论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning
Google DeepMind
Abstract
主流的 Q-learning 算法过高的估计在特定条件下的动作值。实际上,之前是不知道是否这样的过高估计是 common的,是否对性能有害,以及是否能从主体上进行组织。本文就回答了上述的问题,特别的,本文指出最近的 DQN 算法,的确存在在玩 Atari 2600 时会 suffer from substantial overestimations。本文提出了 double Q-learning algorithm 可以很好的降低观测到的 overestimation 问题,而且在几个游戏上取得了更好的效果。
Introduction
强化学习的目标是对序列决策问题能够学习到一个好的策略,通过优化一个累计未来奖励信号。Q-learning 是最著名的 RL 学习算法之一,但是由于其在预测动作值的时候包含一个最大化的步骤,所以导致会出现过高的预测值,使得学习到不实际的高动作值。
在之前的工作中,将 overestimation 的问题归咎于 不够灵活的函数估计 以及 noise。本文统一了这些观点,并且表明 当动作值预测的不准确的时候,就会出现 overestimation,而不管估计误差的来源。当然,在学习的过程中,出现不准确的值估计也是正常的,这也说明 overestimation 可能比之前所看的情况更加普遍。
如果overestimation 的确出现,那么这个开放的问题的确会影响实际的性能。过于优化的值估计在一个问题中是不必要的,如果所有的值都比相对动作参考要均匀的高被保存了,那么我们就不会相信得到的结果策略会更差了。此外,有时候 optimistic 是一件好事情:optimistic in the face of uncertainty is a well-known exploration technique. 然而,如果当预测并且均匀,不集中在 state上,那么他们可能对结果的策略产生坏的影响。Thrun 等人给出了特定的例子,即:导致次优的策略。
为了测试在实际上是否会出现 overestimation,我们探讨了最近 DQN 算法的性能。关于 DQN 可以参考相关文章,此处不赘述了。可能比较奇怪的是,这种 DQN设置 仍然存在过高的估计动作的 value 这种情况。
作者表明,在 Double Q-learning算法背后的idea,可以很好的和任意的函数估计相结合,包括神经网络,我们利用此构建了新的算法,称: Double DQN。本文算法不但可以产生更加精确的 value estimation,而且在几个游戏上得到了更高的分数。这样表明,在 DQN上的确存在 overestimation 的问题,并且最好将其降低或者说消除。
Background
为了解决序列决策问题,我们学习对每一个动作的最优值的估计,定义为:当采取该动作,并且以后也采用最优的策略时,期望得到的将来奖励的总和。在给定一个策略 $\pi$ 之后,在状态 s下的一个动作 a 的真实值为:
$Q_{\pi}(s, a) = E[R_1 + \gamma R_2 + ... | S_0 =s, A_0 = a, \pi]$,
最优的值就是 $Q_*(s, a) = max_{\pi} Q_{\pi}(s, a)$。一个优化的策略就是从每一个状态下选择最高值动作。
预测最优动作值 可以利用 Q-learning算法。大部分有意思的问题都无法在所有状态下都计算出其动作值。相反,我们学习一个参数化的动作函数 Q(s, a; \theta_t)。在状态St下,采取了动作 $A_t$之后标准的 Q-learning 更新,然后观测到奖励 $R_{t+1}$以及得到转换后的状态 $S_{t+1}$:
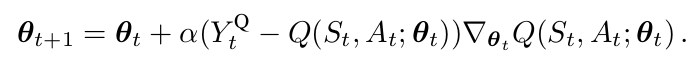
其中,目标 $Y_t^Q$ 的定义为:
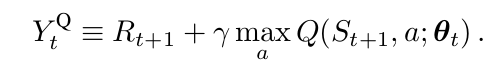
这个更新非常类似于随机梯度下降,朝向 target value $Y^Q_t$ 更新当前值 Q(S_t, A_t; \theta_t)。
Deep Q-Networks.
一个DQN是一个多层的神经网络,给定一个状态 s,输出一个动作值的向量 $Q(s, *; \theta)$,其中,$\theta$ 是网络的参数。对于一个 n维 的状态空间,动作空间是 m 个动作,神经网络是一个函数将其从 n维空间映射到 m维。两个重要的点分别是 target network 的使用 以及 experience replay的使用。target network,参数为 $\theta^-$,和 online的网络一样,除了其参数是从 online network 经过 某些 steps之后拷贝下来的。目标网络是:
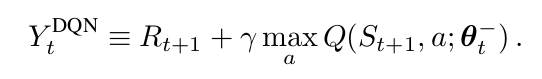
对于 experience replay,观测到的 transitions 都被存贮起来,并且随机的从其中进行采样,用来更新网络。target network 和 experience replay 都明显的改善了最终的 performance。
Double Q-learning
在标准的 Q-learning 以及 DQN 上的 max operator,用相同的值来选择和评价一个 action。这使得其更偏向于选择 overestimated values,导致次优的估计值。为了防止此现象,我们可以从评价中将选择独立出来,这就是 Double Q-learning 背后的 idea。
在最开始的 Double Q-learning算法中,通过随机的赋予每一个 experience 来更新两个 value functions 中的一个 来学习两个value function,如此,就得到两个权重的集合,$\theta$ 以及 $\theta '$。对于每一次更新,其中一个权重集合用来决定贪婪策略,另一个用来决定其 value。做一个明确的对比,我们可以首先排解 selection 和 evaluation,重写公式2,得到:
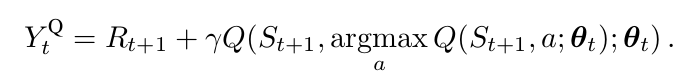
那么, Double Q-learning error可以写为:
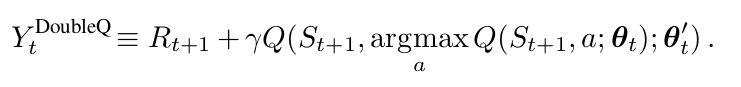 注意到 action 的选择,在 argmax,仍然属于 online weights $\theta_t$。这意味着,像 Q-learning一样,我们仍然可以根据当前值,利用贪婪策略进行 value 的估计。然而,我们利用第二个权重 $\theta _t '$来更加公平的评价该策略。第二个权重的集合,可以通过交换 两个权重的角色进行更新。
注意到 action 的选择,在 argmax,仍然属于 online weights $\theta_t$。这意味着,像 Q-learning一样,我们仍然可以根据当前值,利用贪婪策略进行 value 的估计。然而,我们利用第二个权重 $\theta _t '$来更加公平的评价该策略。第二个权重的集合,可以通过交换 两个权重的角色进行更新。
OverOptimism due to estimation errors:
论文笔记之:Deep Reinforcement Learning with Double Q-learning相关推荐
- 【论文笔记】Deep Reinforcement Learning Control of Hand-Eye Coordination with a Software Retina
目录 Abstract Keywords 1. INTRODUCTION 2. BACKGROUND A. Software Retina B. Deep Reinforcement Learning ...
- 【论文笔记】Deep Reinforcement Learning for Robotic Pushing and Picking in Cluttered Environment
目录 Abstract I. INTRODUCTION II. RELATED WORK III. SYSTEM OVERVIEW IV. ARCHITECTURE A. Robotic Hand S ...
- 活体检测论文笔记2——Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing
本文创新点: 设计了一种基于两种见解来检测来自多个框架的表示攻击的新方法: 1)详细的鉴别线索(例如,空间梯度大小)可以通过叠加的普通卷积被丢弃:2)三维运动人脸的动力学为检测假人脸提供了重要的线索 ...
- 论文记载: Deep Reinforcement Learning for Traffic LightControl in Vehicular Networks
强化学习论文记载 论文名: Deep Reinforcement Learning for Traffic LightControl in Vehicular Networks ( 车辆网络交通信号灯 ...
- 论文解析:Deep Reinforcement Learning for List-wise Recommendations
论文解析:Deep Reinforcement Learning for List-wise Recommendations 简介 京东在强化学习推荐系统方面的工作 背景 推荐系统存在的问题: 无法通 ...
- 论文笔记-DEC (Deep Embedded Clustering)
论文笔记-DEC (Deep Embedded Clustering) 知识点1.将聚类的度量参考T-SNE中的t-分布,将聚类的度量转换成一个概率值(软分配,qij 表示将样本 i 分配给 j 簇的 ...
- 图像隐写术分析论文笔记:Deep learning for steganalysis via convolutional neural networks
好久没有写论文笔记了,这里开始一个新任务,即图像的steganalysis任务的深度网络模型.现在是论文阅读阶段,会陆续分享一些相关论文,以及基础知识,以及传统方法的思路,以资借鉴. 这一篇是Medi ...
- 读书笔记-Coordinated Deep Reinforcement Learners for Traffic Light Control
Coordinated Deep Reinforcement Learners for Traffic Light Control 本文研究了交通灯的学习控制策略.在交通灯控制问题引入了一种新的奖励函 ...
- 论文笔记:Evolving Losses for Unsupervised Video Representation Learning
Evolving Losses for Unsupervised Video Representation Learning 论文笔记 Distillation Knowledge Distillat ...
- 【论文笔记】DEEP FEATURE SELECTION-AND-FUSION FOR RGB-D SEMANTIC SEGMENTATION
论文 题目:DEEP FEATURE SELECTION-AND-FUSION FOR RGB-D SEMANTIC SEGMENTATION 收录于:ICME 2021 论文:Deep Featur ...
最新文章
- python paramiko包 ssh报错No existing session 解决方法
- MFC中修改程序图标
- C/C++宏定义中#与##区别 .
- coursera 《现代操作系统》 -- 第十周 文件系统(2)
- mysql 开发 生产_在没有表锁定的情况下在巨大的MySQL生产表...
- 全球首个AI协同及大数据安全标准正在制定,创新工场参与推进
- linux下安装tuxedo
- python基础学习1-字典的使用
- Spring依赖处理过程源码分析
- 力扣-103. 二叉树的锯齿形层序遍历
- python以写模式打开的文件无法进读操作_以写模式打开的文件无法进行读操作。...
- ROS:机器人系统设计(连接摄像头、Kinect、激光雷达、URDF建模)
- photoshop修色圣典 第5版pdf
- RI-TRP-DR2B 32mm 玻璃应答器|CID载码体标签在半导体行业重复利用之检测方法
- 当天邀请的饭局要参加吗?别说“我有安排”,高手都懂这3个礼数
- layer常用功能-子页面关闭当前窗口-执行子页面方法-方法回调
- kafka实践(十五): 滴滴开源Kafka管控平台 Logi-KafkaManager研究
- Unable to configure Windows to Trust the Fiddler Root certificate.The LOG tab may contain more infor
- 【Luogu P4766】 [CERC2014]Outer space invaders(区间dp)
- Amazon/eBay/Wish/Lazada/速卖通/Shopee/tiktok/沃尔玛/煤炉/补单黑科技?如何解决账号问题。