HTTP缓存ETAG和Last-Modified
from http://lkf0217.javaeye.com/blog/544200
基础知识
1) 什么是”Last-Modified”?
在浏览器第一次请求某一个URL时,服务器端的返回状态会是200,内容是你请求的资源,同时有一个Last-Modified的属性标记此文件在服务期端最后被修改的时间,格式类似这样:
Last-Modified: Fri, 12 May 2006 18:53:33 GMT
客户端第二次请求此URL时,根据 HTTP 协议的规定,浏览器会向服务器传送 If-Modified-Since 报头,询问该时间之后文件是否有被修改过:
If-Modified-Since: Fri, 12 May 2006 18:53:33 GMT
如果服务器端的资源没有变化,则自动返回 HTTP 304 (Not Changed.)状态码,内容为空,这样就节省了传输数据量。当服务器端代码发生改变或者重启服务器时,则重新发出资源,返回和第一次请求时类似。从而保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
2) 什么是”Etag”?
HTTP 协议规格说明定义ETag为“被请求变量的实体值” (参见 —— 章节 14.19)。 另一种说法是,ETag是一个可以与Web资源关联的记号(token)。典型的Web资源可以一个Web页,但也可能是JSON或XML文档。服务器单独负责判断记号是什么及其含义,并在HTTP响应头中将其传送到客户端,以下是服务器端返回的格式:
ETag: "50b1c1d4f775c61:df3"
客户端的查询更新格式是这样的:
If-None-Match: W/"50b1c1d4f775c61:df3"
如果ETag没改变,则返回状态304然后不返回,这也和Last-Modified一样。本人测试Etag主要在断点下载时比较有用。
Last-Modified和Etags如何帮助提高性能?
聪明的开发者会把Last-Modified 和ETags请求的http报头一起使用,这样可利用客户端(例如浏览器)的缓存。因为服务器首先产生 Last-Modified/Etag标记,服务器可在稍后使用它来判断页面是否已经被修改。本质上,客户端通过将该记号传回服务器要求服务器验证其(客户端)缓存。
过程如下:
1. 客户端请求一个页面(A)。
2. 服务器返回页面A,并在给A加上一个Last-Modified/ETag。
3. 客户端展现该页面,并将页面连同Last-Modified/ETag一起缓存。
4. 客户再次请求页面A,并将上次请求时服务器返回的Last-Modified/ETag一起传递给服务器。
5. 服务器检查该Last-Modified或ETag,并判断出该页面自上次客户端请求之后还未被修改,直接返回响应304和一个空的响应体。
HttpClient Redirects Handling
简介
这份文档简单介绍下 HttpClient 手动处理重定向功能。
因为某些原因,比如需要人工的支持或者 HttpClient 不支持又或者网络的限制(如需要特殊的权限才可以访问的资源),有些类型的重定向是 HttpClient 不能自动处理的。当前版本的 HttpClient 不能够自动处理 POST 和 PUT 方法的重定向。
手动处理重定向
介于 300 和 399 之间的状态码,都代表重定向。最常见的重定向状态码如下:
· 301 HttpStatus.SC_MOVED_PERMANENTLY ,永久移除。
· 302 HtpStatus.SC_MOVED_TEMPORARILY ,暂时移除。
· 303 HttpStatus.SC_SEE_OTHER ,重定向到其他资源。
· 307 HttpStatus.SC_TEMPORARY_REDIRECT ,临时重定向。
注意:有些 3XX 的状态码并不只是简单给发送请求标识一个不同的 URL 。这些状态码需要应用自行处理。
当应用程序收个一个简单的重定向 Responses 时,必须用新的 URL 去执行 HttpMethod 的 executeMethod 方法,重新下载新 URL 对应的资源。通常,我们采用递归的方式去处理重定向,以防有多个重定向,不过要加标识数去结束你的递归。
String redirectLocation;
Header locationHeader = method.getResponseHeader("location");
if (locationHeader != null) {
redirectLocation = locationHeader.getValue();
} else {
// The response is invalid and did not provide the new location for
// the resource. Report an error or possibly handle the response
// like a 404 Not Found error.
}
String redirectLocation;
Header locationHeader = method.getResponseHeader("location");
if (locationHeader != null) {
redirectLocation = locationHeader.getValue();
} else {
// The response is invalid and did not provide the new location for
// the resource. Report an error or possibly handle the response
// like a 404 Not Found error.
}
当得到新的 Location 以后,你可以对待一个新的 URL 一样,使用 HttpClient 去请求对应的资源。
开发过web应用的人,应该都知道http重定向这个功能,html就有最简单的方法:
<meta http-equiv="refresh" content="5;url=http://www.cppblog.com/cool-liangbing/">,
也就是告诉你的浏览器5秒之后自动跳转到我的c++博客首页http://www.cppblog.com/cool-liangbing/ 。
重定向常常用于自动跳转,从活动空间来看大概分两类:服务器内部跳转和服务器之间跳转。
服务器内部跳转常见于“登陆成功!5秒之后将自动进入首页”这种应用。而服务器之间跳转,种类稍微
多一些:(1)从服务器内跳往外部服务器; (2)从A服务器跳转到B服务器,接着跳转到C服务器;
(3) 从A服务器跳转到B服务器, 业务处理完毕之后又跳转到A服务器; (4) 从用户浏览器向A服务器
发送请求,在出口网关处进行重定向,如通过iptable之类,重定向到一个认证服务器B,返回一个
认证登陆的页面,当用户输入了正确的用户名和密码等,认证服务器B再通过http重定向到A服务器.
以上所说的4种模式,前3种不值一提,而第4种则有些问题,不是那么容易跳转成功的。
不管你的认证服务器B是用现在的tomcat还是resin,或者其它流行的web服务器,最后发现总是
不能从认证服务器B跳到A服务器. 刚开始怀疑html那种方法不行,就改用javascript写法,改用jsp调用
方法,甚至直接在servlet里调用重定向接口,一一试遍,都失败了,这才怀疑可能不是程序写法上
的问题。
在万般无奈情况下,使用CommView工具来抓包看看,从tcp包本身、http request和http response
包内容来看,看不出什么不对。但发现整个跳转只在一个tcp连接上进行,这使我想到iptable把向A服务器
的请求偷偷转发到认证服务器B, 而浏览器还认为认证服务器B就是A服务器, 所以只要这条tcp连接不断,
浏览器就一直认为这种映射关系正确,所以你怎么也跳转不到真正的目的地-A服务器.
但是我们用老版本httpd或thttpd做web服务器,则可以正常跳转,何故?http协议版本差别:
老版本httpd或thttpd采用http1.0协议,而tomcat和resin这些jsp容器最新版本,大都已经实现了http1.1
协议了,对我们这个问题就是connection是采用非持久的还是持久模式,提取两个版本协议说明:
(1) http1.0:
原文:Except for experimental applications, current practice requires that
the connection be established by the client prior to each request and
closed by the server after sending the response.
翻译:实验室应用除外,当前的做法是客户端在每次请求之前建立连接,而服务器端在发送回应后关闭此连接。
(2) http1.1:
原文:In HTTP/1.0, most implementations used a new connection for each request/response exchange.
In HTTP/1.1, a connection may be used for one or more request/response exchanges,
although connections may be closed for a variety of reasons (see section 8.1).
翻译:在HTTP/1.0协议下,大多数HTTP服务器实现对每一个请求/应答使用一个新连接. 而在HTTP/1.1协议下,一个或多个请求/应答使用同一个连接。
(section 8.1详细说明了为什么这么做)
从协议上分析清楚之后,我们怎么解决上面那个现实问题?肯定不能使用http1.1这种持久性连接。
查了下tomcat docment说明,默认实现了http1.1,现在版本的connector已经早不提供http1.0支持了,
难道我们要退回到http1.0的版本?那是多么痛苦的事情。再查查tomcat/conf/server.xml里关于connector
的配置,有一个参数connecttimeout,默认是20000ms, 作为服务器不可能争对socket accept()的,应该是
socket recv()的超时,那么我们设置它为比我们<meta http-equiv="refresh" content="5;url=xxx">里
秒数小就可以了,保证在跳转之前以前的tcp连接被tomcat服务器断开就可以了,当然iptable应该在认证成功
之后不再对这个上网用户发出的http请求重定向到认证服务器, 这个很容易做到,暂不提细节。
最后附上UML图以方便理解:
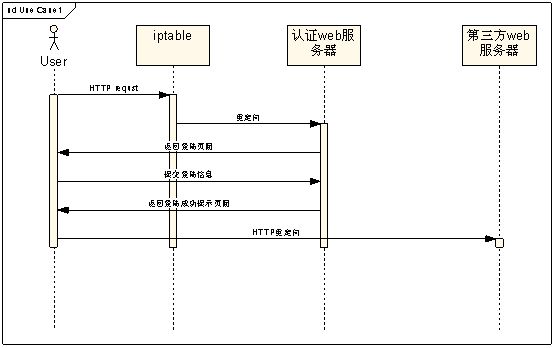
转载于:https://www.cnblogs.com/rongxh7/archive/2010/05/15/1736291.html
HTTP缓存ETAG和Last-Modified相关推荐
- 前端协商缓存强缓存如何使用_http协商缓存与强缓存
概述 良好的缓存策略可以降低资源的重复加载,提高网页的整体加载速度.通常浏览器的缓存策略分为两种:强缓存和协商缓存. 基本原理浏览器在加载资源的时候,会先根据这个资源的一些http header判断他 ...
- 网络协议从入门到底层原理(11)网络爬虫、无线网络、HTTP缓存、即时通信、流媒体
补充知识 网络爬虫 网络爬虫的简易实例 robots.txt 无线网络 HTTP 缓存(Cache) 缓存 - 响应头 缓存 - 请求头 缓存的使用流程 即时通信(IM) XMPP MQTT 流媒体 ...
- 浅谈HTTP缓存机制
前言 HTTP缓存不管是在面试中,还是实际开发中都是重中之重.了解HTTP缓存不仅可以轻松自如应对面试,而且也是在实际开发中对性能优化不可或缺的手段. 客户端缓存 缓存不仅可以存在于缓存服务器内,还可 ...
- 200 OK (from cache) 与 304 Not Modified
本文载于袁源(歪歪)的个人博客:http://www.bokeyy.com/post/200-ok-from-cache-vs-304-not-modified.html . 为什么有的缓存是 200 ...
- 网络协议(十四):WebSocket、WebService、RESTful、IPv6、网络爬虫、HTTP缓存
网络协议系列文章 网络协议(一):基本概念.计算机之间的连接方式 网络协议(二):MAC地址.IP地址.子网掩码.子网和超网 网络协议(三):路由器原理及数据包传输过程 网络协议(四):网络分类.IS ...
- 前端缓存/浏览器缓存机制
前端缓存/浏览器缓存机制 1. 缓存过程分析 浏览器第一次向服务器发起该请求后拿到请求结果后,将请求结果和缓存标识存入浏览器缓存,浏览器对于缓存的处理是根据第一次请求资源时返回的响应头来确定的. 浏览 ...
- 服务器缓存返回状态码,浏览器缓存,状态码200与304
清除浏览器中的缓存,必须从服务端获取最新内容,但不是所有浏览器都支持.. 2.HTTP头信息 Expires:即在 HTTP 头中指明具体失效的时间(HTTP/1.0) Cache Control:m ...
- go读取最后一行_CPU缓存体系对Go程序的影响
小菜刀最近在medium上阅读了一篇高赞文章<Go and CPU Caches>,其地址为https://teivah.medium.com/go-and-cpu-caches-af5d ...
- java中数据池有哪些_什么是数据库的 “缓存池” ?(万字干货)
1.Buffer Pool 概述 Buffer Pool 是什么?从字面上看是缓存池的意思,没错,它其实也就是缓存池的意思.它是 MySQL 当中至关重要的一个组件,可以这么说,MySQL的所有的增删 ...
- 前端协商缓存强缓存如何使用_前端强缓存和协商缓存
缓存是前端面试的一个常见知识点,下面对于实际项目中如何进行缓存的设置给出方案. 强缓存和协商缓存 浏览器缓存是浏览器将用户请求过的静态资源存储到电脑本地磁盘中,当再次访问时,就可以直接从本地缓存中加载 ...
最新文章
- 安卓开发 高德地图 marker 点击移动位置_高德手机AR导航再升级,有惊喜
- 足不出户完成交付独家交付秘籍(第二回)
- system.img解包打包工具_好程序员云计算学习路线分享文件打包及压缩
- java事件的接收_spring发布和接收定制的事件(spring事件传播)
- 20145308刘昊阳 《Java程序设计》实验五报告
- 脚本安装smokeping
- 经济学自身利益最大化_劳动经济学:研究劳动力市场运作的专业
- python url拼接_教你写python爬虫——用python爬原图
- hiho模拟面试题2 补提交卡 (贪心,枚举)
- 2.2线性表的顺序表示和实现
- 39个史诗级奇葩代码注释,程序不会崩,但程序员会
- J2EE事务并发控制策略总结
- 《C++游戏开发》笔记十三 平滑过渡的战争迷雾(一) 原理:Warcraft3地形拼接算法...
- Jim Marino与Meeraj Kunnumpurath专访:关于SCA和Fabric3
- linux 断开远程vnc,Linux停VNC远程控制的使用方法
- 简述数字信号处理的内容和理论
- 让同事主动配合工作的三点技巧|智测优聘总结
- geonode geoserver win10 安装教程(亲测)
- mongo数据库创建用户
- codeforces 869E The Untended Antiquity