爬取天眼查数据 附代码
摘要: 一、常规抓包分析 比如要爬取企业注册信息查询_企业工商信息查询_企业信用信息查询平台_发现人与企业关系的平台-天眼查该页面的基础信息。 通过火狐浏览器抓包,可以发现,所要数据都在下图的json文件里 查看其请求 伪装成浏览器爬取该文件: 伪装成浏览器爬取该文件: import requests header = { 'Host': 'www.
一、常规抓包分析
比如要爬取企业注册信息查询_企业工商信息查询_企业信用信息查询平台_发现人与企业关系的平台-天眼查该页面的基础信息。
通过火狐浏览器抓包,可以发现,所要数据都在下图的json文件里
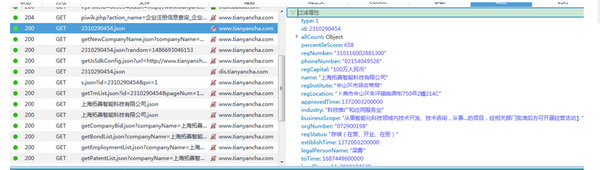
查看其请求
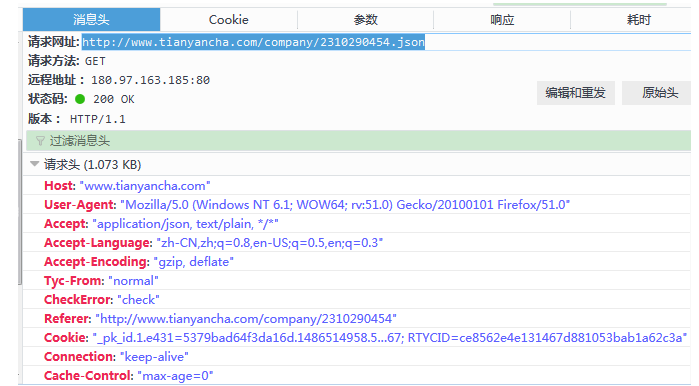
伪装成浏览器爬取该文件:
伪装成浏览器爬取该文件:
import requests
header = {
'Host': 'www.tianyancha.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Tyc-From': 'normal',
'CheckError': 'check',
'Connection': 'keep-alive',
'Referer': 'http://www.tianyancha.com/company/2310290454',
'Cache-Control': 'max-age=0'
,
'Cookie': '_pk_id.1.e431=5379bad64f3da16d.1486514958.5.1486693046.1486691373.; Hm_lvt_e92c8d65d92d534b0fc290df538b4758=1486514958,1486622933,1486624041,1486691373; _pk_ref.1.e431=%5B%22%22%2C%22%22%2C1486691373%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D95IaKh1pPrhNKUe5nDCqk7dJI9ANLBzo-1Vjgi6C0VTd9DxNkSEdsM5XaEC4KQPO%26wd%3D%26eqid%3Dfffe7d7e0002e01b00000004589c1177%22%5D; aliyungf_tc=AQAAAJ5EMGl/qA4AKfa/PDGqCmJwn9o7; TYCID=d6e00ec9b9ee485d84f4610c46d5890f; tnet=60.191.246.41; _pk_ses.1.e431=*; Hm_lpvt_e92c8d65d92d534b0fc290df538b4758=1486693045; token=d29804c0b88842c3bb10c4bc1d48bc80; _utm=55dbdbb204a74224b2b084bfe674a767; RTYCID=ce8562e4e131467d881053bab1a62c3a'
}
r = requests.get('http://www.tianyancha.com/company/2310290454.json', headers=header)
print(r.text)
print(r.status_code)
返回结果如下:
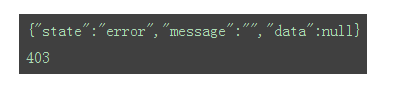
状态码为403,常规爬取不成功。考虑下面一种方式。
二、使用selenium+PHANTOMJS获取数据
首先下载phantomjs到本地,并将phantomjs.exe存放在系统环境变量所在目录下(本人讲该文件放置在D:/Anaconda2/路径下)。
为phantomjs添加useragent信息(经测试,不添加useragent信息爬取到的是错乱的信息):
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilitiesdcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0")
driver = webdriver.PhantomJS(executable_path='D:/Anaconda2/phantomjs.exe', desired_capabilities=dcap)
获取网页源代码:
driver.get('http://www.tianyancha.com/company/2310290454')
#等待5秒,更据动态网页加载耗时自定义
time.sleep(5)
# 获取网页内容
content = driver.page_source.encode('utf-8')
driver.close()
print(content)
对照网页,爬取的源代码信息正确,接下去解析代码,获取对应的信息。
简单写了下获取基础信息的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
from bs4 import BeautifulSoup
from selenium.webdriver.common.desired_capabilities import DesiredCapabilitiesdef driver_open():dcap = dict(DesiredCapabilities.PHANTOMJS)dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0")driver = webdriver.PhantomJS(executable_path='D:/Anaconda2/phantomjs.exe', desired_capabilities=dcap)
return driver
def get_content(driver,url):driver.get(url)
#等待5秒,更据动态网页加载耗时自定义time.sleep(5)
# 获取网页内容content = driver.page_source.encode('utf-8')driver.close()soup = BeautifulSoup(content, 'lxml')
return soupdef get_basic_info(soup):company = soup.select('div.company_info_text > p.ng-binding')[0].text.replace("\n","").replace(" ","")fddbr = soup.select('.td-legalPersonName-value > p > a')[0].textzczb = soup.select('.td-regCapital-value > p ')[0].textzt = soup.select('.td-regStatus-value > p ')[0].text.replace("\n","").replace(" ","")zcrq = soup.select('.td-regTime-value > p ')[0].textbasics = soup.select('.basic-td > .c8 > .ng-binding ')hy = basics[0].textqyzch = basics[1].textqylx = basics[2].textzzjgdm = basics[3].textyyqx = basics[4].textdjjg = basics[5].texthzrq = basics[6].texttyshxydm = basics[7].textzcdz = basics[8].textjyfw = basics[9].text
print u'公司名称:'+company
print u'法定代表人:'+fddbr
print u'注册资本:'+zczb
print u'公司状态:'+zt
print u'注册日期:'+zcrq
# print basics
print u'行业:'+hy
print u'工商注册号:'+qyzch
print u'企业类型:'+qylx
print u'组织机构代码:'+zzjgdm
print u'营业期限:'+yyqx
print u'登记机构:'+djjg
print u'核准日期:'+hzrq
print u'统一社会信用代码:'+tyshxydm
print u'注册地址:'+zcdz
print u'经营范围:'+jyfwdef get_gg_info(soup):ggpersons = soup.find_all(attrs={"event-name": "company-detail-staff"})ggnames = soup.select('table.staff-table > tbody > tr > td.ng-scope > span.ng-binding')
# print(len(gg))
for i in range(len(ggpersons)):ggperson = ggpersons[i].textggname = ggnames[i].text
print (ggperson+" "+ggname)def get_gd_info(soup):tzfs = soup.find_all(attrs={"event-name": "company-detail-investment"})
for i in range(len(tzfs)):tzf_split = tzfs[i].text.replace("\n","").split()tzf = ' '.j爬取天眼查数据 附代码相关推荐
- Python自动化爬取天眼查数据
首先要注册一个账号密码,通过账号密码登录,并且滑块验证,自动输入搜索关键词,进行跳转翻页爬取数据,并保存到Excel文件中. 代码运行时,滑块验证经常不通过,被吃掉,但是发现打包成exe运行没有这个问 ...
- 爬取天眼查 的python 代码
''' @Description: 天眼查关键词爬取风险信息 @Author: bessie_lina @Date: 2019-08-14 17:39:30 @LastEditTime: 2019-0 ...
- python爬取天眼查数据(未破解图片验证及ajax版)
import time import requests from bs4 import BeautifulSoup import lxml import json import copy import ...
- Python爬虫:Xpath爬取网页信息(附代码)
Python爬虫:Xpath爬取网页信息(附代码) 上一次分享了使用Python简单爬取网页信息的方法.但是仅仅对于单一网页的信息爬取一般无法满足我们的数据需求.对于一般的数据需求,我们通常需要从一个 ...
- python分支机构_基于Python爬取天眼查网站的企业信息!Python无所不能!
注:这是一个在未登录的情况下,根据企业名称搜索,爬取企业页面数据的采集程序,是一个比较简单的爬虫,基本上只用到了代理,没有用到其他的反反爬技术,不过由于爬取的数据比较多, 适合刷解析技能的熟练度 . ...
- 记录一次利用python调用chrome爬取天眼查网址工商信息的过程
1.首先准备工作: 1.pyhton3.6(官网有下载).https://www.python.org/downloads/release/python-363/ 2.pycharm 2017 开发工 ...
- python爬取天眼查存入excel表格_爬虫案例1——爬取新乡一中官网2018届高考录取名单...
有一种非常常见并且相对简单的网络爬虫,工作流程大概是这样的: 访问目标网页 提取目标网页内表格信息 写入excel文件并保存 初次实践,我决定尝试写一个这样的爬虫.经过一番构思,我准备把爬取新乡一中官 ...
- python 爬虫实例-python爬虫实例,一小时上手爬取淘宝评论(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- Python爬虫实例,一小时上手爬取淘宝评论(附代码)!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- 猫眼api html,爬取猫眼电影数据(示例代码)
1 static void Main(string[] args)2 {3 int errorCount = 0;//计算爬取失败的次数 4 int count = 450;//结束范围 5 for ...
最新文章
- micropython mqtt_MicroPython使用MQTT协议接入OneNET云平台
- 2020年最火本科生专业来了!180所高校新增人工智能专业
- 保障粮食安全-农业大健康-温铁军 谋定落实粮食安全责任
- git clone 出错SSL certificate problem, verify that the CA cert is OK.
- pyqt5讲解2:QPushButton,QRadioButton,QCheckBox
- A20修改串口设备文件
- 计算机作曲 研究生 武汉音乐学院,计算机音乐作曲(武汉音乐学院2021年招收攻读硕士学位研究生考试大纲)...
- red hat linux 关闭防火墙,red hat enterprise linux 7关闭防火墙的方法
- 如何在Sitecore CMS中打开内容编辑器
- iOS 使用SourceTree注意事项
- Chipmunk2D中文手册
- 文字转语音真人发声免费的有哪些?文字转语音有这两款软件就够了
- unigui发布_unigui+fastReport实现web打印方案
- 杭州师范大学仓前校区宽带认证客户端电信用户拨号宽带链接路由器
- PS如何扣除部分图并添加图
- 倍福--电子凸轮的基本配置
- thrust示例ex4: Sinc方法数据重采样加密
- IOS防破解 加密
- 对话周鸿袆:从程序员创业谈起
- java 接口 练习题_JAVA 接口练习题