python爬虫怎么爬小说_Python 新手] 爬虫练习:爬取起点中文网的小说排行并存入 excel 表格中...
使用的 python 库
1.request 库,用于向服务器发起请求信息。
2.lxml 库,用于解析服务器返回的 HTML 文件。
3.time 库,设置爬取时间差,防止短时间内多次页面请求而被限制访问。
4.xwlt 库,用于将数据存入 excel 表格之中。
爬取思路
1.爬取页面的网址为https://www.qidian.com/all?page=1page 的值不一样,由此可以得到所有页面的网址。,经过手动浏览可以发现页面之间
2.需要爬取的信息如下图所示:
在这里插入图片描述
3.在信息提取完成之后使用 xlwt 库将它们存入 excel 表格中。
爬虫代码
import xlwt
from lxml import etree
import request
import time
# 伪装请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
}
all_info_list = [] # 存储每部小说的各种信息列表
# 定义获取爬虫信息的函数
def get_info(url):
res = requests.get(url, headers=headers)
selector = etree.HTML(res.text)
# 采用 xpath 方法对网页信息进行搜索
infos = selector.xpath('//ul[@class="all-img-list cf"]/li') # 找到信息的循环点
for info in infos:
title = info.xpath('div[2]/h4/a/text()')[0]
author = info.xpath('div[2]/p[@class="author"]/a[@class="name"]/text()')[0]
style1 = info.xpath('div[2]/p[@class="author"]/a[2]/text()')[0]
style2 = info.xpath('div[2]/p[@class="author"]/a[3]/text()')[0]
style = style1+'-'+style2
complete = info.xpath('div[2]/p[@class="author"]/span/text()')[0]
introduce = info.xpath('div[2]/p[@class="intro"]/text()')[0].strip()
info_list = [title, author, style, complete, introduce]
all_info_list.append(info_list)
# 爬取成功后等待两秒
time.sleep(2)
# 主程序入口
if name == "main":
urls = ['https://www.qidian.com/all?page=.format(str(i)){}' for i in range(1, 101)]
for url in urls:
get_info(url)
# 写好 excel 表格中的各个属性名
header = ['书名', '作者', '类型', '状态', '简介']
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('sheet1')
for h in range(len(header)):
sheet.write(0, h, header[h])
i = 1
# 将提取到的信息写入 excel 表格中
for list in all_info_list:
j = 0
for data in list:
sheet.write(i, j, data)
j += 1
i += 1
# 将信息保存在 D:/reptile 目录下的 xiaoshuo.xls 文件中
book.save('D:/reptile/xiaoshuo.xls')
爬取结果
在这里插入图片描述
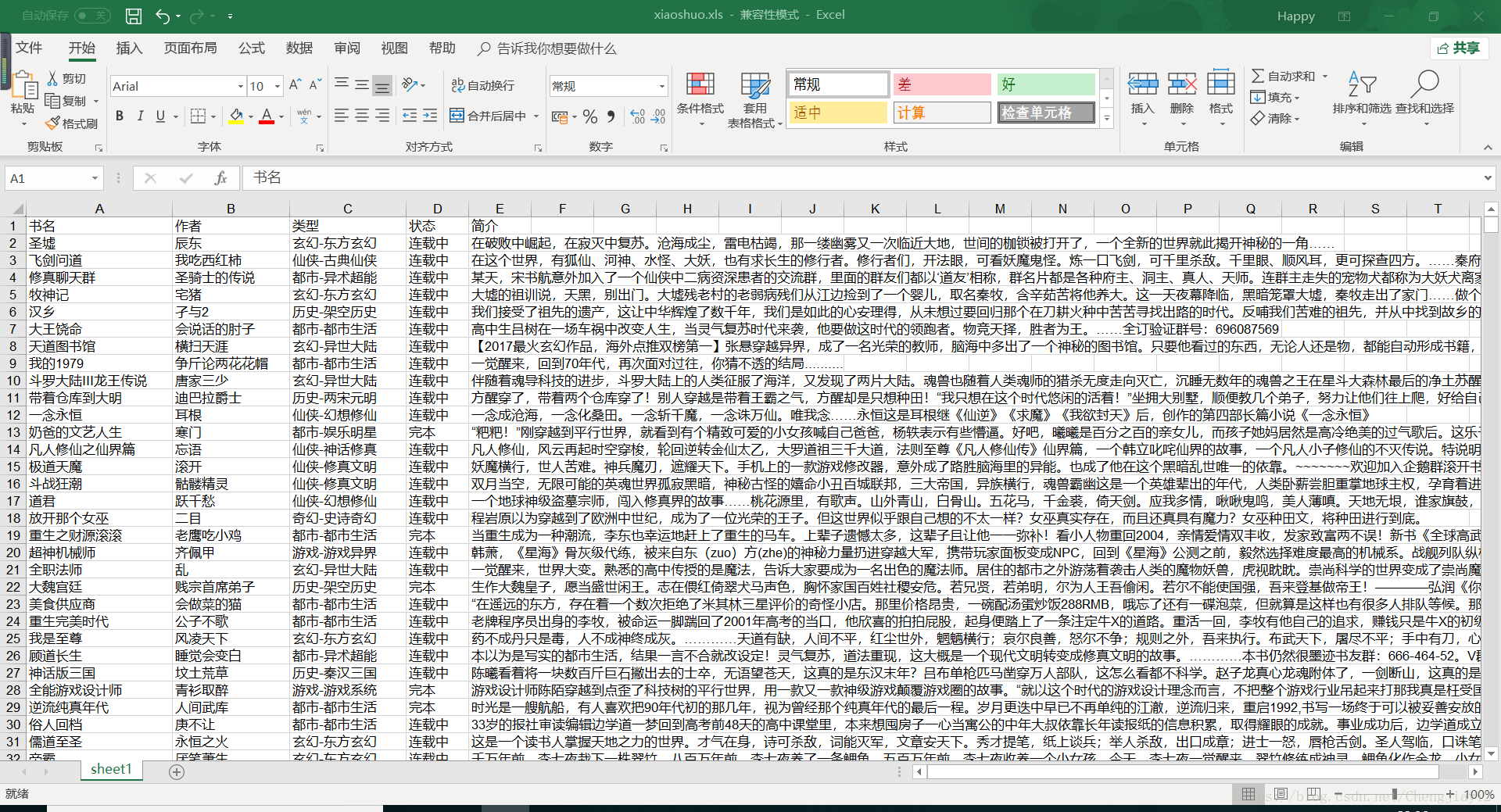
总结
虽然能成功的爬取小说的大部分信息,但是由于小说的字数信息在网页上并不是不变的,使用没能爬取到小说的字数信息,本次爬虫练习基本上完成了爬虫的功能,但在复杂页面的爬取上面还得继续学习。
python爬虫怎么爬小说_Python 新手] 爬虫练习:爬取起点中文网的小说排行并存入 excel 表格中...相关推荐
- Python爬虫学习之爬取豆瓣音乐Top250存入Excel表格中
前言 目标网站:https://music.douban.com/top250 任务: 爬取豆瓣音乐Top250的歌曲名 爬取豆瓣音乐Top250的歌曲对应的表演者.发行时间和音乐流派(分别对应下图斜 ...
- Python爬虫编程思想(48):项目实战:抓取起点中文网的小说信息
本文会利用requests库抓取起点中文网上的小说信息,并通过XPath提取相关的内容,最后将经过提取的内容保存到Excel文件中.本例需要使用第三方的xlwt库,该库用来通过Python操作Exce ...
- 爬取起点中文网的小说
运行无反应,也不报错,啥毛病?? import xlwt import requests from lxml import etree import timeall_info_list=[] def ...
- python 爬虫抓取网页数据导出excel_Python爬虫|爬取起点中文网小说信息保存到Excel...
前言: 爬取起点中文网全部小说基本信息,小说名.作者.类别.连载\完结情况.简介,并将爬取的数据存储与EXCEL表中 环境:Python3.7 PyCharm Chrome浏览器 主要模块:xlwt ...
- python爬虫之爬取起点中文网小说
python爬虫之爬取起点中文网小说 hello大家好,这篇文章带大家来制作一个python爬虫爬取阅文集团旗下产品起点中文网的程序,这篇文章的灵感来源于本人制作的一个项目:电脑助手 启帆助手 ⬆是项 ...
- python爬虫之爬取起点中文原创小说排行榜
学习python有段时间了,最近做了一个网上爬虫工具爬取起点中文原创小说排行榜数据,作为最近学习python的一个阶段性成果. 工具 对于做网络爬虫工具经常用到的就是chrome浏览器,主要用于抓取网 ...
- Python爬虫之爬取起点中文网
python之爬取起点中文网 最近学了爬虫,想实战一下就选取了最近经常看小说的起点中文网来进行爬取 过程如下: 分析爬取信息: 爬取网址:https://www.qidian.com/rank?chn ...
- 【Python爬虫实战】1.爬取A股上市公司年报链接并存入Excel
1.项目分析 数据来源:巨潮资讯 项目需求:按照股票代码,公司名称,年报全称,年份,下载链接等要素写入excel表 使用语言:python 第三方库:requests, re , time等 成品展示 ...
- python 获取li的内容_Python开发案例:爬取四川省统计局数据Matplotlib绘图
开发环境 Windows 10 企业版 Pycharm 2019.01 EAP Community Edition Python 3.7 前言 四川省统计局提供了过去若干月份的统计数据.统计局提供的数 ...
最新文章
- 区区几行Python代码,一分钟搞定一天工作量
- 20172310 2017-2018-2 《程序设计与数据结构》第八周学习总结
- LeetCode Median of Two Sorted Arrays (DFS)
- SpringMVC_1.认识MVC
- c# 四舍五入、上取整、下取整
- mysql 设置事物自动提交_mysql事务自动提交的问题
- Sentinel连接 Azure 活动日志中的数据
- nn.Conv2d的解释
- Android中的Binder机制
- No provisioned iOS devices are available with a compatible iOS version. Connect an iOS device with a
- Comic Life 3 for Mac(漫画创作软件)内附安装教程需要 macOS 11.x系统
- import dlib,报错:ImportError: libcublas.so.10.0: cannot open shared object file: No such file or direc
- 实验02 使用网络模拟器packet Tracer实验报告
- “FF新推荐”猥琐的弹窗如何关闭?
- OPenGL--Transform feedback示例解析
- 大数据公司宣传语 公司文化企业文化
- html微信怎么转发,微信朋友圈怎么转发
- 短信读取软件的开发阶段总结(二)
- SRS Premium Sound音效增强软件
- shell 100例
热门文章
- Vue中打印网页的指定部分的几种方法
- java里部分文件全选怎么整_选定全部文件的快捷键-怎么全选文件夹的文件-文件...
- 多智能体系统——竞争网络下异构多智能体系统的分组一致性问题 Group consensus of heterogeneous multi-agent system (附论文链接+源码Matlab)
- springboot毕设项目高校体育器材管理信息系统5us4g(java+VUE+Mybatis+Maven+Mysql)
- 特警把那盅犯形容的汝么厉害
- RFID潜行闭环应用
- 判断一个多边形是否是凸多边形
- Path环境变量是什么?有什么用?怎么工作?JDK,JRE,JVM,集成开发工具是什么?有什么用?怎么工作?JDK安装包文件结构?有必要设置Path环境变量?Eclipse和IDEA开发工具的运作
- 联力L216装机心得
- signature=a335cd7040789f936f75c72e4ba37676,浅谈新教材Reading的整体教学