ATS读小文件(内存命中)
一个资源根据其大小可能会存在多个存储对象中。如果足够小(连同doc结构的大小小于一个fragment的size),连同这个资源的meta信息一起存储在一个doc中。如果比较大,第一个存储对象保存资源的meta信息,后面跟着若干个fragment存着资源的content。这里讨论小文件读行为,并且内存命中,在资源第二次命中的时候才有可能是内存命中。整个流程在主状态机流程的入口函数是Cache::open_read,正流程如下:
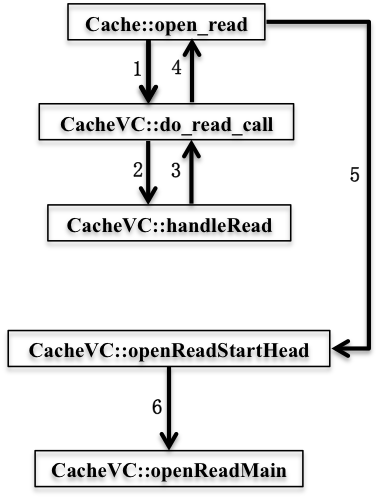
Cache::open_read: 首先需要计算的到vol,因为需要知道资源在哪个vol上才能确定是否存在,每个vol都是独立存在的。获取锁之后运行了dir_probe函数,确定了缓存查询的结果。获取了dir,对CacheVC对象的key和dir进行了初始化。生成一个CacheVC对象,之后的操作都是这个CacheVC对象是事儿了。设置回调函数为Cache::openReadStartHead,设置完回调函数会执行do_read_call,最终do_read_call返回了EVENT_RETURN,执行了事件回调函数,就是刚刚设置的Cache::openReadStartHead。
dir_probe: 通过md5值计算得到资源所在的segemnt和bucket,进而得到目标dir,如果dir是否“正确”,如果正确就认为命中了。
CacheVC::do_read_call: 初始化doc_pos为0。解析dir,获取fragment大概大小(dir_approx_size)。决定是否应该存在于ssd中(dir_inssd),如果已经是从ssd中读了,就肯定不写了。每个vol都会对应自己的ssd,每个vol都会维护一些历史数据用来判断热度相关的数据。最终执行CacheVC::handleRead,最终返回了EVENT_RETURN。
CacheVC::handleRead: 获取偏移量(dir_get_offset)。 在内存中查询(vol->ram_cache->get函数会根据records.config中的配置项proxy.config.cache.ram_cache.algorithm指向不同的函数)。假设内存查询函数为RamCacheLRU::get,详见下面解析。内存命中的话在这个函数里面会将内容放倒buf中,进而获取到了doc。
RamCacheLRU::get: 判断是否在内存中命中,如果命中了,在lru队列中删除并且在头部重新插入。
CacheVC::openReadStartHead: 每次读操作都会执行一次,获取这个资源相关的信息,根据buf是否为空判断是否命中。确定一个alternate,通过判断alternate的key是否就是doc的key来判断这个alternate是不是要找的那个。如果是的话判断是不是single fragment,如果满足len = heln + total_len + 72,认为是小文件。获取doc_pos,即为doc的大小与整个资源的metadata的大小的和。获取next key(对于小文件没必要,但是也执行了),执行begin_read,这个函数主要判断了是否需要evacuate,由于小文件都会存在一个fragment,而此时已经都到了内存中,所以不需要考虑evacuate问题。最后将回调函数设置为 CacheVC::openReadMain,并且执行缓存主状态机事件回调函数 HttpCacheSM::state_cache_open_read,传递的参数是 CACHE_EVENT_OPEN_READ。
转载于:https://blog.51cto.com/11490450/1861921
ATS读小文件(内存命中)相关推荐
- 滴水三期逆向基础系列(一)-读取文件到内存再读取回文件
跟着滴水三期学了很长时间了,本着,每一点都要吃透的精神,跟"读文件到内存(拉伸),再读回文件(压缩回来)"杠了一天.先看看按着老师的架构写的代码吧(老师的代码有很多问题(可能是我太 ...
- 海量小文件场景下训练加速优化之路
作者:星辰算力平台 1. 背景 随着大数据.人工智能技术的蓬勃发展,人类对于算力资源的需求也迎来大幅度的增长.在腾讯内部,星辰算力平台以降本增效为目标,整合了公司的GPU训练卡资源,为算法工程师们提供 ...
- HDFS小文件问题及解决方案
1. 概述 小文件是指文件size小于HDFS上block大小的文件.这样的文件会给hadoop的扩展性和性能带来严重问题.首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储 ...
- java切割文件_Java如何将大文件切割成小文件
运用Java编写代码将一个大文件切割成指定大小的小文件 思路: 对已知文件进行切割操作 –> 得到多个碎片文件 使用: 1. 1个字节输入流 –> 读取已知文件中的数据 2. 多个字节输出 ...
- 【JavaNIO的深入研究4】内存映射文件I/O,大文件读写操作,Java nio之MappedByteBuffer,高效文件/内存映射...
内存映射文件能让你创建和修改那些因为太大而无法放入内存的文件.有了内存映射文件,你就可以认为文件已经全部读进了内存,然后把它当成一个非常大的数组来访问.这种解决办法能大大简化修改文件的代码. file ...
- Hadoop之Hadoop企业优化(HDFS小文件优化)
Hadoop之Hadoop企业优化 目录 MapReduce 跑的慢的原因 MapReduce优化方法之数据输入 MapReduce优化方法之Map阶段 MapReduce优化方法之Reduce阶段 ...
- linux文件 内存映射 锁,linux – mmap:将映射文件立即加载到内存中吗?
不,是的,也许吧.这取决于. 调用mmap通常只意味着对应用程序而言,映射文件的内容将映射到其地址空间,就像文件已加载到那里一样.或者,好像该文件确实存在于内存中,就好像它们是同一个(包括更改被写回磁 ...
- 关于hadoop处理大量小文件情况的解决方法
小文件是指那些size比HDFS的block size(默认64m)小的多的文件.任何一个文件,目录和bolck,在HDFS中都会被表示为一个object存储在namenode的内存中,每一个obje ...
- Spark优化之小文件是否需要合并?
我们知道,大部分Spark计算都是在内存中完成的,所以Spark的瓶颈一般来自于集群(standalone, yarn, mesos, k8s)的资源紧张,CPU,网络带宽,内存.Spark的性能,想 ...
最新文章
- Git_学习_06_ 放弃本地修改
- 皮一皮:钢铁直女?鉴定了,钢的不能再钢!
- Python编程基础:第三十节 文件检测File Detection
- 漫谈MySQL索引与字段儿长度的关系
- vb.net2.0 Hmac-md5加密算法
- 【计算机视觉】运动目标检测算法文献阅读笔记
- 大型网站架构之系列(4)——分布式中的异步通信
- nginx/windows: nginx多虚拟主机配置
- CC_STACKPROTECTOR防内核堆栈溢出补丁分析【转】
- Java新手入门值得看的五本书!
- Python+FFmpeg提取哔哩哔哩安卓缓存
- java mov 转 mp4 视频格式
- Android 屏幕旋转流程分析
- 【BSC】使用Python玩转PancakeSwap(入门篇)
- Swing Copters摇摆直升机高分攻略,游戏攻略
- 【华为云计算产品系列】云上迁移工具RainBow实战详解
- android 微信刷步数,微信QQ自动手动刷步数支持98800步安卓应用
- UML图有哪些类型?
- 论文中文翻译——A deep tree-based model for software defect prediction
- IT干货汇总第二波!视频、录音、PPT应有尽有!全免费!