廖雪峰的Python教程
Hadoop学习之旅三:MapReduce相关推荐
- Hadoop学习笔记—4.初识MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个 编程模型 ,用以进行大数据量的计算.对于大 数据量的计算,通常采用的处理手法就是并行计算.但对许多开 ...
- HALCON学习之旅(三)
HALCON学习之旅(三) 文章目录 HALCON学习之旅(三) 1.创建自适应图形窗口 2.霍夫变换寻找图像直线 1.创建自适应图形窗口 原因:默认的图形窗口尺寸为512*512.当图像变量尺寸与图 ...
- Hadoop 学习笔记(三)常用命令
Hadoop 学习笔记(三)常用命令 进入HADOOP_HOME目录. 执行sh bin/start-all.sh 进入HADOOP_HOME目录. 执行sh bin/stop-all.sh Usag ...
- hadoop学习之旅1
大数据介绍 大数据本质也是数据,但是又有了新的特征,包括数据来源广.数据格式多样化(结构化数据.非结构化数据.Excel文件.文本文件等).数据量大(最少也是TB级别的.甚至可能是PB级别).数据增长 ...
- Hadoop学习(二)——MapReduce\Yarn架构
其他更多java基础文章: java基础学习(目录) 学习资料 理解Hadoop YARN架构 本文先讲MapReduce 1.x的框架.再讲MapReduce 1.x升级改进后MapReduce 2 ...
- 滴滴Booster移动APP质量优化框架 学习之旅 三
推荐阅读: 滴滴Booster移动App质量优化框架-学习之旅 一 Android 模块Api化演练 不一样视角的Glide剖析(一) 滴滴Booster移动App质量优化框架-学习之旅 二对重复资源 ...
- Hadoop学习(16)-MapReduce的shuffle详解
原文来自:扎心了,老铁的<Hadoop学习之路(二十三)MapReduce中的shuffle详解>
- Hadoop学习(11)-MapReduce的核心运行机制
原文来自:扎心了,老铁的<Hadoop学习之路(十四)MapReduce的核心运行机制>
- Hadoop学习之路(7)MapReduce自定义排序
本文测试文本: tom 20 8000 nancy 22 8000 ketty 22 9000 stone 19 10000 green 19 11000 white 39 29000 socrate ...
最新文章
- 数据结构和算法:(3)3.2.1单链表的整表创建
- cad等比例缩放快捷键_「CAD」利用块对图形进行非等比例缩放
- 使用HTML5的canvas做一个会动的时钟
- 关于Android的一些设计
- sklearn多分类问题
- CSS-3 Animation 的使用
- 分模块开发创建父工程——(六)
- Python threading Thread多线程的使用方法
- mysql字符串用法
- 不愧是阿里大佬,mysql存储过程写法案例
- 记录android点滴(一)--通过build.prop实现产品定制的方法
- 使用rpm包安装mysql_centos下利用rpm包安装mysql
- 新手学完Java可以面试哪些岗位?
- python的threading是什么意思_Python中的threading模块是什么
- ListView vs FlatList vs RecyclerListView性能对比
- oracle数据库中sql语句性能提升之to_char改造
- 成功解决python.exe 无法找到入口 无法定位程序输入点
- FAT,FAT32,NTFS
- 英国易捷航空遭黑客入侵 约900万客户数据被窃取
- 《Nature》子刊发布,IIT科学家模仿“植物的触须”,打造可逆渗透致动的仿生软体机器人