图像 异常检测算法_检测图像异常的算法
图像 异常检测算法
Modern applications are generating enormous amounts of image data. And in the last years, researches began to apply some data mining algorithms to extract useful information from these images to apply smart decisions in business, to detect harmful situations in medicine, to understand behavioral patterns for people, and much more.
现代应用程序正在生成大量图像数据。 在过去的几年中,研究开始应用一些数据挖掘算法来从这些图像中提取有用的信息,以将明智的决策应用于业务,检测医学中的有害情况,了解人们的行为模式等等。
Detecting anomalies play a very important role in data mining which raises suspicions while these outliers most of the time differs a lot from the rest of the majority of images. The purpose of this article is to give a state of the art overview of this topic and give some real examples using two famous algorithms.
检测异常在数据挖掘中起着非常重要的作用,这引起了人们的怀疑,而这些异常值在大多数情况下与大多数其他图像有很大不同。 本文的目的是提供有关此主题的最新技术概述,并使用两种著名的算法给出一些实际示例。
检测图像中的离群值 (Detecting outliers in images)
Detecting outliers in images is not an easy task, and can’t be done efficiently using some famous outlier detection algorithms. Like it will be too hard to detect outlier images using statistical methods like the Z-Score algorithm or Boxplots. While the DBScan clustering algorithm designed when the distribution of values in the feature space cannot be assumed, but applying that algorithm for this application is not clear forward. So the idea is not to choose an algorithm rather than see how to frame the problem correctly then choose one of the algorithms that suit that frame.
检测图像中的离群值不是一件容易的事,并且无法使用某些著名的离群值检测算法来有效地完成。 就像使用Z-Score算法或Boxplots之类的统计方法来检测离群值图像将太困难了。 虽然无法假定DBScan集群算法是在无法假定值在特征空间中的分布时设计的,但尚不清楚该算法在该应用程序中的应用。 因此,这个想法不是选择一种算法,而是看如何正确地解决问题,然后选择一种适合该框架的算法。
Here is a very good article about anomalies detection in common:
这是一篇关于常见异常检测的非常好的文章:
Machine learning researchers have created algorithms such as Isolation forest, one-class SVMs, local outlier factor to detect outliers in images. In the next paper with the title “Anomaly Detection Using Similarity-based One-Class SVM for Network Traffic Characterization”:
机器学习研究人员创建了诸如隔离森林 , 一类SVM , 局部离群值因素之 类的算法来检测图像中的离群值。 在下一篇标题为“ 使用基于相似性的一类SVM进行网络流量表征的异常检测 ”的文章中:
https://www.researchgate.net/publication/331257012_Anomaly_Detection_Using_Similarity-based_One-Class_SVM_for_Network_Traffic_Characterization
https://www.researchgate.net/publication/331257012_Anomaly_Detection_Using_Similarity-based_One-Class_SVM_for_Network_Traffic_Characterization
The writers tried to apply One-Class SVM in detecting malicious activities in car traffic in real-time, and real-time was a big challenge for their system while they weren’t studying the efficient of their algorithm rather than detecting the cases that the network administrators should give attention to and label that behaviors (Normal — Abnormal — Critical).
作者试图将一类支持向量机(SVM)用于实时检测汽车交通中的恶意活动,而实时性对他们的系统来说是一个巨大的挑战,因为他们没有研究算法的效率,而不是检测出网络管理员应注意并标记该行为(正常-异常-严重)。
Isolation forest (iForest) is another effective method in detecting outliers, Fei Tony Liu and Kai Ming Ting in their paper Isolation-based Anomaly Detection discussed the details of this algorithm:
隔离林(iForest)是检测异常值的另一种有效方法, Fei Tony Liu和Kai Ming Ting在他们的基于隔离的异常检测中讨论了该算法的细节:
And we will talk more about this efficient way of detecting anomalies.
我们将更多地讨论这种检测异常的有效方法。
Some people recently tried to apply deep learning techniques to detect anomalies in images, the idea behind that turn around autoencoders neural networks where the encoder accepts the input data, compress it into the latent-space representation. Then the decoder will reconstruct the input data from that space. When training the hidden layers have been taught of de-noising the input data and here is the key to detecting anomalies. When we apply that network on anomaly images the reconstructed image will have a high mean-squared-error (MSE) since the autoencoders have never seen that sample of data before. While it’s a new and effective way to detect anomalies but it has some negative sides like we should choose the MSE threshold and the network should be trained on a specific class of data and anomalies should be completely a different class so it can be detected as an anomaly.
最近有人尝试应用深度学习技术来检测图像中的异常现象,其背后的想法是绕过自动编码器神经网络,在该网络中,编码器接受输入数据,并将其压缩为潜伏空间表示。 然后,解码器将从该空间重构输入数据。 训练隐层时,已经教过如何对输入数据进行消噪,这是检测异常的关键。 当我们将该网络应用于异常图像时,由于自动编码器之前从未见过该数据样本,因此重构图像将具有较高的均方误差(MSE)。 尽管这是检测异常的一种新的有效方法,但它具有一些负面影响,例如我们应该选择MSE阈值,并且应该对网络上的特定类别的数据进行训练,而异常应该是完全不同的类别,因此可以将其检测为异常。异常。
If you want to try that in the next link you will find a very interesting demo:
如果您想在下一个链接中尝试,您将找到一个非常有趣的演示:
Some papers discussed the use of Generative Adversarial Networks in detecting anomalies in images:
一些论文讨论了生成对抗网络在检测图像异常中的使用:
http://link-springer-com-443.webvpn.fjmu.edu.cn/chapter/10.1007%2F978-3-030-10925-7_1
http://link-springer-com-443.webvpn.fjmu.edu.cn/chapter/10.1007%2F978-3-030-10925-7_1
They were searching for a good representation of the sample in the latent space of the generator like the concept discussed before in deep learning. While they achieved state-of-the-art performance on standard image benchmark datasets, but again we have the same negative points discussed in deep learning where it’s deeply related to the training phase and the main class nature and features.
他们正在寻找生成器潜在空间中样本的良好表示形式,就像之前在深度学习中讨论的概念一样。 尽管他们在标准图像基准数据集上取得了最先进的性能,但是在深度学习中,我们同样遇到了同样的缺点,它与训练阶段以及主要课程的性质和功能密切相关。
隔离林 (Isolation forest)
Also, known as “iForest” algorithm. It’s using Binary trees for separating groups of points using a random threshold applied on a random feature space until we reach the leaves with only one point in each. And then generate multiple trees on each group of samples to get a forest of trees where the score of a point is its path length averaged across the trees of the forest.
也称为“ iForest”算法。 它使用二叉树通过在随机特征空间上应用随机阈值来分离点组,直到我们到达每个只有一个点的叶子为止。 然后在每组样本上生成多棵树,以得到一个森林树,其中一个点的分数是其在森林树之间平均的路径长度。
Briefly, by using this algorithm, we will keep partitioning the dataset until each point will be alone, outliers points will be partitioned in the earlier stages of running the algorithm while normal points will require more partitions to be isolated. Each partition is randomly generated, individual trees are generated with different sets of partitions.
简而言之,通过使用该算法, 我们将继续对数据集进行分区,直到每个点都单独存在 ,在运行算法的早期阶段,将对离群点进行分区,而对正常点则需要进行更多分区。 每个分区都是随机生成的 , 单个树是用不同的分区集生成的 。
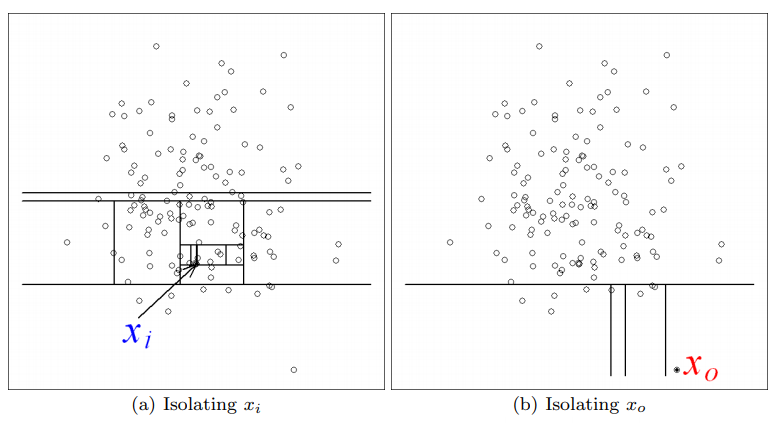
We can see clearly from the images that X0 (Anomaly point) will be partitioned faster than Xi (Normal point).
从图像中我们可以清楚地看到,X0(异常点)的分割速度比Xi(正常点)的分割速度快。
Isolation forest’s basic principle is that outliers are few and far from the rest of the observations. After generating the trees there is a specific formula to score each point, this formula as next:
隔离林的基本原理是离群值很少且与其余观测值相距甚远。 生成树后,有一个特定的公式可以为每个点评分,该公式如下:
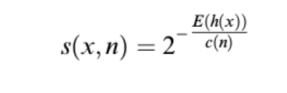
Where:
哪里:
- h(x) the path lengthh(x)路径长度
- E(h(x)) is the average of h(x) from a collection of Isolation treesE(h(x))是来自隔离树集合的h(x)的平均值
- c(n) the unsuccessful length search of binary treec(n)二叉树的长度搜索不成功
- N number of external nodesN个外部节点
So when the score is near 1, that means the point is an outlier. If the score is too low that means it’s a normal point. Usually, we should not get values around 0.5 or that means either the generation or picking the features was not so good or there are no outliers in the distribution.
因此,当分数接近1时,表示该点是离群值 。 如果分数太低,则表示这是正常点。 通常,我们不应该获得约0.5的值,否则意味着生成或挑选要素的质量不太好,或者分布中没有异常值。
Isolation forest is characterized by the lack of the need of scaling the values in the feature space, is an effective method when value distributions cannot be assumed, has few parameters, this makes this method fairly robust and easy to optimize, well suited for streaming data and works great with very high dimensional datasets.
隔离林的特点是无需缩放特征空间中的值 ,是一种无法假设值分布的有效方法 , 参数很少 ,这使该方法相当健壮且易于优化, 非常适合流数据并且非常适合高维数据集 。
For more details about the algorithm check out its publication:
有关该算法的更多详细信息,请查看其出版物:
I wrote a code that will fetch a class of images and generate forests for this class.
我写了一段代码,将获取一类图像并为该类生成森林。
I already implemented that code after reading the next article:
阅读下一篇文章后,我已经实现了该代码:
It was a very useful article to give an introduction about anomaly detection using the Isolation Forest algorithm.
这是一篇非常有用的文章,对使用隔离林算法进行异常检测进行了介绍。
I used the same datasets of the next paper:
我使用了下一篇论文的相同数据集:
You can download the images under the “8 Scene Categories Dataset” section.
您可以在“ 8个场景类别数据集”部分下下载图像。
健壮的随机砍伐森林 (Robust Random Cut Forest)
Also, known as “RRCF” algorithm is an unsupervised algorithm for detecting anomalies designed by Sudipto Guha, Nina Mishra, Gourav Roy, and Gourav Roy:
同样,被称为“ RRCF”算法的是由Sudipto Guha,Nina Mishra,Gourav Roy和Gourav Roy设计的用于检测异常的无监督算法:
This is proven in their work that it's superior to the Isolation forest algorithm in detecting anomalies in common especially in real-time streams. It works like iForest exactly. But the only difference here is that it’s not fully random. The probability of a dimension being chosen is proportional to the spread of the data on that dimension using the next formula:
他们的工作证明, 在检测常见异常(尤其是实时流)方面, 它优于隔离林算法 。 就像iForest一样。 但是这里唯一的区别是它不是完全随机的 。 使用下一个公式,选择维的概率与该维上数据的分布成比例 :
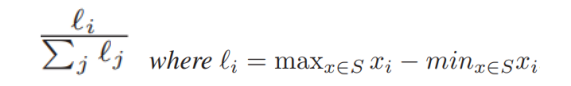
The score is different though but follows the same principle: high score = anomaly, low score normal point. So in this algorithm, the added values compared to iForest are:
分数虽然不同,但遵循相同的原理:高分=异常,低分正常。 因此,在此算法中,与iForest相比的增加值是:
The effective construction of the trees with stream data
利用流数据有效构建树
The handling of irrelevant dimensions
不相关尺寸的处理
Also, I wrote a version of my last code using this algorithm:
另外,我使用此算法编写了最后一个代码的版本:
摘要 (Summary)
After testing I didn't actually get very good results in detecting anomalies but got a very good performance in either training or testing. I think the reasons behind that are:
经过测试之后,我在检测异常方面实际上没有获得很好的结果,但是在培训或测试方面都获得了很好的表现。 我认为其背后的原因是:
- I used a small dataset for training我使用了一个小的数据集进行训练
- I should model my problem better, so using only the HSV color space histogram as an input may not be enough info, especially that there may be a lot of overlapping in images colors between different scenes我应该对问题进行更好的建模,因此仅使用HSV色彩空间直方图作为输入信息可能不够,尤其是不同场景之间的图像色彩可能存在很多重叠
But I believe that these algorithms are so effective for basic anomalies detection in different other fields, especially when you don’t want to get into the neural networks and their complexities. But always the best way is to model your problem first and decide your inputs, and according to your analysis, you can find the best solution.
但是我相信这些算法对于其他领域的基本异常检测非常有效,尤其是当您不想进入神经网络及其复杂性时。 但是,最好的方法始终是首先对问题建模,并确定您的投入,然后根据您的分析,找到最佳解决方案。
This is just a quick state of the art article to save you time searching on the internet about these topics, and give you a quick boost with iForest and RRCF algorithms.
这只是一篇最新的技术文章,可节省您在Internet上搜索这些主题的时间,并借助iForest和RRCF算法快速为您提供帮助。
I am still continuing to research more about detecting anomalies but in networks and I will post more articles about that in the future.
我仍在继续研究更多有关检测异常的方法,但是在网络中,以后我会发布更多有关此问题的文章。
翻译自: https://medium.com/@a.mhaish/algorithms-to-detect-anomalies-in-images-56a1793eba56
图像 异常检测算法
http://www.taodudu.cc/news/show-3585365.html
相关文章:
- 深度盘点:时序预测之异常检测算法综述
- 异常检测算法分类总结(含常用开源数据集)
- 异常检测算法综述
- 【机器学习】一文详解异常检测算法:KNN
- 时序异常检测算法汇总
- 异常检测算法分类总结
- 异常检测算法概述(全)
- 数学建模:异常检测算法
- 14种异常检测方法总结
- 异常检测/离群点检测算法汇总
- 动态规划--数塔问题
- 动态规划之硬币问题
- 动态规划法 第4关:求最长的单调递增子序列长度
- 『动态规划』动态规划概述
- 动态规划和贪心算法
- 动态规划拙见
- 点菜问题动态规划
- 动态规划入门篇
- 动态规划(C语言)
- matlab求解动态规划
- 动态规划1
- 动态规划算法的原理和实现(Java)
- 安卓Activity详解
- Activity的启动模式
- Android 程序,实现Activity之间的跳转
- Activity的四种启动方式
- Activity中销毁fragment
- Android 深入研究之 ✨ Activity启动流程+Activity生命周期✨
- activity监听器使用
- Android程序活动单元Activity
图像 异常检测算法_检测图像异常的算法相关推荐
- 异常行为检测算法_检测异常行为的异常或异常类型算法
异常行为检测算法 Anomaly detection is a critical problem that has been researched within diverse research ar ...
- 多元高斯分布异常检测代码_数据科学 | 异常检测的N种方法,阿里工程师都盘出来了...
↑↑↑↑↑点击上方蓝色字关注我们! 『运筹OR帷幄』转载 作者:黎伟斌.胡熠.王皓 编者按: 异常检测在信用反欺诈,广告投放,工业质检等领域中有着广泛的应用,同时也是数据分析的重要方法之一.随着数据量 ...
- felzenszwalb算法_学习图像场景解析的理论和应用(二)场景解析的经典算法分析之SLIC...
2003 年,任晓峰教授在图像分割技术层面上提出了超像素分割的这一概念,是指具有相似纹理.颜色.亮度等特征的相邻像素构成的有一定视觉意义的不规则像素块.它利用像素之间特征的相似性将像素分组,用少量的超 ...
- 提取图像感兴趣区域_从图像中提取感兴趣区域
提取图像感兴趣区域 Welcome to the second post in this series where we talk about extracting regions of intere ...
- 外星人图像和外星人太空船_卫星图像:来自太空的见解
外星人图像和外星人太空船 By Christophe Restif & Avi Hoffman, Senior Software Engineers, Crisis Response 危机应对 ...
- java 异常 最佳实践_处理Java异常的10种最佳实践
java 异常 最佳实践 在本文中,我们将看到处理Java异常的最佳实践. 用Java处理异常不是一件容易的事,因为新手很难理解,甚至专业的开发人员也可能浪费时间讨论应该抛出或处理哪些Java异常. ...
- 图像重建算法_基于深度学习图像重建算法(DLIR)对CT图像质量和剂量优化的研究:体模实验...
编者按:今年Joël Greffier博士等在European Radiology (IF 4.1)上发表了题为<Image quality and dose reduction opportu ...
- 斗牛怎么玩法算法_游戏开发中的算法
游戏技术这条路,可深可浅.你可以满足于完成GamePlay玩法层面的东西,你也可以满足于架构和框架设计层面的东西,你也可以醉心于了解某一游戏引擎带来的掌控感.但是,我们不该止步于此,止步与目前所见或所 ...
- k均值算法 二分k均值算法_如何获得K均值算法面试问题
k均值算法 二分k均值算法 数据科学访谈 (Data Science Interviews) KMeans is one of the most common and important cluste ...
最新文章
- 轻量级的项目管理工具-Leangoo
- 给CVPR颁“金酸莓奖”,知乎网友热议最差论文,战火烧到Reddit论坛
- 搭建服务器Apache+PHP+MySql需要注意的问题
- 使用Xcode、Android Studio将项目链接到Git
- 【个人笔记】OpenCV4 C++ 快速入门 00课
- idea tab页签颜色不明显,自定义颜色解决。
- .msi文件安装出现2503、2502错误
- 进化算法——组合优化
- 微处理器 微计算机 单片机,微处理器、微计算机、微处理机、CPU、单片机有什么区别?...
- FPGA学习积累之AM调制解调(解调部分没搞太明白)
- 假如你在泰坦尼克号上 你能活下来吗?——kaggle比赛泰坦尼克号数据集基于决策树
- chrome浏览器一键切换搜索引擎,一键切换谷歌和百度搜索(不需要重新输入keyword,带关键词切换引擎)
- mybatis-sqlserver批量新增返回id
- JS CSS 超出字符省略号,获取字符串实际所占长度,显示文字提示tooltip
- WebDAV之葫芦儿·派盘+纯纯写作
- DJL-Java开发者动手学深度学习之线性回归
- Essential Google Cloud Infrastructure: Foundation
- java 数据容器 有序_java容器-全览
- Promise过程中穿插用户操作
- 童年记忆中的湾里老爷爷