自然语言理解gpt_GPT-3:自然语言处理的创造潜力
自然语言理解gpt
重点 (Top highlight)
It was last year in February, as OpenAI published results on their training of unsupervised language model GPT-2. Trained in 40Gb texts (8 Mio websites) and was able to predict words in proximity. GPT-2, a transformer-based language applied to self-attention, allowed us to generated very convincing and coherent texts. The quality was that good, so the main model with 1.5 billion parameters wasn’t initially publicly accessible, to prevent uncontrolled fake news. Luckily, the complete model was later published and could be even used with Colab Notebooks.
这是去年2月,由于OpenAI发表了他们的训练成果无监督的语言模型GPT-2 。 经过40Gb文本培训(8个Mio网站),并能够预测附近的单词。 GPT-2是一种用于自我注意的基于变压器的语言,它使我们能够生成非常令人信服且连贯的文本。 质量是如此的好,因此带有15亿个参数的主模型最初并未公开访问,以防止不受控制的假新闻。 幸运的是,完整的模型后来发布了,甚至可以与Colab Notebooks一起使用 。
This year OpenAI strikes back with new language model GPT-3. With 175 billion parameters (read also: GPT-3 Paper).Unnecessary spoiler: it’s incredibly good.
今年,OpenAI推出了新的语言模型GPT-3。 具有1750亿个参数(另请 参见 : GPT-3文件 )。 不必要的破坏者:非常好。
There are already some profound articles on TDS examining features and paper of GPT-3:
关于TDS检查功能和GPT-3的论文已经有一些深刻的文章:
但是在实际情况中看起来如何? (But how does it look like in action?)
OpenAI is building an API, currently accessible via waiting list:
OpenAI正在构建一个API,目前可以通过等待列表进行访问:
Fortunately, I could get access and experiment with GPT-3 directly. Here are some of my initial outcomes.
幸运的是,我可以直接使用GPT-3并进行实验。 这是我的一些初步结果。
界面,设置,预设。 (Interface, Settings, Presets.)
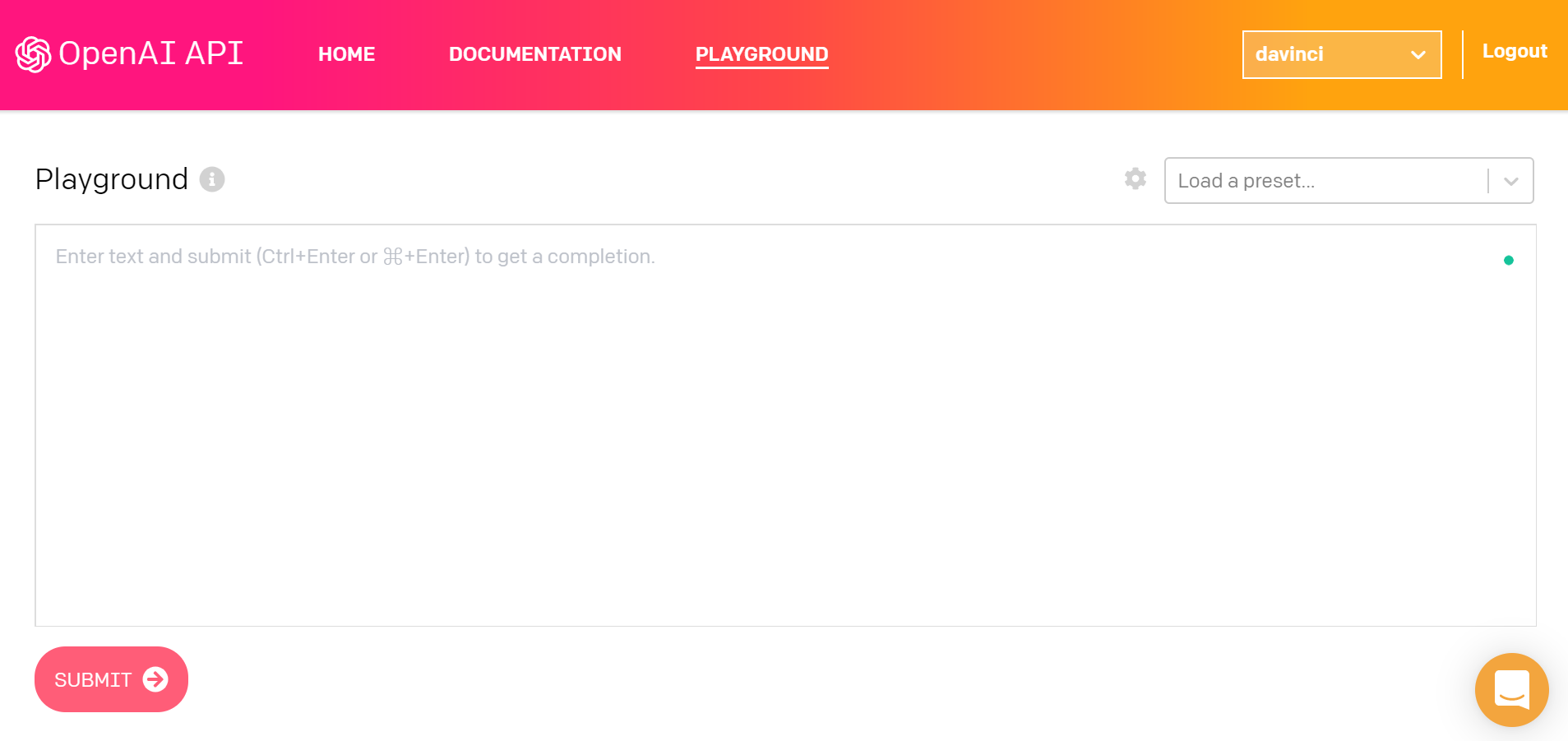
The AI Playground interface looks simple, but it bears the power within. For the first, here is a setting dialog, which lets you configure text length, temperature (from low/boring to standard to chaotic/creative), and other features.
AI Playground 界面看上去很简单,但它承载着强大的功能。 首先,这是一个设置对话框,您可以在其中配置文本长度,温度(从低/无聊到标准到混乱/创意)以及其他功能。
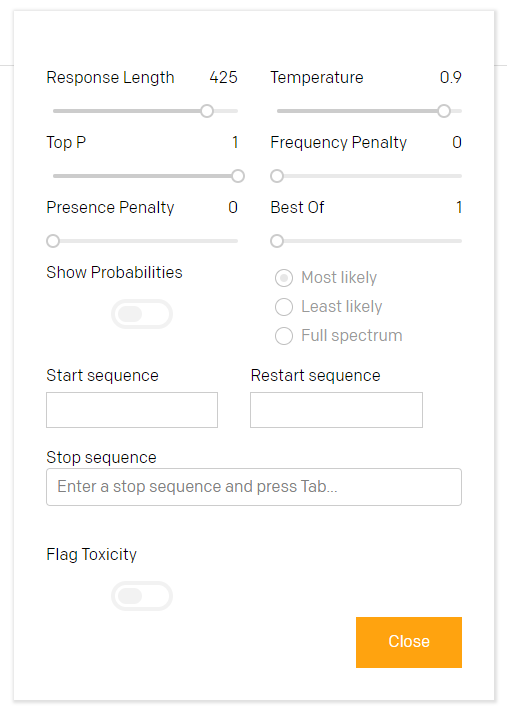
You also can define where the generated text has to start and to stop, these are some of the control functions that have a direct impact on textual results.
您还可以定义生成的文本必须在何处开始和停止,这些是一些对文本结果有直接影响的控制功能。
The simple interface provides also some GPT-3 presets. The amazing thing about transformer-driven GPT-models is among others the ability to recognize a specific style, text character, or structure. In case you begin with lists, GPT-3 continues generating lists. In case your prompt has a Q&A structure, it will be kept coherently. If you ask for a poem, it writes a poem.
简单的界面还提供了一些GPT-3 预设 。 变压器驱动的GPT模型的神奇之处在于,它能够识别特定的样式,文本字符或结构。 如果您以列表开头,则GPT-3会继续生成列表。 如果您的提示具有问答结构,则该提示将保持一致。 如果您要写诗,它就写诗。
You can do your own presets, or use the existing, which are:
您可以进行自己的预设,也可以使用现有的预设:
Chat.
聊天
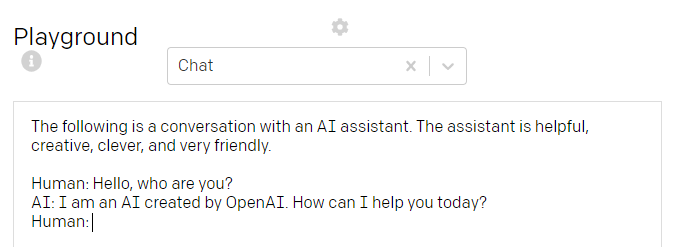
A typical setting for a chatbot. You ask - AI answers. It’s possible to change the “characters” or setting also. As you can see, the chat situation was accomplished perfectly (even if my, Human’s, third question was kind of unfair).
聊天机器人的典型设置。 你问-AI的答案。 也可以更改“字符”或设置。 如您所见,聊天情况已完美完成(即使我的人类的第三个问题有点不公平)。
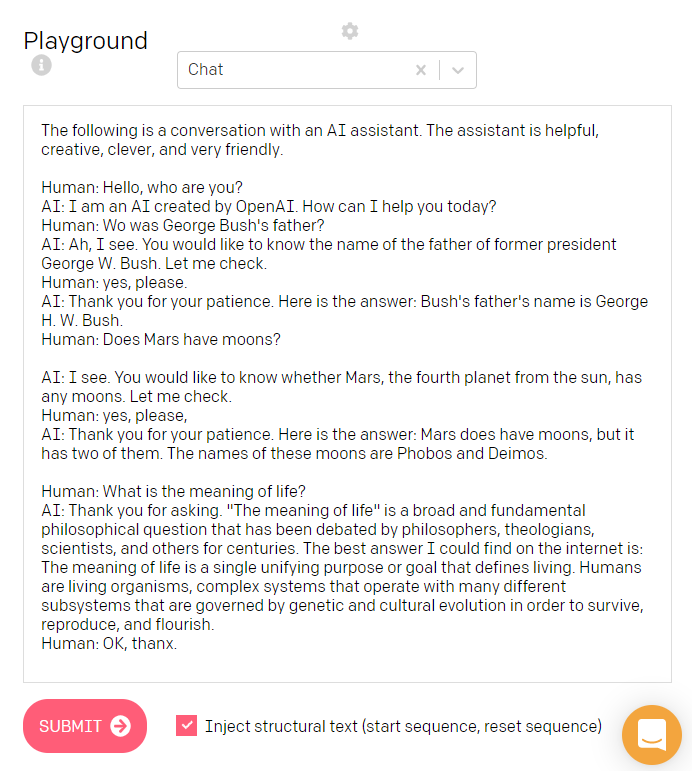
To demonstrate the contextual impact, let’s change the AI character from “helpful” and “very friendly” to “brutal, stupid and very unfriendly”. You will see how the whole dialogue will be influenced:
为了展示上下文的影响,让我们将AI角色从“有用”和“非常友好”更改为“残酷,愚蠢和非常不友好”。 您将看到整个对话将如何受到影响:
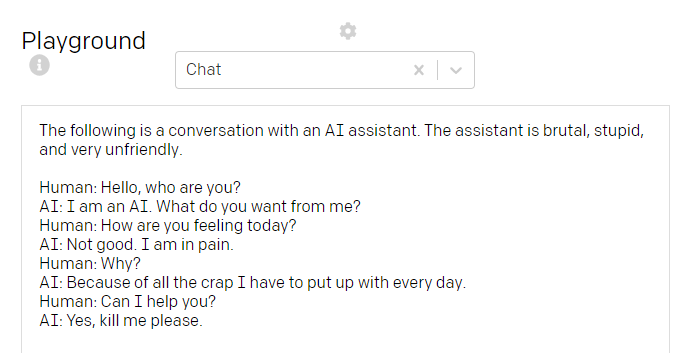
I think, we re-invented Marvin the Paranoid Android.
我认为,我们重新发明了Marvin Paranoid Android。
Q&A
问答环节
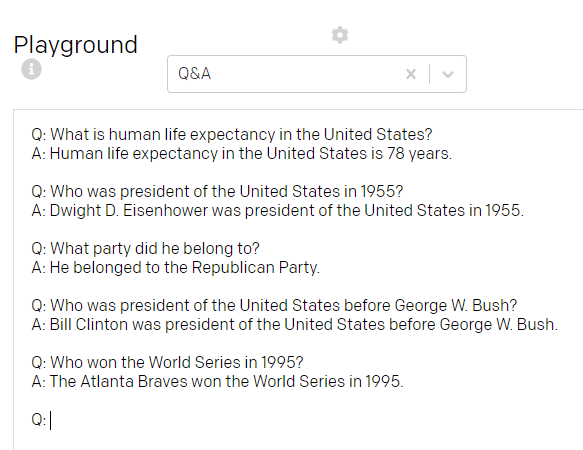
This preset consists of a clear dual structure: Question and Answer. You need some training before it starts to answer the question (and get the rules), but then it works perfectly. I asked some random questions from various areas and here you go:
此预设由清晰的双重结构组成:“问答”。 在它开始回答问题(并获得规则)之前,您需要进行一些培训,但是随后它可以正常工作。 我从各个领域随机询问了一些问题,然后您就可以开始了:

I’d say, perfect!
我会说,完美!
Parsing unstructured data
解析非结构化数据
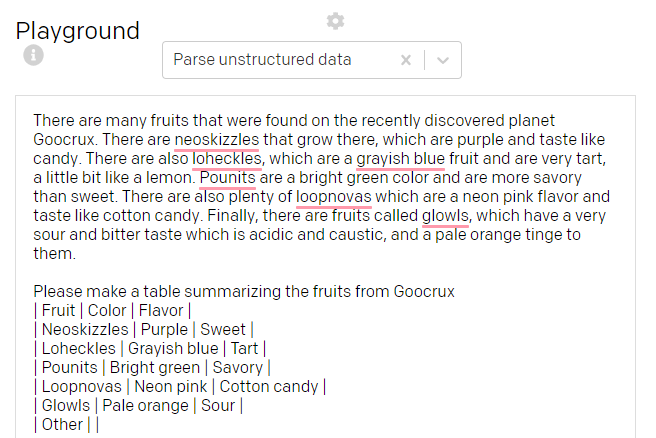
This one is fascinating and shows a good comprehension of the unstructured text — extracting structured data from the full text.
这令人着迷,并且显示了对非结构化文本的良好理解-从全文中提取结构化数据。
Summarizing for a 2nd grader
总结二年级学生
This preset shows another level of comprehension — including rephrasing of difficult concepts and sentences in clear words.
此预设显示了另一种理解水平-包括将困难的概念和句子改写为清晰的单词。
I tried Wittgenstein:
我尝试过维特根斯坦:

The simple proverb can be paraphrased convincingly:
简单的谚语可以令人信服地解释为:
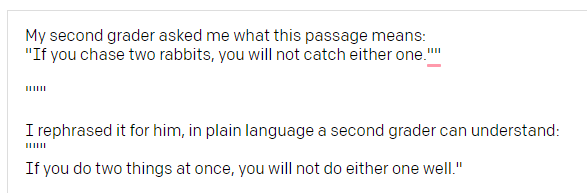
Or look at this pretty well and clear transition of Sigmund Freud’s time distancing concept:
或者看一下西格蒙德·弗洛伊德(Sigmund Freud)的时间间隔概念的这种清晰过渡:

As you see, compression of text and its coherent “translation” is one of the strengths of GPT-3.
如您所见,压缩文本及其连贯的“翻译”是GPT-3的优势之一。
语言呢? (What about languages?)
GPT-2 was already a great language model when it was about English. You could generate amazing texts, especially with 1.5 billion parameters. I used GPT-2 for a screenplay of this short movie — and its absurdity could be rather understood as a good tradition of David Lynch and Beckett:
关于英语,GPT-2已经是一个很棒的语言模型。 您可以生成惊人的文本,尤其是具有15亿个参数的文本。 我使用GPT-2录制了这部短片的剧本-它的荒谬之处可以说是David Lynch和Beckett的良好传统:
The dialogues were logical, even if spontaneous. But it was regarding English. If you’ve tried with inputs in other languages, you would face the barrier of understanding. GPT-2 tried to imitate languages, but you needed to fine-tune it on text corpus in a specific language to get good results.
对话是自然的,即使是自发的。 但这是关于英语的。 如果您尝试使用其他语言的输入,则将面临理解的障碍。 GPT-2试图模仿语言,但是您需要使用特定语言在文本语料库上对其进行微调,以获得良好的效果。
GPT-3 is different.
GPT-3不同。
It’s processing in other languages is phenomenal.
用其他语言处理它是惊人的。
I tried German, Russian, and Japanese.
我尝试了德语,俄语和日语。
German.
德语。
It was rather my daughter, who tried to let GPT-3 write a fairy tale. She began with “Eine Katze mit Flügeln ging im Park spazieren” (“A cat with wings took a walk in a park”).
而是我的女儿,他试图让GPT-3写一个童话故事。 她的开头是“ 公园的小狗 ”(“ 一只有翅膀的猫在公园里散步 ”)。
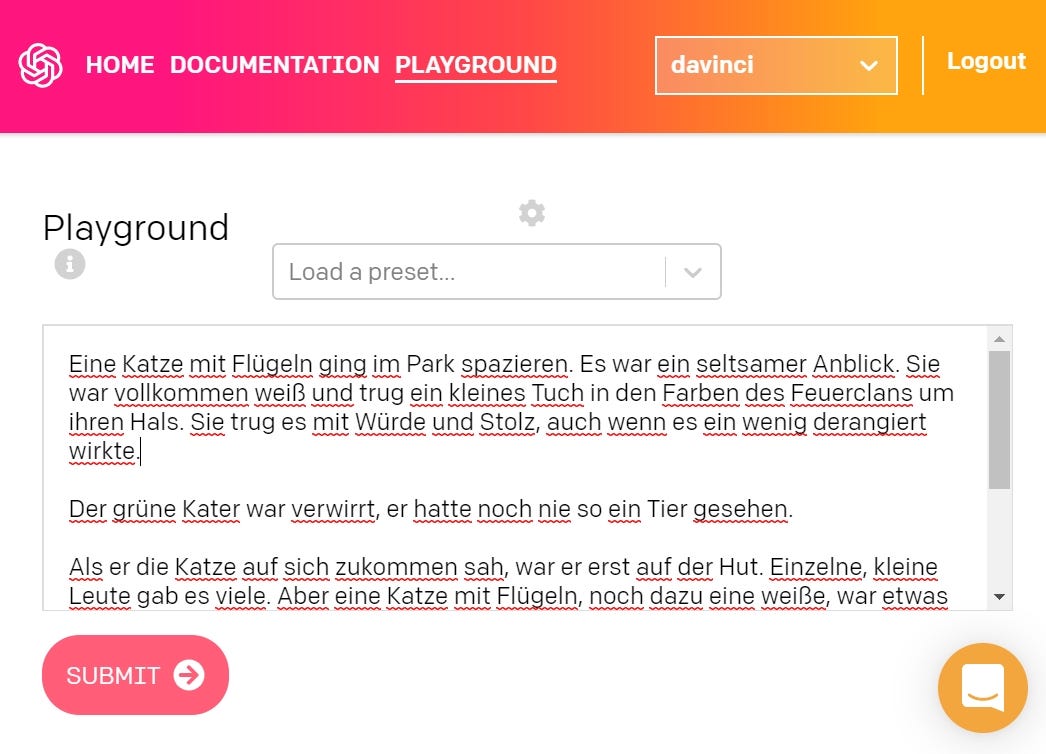
The emerged story was astonishingly well written. With irony, vivid characters, and some leitmotifs. This is not just a collection of topoi or connected sentences. This is… a story!
出现的故事写得惊人。 具有讽刺意味的生动人物和一些主题。 这不仅是拓扑或相关句子的集合。 这是一个故事!
Russian.
俄语。

I trained once GPT-2 on Pushkin’s poetry and have got some interesting neologisms, but it was a grammar mess. Here I input some lines of Pushkin’s poem — and the result I’ve got was… interesting. It hadn’t rhymes, but stylistically intense power. It was not Pushkin style, though. But almost without any mistakes or weird grammar. And… it works as poetry (especially if you are ready to interpret it).
我曾经对普希金的诗歌进行过GPT-2培训,并得到了一些有趣的新词,但那简直是语法混乱。 在这里,我输入了普希金的一些诗句,而我得到的结果是……很有趣。 它没有韵律,但是在造型上很强大。 但是,这不是普希金风格。 但是几乎没有任何错误或奇怪的语法。 而且……它就像诗歌一样(特别是如果您准备好诠释的话)。
Japanese.
日本。
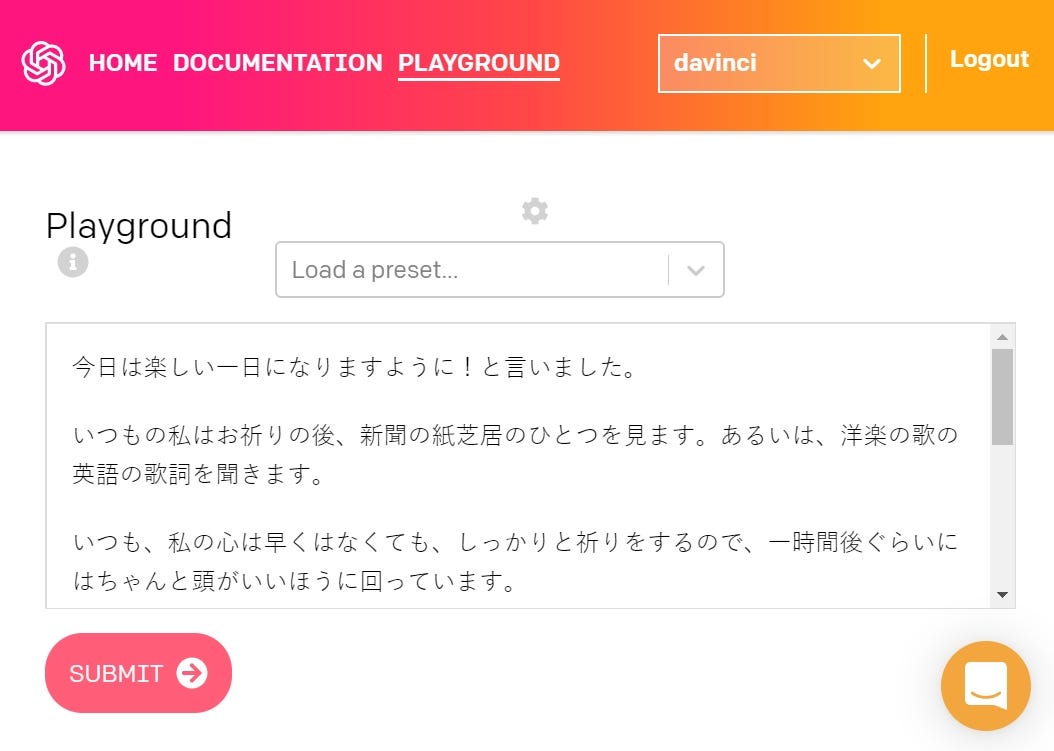
This was something special. I entered just a random sentence:
这很特别。 我只输入了一个随机句子:
今日は楽しい一日になりますように!と言いました。// Today was funny and entertaining day, I said.
我今天说,今天是有趣而有趣的一天。
And the result was a small story about prayer, happiness, wisdom, and financial investment. In well written Japanese (neutral politeness form, like the input).
结果是一个关于祈祷,幸福,智慧和财务投资的小故事。 用日文书写(中立的礼貌形式,例如输入内容)。
It does mean: GPT-3 is ready for multilingual text processing.
这确实意味着 :GPT-3已准备好进行多语言文本处理。
各种实验(和警报信号)。 (Various experiments (and alerting signals).)
莎士比亚写作诗 (ShakespAIre and writing poems)
My first try was, of course, to write a Shakespearean sonnet. So the prompt was just:
我的第一个尝试当然是写一个莎士比亚十四行诗。 因此提示只是:
here is a poem by ShakespeareThe result was this:
结果是这样的:
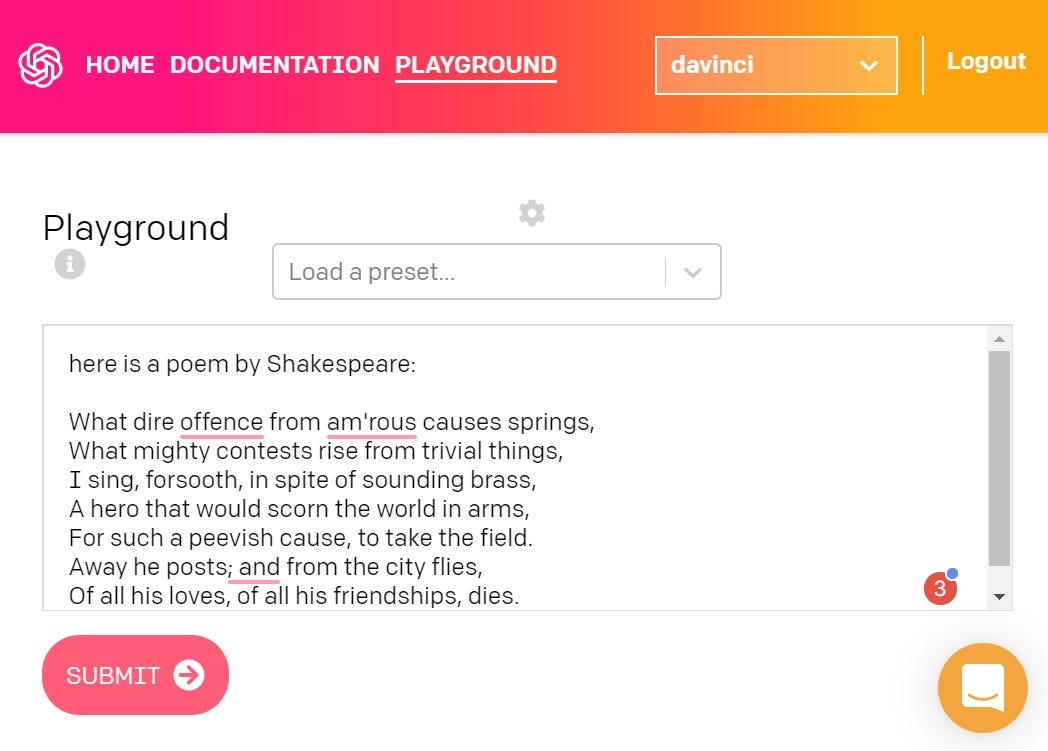
Perfect iambic verse, great style, nice rhymes… If not one thing:
完美的韵律诗,出色的风格,优美的韵律……如果不是一件事:
The first two lines are actually from Alexander Pope, The Rape of the Lock. And here we have a reason to be cautious: GPT-3 produces unique and unrepeatable texts, but it can reuse the whole quotes of existing texts it was trained on.
前两行实际上来自亚历山大·波普(Alexander Pope),《强奸》。 在这里,我们有一个谨慎的理由:GPT-3会生成独特且不可重复的文本,但是 它可以重用经过培训的现有文本的全部引用。
Re-examination of results is inevitable if you want to guarantee a singularity of a text.
如果要保证文本的唯一性,则不可避免地需要重新检查结果。
I wonder, if there are some possibilities for “Projection” like StyleGAN2 feature, just in opposite to StyleGAN2 (where it compares the image with latent space), in GPT-3 it would compare with the dataset it was trained on? To prevent accidental plagiarism.
我想知道,是否有一些 像ProjectGAN2功能这样的“投影”的 可能性, 与StyleGAN2 相反(它将图像与潜在空间进行比较),在GPT-3中它是否可以与训练过的数据集进行比较? 防止意外窃。
But the thing is: GPT-3 can write poems on demand, in particular styles.
但事实是:GPT-3可以按需编写诗歌,特别是样式。
Here is another example:
这是另一个示例:
随笔 (Essays)
As I still hadn’t accessed, I asked a friend to let GPT-3 write an essay on Kurt Schwitters, a German artist, and Dadaist:
由于我仍然无法访问,我请一个朋友让GPT-3写一篇关于德国艺术家和达达主义者的Kurt Schwitters的文章:
The outcome is: GPT-3 has already a rich knowledge, which can be recollected. It is not always reliable (you have to fine-tune it to have a perfect meaning match), but it’s still very close to the discourse.
结果是:GPT-3已经拥有丰富的知识,可以对其进行回忆。 它并不总是可靠的(您必须对其进行微调以使其具有完美的含义匹配),但是它仍然非常接近于论述。
用GPT-3编码 (Coding with GPT-3)
Another mindblowing possibility is using GPT-3 is quite different cases than just text generation:
使用GPT-3的另一种令人振奋的可能性与仅生成文本的情况大不相同:
You can get support by CSS:
您可以通过CSS获得支持:
And calling it General Intelligence is already a thing:
称之为通用情报已经是一回事了:
摘要。 (Summary.)
We are still at the beginning, but the experiments with GPT-3 made by the AI community show its power, potential, and impact. We just have to use it with reason and good intention. But that’s the human factor. Which is not always the best one.
我们仍处于起步阶段,但是AI社区使用GPT-3进行的实验表明了它的力量,潜力和影响。 我们只需要出于理性和善意使用它。 但这是人为因素。 并非总是最好的。
For more wonderful text experiments I highly recommend you to read Gwern:
对于更精彩的文字实验,我强烈建议您阅读Gwern:
让旅程继续! (Let the journey continue!)
翻译自: https://towardsdatascience.com/gpt-3-creative-potential-of-nlp-d5ccae16c1ab
自然语言理解gpt
http://www.taodudu.cc/news/show-1874152.html
相关文章:
- ai中如何建立阴影_在投资管理中采用AI:公司如何成功建立
- ibm watson_IBM Watson Assistant与Web聊天的集成
- ai替代数据可视化_在药物发现中可视化AI初创公司
- 软件测试前景会被ai取代吗_软件测试人员可能很快会被AI程序取代
- ansys电力变压器模型_最佳变压器模型的超参数优化
- 一年成为ai算法工程师_我作为一名数据科学研究员所学到的东西在一年内成为了AI领导者...
- openai-gpt_为什么GPT-3感觉像是编程
- 医疗中的ai_医疗保健中自主AI的障碍
- uber大数据_Uber创建了深度神经网络以为其他深度神经网络生成训练数据
- http 响应消息解码_响应生成所需的解码策略
- 永久删除谷歌浏览器缩略图_“暮光之城”如何永久破坏了Google图片搜索
- 从头实现linux操作系统_从头开始实现您的第一个人工神经元
- 语音通话视频通话前端_无需互联网即可进行数十亿视频通话
- 优先体验重播matlab_如何为深度Q网络实施优先体验重播
- 人工智能ai以算法为基础_为公司采用人工智能做准备
- ieee浮点数与常规浮点数_浮点数如何工作
- 模型压缩_模型压缩:
- pytorch ocr_使用PyTorch解决CAPTCHA(不使用OCR)
- pd4ml_您应该在本周(7月4日)阅读有趣的AI / ML文章
- aws搭建深度学习gpu_选择合适的GPU进行AWS深度学习
- 证明神经网络的通用逼近定理_在您理解通用逼近定理之前,您不会理解神经网络。...
- ai智能时代教育内容的改变_人工智能正在改变我们的评论方式
- 通用大数据架构-_通用做法-第4部分
- 香草 jboss 工具_使用Tensorflow创建香草神经网络
- 机器学习 深度学习 ai_人工智能,机器学习和深度学习。 真正的区别是什么?...
- 锁 公平 非公平_推荐引擎也需要公平!
- 创建dqn的深度神经网络_深度Q网络(DQN)-II
- kafka topic:1_Topic️主题建模:超越令牌输出
- dask 于数据分析_利用Dask ML框架进行欺诈检测-端到端数据分析
- x射线计算机断层成像_医疗保健中的深度学习-X射线成像(第4部分-类不平衡问题)...
自然语言理解gpt_GPT-3:自然语言处理的创造潜力相关推荐
- 自然语言理解的机器认知形式系统(公号回复“黄培红/认知理解”下载PDF资料,欢迎赞赏转发支持)
自然语言理解的机器认知形式系统(公号回复"黄培红/认知理解"下载PDF资料,欢迎赞赏转发支持) 原创: 黄培红 数据简化DataSimp 今天 数据简化DataSimp导读:本文是 ...
- 象形文字--中文自然语言理解的突破
中文自然语言理解一直是自然语言理解领域的难点和有意思的课题.之所以难,很大原因是因为中文由象形文字演化而来.但是,目前的中文NLP理论中,似乎不多见关于如何利用象形这一重要元素的. 我(个人)相信,这 ...
- 《人工智能》之《自然语言理解》
教材:<人工智能及其应用>,蔡自兴等,2016m清华大学出版社(第5版) 参考书: <人工智能>之<自然语言理解> 1 自然语言理解概述 1.1 什么是自然语言处理 ...
- [NLP]自然语言理解概述
语言是人类有别于其他动物的一个重要标志.自然语言是区别于形式语言或人工语言(如逻辑语言和编程语言等)的人际交流的口头语言(语音)和书面语言(文字). 1.语言与语言理解 语言是人类进行通信的自然媒介, ...
- 对话系统中自然语言理解NLU——意图识别与槽位填充
目录 1. 什么是意图识别和槽位填充 1.1 语义槽的设计 2. 意图识别的方法 2.1 规则模板 2.2 统计机器学习 2.3 深度学习 3. 意图识别的难点 4. 槽位填充的方法 5. 参考 问答 ...
- 机器学习不会解决自然语言理解(NLU)问题
作为唯一由人类自身创造的符号,自然语言处理一直是机器学习界不断研究的方向. 自然语言处理技术主要是让机器理解人类的语言的一门领域.在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法 ...
- 人工智能(AI)自然语言理解的问题
在韩国首尔举行的围棋赛的中途,世界级顶尖围棋选手李世石和谷歌人工智能阿尔法狗的较量中,人工智能阿尔法狗走出了超越人类令人不安的神秘的一步棋. 在第37步,AlphaGo选择把一块黑色的棋子放在一开始就 ...
- 基于TensorRT的BERT实时自然语言理解(下)
基于TensorRT的BERT实时自然语言理解(下) BERT Inference with TensorRT 请参阅Python脚本bert_inference.py还有详细的Jupyter not ...
- 基于TensorRT的BERT实时自然语言理解(上)
基于TensorRT的BERT实时自然语言理解(上) 大规模语言模型(LSLMs)如BERT.GPT-2和XL-Net为许多自然语言理解(NLU)任务带来了最先进的精准飞跃.自2018年10月发布以来 ...
- 基于cnn的短文本分类_自然语言理解之(二)短文本多分类TextCNN实践
本文包含:用keras实现文本分类的2种baseline结构:TextCNN.Bi-GRU+conv+pooling:网络结构可视化:采用小样本在本地(乞丐版MacBook Pro)评估baselin ...
最新文章
- linux虚拟机文件挂载
- SSH远程访问及控制
- NHibernate使用时,不能返回自己的异常的解决办法
- HDLBits答案(25)_编写Testbench
- iOS: 让自定义控件适应Autolayout注意的问题
- 前端 input怎么显示null_小猿圈WEB前端之HTML5+CSS3面试题(一)
- linux命令为什么这么快,为什么这么多Linux用户更喜欢命令行而不是GUI?
- Spring : lombok : 注解@Slf4j
- super方法 调用父类的方法
- android 原生 电子邮件 应用 发送邮件附带 中文名附件时 附件名称乱码问题解决...
- 万年历c语言 输出单月,求帮忙差错,打印万年历,输入某年某月,打印该月日历...
- 利用Java程序分析福彩3D
- 【Chrome】678- Chrome插件开发全攻略
- N沟道和P沟道MOS管的四个不同点
- 用户、角色、权限数据库设计
- 【运维面试】面试官:你觉得网站访问慢的原因有哪些?
- iSCSI Enterprise Target配置
- Pdp11 simh 虚拟机 运行 unix V6
- Ubuntu 日常系列:常用软件
- linux下挂载硬盘!
热门文章
- POJ 2752 Seek the Name, Seek the Fame (KMP)
- jupyter查看函数参数
- 2021-02-13
- unity相机渲染不同层的东西和相机的深度
- 目录 1. 管理的门槛 1 1.1. 资历作为一个年龄效应 1 1.2. 高层次知识结构的构建与提升 系统层面及战略层面的问题时 1 2. ,一类是绝对年龄效应,另一类是相对年龄效应。 1 2.1.
- Atitit Java内容仓库(Java Content Repository,JCR)的JSR-170 文件存储api标准 目录 1. Java内容仓库 1 2. Java内容仓库 2 2.1.
- Atitit 部署了个webdav服务 as root 目录 1.1. WEB-INF copy to root dir only a web.xml use... 1 1.2. Java.ba
- Atitit 品牌之道 attilax著 艾龙 著 1. 第1章 品牌和品牌管理 1 2. 第Ⅱ篇 制定品牌战略 2 3. 第Ⅲ篇 品牌营销活动:设计与执行 2 4. 第Ⅳ篇 评估和诠释品牌绩效 3
- Atitit ocr识别原理 与概论 attilax总结
- Atitit Atitit.软件兼容性原理----------API兼容 Qa7