Lect3 最优化Optimization
文章目录
- Reference
- 简介
- 损失函数可视化
- 最优化
- 梯度计算
- 使用有限差值进行数值计算
- 微分计算梯度
- 梯度下降
Reference
- https://zhuanlan.zhihu.com/p/21387326?refer=intelligentunit
- https://zhuanlan.zhihu.com/p/21360434?refer=intelligentunit
简介
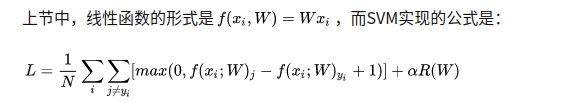
最优化是求一个最佳的WWW使得LLL最小,LLL由score function 和 loss function组成。
损失函数可视化

在两个维度上的loss值切片图,red表示large loss,blue表示small loss
最优化
- 策略#1:随机搜索
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
- 策略#2:随机局部搜索
step_size = 0.0001Wtry = W + np.random.randn(10, 3073) * step_size
- 策略#3:跟随梯度
当函数有多个参数的时候,我们称导数为偏导数。而梯度就是在每个维度上偏导数所形成的向量。

梯度计算
使用有限差值进行数值计算
def eval_numerical_gradient(f, x):""" 一个f在x处的数值梯度法的简单实现- f是只有一个参数的函数- x是计算梯度的点""" fx = f(x) # 在原点计算函数值grad = np.zeros(x.shape)h = 0.00001# 对x中所有的索引进行迭代it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])while not it.finished:# 计算x+h处的函数值ix = it.multi_indexold_value = x[ix]x[ix] = old_value + h # 增加hfxh = f(x) # 计算f(x + h)x[ix] = old_value # 存到前一个值中 (非常重要)# 计算偏导数grad[ix] = (fxh - fx) / h # 坡度it.iternext() # 到下个维度return grad
实际中用中心差值公式(centered difference formula) 效果更好。
效果更好。
微分计算梯度
梯度告诉我们损失函数在每个维度上的斜率,以此来进行更新。
- 步长的影响(learning rate):梯度指明了函数在哪个方向是变化率最大的,但是没有指明在这个方向上应该走多远。步长的影响,

- 在梯度负方向上更新

梯度下降
# 普通的梯度下降while True:weights_grad = evaluate_gradient(loss_fun, data, weights)weights += - step_size * weights_grad # 进行梯度更新
- 小批量数据梯度下降(Mini-batch gradient descent)
在大规模的应用中(比如ILSVRC挑战赛),训练数据可以达到百万级量级。如果像这样计算整个训练集,来获得仅仅一个参数的更新就太浪费了。一个常用的方法是计算训练集中的小批量(batches)数据。例如,在目前最高水平的卷积神经网络中,一个典型的小批量包含256个例子,而整个训练集是多少呢?一百二十万个。这个小批量数据就用来实现一个参数更新:
# 普通的小批量数据梯度下降while True:data_batch = sample_training_data(data, 256) # 256个数据weights_grad = evaluate_gradient(loss_fun, data_batch, weights)weights += - step_size * weights_grad # 参数更新
**这个方法之所以效果不错,是因为训练集中的数据都是相关的。**小批量数据的大小是一个超参数,但是一般并不需要通过交叉验证来调参。它一般由存储器的限制来决定的,或者干脆设置为同样大小,比如32,64,128等。之所以使用2的指数,是因为在实际中许多向量化操作实现的时候,如果输入数据量是2的倍数,那么运算更快。
Lect3 最优化Optimization相关推荐
- 深度学习-最优化笔记
深度学习-最优化笔记 作者:杜客 链接:https://zhuanlan.zhihu.com/p/21360434 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 译 ...
- 【CS231n】斯坦福大学李飞飞视觉识别课程笔记(九):最优化笔记(上)
[CS231n]斯坦福大学李飞飞视觉识别课程笔记 由官方授权的CS231n课程笔记翻译知乎专栏--智能单元,比较详细地翻译了课程笔记,我这里就是参考和总结. [CS231n]斯坦福大学李飞飞视觉识别课 ...
- halcon 形状匹配
halcon 形状匹配 1.例子 指定模板图像区域(也可以用draw_rectangle1画一个矩形) Row1 := 188 Column1 := 182 Row2 := 298 Column2 : ...
- 计算机图形学多边形填充代码_计算机图形学 Computer Graphics (第一周笔记及课件翻译)...
本文使用 Zhihu On VSCode 创作并发布 注:本文部分内容源自于UDE课程 Computer Graphics(Prof. Dr. Jens Krüger),仅供本人自己学习与作为课程笔记 ...
- SAP R3 系统技术基础
1.在线帮助 在SAPR/3三层客户/服务器体系结构的客户端,SAP提供了可移植的能运行于多种平台的一致的用户界面,称为SAPGUI.SAPGUI依据软件人类工程学的最新研究成果,以<SAPSt ...
- MATLAB图像数字水印的方案
3.1 图像数字水印的技术方案 在数据库中存储在国际互联网上传输的水印图像一般会被压缩,有时达到很高的压缩比.因此,数字水印算法所面临的第一个考验就是压缩.JPEG和EZW(Embedded Zero ...
- CS231n-课程总结
来自斯坦福CS231n课程 李飞飞主讲 我主要是对Notes部分的小总结 包括图像基础,神经网络Backprop,卷积层做了基础的了解 还有参数的调整,解决过拟合的问题等等 0_图像基础 1.k-Ne ...
- matlab wolfe准则,[原创]用“人话”解释不精确线搜索中的Armijo-Goldstein准则及Wolfe-Powell准则...
line search(一维搜索,或线搜索)是最优化(Optimization)算法中的一个基础步骤/算法.它可以分为精确的一维搜索以及不精确的一维搜索两大类. 在本文中,我想用"人话&qu ...
- r语言的MASS包干什么的_R语言常用包汇总
转载于:https://blog.csdn.net/sinat_26917383/article/details/50651464?locationNum=2&fps=1 一.一些函数包大汇总 ...
最新文章
- 男人约会动机大揭秘。
- bootstrap解析-栅格系统
- 手机淘宝以秒杀抢滩校园市场
- 不厌其烦的四大集成电路
- QSAR生命的发动机卟啉c20h14n4---用反向传导做卟啉的分子模型
- 在Python中变量名这样写,就是给自己挖坑
- ssl certificate 验证
- 贝叶斯公式设b_数据分析经典模型——朴素贝叶斯
- jquery 键盘事件
- java数据结构- - - -栈
- 2008不可错过的好莱坞电影
- 数据分析方向之连续性的价值分析
- Jmeter数据库mysql测试说明
- cmd命令配置MySQL
- 赋能房地产科技生态,“城越”加速器首期计划正式开启
- BAAF-Net源码阅读
- mmorpg无缝地图
- c++英雄联盟_C联盟
- 网络加速器是干什么用的?
- 如何实现WiFi与5G无缝切换?如何进行无线通信切换测试?(一)