python : 超参数优化工具笔记 Tune with PyTorch Quick Start+基础概念
超参数优化工具
https://docs.ray.io/en/master/tune/index.html
注:为了可读性,将代码放到了参考与更多部分(并附上代码来源链接与测试结果)
install
pip install ray[tune] -i https://pypi.tuna.tsinghua.edu.cn/simple # pip install ray 安装总是time out
# C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\ray\_private\compat.py", line 14, in patch_redis_empty_recv
# import redis ModuleNotFoundError: No module named 'redis' redis 是一个 Key-Value 数据库
pip install redis -i https://pypi.tuna.tsinghua.edu.cn/simple
Quick Start Example
二次函数(代码见参考与更多)
minf(x)=a2+b度量标准(f)和模式(min)min \ f(x)=a^2+b\\ 度量标准(f)和模式(min) min f(x)=a2+b度量标准(f)和模式(min)
程序为a和b定义一个搜索空间,并让Ray Tune在该空间中搜索最优值。
手写数据集(代码见参考与更多)
和上一个例子类似,不过搜索的数据是从分布里选取的。(更进一步的还有早停和贝叶斯搜索方法与加载搜索结果的方法)
关键概念
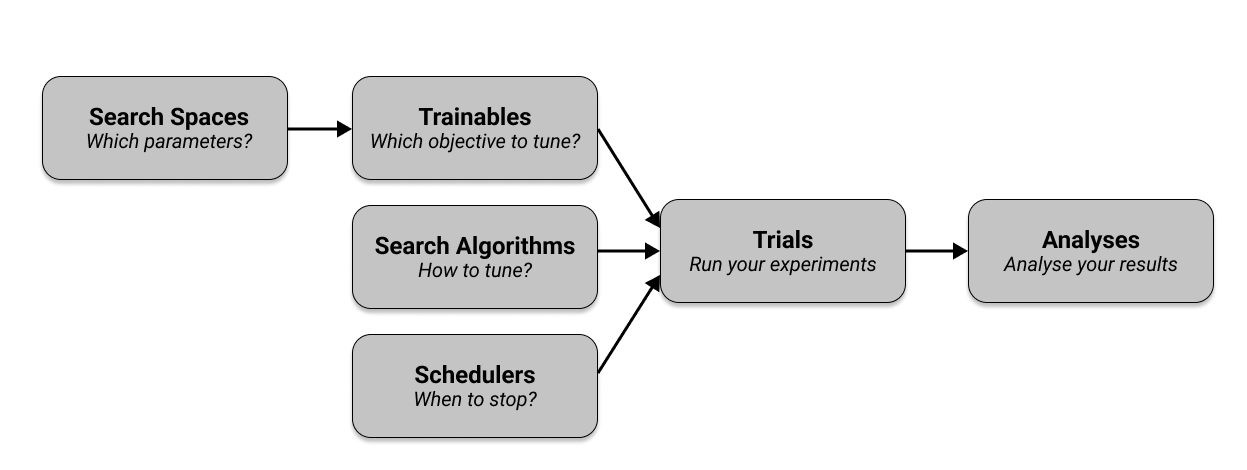
| 项目 | 解释 | 更多 |
|---|---|---|
| SerchSpace | 搜索空间 | |
| Trainable | 类似目标函数 | # Pass in a Trainable class or function, along with a search space “config”. tune.run(trainable, config={“a”: 2, “b”: 4}) |
| Search Algorithms | 搜索函数 | |
| Scjesulers | 训练策略 | tune.run(trainable, config, num_samples, scheduler) |
| Analyses | 结果分析 |
参考与更多
# 安装ray https://blog.csdn.net/weixin_45211921/article/details/117452963
pip3 install pytest-runner
pip3 install ray
pip install ray[default]# windows 下需要多的步骤
Quick Start Example
# https://docs.ray.io/en/master/tune/index.html
from ray import tune# 1. Define an objective function.
def objective(config):score = config["a"] ** 2 + config["b"]return {"score": score}# 2. Define a search space.
search_space = {"a": tune.grid_search([0.001, 0.01, 0.1, 1.0]),"b": tune.choice([1, 2, 3]),
}# 3. Start a Tune run and print the best result.
analysis = tune.run(objective, config=search_space) # 运行次数 num_samples :tune.run(trainable, config={"a": 2, "b": 4}, num_samples=10)
print(analysis.get_best_config(metric="score", mode="min")) # 度量标准和模式
结果分析
# https://docs.ray.io/en/latest/tune/key-concepts.html
analysis = tune.run(trainable,config=config,metric="score",mode="min",search_alg=BayesOptSearch(random_search_steps=4),stop={"training_iteration": 20},)
# 获取最佳结果
best_trial = analysis.best_trial # Get best trial
best_config = analysis.best_config # Get best trial's hyperparameters
best_logdir = analysis.best_logdir # Get best trial's logdir
best_checkpoint = analysis.best_checkpoint # Get best trial's best checkpoint
best_result = analysis.best_result # Get best trial's last results
best_result_df = analysis.best_result_df # Get best result as pandas dataframe# 或者直接获取所有的结果用于分析
# Get a dataframe with the last results for each trial
df_results = analysis.results_df
# Get a dataframe of results for a specific score or mode
df = analysis.dataframe(metric="score", mode="max")
运行结果
== Status == 略去状态信息
# tune.run 将执行所有 trials (除非出错).
+-----------------------+----------+----------------+-------+-----+
| Trial name | status | loc | a | b |
|-----------------------+----------+----------------+-------+-----|
| objective_47380_00000 | RUNNING | 127.0.0.1:5320 | 0.001 | 3 |
| objective_47380_00001 | PENDING | | 0.01 | 3 |
| objective_47380_00002 | PENDING | | 0.1 | 3 |
| objective_47380_00003 | PENDING | | 1 | 1 |
+-----------------------+----------+----------------+-------+-----++-----------------------+------------+----------------+-------+-----+--------+------------------+---------+
| Trial name | status | loc | a | b | iter | total time (s) | score |
|-----------------------+------------+----------------+-------+-----+--------+------------------+---------|
| objective_47380_00001 | RUNNING | 127.0.0.1:8292 | 0.01 | 3 | 1 | 0 | 3.0001 |
| objective_47380_00002 | RUNNING | 127.0.0.1:8316 | 0.1 | 3 | | | |
| objective_47380_00003 | PENDING | | 1 | 1 | | | |
| objective_47380_00000 | TERMINATED | 127.0.0.1:5320 | 0.001 | 3 | 1 | 0.000999928 | 3 |
+-----------------------+------------+----------------+-------+-----+--------+------------------+---------++-----------------------+------------+----------------+-------+-----+--------+------------------+---------+
| Trial name | status | loc | a | b | iter | total time (s) | score |
|-----------------------+------------+----------------+-------+-----+--------+------------------+---------|
| objective_47380_00000 | TERMINATED | 127.0.0.1:5320 | 0.001 | 3 | 1 | 0.000999928 | 3 |
| objective_47380_00001 | TERMINATED | 127.0.0.1:8292 | 0.01 | 3 | 1 | 0 | 3.0001 |
| objective_47380_00002 | TERMINATED | 127.0.0.1:8316 | 0.1 | 3 | 1 | 0 | 3.01 |
| objective_47380_00003 | TERMINATED | 127.0.0.1:8756 | 1 | 1 | 1 | 0 | 2 |
+-----------------------+------------+----------------+-------+-----+--------+------------------+---------+
12.21 seconds (11.50 seconds for the tuning loop)# 环境 虚拟机 win7 8GB 内存 无gpu
{'a': 1.0, 'b': 1}Process finished with exit code 0手写数据集
# https://docs.ray.io/en/latest/tune/getting-started.html#tune-tutorialimport numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as Ffrom ray import tune
from ray.tune.schedulers import ASHASchedulerclass ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()# In this example, we don't change the model architecture# due to simplicity.self.conv1 = nn.Conv2d(1, 3, kernel_size=3)self.fc = nn.Linear(192, 10)def forward(self, x):x = F.relu(F.max_pool2d(self.conv1(x), 3))x = x.view(-1, 192)x = self.fc(x)return F.log_softmax(x, dim=1)# Change these values if you want the training to run quicker or slower.
EPOCH_SIZE = 1 # 512
TEST_SIZE = 1 # 256def train(model, optimizer, train_loader):device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.train()for batch_idx, (data, target) in enumerate(train_loader):# We set this just for the example to run quickly.if batch_idx * len(data) > EPOCH_SIZE:returndata, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()def test(model, data_loader):device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.eval()correct = 0total = 0with torch.no_grad():for batch_idx, (data, target) in enumerate(data_loader):# We set this just for the example to run quickly.if batch_idx * len(data) > TEST_SIZE:breakdata, target = data.to(device), target.to(device)outputs = model(data)_, predicted = torch.max(outputs.data, 1)total += target.size(0)correct += (predicted == target).sum().item()return correct / totaldef train_mnist(config):# Data Setupmnist_transforms = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307, ), (0.3081, ))])train_loader = DataLoader(datasets.MNIST("~/data", train=True, download=True, transform=mnist_transforms),batch_size=64,shuffle=True)test_loader = DataLoader(datasets.MNIST("~/data", train=False, transform=mnist_transforms),batch_size=64,shuffle=True)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = ConvNet()model.to(device)optimizer = optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"])for i in range(10):train(model, optimizer, train_loader)acc = test(model, test_loader)# Send the current training result back to Tunetune.report(mean_accuracy=acc)if i % 5 == 0:# This saves the model to the trial directorytorch.save(model.state_dict(), "./model.pth")search_space = {"lr": tune.sample_from(lambda spec: 10 ** (-10 * np.random.rand())),"momentum": tune.uniform(0.1, 0.9),
}# Uncomment this to enable distributed execution
# `ray.init(address="auto")`# Download the dataset first 等待从http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz下载数据
datasets.MNIST("~/data", train=True, download=True)analysis = tune.run(train_mnist, config=search_space) #TODOdfs = analysis.trial_dataframes
[d.mean_accuracy.plot() for d in dfs.values()]
贝叶斯搜索
# 首先执行 pip install bayesian-optimization
from ray.tune.suggest.bayesopt import BayesOptSearch# Define the search space
search_space = {"a": tune.uniform(0, 1), "b": tune.uniform(0, 20)}algo = BayesOptSearch(random_search_steps=4)tune.run(trainable,config=search_space,metric="score",mode="min",search_alg=algo,stop={"training_iteration": 20},
)
更多搜索算法或者实现自己的搜索算法
|
SearchAlgorithm |
Summary |
Website |
Code Example |
|---|---|---|---|
|
Random search/grid search |
Random search/grid search |
tune_basic_example |
|
|
AxSearch |
Bayesian/Bandit Optimization |
[Ax] |
AX Example |
|
BlendSearch |
Blended Search |
[Bs] |
Blendsearch Example |
|
CFO |
Cost-Frugal hyperparameter Optimization |
[Cfo] |
CFO Example |
|
DragonflySearch |
Scalable Bayesian Optimization |
[Dragonfly] |
Dragonfly Example |
|
SkoptSearch |
Bayesian Optimization |
[Scikit-Optimize] |
SkOpt Example |
|
HyperOptSearch |
Tree-Parzen Estimators |
[HyperOpt] |
Running Tune experiments with HyperOpt |
|
BayesOptSearch |
Bayesian Optimization |
[BayesianOptimization] |
BayesOpt Example |
|
TuneBOHB |
Bayesian Opt/HyperBand |
[BOHB] |
BOHB Example |
|
NevergradSearch |
Gradient-free Optimization |
[Nevergrad] |
Nevergrad Example |
|
OptunaSearch |
Optuna search algorithms |
[Optuna] |
Optuna Example |
|
ZOOptSearch |
Zeroth-order Optimization |
[ZOOpt] |
ZOOpt Example |
|
SigOptSearch> |
Closed source |
[SigOpt] |
SigOpt Example |
|
HEBOSearch |
Heteroscedastic Evolutionary Bayesian Optimization |
[HEBO] |
HEBO Example |
日程表与早停 Schedulers
如果未指定调度程序,Tune 将默认使用先进先出 (FIFO) 调度程序,该调度程序仅按您的搜索算法选择的试验按照它们被挑选的顺序通过,并且不会早停。
from ray.tune.schedulers import HyperBandScheduler# Create HyperBand scheduler and minimize the score
hyperband = HyperBandScheduler(metric="score", mode="max")config = {"a": tune.uniform(0, 1), "b": tune.uniform(0, 1)}tune.run(trainable, config=config, num_samples=20, scheduler=hyperband)
运行结果
(pid=7320)
== Status ==
Current time: 2022-**-** **:**:** (running for 00:04:28.04)
Memory usage on this node: 7.0/* GiB
Using FIFO scheduling algorithm.
Resources requested: 1.0/2 CPUs, 0/0 GPUs, 0.0/0.82 GiB heap, 0.0/0.41 GiB objects
Result logdir: C:\Users\Administrator\ray_results\train_mnist_2022-05-25_10-04-34
Number of trials: 1/1 (1 RUNNING)
+-------------------------+----------+----------------+-------------+------------+
| Trial name | status | loc | lr | momentum |
|-------------------------+----------+----------------+-------------+------------|
| train_mnist_05ccd_00000 | RUNNING | 127.0.0.1:7780 | 5.27504e-09 | 0.653214 |
+-------------------------+----------+----------------+-------------+------------+Result for train_mnist_05ccd_00000:date: 2022-**-**_**-**-** # 时间戳done: falseiterations_since_restore: 1mean_accuracy: 0.03125node_ip: 127.0.0.1training_iteration: 1trial_id: 05ccd_00000Result for train_mnist_05ccd_00000:date: 2022-**-**_**-**-**done: trueexperiment_id: 20149107d1784b8e83e2f3139e19e512experiment_tag: 0_lr=5.275e-09,momentum=0.65321hostname: YYDN-20211110NLiterations_since_restore: 10mean_accuracy: 0.109375node_ip: 127.0.0.1warmup_time: 0.006000518798828125== Status ==
Current time: 2022-05-25 10:09:05 (running for 00:04:29.67)
Memory usage on this node: 7.1/8.0 GiB
Using FIFO scheduling algorithm.
Resources requested: 0/2 CPUs, 0/0 GPUs, 0.0/0.82 GiB heap, 0.0/0.41 GiB objects
Number of trials: 1/1 (1 TERMINATED)
+-------------------------+------------+----------------+-------------+------------+----------+--------+------------------+
| Trial name | status | loc | lr | momentum | acc | iter | total time (s) |
|-------------------------+------------+----------------+-------------+------------+----------+--------+------------------|
| train_mnist_05ccd_00000 | TERMINATED | 127.0.0.1:7780 | 5.27504e-09 | 0.653214 | 0.109375 | 10 | 1.00106 |
+-------------------------+------------+----------------+-------------+------------+----------+--------+------------------+2022-05-25 10:09:05,136 INFO tune.py:701 -- Total run time: 271.33 seconds (269.49 seconds for the tuning loop).
Process finished with exit code -1
关键概念
搜索空间
# https://docs.ray.io/en/latest/tune/api_docs/search_space.html#tune-sample-docs
config = {# Sample a float uniformly between -5.0 and -1.0"uniform": tune.uniform(-5, -1),# Sample a float uniformly between 3.2 and 5.4,# rounding to increments of 0.2"quniform": tune.quniform(3.2, 5.4, 0.2),# Sample a float uniformly between 0.0001 and 0.01, while# sampling in log space"loguniform": tune.loguniform(1e-4, 1e-2),# Sample a float uniformly between 0.0001 and 0.1, while# sampling in log space and rounding to increments of 0.00005"qloguniform": tune.qloguniform(1e-4, 1e-1, 5e-5),# Sample a random float from a normal distribution with# mean=10 and sd=2"randn": tune.randn(10, 2),# Sample a random float from a normal distribution with# mean=10 and sd=2, rounding to increments of 0.2"qrandn": tune.qrandn(10, 2, 0.2),# Sample a integer uniformly between -9 (inclusive) and 15 (exclusive)"randint": tune.randint(-9, 15),# Sample a random uniformly between -21 (inclusive) and 12 (inclusive (!))# rounding to increments of 3 (includes 12)"qrandint": tune.qrandint(-21, 12, 3),# Sample a integer uniformly between 1 (inclusive) and 10 (exclusive),# while sampling in log space"lograndint": tune.lograndint(1, 10),# Sample a integer uniformly between 1 (inclusive) and 10 (inclusive (!)),# while sampling in log space and rounding to increments of 2"qlograndint": tune.qlograndint(1, 10, 2),# Sample an option uniformly from the specified choices"choice": tune.choice(["a", "b", "c"]),# Sample from a random function, in this case one that# depends on another value from the search space"func": tune.sample_from(lambda spec: spec.config.uniform * 0.01),# Do a grid search over these values. Every value will be sampled# `num_samples` times (`num_samples` is the parameter you pass to `tune.run()`)"grid": tune.grid_search([32, 64, 128])
}
Tune: A Research Platform for Distributed Model Selection and Training
更多
超参数优化工具
pytorch tune:这篇文章是对channel进行了优化
auto_pytorch
Skopt
使用指导略
How to use Tune with PyTorch(ray的官方文档)
pytorch tune
auto_pytorch
Skopt
python : 超参数优化工具笔记 Tune with PyTorch Quick Start+基础概念相关推荐
- python : 超参数优化工具笔记 Tune with PyTorch 在PyTorch中使用
主要代码 按照本文中的规则进行运行即可,测试过程一共运行的次数为num_samples*epoch. def main(num_samples=10, max_num_epochs=10, gpus_ ...
- 超参数优化专题之工具—microsoft/nni(1)
超参数优化专题之工具-microsoft/nni 这篇博客主要讲述模型的调参的一些基本知识,主要两个方面,调参的工具和相应的算法. 工具我比较推荐的是微软的nni框架,以及weight & b ...
- Python 机器学习 | 超参数优化 黑盒(Black-Box)非凸优化技术实践
文章目录 一.关键原理 二.Python 实践 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一.关键原理 为什么要做超参数优化? 机器学习建模预测时,超参数是用 ...
- 深度学习笔记(十四)—— 超参数优化[Hyperparameter Optimization]
这是深度学习笔记第十四篇,完整的笔记目录可以点击这里查看. 训练神经网络会涉及到许多超参数设置.神经网络中最常见的超参数包括: the initial learning rate lea ...
- python 超参数_完整介绍用于Python中自动超参数调剂的贝叶斯优化
完整介绍用于Python中自动超参数调剂的贝叶斯优化-1.jpg (109.5 KB, 下载次数: 0) 2018-7-4 23:45 上传 调剂机器学习超参数是一项繁琐但至关重要的任务,因为算法的性 ...
- 【机器学习】算法模型自动超参数优化方法
什么是超参数? 学习器模型中一般有两类参数,一类是可以从数据中学习估计得到,我们称为参数(Parameter).还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,我们称为超参数(Hyper ...
- 常见的10大超参数优化库
Skopt https://scikit-optimize.github.io/ 是一个超参数优化库,包括随机搜索.贝叶斯搜索.决策森林和梯度提升树.这个库包含一些理论成熟且可靠的优化方法,但是这些模 ...
- [机器学习] 超参数优化介绍
很多算法工程师戏谑自己是调参工程师,因为他们需要在繁杂的算法参数中找到最优的组合,往往在调参的过程中痛苦而漫长的度过一天.如果有一种方式可以帮助工程师找到最优的参数组合,那一定大有裨益,贝叶斯超参优化 ...
- 全网最全:机器学习算法模型自动超参数优化方法汇总
什么是超参数? 学习器模型中一般有两类参数,一类是可以从数据中学习估计得到,我们称为参数(Parameter).还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,我们称为超参数(Hyper ...
最新文章
- (一)七种AOP实现方法
- nginx重新编译安装mysql_Centos 6.5编译安装Nginx+php+Mysql
- vue 多层双层全选_vue多级复杂列表展开/折叠及全选/分组全选实现
- 使用tensorflow查询机器上是否存在可用的gpu设备
- Unity内置的三套消息发送机制的应用实例
- Centos 7 文件管理基础命令
- Linux 系统服务管理和控制程序(初始化系统/Init System) -- systemd 介绍
- Laravel 的安装使用
- 电子科大自考c语言试题,电子科大“立人班”40人全部读研深造
- matlab期中考试卷,湖南大学matlab期中考试试卷分析
- six.move 的作用
- 异步编程之co——源码分析
- 【GitHub】cmder下载地址
- 现代通信技术之分组交换技术
- chrome 打开默认页 被篡改_Chrome谷歌浏览器主页总被篡改怎么解决?
- 线性空间里的线性映射
- 计算机网络谢希仁(1)
- 计算机科学与技术有哪些证书,计算机科学与技术在职研究生的证书有哪些?
- ACM模板(从小白到ACMer的学习笔记)
- 华山绝顶的人生思考。
热门文章
- android自动获取位置,Android中获取当前位置信息
- 微信小程序报错{“errMsg“:“hideLoading:fail:toast can‘t be found“}
- Linux基础命令---文本过滤coi
- 【SQL】递归展BOM全阶,含半成品,用量累乘,如半成品用量2,下阶用量需要乘以2
- HTML期末学生作业 HTML+CSS+JavaScript仿猫眼电影在线网站 Hbuilder网页制作
- @SentinelResource详解
- Android基站定位——通过手机信号获取基站信息(一)
- Android基站定位——三基站(多基站)定位(三)
- 【综述】Transformers in Remote Sensing: A Survey
- Web应用程序的身份验证机制