DeepFM 参数理解(二)
原文: https://www.sohu.com/a/251772910_633698
什么是CTR预估
CTR(Click-Through-Rate)即点击通过率,是互联网广告常用的术语,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数除以广告的展现量。
CTR是衡量互联网广告效果的一项重要指标。
CTR预估数据特点:
- 输入中包含类别型和连续型数据。类别型数据需要one-hot,连续型数据可以先离散化再one-hot,也可以直接保留原值
- 维度非常高
- 数据非常稀疏
- 特征按照Field分组
CTR预估重点在于学习组合特征。注意,组合特征包括二阶、三阶甚至更高阶的,阶数越高越复杂,越不容易学习。
Google的论文研究得出结论:高阶和低阶的组合特征都非常重要,同时学习到这两种组合特征的性能要比只考虑其中一种的性能要好。
那么关键问题转化成:如何高效的提取这些组合特征。一种办法就是引入领域知识人工进行特征工程。这样做的弊端是高阶组合特征非常难提取,会耗费极大的人力。而且,有些组合特征是隐藏在数据中的,即使是专家也不一定能提取出来,比如著名的“尿布与啤酒”问题。
在DeepFM提出之前,已有LR,FM,FFM,FNN,PNN(以及三种变体:IPNN,OPNN,PNN*),Wide&Deep模型,这些模型在CTR或者是推荐系统中被广泛使用。
CTR模型演进历史
1. 线性模型
最开始CTR或者是推荐系统领域,一些线性模型取得了不错的效果。比如:LR,FTRL。
线性模型有个致命的缺点:无法提取高阶的组合特征。所以常用的做法是人为的加入pairwise feature interactions。
即使是这样:对于那些出现很少或者没有出现的组合特征以及高阶组合特征依旧无法提取。
LR最大的缺点就是无法组合特征,依赖于人工的特征组合,这也直接使得它表达能力受限,基本上只能处理线性可分或近似线性可分的问题。
2. FM模型
线性模型差强人意,直接导致了FM模型应运而生(在Kaggle上打比赛提出来的,取得了第一名的成绩)。
FM通过隐向量latent vector做内积来表示组合特征,从理论上解决了低阶和高阶组合特征提取的问题。
但是实际应用中受限于计算复杂度,一般也就只考虑到2阶交叉特征。
后面又进行了改进,提出了FFM,增加了Field的概念。
3. 遇上深度学习
随着DNN在图像、语音、NLP等领域取得突破,人们见见意识到DNN在特征表示上的天然优势,相继提出了使用CNN或RNN来做CTR预估的模型。
但是,CNN模型的缺点是:偏向于学习相邻特征的组合特征。 RNN模型的缺点是:比较适用于有序列(时序)关系的数据。
FNN的提出,应该算是一次非常不错的尝试:先使用预先训练好的FM,得到隐向量,然后作为DNN的输入来训练模型。缺点在于:受限于FM预训练的效果。
随后提出了PNN,PNN为了捕获高阶组合特征,在embedding layer和first hidden layer之间增加了一个product layer。
根据product layer使用内积、外积、混合分别衍生出IPNN, OPNN, PNN*三种类型。
无论是FNN还是PNN,他们都有一个绕不过去的缺点:对于低阶的组合特征,学习到的比较少。而前面我们说过,低阶特征对于CTR也是非常重要的。
Google意识到了这个问题,为了同时学习低阶和高阶组合特征,提出了Wide&Deep模型。
它混合了一个线性模型(Wide part)和Deep模型(Deep part)。这两部分模型需要不同的输入,而Wide part部分的输入,依旧依赖人工特征工程。
但是,这些模型普遍都存在两个问题:
偏向于提取低阶或者高阶的组合特征。不能同时提取这两种类型的特征。 需要专业的领域知识来做特征工程。
DeepFM在Wide&Deep的基础上进行改进,成功解决了这两个问题,并做了一些改进,其优势/优点如下:
- 不需要预训练FM得到隐向量
- 不需要人工特征工程
- 能同时学习低阶和高阶的组合特征
- FM模块和Deep模块共享Feature Embedding部分,可以更快的训练,以及更精确的训练学习
下面,就让我们走进DeepFM的世界,一起去看看它到底是怎么解决这些问题的!
DeepFM
主要做法如下:
首先,使用FM Component + Deep Component。FM提取低阶组合特征,Deep提取高阶组合特征。但是和Wide&Deep不同的是,DeepFM是端到端的训练,不需要人工特征工程。
其次,共享feature embedding。FM和Deep共享输入和feature embedding不但使得训练更快,而且使得训练更加准确。
相比之下,Wide&Deep中,input vector非常大,里面包含了大量的人工设计的pairwise组合特征,增加了他的计算复杂度。
DeepFM架构图:
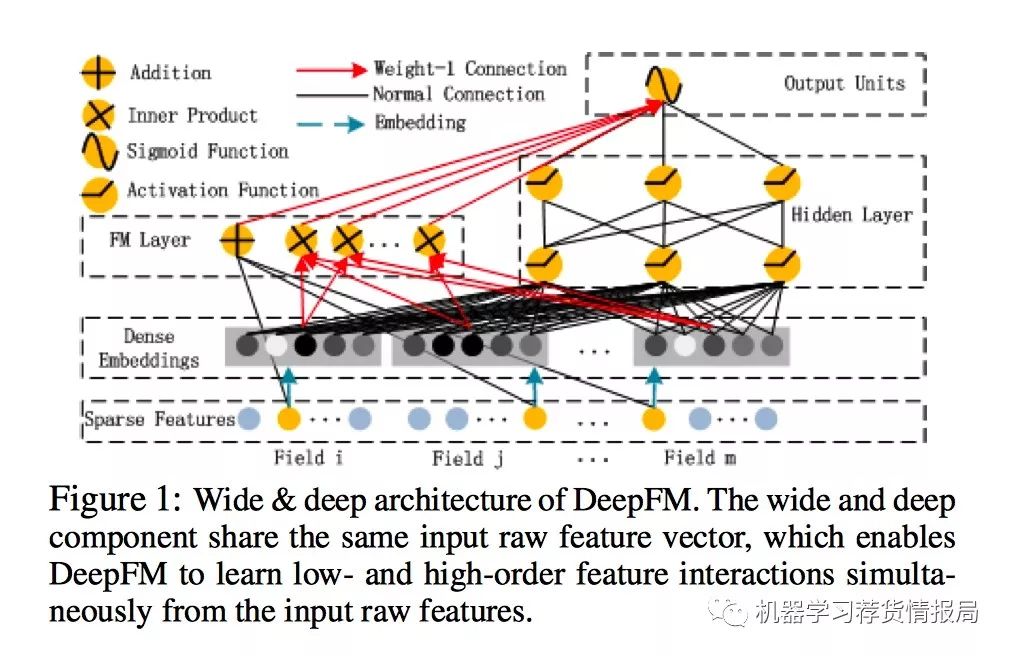
1. FM Component
FM部分的输出由两部分组成:一个Addition Unit,多个内积单元。

这里的d是输入one-hot之后的维度,我们一般称之为feature_size。对应的是one-hot之前的特征维度,我们称之为field_size。
FM架构图:
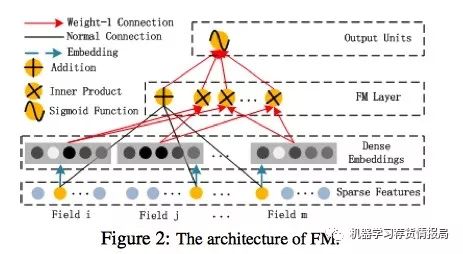
Addition Unit反映的是1阶的特征。内积单元反映的是2阶的组合特征对于预测结果的影响。
注意:
虽然公式上Y_fm是所有部分都求和,是一个标量。但是从FM模块的架构图上我们可以看到,输入到输出单元的部分并不是一个标量,应该是一个向量。
实际实现中采用的是FM化简之后的内积公式,最终的维度是:field_size + embedding_size
这里分别展开解释下维度的两部分是怎么来的,对于理解模型还是很重要的:
第一、field_size对应的是
这里的X是one-hot之后的,one-hot之后,我们认为X的每一列都是一个单独的维度的特征。
这里我们表达的是X的1阶特征,说白了就是单独考虑X的每个特征,他们对最终预测的影响是多少。
是多少那?是W!W对应的就是这些维度特征的权重。假设one-hot之后特征数量是feature_size,那么W的维度就是 (feature_size, 1)。
这里 是把X和W每一个位置对应相乘相加。由于X是one-hot之后的,所以相当于是进行了一次Embedding!X在W上进行一次嵌入,或者说是一次选择,选择的是W的行,按照X中不为0的那些特征对应的index,选择W中row=index的行。
这里解释下Embedding: W是一个矩阵,每一行对应X的一个维度的特征(这里是one-hot之后的维度,一定要注意)。W的列数为1,表示嵌入之后的维度是1。
W的每一行对应一个特征,相当于是我们拿输入Xi作为一个index, Xi的任意一个Field i中只有1个为1,其余的都是0。哪个位置的特征值为1,那么就选中W中对应的行,作为嵌入后这个Field i对应的新的特征表示。
对于每一个Field都执行这样的操作,就选出来了X_i Embedding之后的表示。注意到,每个Field都肯定会选出且仅选出W中的某一行(想想为什么?),因为W的列数是固定的,每一个Field都选出W.cols作为对应的新特征。
把每个Field选出来的这些W的行,拼接起来就得到了X Embedding后的新的表示:维度是num(Field) * num(W.cols)。虽然每个Field的长度可能不同,但是都是在W中选择一行,所以选出来的长度是相同的。
这也是Embedding的一个特性:虽然输入的Field长度不同,但是Embedding之后的长度是相同的。
什么?Embedding这么复杂,怎么实现的?非常简单!直接把X和W做内积即可。是的,你没看错,就是这么简单(tensoflow中封装了下,改成了tf.nn.embedding_lookup(embeddings, index),原理就是不做乘法,直接选出对应的行)。
自己写个例子试试:X.shape=(1, feature_size), W.shape = (feture_size, embedding_size)就知道为什么选出1对应W的行和做内积结果是一样的是怎么回事了。
所以:FM模块图中,黑线部分是一个全连接!W就是里面的权重。把输入X和W相乘就得到了输出。至于Addition Unit,我们就不纠结了,这里并没有做什么加法,就把他当成是反应1阶特征对输出的影响就行了。

FM论文中给出了化简后的公式:

这里最后的结果中是在[1,K]上的一个求和。 K就是W的列数,就是Embedding后的维度,也就是embedding_size。也就是说,在DeepFM的FM模块中,最后没有对结果从[1,K]进行求和。而是把这K个数拼接起来形成了一个K维度的向量。
FM Component总结:
- FM模块实现了对于1阶和2阶组合特征的建模。
- 没有使用预训练
- 没有人工特征工程
- embedding矩阵的大小是:特征数量 * 嵌入维度。 然后用一个index表示选择了哪个特征
需要训练的有两部分:
- input_vector和Addition Unit相连的全连接层,也就是1阶的Embedding矩阵
- Sparse Feature到Dense Embedding的Embedding矩阵,中间也是全连接的,要训练的是中间的权重矩阵,这个权重矩阵也就是隐向量V
Deep Component
Deep Component架构图:

Deep Component是用来学习高阶组合特征的。网络里面黑色的线是全连接层,参数需要神经网络去学习。
由于CTR或推荐系统的数据one-hot之后特别稀疏,如果直接放入到DNN中,参数非常多,我们没有这么多的数据去训练这样一个网络。所以增加了一个Embedding层,用于降低纬度。
这里继续补充下Embedding层,两个特点:
- 尽管输入的长度不同,但是映射后长度都是相同的.embedding_size 或 k
- embedding层的参数其实是全连接的Weights,是通过神经网络自己学习到的
Embedding层的架构图:

值得注意的是:FM模块和Deep模块是共享feature embedding的(也就是V)。
好处:模型可以从最原始的特征中,同时学习低阶和高阶组合特征 不再需要人工特征工程。Wide&Deep中低阶组合特征就是同过特征工程得到的。
DeepFM 参数理解(二)相关推荐
- JVM实用参数(二)参数分类和即时(JIT)编译器诊断
作者: PATRICK PESCHLOW 原文地址 译者:赵峰 校对:许巧辉 在这个系列的第二部分,我来介绍一下HotSpot JVM提供的不同类别的参数.我同样会讨论一些关于JIT编译 ...
- C语言基础知识之define宏定义表达式,undef,内存对齐,a和a的区别,数组知识点,int (*)[10] p,二维数组参数与二维指针参数,函数指针数组,常见的内存错误及对策
一.用define宏定义表达式 1.定义一年有多少秒: #define SEC_A_YEAR 60*60*24*365 //上述描述不可靠,没有考虑到在16位系统下把这样一个数赋给整型变量的时候可能会 ...
- Tensorflow的MNIST进阶教程CNN网络参数理解
背景 问题说明 分析 LeNet5参数 MNIST程序参数 遗留问题 小结 背景 之前博文中关于CNN的模型训练功能上是能实现,但是研究CNN模型内部结构的时候,对各个权重系数ww,偏差bb的shap ...
- 深入理解二维码生成尺寸
深入理解二维码生成尺寸 详细了解二维码的原理,CSDN这两篇博客不错: 转自MachineChen的博客:http://blog.csdn.net/u012611878/article/details ...
- 微信生成带参数的二维码,合成海报,扫码后推送小程序?
微信服务号渠道二维码功能,支持生成带参数二维码,合成海报二维码,微信扫码后推送内容:结合微号帮平台48小时信息推送,推送微信小程序. 带参二维码 海报二维码 微信扫码后回复 48小时信息推送 在微号帮 ...
- 参数匹配模型——Python学习之参数(二)
参数匹配模型--Python学习之参数(二) 文章目录 参数匹配模型--Python学习之参数(二) 位置参数:从左至右进行匹配 关键字参数:通过参数名进行匹配 默认参数:为没有传入值的参数定义参数值 ...
- python制作微信个人二维码_Python实现 | 微信带参数的二维码
微信运营越来越多了,这种带参数二维码的使用场景还挺多的,但是网上的实现大都是PHP啥的,还不想写PHP的我只好用Python实现一下了. 关于带参二维码的介绍,记得先看官网:生成带参数的二维码. 先大 ...
- vue js前端根据所需参数生成二维码并下载
需要一个插件 qrcodejs2, 使用 npm install qrcodejs2 --save 下载该依赖包. 在vue中引入(我这边是vue2).import QRCode from 'qrco ...
- db链接相关链接相关参数理解
db链接相关链接相关参数理解 max_connect_errors:tcp/ip链接建立后等待client发送账号,密码等身份验证信息的超时时间的次数 connect_timeout:tcp/ip链接 ...
- [转帖]/proc/sys/net/ipv4/ 下参数理解
/proc/sys/net/ipv4/ 下参数理解,方便服务器优化 2017年06月02日 16:52:27 庞叶蒙 阅读数 3065 https://blog.csdn.net/pangyemeng ...
最新文章
- 趣谈 23 种设计模式(多图 + 代码)
- 第 21 章 System Utilities 配置工具
- JAVA中的集合与排序
- 孙正义的软银愿景宫斗内幕:印度裔高管争宠,黑公关手段,设局桃色仙人跳...
- ecma 2018, javascript spread syntax behaves like Object.assign
- FlexPaper二次开发问题及搜索高亮显示
- DOS命令大全 收藏
- MySQL安装错误:/usr/local/mysql/libexec/mysqld: unknown option '--skip-federated'
- travis-ci_使用Travis-CI的SpringBoot应用程序的CI / CD
- Tornado 高并发源码分析之六---异步编程的几种实现方式
- CSS——可视化格式模型
- mysql 不省略0_mysql数据类型和运算符
- 2014年前端开发者如何提升自己
- 算法分析与设计 八大排序算法
- 在网易游戏的第三年——Jerish的2021总结
- 【Windows】将bat文件注册为windows服务
- 入选全球灯塔工厂 西部数据践行可持续发展承诺
- 抓取、下载某位博主的豆瓣日记
- Linux中PATH、PYTHONPAT、sys.path小结
- SkyWalking调研与初步实践