KD Tree的原理及Python实现

1. 原理篇
我们用大白话讲讲KD-Tree是怎么一回事。
1.1 线性查找
假设数组A为[0, 6, 3, 8, 7, 4, 11],有一个元素x,我们要找到数组A中距离x最近的元素,应该如何实现呢?比较直接的想法是用数组A中的每一个元素与x作差,差的绝对值最小的那个元素就是我们要找的元素。假设x = 2,那么用数组A中的所有元素与x作差得到[-2, 4, 1, 6, 5, 2, 9],其中绝对值最小的是1,对应的元素是数组A中的3,所以3就是我们的查找结果。
1.2 二分查找
如果我们有大量的元素要在数组A中进行查找,那么1.1的方式就显得不是那么高效了,如果数组A的长度为N,那么每次查找都要进行N次操作,即算法复杂度为O(N)。
- 我们把数组A进行升序排列,得到[0, 3, 4, 6, 7, 8, 11];
- 令x = 2,数组中间的元素是6,2小于6,所以2只可能存在于6的左边,我们只需要在数组[0, 3, 4]中继续查找;
- 左边的数组中间的元素是3,2小于3,所以2只可能存在于3的左边,即数组[0];
- 由于数组[0]无法再分割,查找结束;
- x需要跟我们最终找到的0,以及倒数第二步找到的3进行比较,发现2离3更近,所以查找结果为3。
这种查找方法就是二分查找,其算法复杂度为O(Log2(N))。
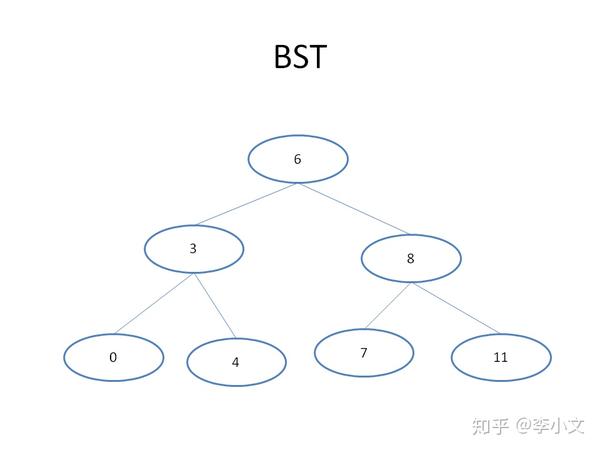
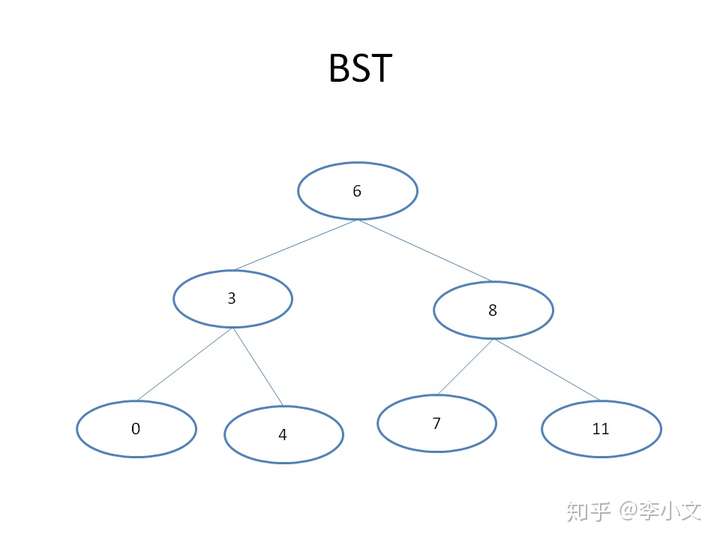
1.3 BST
除了数组之外,有没有更直观的数据结构可以实现1.2的二分查找呢?答案就是二分查找树,全称Binary Search Tree,简称BST。把数组A建立成一个BST,结构如下图所示。我们只需要访问根节点,进行值比较来确定下一节点,如此循环往复直到访问到叶子节点为止。
1.4 多维数组
现在我们把问题加点难度,假设数组B为[[6, 2], [6, 3], [3, 5], [5, 0], [1, 2], [4, 9], [8, 1]],有一个元素x,我们要找到数组B中距离x最近的元素,应该如何实现呢?比较直接的想法是用数组B中的每一个元素与x求距离,距离最小的那个元素就是我们要找的元素。假设x = [1, 1],那么用数组A中的所有元素与x求距离得到[5.0, 5.4, 4.5, 4.1, 1.0, 8.5, 7.0],其中距离最小的是1,对应的元素是数组B中的[1, 2],所以[1, 2]就是我们的查找结果。
1.5 再次陷入困境
如果我们有大量的元素要在数组B中进行查找,那么1.4的方式就又显得不是那么高效了,如果数组B的长度为N,那么每次查找都要进行N次操作,即算法复杂度为O(N)。
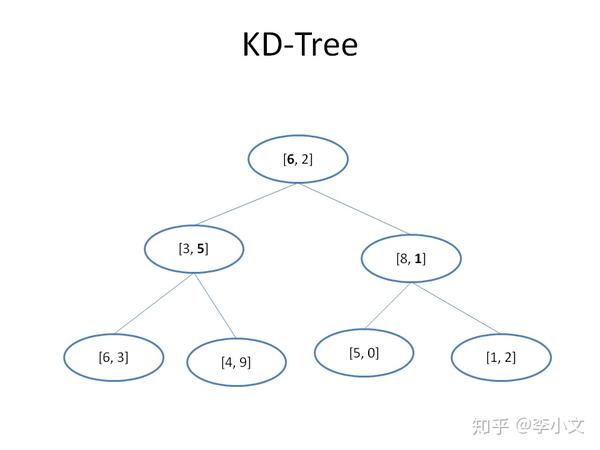
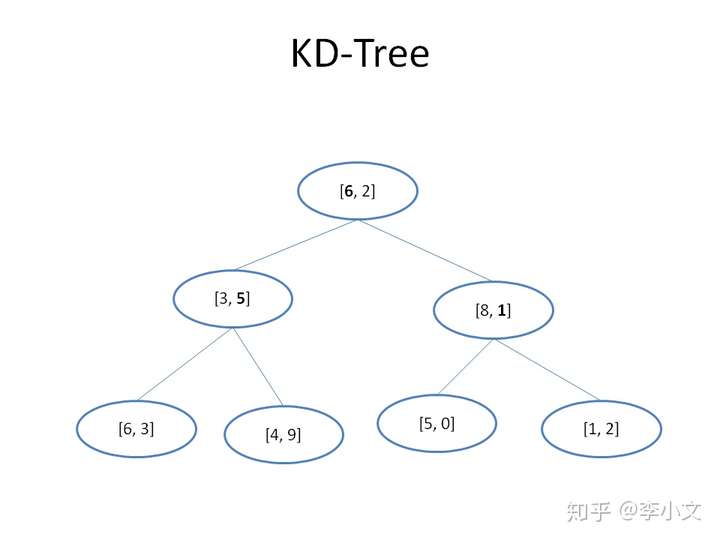
1.6 什么是KD-Tree
这时候已经没办法用BST,不过我们可以对BST做一些改变来适应多维数组的情况。当当当当~,这时候该KD-Tree出场了。废话不多说,先上图:
1.7 如何建立KD-Tree
您可能会问,刚在那张图的KD Tree又是如何建立的呢? 很简单,只需要5步:
1. 建立根节点;
2. 选取方差最大的特征作为分割特征;
3. 选择该特征的中位数作为分割点;
4. 将数据集中该特征小于中位数的传递给根节点的左儿子,大于中位数的传递给根节点的右儿子;
5. 递归执行步骤2-4,直到所有数据都被建立到KD Tree的节点上为止。
不难看出,KD Tree的建立步骤跟BST是非常相似的,可以认为BST是KD Tree在一维数据上的特例。KD Tree的算法复杂度介于O(Log2(N))和O(N)之间。
1.8 特征选取
您可能还会问,为什么方差最大的适合作为特征呢? 因为方差大,数据相对“分散”,选取该特征来对数据集进行分割,数据散得更“开”一些。
1.9 分割点选择
您可能又要问,为什么选择中位数作为分割点呢? 因为借鉴了BST,选取中位数,让左子树和右子树的数据数量一致,便于二分查找。
1.10 利用KD-Tree查找元素
KD Tree建好之后,接下来就要利用KD Tree对元素进行查找了。查找的方式在BST的基础上又增加了一些难度,如下:
1. 从根节点开始,根据目标在分割特征中是否小于或大于当前节点,向左或向右移动。
2. 一旦算法到达叶节点,它就将节点点保存为“当前最佳”。
3. 回溯,即从叶节点再返回到根节点
4. 如果当前节点比当前最佳节点更接近,那么它就成为当前最好的。
5. 如果目标距离当前节点的父节点所在的将数据集分割为两份的超平面的距离更接近,说明当前节点的兄弟节点所在的子树有可能包含更近的点。因此需要对这个兄弟节点递归执行1-4步。
1.11 超平面
所以什么是超平面呢,听起来让人一脸懵逼。
以[0, 2, 0], [1, 4, 3], [2, 6, 1]的举例:
1. 如果用第二维特征作为分割特征,那么从三个数据点中的对应特征取出2, 4, 6,中位数是4;
2. 所以[1, 4, 3]作为分割点,将[0, 2, 0]划分到左边,[2, 6, 1]划分到右边;
3. 从立体几何的角度考虑,三维空间得用一个二维的平面才能把空间一分为二,这个平面可以用y = 4来表示;
4. 点[0, 2, 0]到超平面y = 4的距离就是 sqrt((2 - 4) ^ 2) = 2;
5. 点[2, 6, 1]到超平面y = 4的距离就是 sqrt((6 - 4) ^ 2) = 2。
2. 实现篇
本人用全宇宙最简单的编程语言——Python实现了KD-Tree算法,没有依赖任何第三方库,便于学习和使用。简单说明一下实现过程,更详细的注释请参考本人github上的代码。
2.1 创建Node类
初始化,存储父节点、左节点、右节点、特征及分割点。
class Node(object):def __init__(self):self.father = Noneself.left = Noneself.right = Noneself.feature = Noneself.split = None2.2 获取Node的各个属性
def __str__(self):return "feature: %s, split: %s" % (str(self.feature), str(self.split))2.3 获取Node的兄弟节点
@property
def brother(self):if self.father is None:ret = Noneelse:if self.father.left is self:ret = self.father.rightelse:ret = self.father.leftreturn ret2.4 创建KDTree类
初始化,存储根节点。
class KDTree(object):def __init__(self):self.root = Node()2.5 获取KDTree属性
便于我们查看KD Tree的节点值,各个节点之间的关系。
def __str__(self):ret = []i = 0que = [(self.root, -1)]while que:nd, idx_father = que.pop(0)ret.append("%d -> %d: %s" % (idx_father, i, str(nd)))if nd.left is not None:que.append((nd.left, i))if nd.right is not None:que.append((nd.right, i))i += 1return "\n".join(ret)2.6 获取数组中位数的下标
def _get_median_idx(self, X, idxs, feature):n = len(idxs)k = n // 2col = map(lambda i: (i, X[i][feature]), idxs)sorted_idxs = map(lambda x: x[0], sorted(col, key=lambda x: x[1]))median_idx = list(sorted_idxs)[k]return median_idx2.7 计算特征的方差
注意这里用到了方差公式,D(X) = E(X^2)-[E(X)]^2
def _get_variance(self, X, idxs, feature):n = len(idxs)col_sum = col_sum_sqr = 0for idx in idxs:xi = X[idx][feature]col_sum += xicol_sum_sqr += xi ** 2return col_sum_sqr / n - (col_sum / n) ** 22.8 选择特征
取方差最大的的特征作为分割点特征。
def _choose_feature(self, X, idxs):m = len(X[0])variances = map(lambda j: (j, self._get_variance(X, idxs, j)), range(m))return max(variances, key=lambda x: x[1])[0]2.9 分割特征
把大于、小于中位数的元素分别放到两个列表中。
def _split_feature(self, X, idxs, feature, median_idx):idxs_split = [[], []]split_val = X[median_idx][feature]for idx in idxs:if idx == median_idx:continuexi = X[idx][feature]if xi < split_val:idxs_split[0].append(idx)else:idxs_split[1].append(idx)return idxs_split2.10 建立KDTree
使用广度优先搜索的方式建立KD Tree,注意要对X进行归一化。
def build_tree(self, X, y):X_scale = min_max_scale(X)nd = self.rootidxs = range(len(X))que = [(nd, idxs)]while que:nd, idxs = que.pop(0)n = len(idxs)if n == 1:nd.split = (X[idxs[0]], y[idxs[0]])continuefeature = self._choose_feature(X_scale, idxs)median_idx = self._get_median_idx(X, idxs, feature)idxs_left, idxs_right = self._split_feature(X, idxs, feature, median_idx)nd.feature = featurend.split = (X[median_idx], y[median_idx])if idxs_left != []:nd.left = Node()nd.left.father = ndque.append((nd.left, idxs_left))if idxs_right != []:nd.right = Node()nd.right.father = ndque.append((nd.right, idxs_right))2.11 搜索辅助函数
比较目标元素与当前结点的当前feature,访问对应的子节点。反复执行上述过程,直到到达叶子节点。
def _search(self, Xi, nd):while nd.left or nd.right:if nd.left is None:nd = nd.rightelif nd.right is None:nd = nd.leftelse:if Xi[nd.feature] < nd.split[0][nd.feature]:nd = nd.leftelse:nd = nd.rightreturn nd2.12 欧氏距离
计算目标元素与某个节点的欧氏距离,注意get_euclidean_distance这个函数没有进行开根号的操作,所以求出来的是欧氏距离的平方。
def _get_eu_dist(self, Xi, nd):X0 = nd.split[0]return get_euclidean_distance(Xi, X0)2.13 超平面距离
计算目标元素与某个节点所在超平面的欧氏距离,为了跟2.11保持一致,要加上平方。
def _get_hyper_plane_dist(self, Xi, nd):j = nd.featureX0 = nd.split[0]return (Xi[j] - X0[j]) ** 22.14 搜索函数
搜索KD Tree中与目标元素距离最近的节点,使用广度优先搜索来实现。
def nearest_neighbour_search(self, Xi):dist_best = float("inf")nd_best = self._search(Xi, self.root)que = [(self.root, nd_best)]while que:nd_root, nd_cur = que.pop(0)while 1:dist = self._get_eu_dist(Xi, nd_cur)if dist < dist_best:dist_best = distnd_best = nd_curif nd_cur is not nd_root:nd_bro = nd_cur.brotherif nd_bro is not None:dist_hyper = self._get_hyper_plane_dist(Xi, nd_cur.father)if dist > dist_hyper:_nd_best = self._search(Xi, nd_bro)que.append((nd_bro, _nd_best))nd_cur = nd_cur.fatherelse:breakreturn nd_best3 效果评估
3.1 线性查找
用“笨”办法查找距离最近的元素。
def exhausted_search(X, Xi):dist_best = float('inf')row_best = Nonefor row in X:dist = get_euclidean_distance(Xi, row)if dist < dist_best:dist_best = distrow_best = rowreturn row_best3.2 main函数
主函数分为如下几个部分:
1. 随机生成数据集,即测试用例
2. 建立KD-Tree
3. 执行“笨”办法查找
4. 比较“笨”办法和KD-Tree的查找结果
def main():def main():print("Testing KD Tree...")test_times = 100run_time_1 = run_time_2 = 0for _ in range(test_times):low = 0high = 100n_rows = 1000n_cols = 2X = gen_data(low, high, n_rows, n_cols)y = gen_data(low, high, n_rows)Xi = gen_data(low, high, n_cols)
tree = KDTree()tree.build_tree(X, y)start = time()nd = tree.nearest_neighbour_search(Xi)run_time_1 += time() - startret1 = get_euclidean_distance(Xi, nd.split[0])start = time()row = exhausted_search(X, Xi)run_time_2 += time() - startret2 = get_euclidean_distance(Xi, row)assert ret1 == ret2, "target:%s\nrestult1:%s\nrestult2:%s\ntree:\n%s" \% (str(Xi), str(nd), str(row), str(tree))
print("%d tests passed!" % test_times)
print("KD Tree Search %.2f s" % run_time_1)
print("Exhausted search %.2f s" % run_time_2)
![]()
https://github.com/tushushu/imylu/tree/master/imylu/utils
![]()
KD Tree的原理及Python实现相关推荐
- k-d tree算法原理及实现
k-d tree即k-dimensional tree,常用来作空间划分及近邻搜索,是二叉空间划分树的一个特例.通常,对于维度为k,数据点数为N的数据集,k-d tree适用于N≫2k的情形. 1)k ...
- kd树 python实现_KD Tree的原理及Python实现
提到KD-Tree相信大家应该都不会觉得陌生(不陌生你点进来干嘛[捂脸]),大名鼎鼎的KNN算法就用到了KD-Tree.本文就KD-Tree的基本原理进行讲解,并手把手.肩并肩地带您实现这一算法. 完 ...
- K-D Tree 算法详解及Python实现
K-D Tree 算法 k−d treek−dtree\mathrm{k-d\ tree}即k−dimensional treek−dimensionaltree\mathrm{k-dimension ...
- KD Tree原理讲解
1.引子 在一张地图上,有600多个单位,每个单位之间都需要独立寻路,检测碰撞和寻找最近的敌方目标.当这一切需要在手机上流畅运行并尽可能快的在服务器进行模拟时,最简单的平方算法O(N^2)已经不能满足 ...
- k-d tree入门
暑期集训开始了 本篇博客将会简单讲一下k-d tree的原理以及实现 首先大家要先了解一下二叉搜索树 二叉搜索树是一个很简单常见的数据结构,他符合以下两个特征 1.一个节点若有左子树,则左子树上的点全 ...
- k-d tree 介绍
作为存取高维数据的一种数据结构,k-d tree 在静态查询和插入方面的效率还是很高的.本文在这里对 k-d tree 的内容作一些介绍,可能也会结合自己使用 k-d tree 的一些体验作一些点评. ...
- kd tree python 搜索
海量数据最近邻查找可以用kd tree 目前理解,kd tree需要的数据维度相同,否则会出问题 kd tree实现:https://github.com/stefankoegl/kdtree 下面是 ...
- PCL :K-d tree 2 结构理解
K-d tree 基础思路:(先看之前的KNN思想,更容易理解) 导语:kd 树是一种二叉树数据结构,可以用来进行高效的 kNN 计算.kd 树算法偏于复杂,本篇将先介绍以二叉树的形式来记录和索引空间 ...
- PCL:k-d tree 1 讲解
1.简介 kd-tree简称k维树,是一种空间划分的数据结构.常被用于高维空间中的搜索,比如范围搜索和最近邻搜索.kd-tree是二进制空间划分树的一种特殊情况.(在激光雷达SLAM中,一般使用的是三 ...
最新文章
- 字符串工具类、数组工具类、集合工具类、转型操作工具类、编码与解码操作工具类...
- BZOJ2298 [HAOI2011]problem a 【dp】
- python 字典过滤
- android 网络调试工具,安卓网络调试助手
- [html] 解释下你对GBK和UTF-8的理解?并说说页面上产生乱码的可能原因
- python-面向对向-实例方法的继承-多继承父类中的super与子类实例对象的关系
- 如何写好学术期刊文章?
- 关于VS2017提示I/O文件操作函数需要加上_s的解决办法
- 博客园的第一篇文章-----述学习编程的开始与经历
- 【BZOJ-1090】字符串折叠 区间DP + Hash
- 08.存储Cinder→5.场景学习→02.Create Volume→1.cinder-api处理过程
- 3种方法设置和取消Excel文件的打开密码
- Java 中status意思_struts的status属性
- TDengine 荣获 CSDN IT 技术影响力之星 “年度开源项目” 、 “年度IT领军人物”奖项
- crontab、cron、at、atq、batch、ps命令练习题
- java 手机 连接电脑,非智能手机怎么连接电脑
- python集合元素个数_python如何取set元素个数
- kvs(Kyoto Visualization System)的初次使用
- InteractiveDataDisplay.WPF 固定坐标轴
- Java使用geotools将Geometry(地图要素)导出为shp文件