使用Python编写机器学习入门教程
本文要点
\\
- 当输入变量和我们尝试去预测的输出变量之间是线性相关时,或者当解释模型的能力很重要时(例如,隔离任何一个输入变量对于预测的影响),逻辑回归对于二进制分类是比较合适的选择。\\t
- 决策树和随机森林是非线性模型,可以被用来很好地计算更复杂的关系,但是它不太适用于处理人类行为理解。\\t
- 适当地评估模型性能很重要,验证你的模型在之前未见过的数据上表现是否良好。\\t
- 产品化一个机器学习模型牵涉许多考虑因素,不同于模型开发过程中的那些考虑因素:例如,如何同步地计算模型输入?每次得分时你需要记录什么信息?你如何确定生产环境下模型的性能?\
机器学习是我们日常接触到的许多产品的长期发展动力,从类似于Apple的Siri和Google的智能助手,到类似于亚马逊的建议你买新产品的推荐引擎,再到Google和Facebook使用的广告排名系统。最近,机器学习又由于“深度学习”的发展开始进入公众视线,包括AlphaGo击败韩国围棋大师李世石,并且在图像识别和机器翻译领域发布了令人印象深刻的新产品。
\\
在本系统中,我们将介绍一些强大的,但是在机器学习中普遍适用的技术。这些技术既包括深度学习,也包括现代企业需要的许多传统算法。阅读系统文章之后,你应该具备在你自己的领域着手进行具体机器学习实验的相应知识。
\\
InfoQ的这篇文章是“机器学习介绍”系列的一部分。你可以通过订阅RSS收到后续通知。
\\
本系列将探讨各种关于机器学习的主题和技术,机器学习可以说是最近几年最有讨论价值的技术和计算机科学领域。在InfoQ发表的一些文章中已经涉及到了高层的机器学习(例如,Getting a Handle on Data Science系列文章之一Getting Started with Machine Learning),本篇文章及后续一篇文章我们会详细介绍之前讨论的概念和方法,突出具体示例,并且尝试进入新领域,包括神经网络和深度学习。
\\
我们会从本文开始,结合一个Python扩展的“案例研究”:我们可以如何构建用于检测信用卡诈骗的机器学习模型?(虽然我们会使用诈骗检测语言,所做的大部工作是在微小修改基础上适用于其他分类问题,例如,广告点击预测。)随着时间的推移,我们会遇到许多机器学习的关键思想和术语,包括逻辑回归、决策树、随机森林、正向预测(True Positive)和负向预测(False Positive)、交叉验证(cross-validation),以及受试者工作特征(Receiver Operating Characteristic,简称ROC)曲线和曲线以下区域(Area Under the Curve,简称AUC)曲线。
\\
目标:信用卡诈骗
\\
在线销售产品的企业不可避免地需要应对欺诈行为。一个典型的欺诈交易,诈骗者使用偷来的信用卡号码去在线网站购买商品。欺诈者稍后会在其他地方以打折形式销售这些商品,中饱私囊,然而企业必须承担“退款”成本。你可以从这里获取信用卡诈骗的详细内容。
\\
让我们假设自己是一个电子商务企业,并且已经应对诈骗有一些时间了,我们想要使用机器学习帮助解决问题。更具体地说,每次交易进行时,我们想要去预测是否可以证明是诈骗者(例如,是否授权的持卡人不是交易人),这样我们可以相应地采取行动。这类机器学习问题被称为分类,因为我们正在做的就是把每笔收入归入欺诈或非欺诈这两类中的其中一类。
\\
对于每一笔历史付款,我们有一个布尔值指示表明这笔交易是否欺诈(fraudulent),以及一些我们认为可能表明欺诈的其他属性,例如,以美元支付的金额(amount)、卡片开卡国家(card_country),以及这张卡片同一天内在我们企业的支付次数(card_use_24h)。因此,极有可能我们建立预测模型的数据看起来如以下CSV所示:
\\
\fraudulent,charge_time,amount,card_country,card_use_24h\\False,2015-12-31T23:59:59Z,20484,US,0\\False,2015-12-31T23:59:59Z,1211,US,0\\False,2015-12-31T23:59:59Z,8396,US,1\\False,2015-12-31T23:59:59Z,2359,US,0\\False,2015-12-31T23:59:59Z,1480,US,3\\False,2015-12-31T23:59:59Z,535,US,3\\False,2015-12-31T23:59:59Z,1632,US,0\\False,2015-12-31T23:59:59Z,10305,US,1\\False,2015-12-31T23:59:59Z,2783,US,0
\\
有两个重要的细节我们会在讨论里跳过,但是我们需要牢记于心,因为它们同样重要,甚至超过我们在这里介绍的模型构建问题。
\\
首先,确定我们认为存在诈骗行为的特征是一个数据科学问题。在我们的例子中,我们已经确认支付的金额、这张卡片是在哪个国家发行的,以及过去一天里我们收到的卡片交易次数等作为特征,我们认为这些特征可能可以有效预测诈骗。一般来说,你将需要花费许多时间查看这些数据,以决定什么是有用的,什么是没有用的。
\\
其次,计算特征值的时候存在数据基准问题:我们需要所有历史样本值用于训练模型,但是我们也需要把他们的实时付款值加进来,用以正确地对新的交易加入训练。当你开始担忧诈骗之前,你已经维持和记录了过去24小时滚动记录的信用卡使用次数,这样如果你发现特征是有利于诈骗检测的,你将会需要在生产环境和批量环境中分别在计算中使用它们。依赖于定义的不同特征,结果很有可能是不一样的。
\\
这些问题合在一起通常被认为是特征工程,并且通常是工业级机器学习领域最常涉及(有影响)的部分。
\\
逻辑回归
\\
让我们以一个最基本的模型开始,一个线性模型。我们将会发现系数a、b、...、z,如下
\\
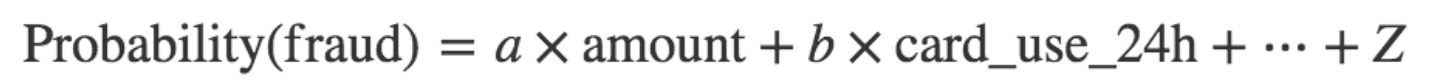
\\
对于每一笔支付,我们会将amount、card_country和card_use_24h的值代入到上面的公式中,如果概率大于0.5,我们会“预测”这笔支付是欺诈的,反之我们将会预测它是合法的。
\\
在我们讨论如何计算a、b、...、z之前,我们需要解决两个当前问题:
\\
- 概率(欺诈)需要在0和1之间的一个数字,但是右侧的数量可以任意大(绝对值),取决于amount和 card_use_24h的值(如果那些特征的值足够大,并且a或者b至少有一个非零)。\\t
- card_country不是一个数字,它从许多值中取其一(例如US、AU、GB,以及等等)。这些特征被称为分类的,并且需要在我们可以训练模型之前进行适当地“编码”。\
Logit函数
\\
为了解决问题(1),我们会建立一个称为诈骗者的log-odds模型,而不是直接通过p = Probability(fraud)构建模型,所以我们的模型就变成
\\
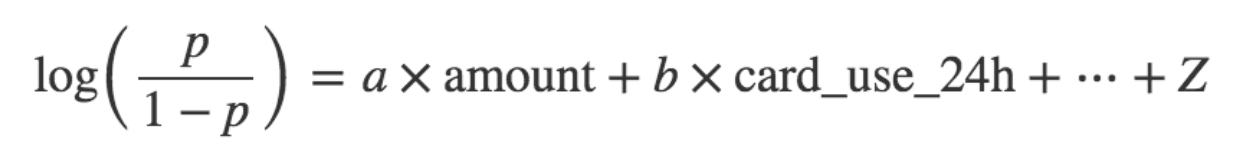
\\
如果一个事件发生的概率为p,它的可能性是p / (1 - p),这就是为什么我们称公式左边为“对数几率(log odds)”或者“logit”。
\\
考虑到a、b、...、z这些值和特征,我们可以通过反转上面给出的公式计算预测诈骗概率,得到以下公式
\\
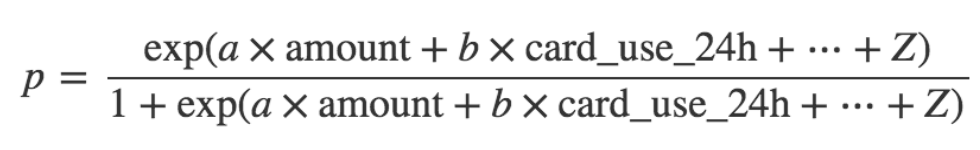
\\
诈骗p的概率是线性函数的转换函数L=a x amount + b x card_use_24h + …,看起来如下所示:
\\
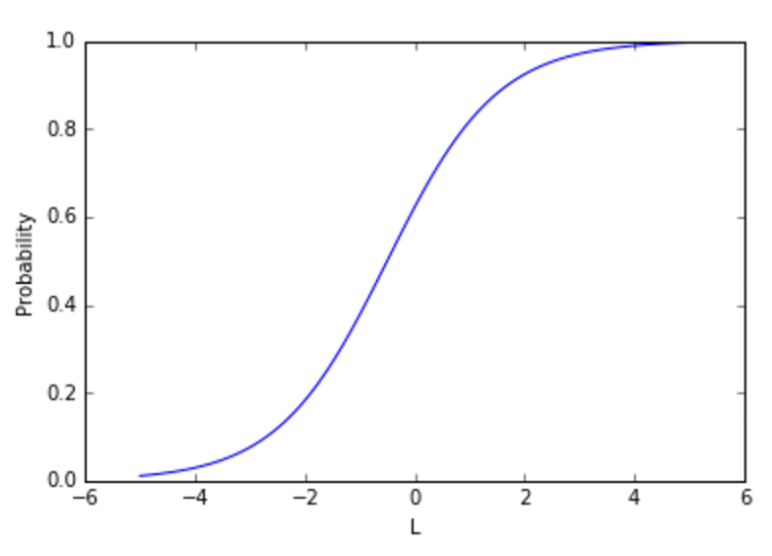
\\
不考虑线性函数的值,sigmoid映射为一个在0和1之间的数字,这是一个合法的概率。
\\
分类变量
\\
为了解决问题(2),我们会使用分类变量 card_country(拿N个不同值中的1个)并且扩展到N-1“虚拟”变量。这些新的特征是布尔型格式,card_country = AU、card_country = GB等等。我们只是需要N-1“虚拟”,因为当N-1虚拟值都是false的时候N值是必然包含的。为了简单起见,让我们假设card_country可以仅仅使用AU、GB和US三个值中的一个。然后我们需要两个虚拟变量去对这个值进行编码,并且我们想要去适配的模型(例如,发现系数值)是:
\\
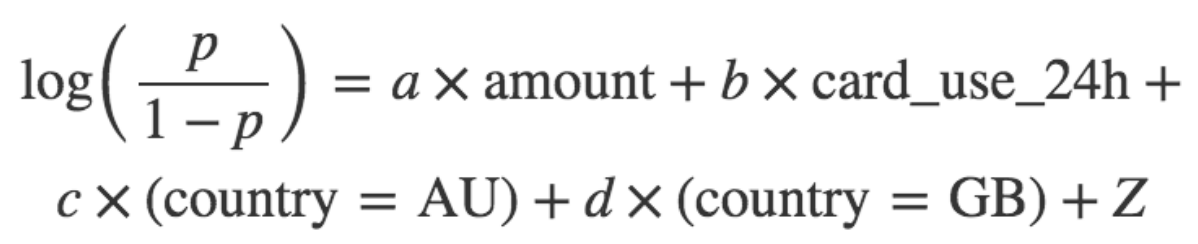
\\
模型类型被称为一个逻辑回归。
\\
拟合模型
\\
我们如何确定a、b、c、d和Z的值?让我们以随机选择a、b、c、d和Z的方式开始。我们可以定义这套猜测的可能性如:
\\
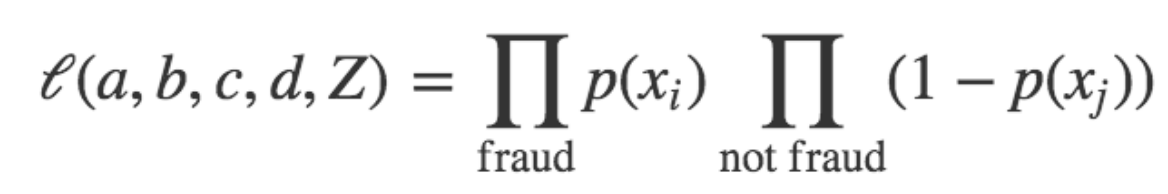
\\
也就是说,从我们的数据集里取出每一个样本,并且计算诈骗p的预测概率,提供给猜测a、b、c、d和Z(每个样本的特征值)的值使用:
\\
\\
对于每个实际上是欺诈的样本,我们希望p比较接近1,而对于每一个不是诈骗的样本,我们希望p接近0(所以1-p应该接近1)。因此,我们对于所有欺诈样本采用p产品,对于所有非欺诈样本采用1-p产品,用以得到评估,猜测a、b、c、d和Z有多好。我们想让似然函数尽可能大(例如,尽可能地接近1)。开始我们的猜测,我们迭代地调整a、b、c、d和Z,提高可能性,直到我们发现不可以再通过扰动系数提升它的值。一种常用的优化方式是随机梯度下降。
\\
Python实现
\\
现在我们将会使用标准的Python开源工具实践我们刚刚讨论完的原理。我们将会使用pandas,它给Python带来了类似于R语言的大规模数据科学的API(R-like data frames),以及scikit-learn,它是一个热门的机器学习包。让我们对之前描述过的CSV文件命名为“data.csv”;我们可以上传数据并看一下下面的代码:
\\
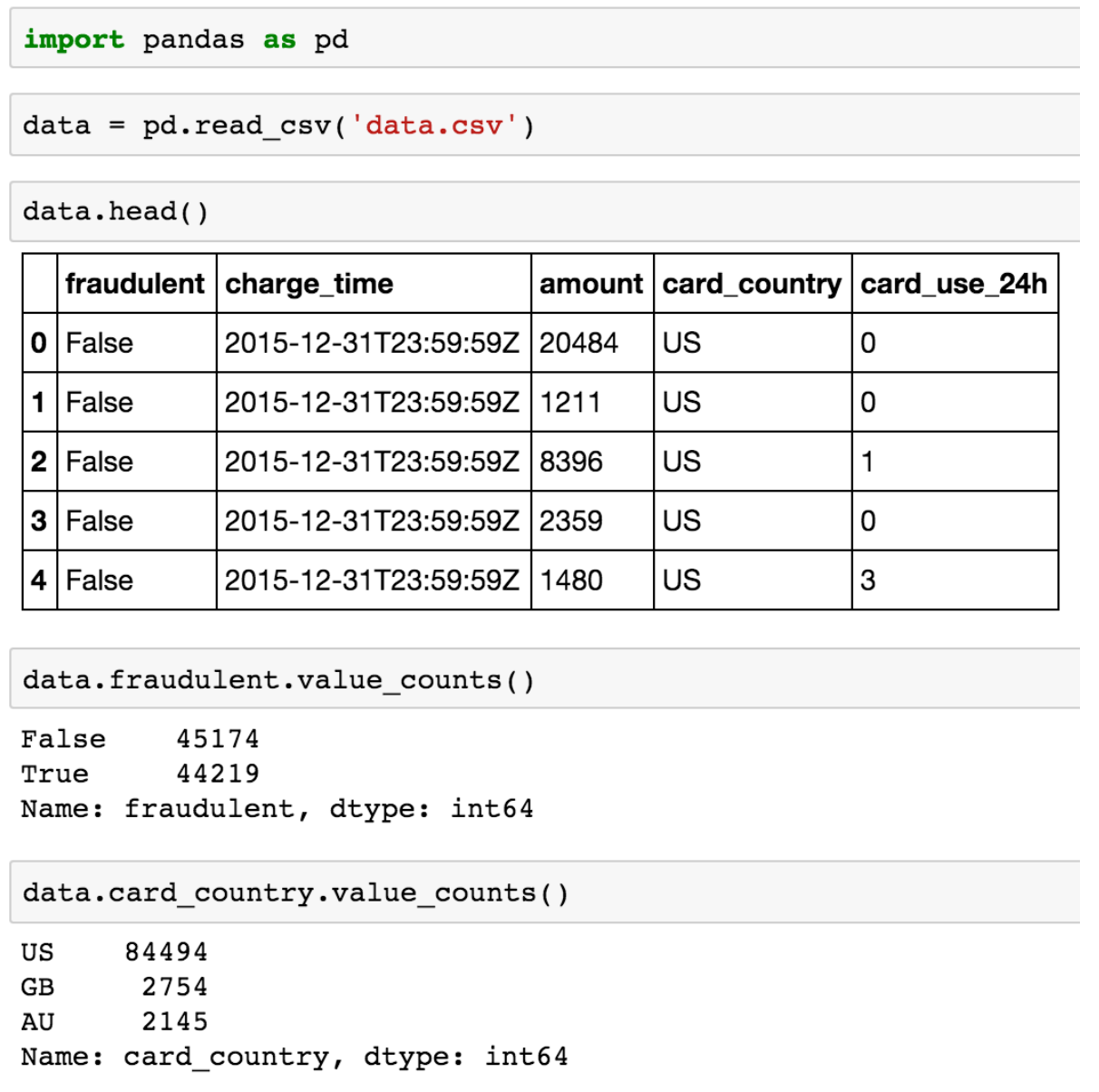
\\
我们可以使用如下代码编码card_country成为合适的虚拟变量
\\
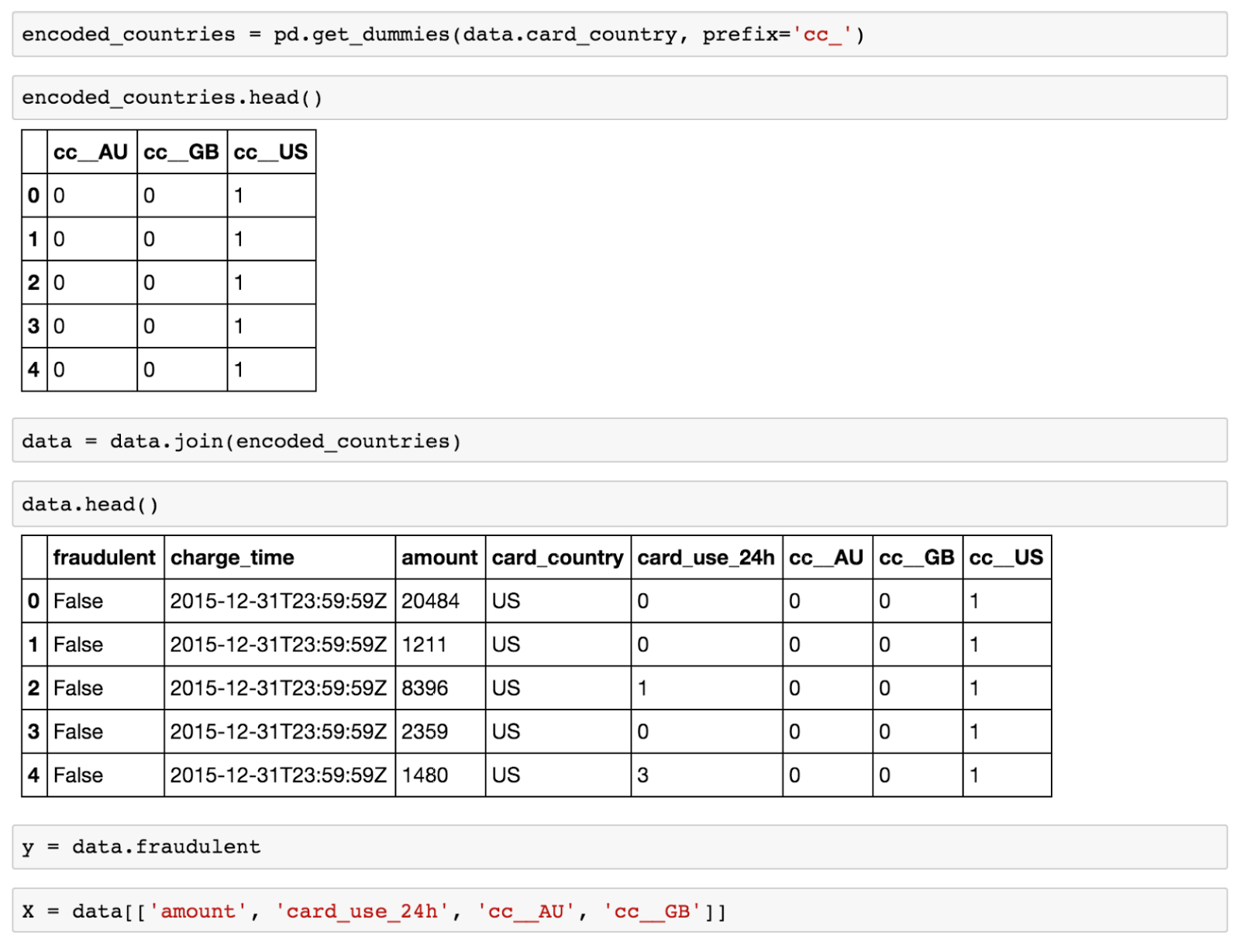
\\
现在大规模数据帧数据拥有了所有我们需要的数据、虚拟变量以及所有用于训练我们的模型的数据。我们对目标进行切分(在这种欺诈情况下尝试预测变量)以及用scikit需要的属性作为不同的输入参数。
\\
在进行模型训练之前,我们还有一个问题需要讨论。我们希望我们的模型归纳充分,例如,当对付款进行分类时应该是准确的,它应该是我们之前没有见过的方式,而不应该仅仅是之前见过那些在支付时计算的特殊模式。为了确保不会在现有的数据中过度拟合模型成为噪声,我们将会分割数据为两个训练集,一个训练集会被用来评估模型参数(a、b、c、d和Z)以及验证集(也被叫做测试集),另一个数据集会被用来计算模型性能指标(下一章我们会介绍)。如果一个模型是过度拟合的,它会在训练集上表现良好(因为它会在该集合中学习模式),但是在验证集上表现较差。还有其他的交叉验证方式(例如,k-fold交叉验证),但是“测试训练”分离会适合我们这里的目的。
\\
我们使用sckit可以很轻松地分割数据为训练和测试集,如下:
\\

\\
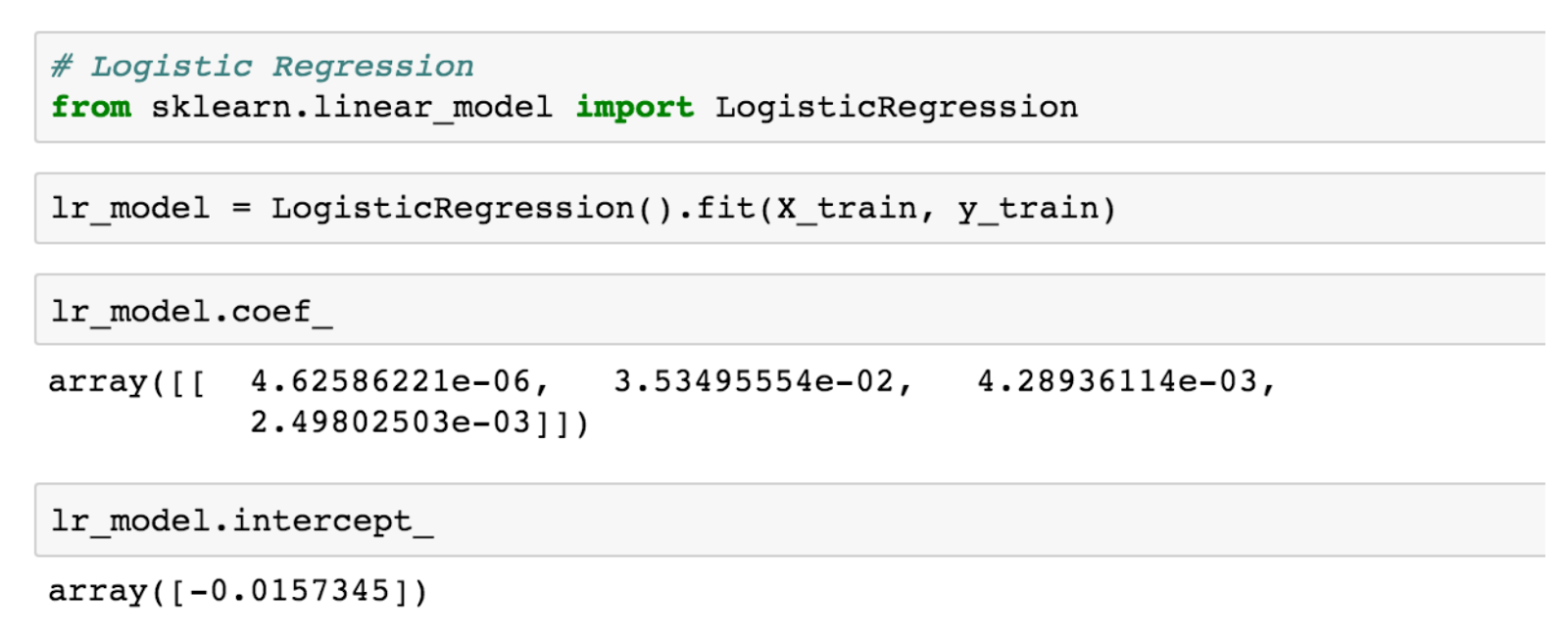
在这里例子中,我们会使用数据的2/3用于训练模型,数据的1/3用于验证模型。我们现在准备去训练模型,在此它只是个琐碎小事:
\\
\\
该拟合函数运行拟合程序(最大化上面提到的似然函数),然后我们可以针对a、b、c、d(在coef_)和Z(在intercept_)的值查询返回的对象。因此我们的最终模型是
\\
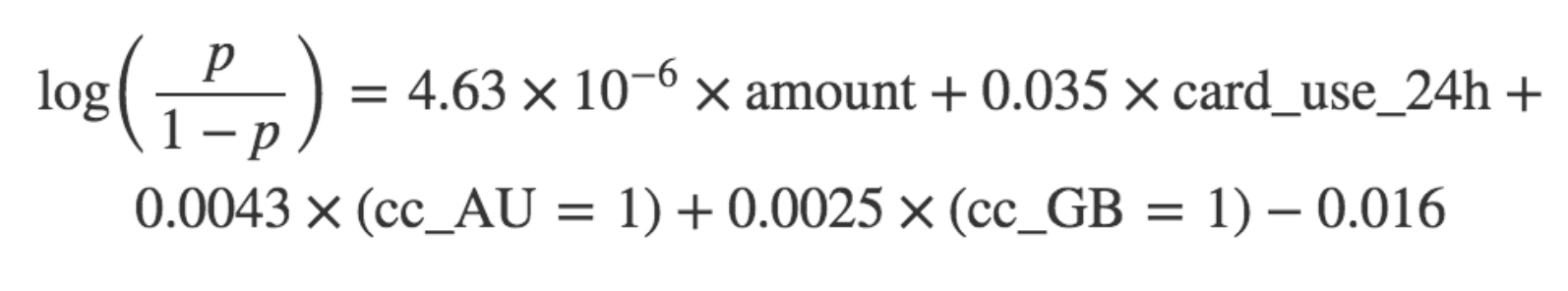
\\
评价模型表现
\\
一旦训练了模型之后,我们就需要去确定这个模型在预测感兴趣的变量上究竟有多好了(在本例子中,该布尔值表明该支付是否存在欺诈)。回想一下我们曾经说过希望对支付按照欺诈进行分类,如果概率(欺诈)大于0.5,我们希望将其归类为合法的。针对一个模型和一个分类规则的性能评定方式,通常使用两个变量,如下所示:
\\
- 假阳性率:所有合法费用中被错误地分类为欺诈的那部分,以及\\t
- 真阳正率(也被称为召回率或者敏感性指标),所有欺诈收入中被正确地分类为欺诈的那部分。\
评估分类性能有很多方式,我们会锁定这两个变量。
\\
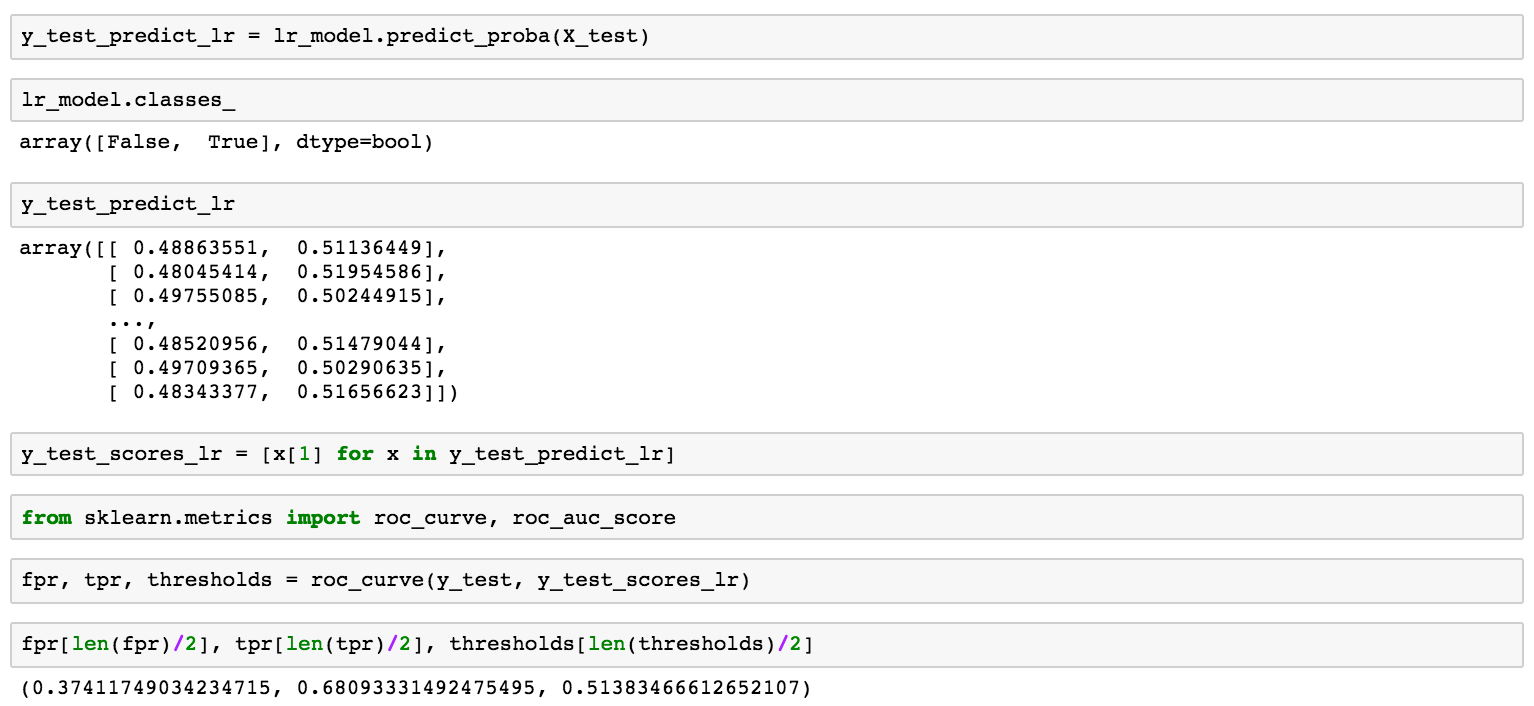
理想情况下,假阳性率将会接近0并且真阳正率会接近1。当我们改变概率阈值时我们把一笔费用分类为欺诈的(上面我们说是0.5,但是我们可以选择0和1之间的任何值,越小的值意味着我们更加积极地标记支付为欺诈的,而高的值意味着我们更加保守),假阳性率和真阳正率勾画了一个曲线,这个曲线依赖于我们的模型有多好。我们称之为受试者工作特征曲线(ROC曲线),可以使用scikit很容易计算出来:
\\
\\
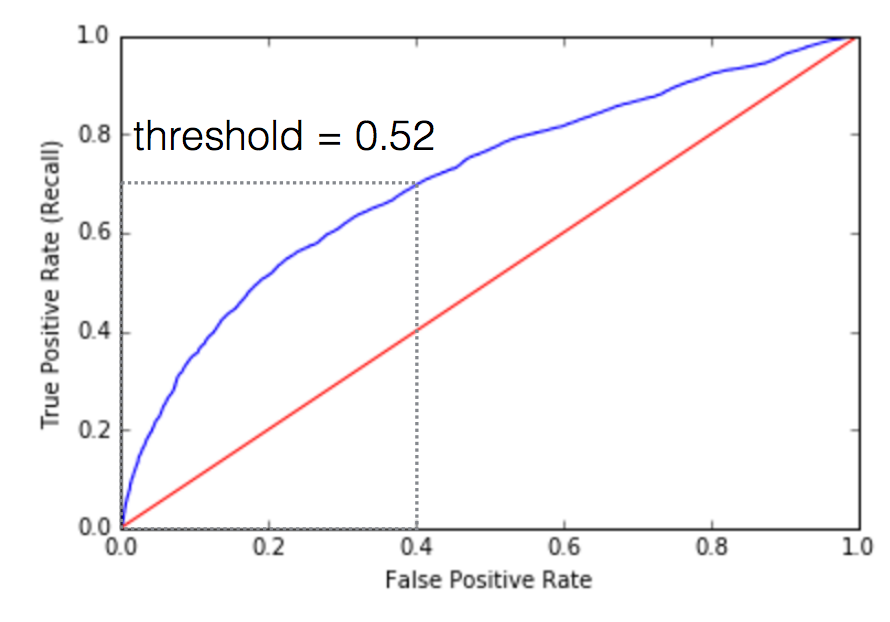
变量fpr、tpr和阈值包含了所有ROC曲线的数据,但是我们挑选了一些有针对性的样本:如果概率(欺诈)大于0.514,而假阳性率是0.374,真阳性率是0.681时,我们假定该费用为欺诈。我们所选的ROC曲线及描绘点为:
\\
\\
模型性能较好,越接近ROC曲线(上面蓝色的线),越会紧靠图形左上方的边框。注意ROC曲线可以告诉你模型有多好,可以使用一个AUC数计算,或者查看曲线下的面积。AUC值越接近于1,模型性能越好。
\\

\\
当然,当你把模型值放入生产环境并使用它时,你通常会需要去通过我们上面采用的方式,即比较他们的阈值方式采取行动输出概率模型,如果概率(欺诈)\u0026gt;0.5,我们认为一笔费用被假设为是欺诈的。因此,对于一个特定的应用程序,模型性能对应于ROC曲线上的一个点,曲线整体再一次仅仅控制了假阳性率和真阳正率之间的交易平衡,例如,政策选择范围内的处置方式不同。
\\
决策树与随机森林
\\
上述的逻辑回归模型是线性机器学习模型的一个示例。想象一下,我们有的每一笔支付示例是空间里的一个点,这个点的坐标就是特征值。如果我们仅仅有两个特征值,每个示例点会是X-Y平面上的一个点。如果在我们可以使用线性函数把无欺诈样本和欺诈者样本区分开时,通常类似于逻辑回归的线性模型就能较好地运行,这意味着几乎所有欺诈样本处于一条线的一边,而几乎所有的非欺诈样本处于这条线的另一边。
\\
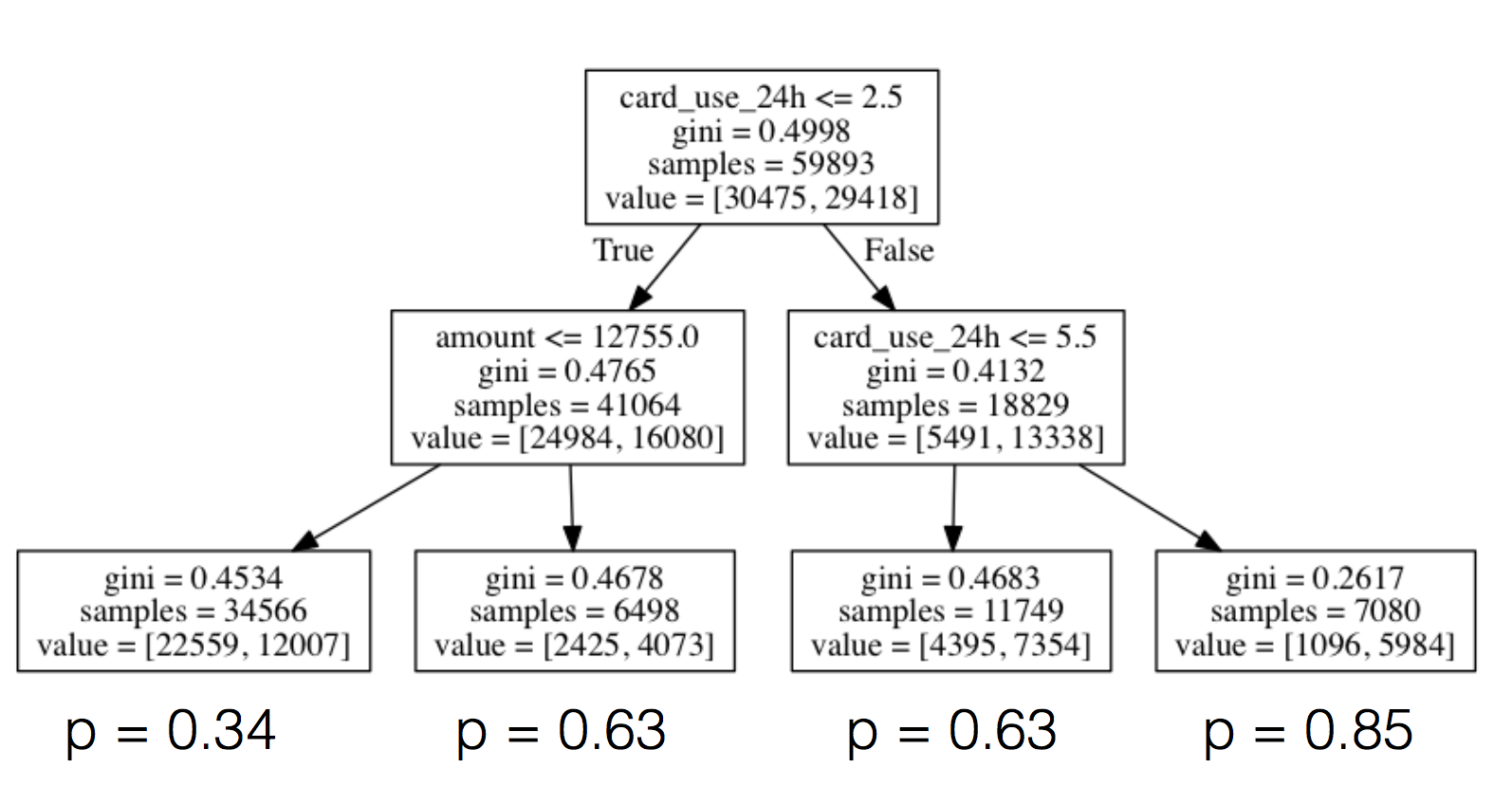
通常情况下,预测特征和目标变量之间的关系,我们试图预测这个关系是非线性的,在这种情况下,我们需要使用非线性模型计算关系。一个强有力的、较为直观的非线性模型是决策树,如下所示:
\\
\\
对于每个节点,我们将特定特征的值和一些阈值进行比较,根据比较结果分出向左还是向右。我们继续以这种方式(类似一个于二十问的游戏,虽然数目不需要二十层深度),直到我们到达树木的树叶。树叶由我们训练集里的所有的样本组成,比较这棵树上的每一个节点的满意路径,示例树叶上欺诈那一部分被模型报告预测的概率判定为欺诈。当我们有新的样本需要被分类时,直到到达树叶之前,我们生成它的特征并且开始玩“二十问的游戏”,然后预测欺诈的可能性,并描述如下。
\\
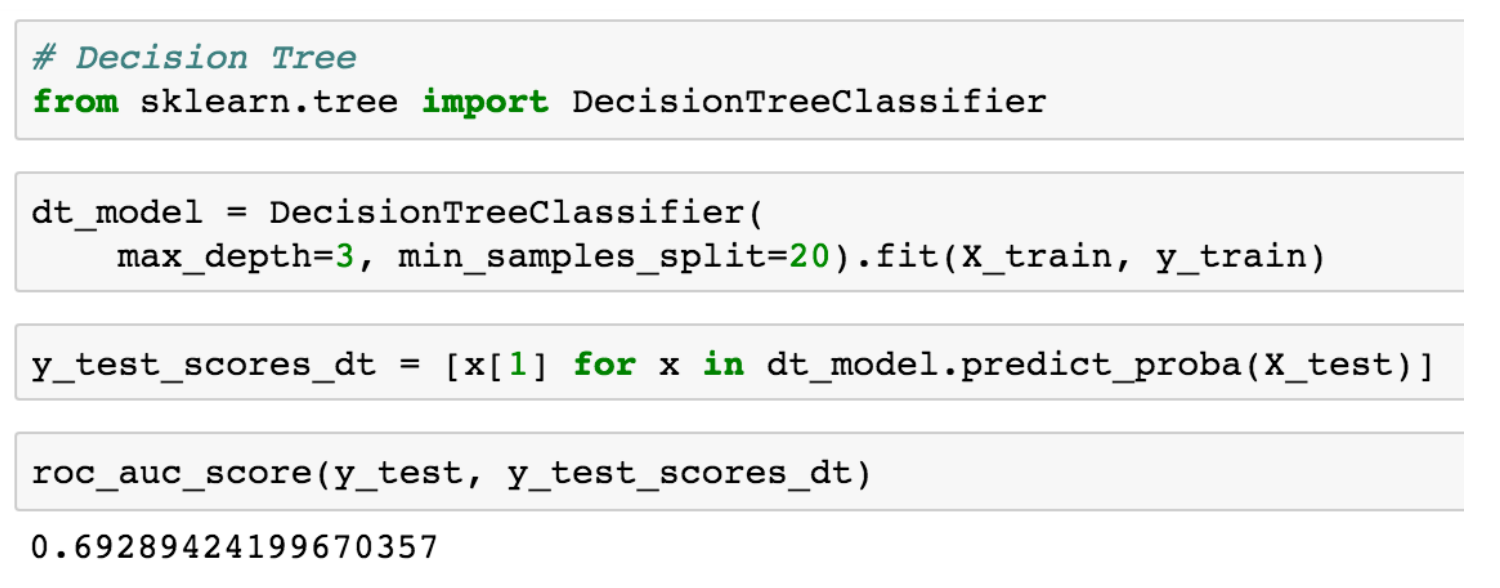
虽然我们不会去深究树是如何生成的细节内容(虽然,简单来说我们就是为每一个节点选择特征和阈值,最大化信息增益或者辨别力概念,即上述图表中报告的基尼系数,并在达到预先指定的一些停止标准前一直进行递归),使用scikit训练决策树模型就像训练逻辑回归一样容易(或者事实上在任何其他模型上):
\\
\\
决策树的一个问题是它们很容易被过度拟合,一棵很深的树的每个叶子仅仅是训练数据里的一个示例,通常会计算每个样本的噪音,并且可能不是常见趋势,但是随机森林模型可以帮助解决这个问题。在一个随机森林中,我们训练大量的决策树,但是每棵树的训练仅仅是我们现有的数据的一个子集,并且当构建每棵树时我们仅仅考虑了切分的子集特征。所预测的欺诈的概率是森林里所有树所生产的平均概率。仅基于数据子集对每棵树进行训练,仅将特征的子集作为每个节点的分离候选来考虑,减少树木之间的相关性,让过度拟合更少一些。
\\
综上所述,当特征和目标变量之间的关系是线性时,像逻辑回归这样的线性模型是适当的,或者当你希望分离任务特征对预测的影响(因为这样可以直接读取回归系数)。另一方面,像决策树这样的非线性模型和随机森林是很难解释的,但是他们可以被用来计算更复杂的关系。
\\
产品化机器学习模型
\\
训练一个机器学习模式可以被认为仅仅是使用机器学习解决业务问题过程的第一步。正如上面描述的,模型训练通常必须在特征工程开始工作前完成。一旦有了模型就需要去产品化它了,也就是说,让这个模型可以用于生产环境并可以采取适当的行动(例如,阻止被评估为欺诈的交易)。
\\
虽然我们不会在这里谈论细节,但是产品化会引入许多挑战,例如,你可以使用Python部署模型,但是你的生产环境软件栈使用的是Ruby。如果出现这种情况,你将会需要让你的模型通过一定格式的序列化形式从Python转为Ruby,并且让你生产环境的Ruby代码读取序列化,或者使用面向服务的系统架构实现从Python到Ruby的服务请求,二选一。
\\
对于完全不同性质的问题,你也会想要在生产环境下维持度量模型性能(与验证数据的大量计算不同)。依赖于你如何使用模型,这个过程可能比较困难,因为仅仅使用模型去控制行为的方式可以导致你没有数据计算你的度量。本系列的其他文章将会考虑一些这类问题。
\\
支撑材料
\\
包含所有的示例代码的Jupyter笔记可以在这里发现,模型训练样本数据可以在这里找到。
\\
作者介绍
\\
 Michael Manapat (@mlmanapat) 在Stripe负责领导机器学习产品开发工作,包括Stripe Radar。在加入Stripe之前,他是Google的一名工程师,同时也是哈佛大学应用数学专业博士后研究员和讲师。他从麻省理工大学(MIT)获得了数学专业博士学位。
Michael Manapat (@mlmanapat) 在Stripe负责领导机器学习产品开发工作,包括Stripe Radar。在加入Stripe之前,他是Google的一名工程师,同时也是哈佛大学应用数学专业博士后研究员和讲师。他从麻省理工大学(MIT)获得了数学专业博士学位。
\\\\
机器学习是我们日常接触到的许多产品的长期发展动力,从类似于Apple的Siri和Google的智能助手,到类似于亚马逊的建议你买新产品的推荐引擎,再到Google和Facebook使用的广告排名系统。最近,机器学习由于“深度学习”的发展开始进入到公众视线,这包括AlphaGo击败韩国围棋大师李世石,并且在图像识别和机器翻译领域发布了令人印象深刻的新产品。
\\
在本系统中,我们将介绍一些强大的,但是在机器学习中普遍适用的技术。这些技术包括深度学习,也包括现代企业需要的许多传统的方式。阅读系统文章之后,你应该有相应知识在你自己的领域着手进行具体的机器学习实验。
\\
查看英文原文:Introduction to Machine Learning with Python
\\
感谢冬雨对本文的审校。
\\
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。
使用Python编写机器学习入门教程相关推荐
- 用python写脚本看什么书-终于知晓python编写脚本入门教程
PyQt5是基于Digia公司强大的图形程式框架Qt5的python接口,由一组python模块构成.PyQt5本身拥有超过620个类和6000函数及方法.在可以运行于多个平台.PyQt5拥有双重协议 ...
- Python 数据科学入门教程:机器学习:回归
Python 数据科学入门教程:机器学习:回归 原文:Regression - Intro and Data 译者:飞龙 协议:CC BY-NC-SA 4.0 引言和数据 欢迎阅读 Python 机器 ...
- python教学视频下载-Python机器学习入门教程全套视频下载【传智播客】
Python机器学习入门教程 初级共3天课 本套教程是机器学习的入门课程,主要介绍一些经典的传统机器学习算法,如分类算法:KNN算法,朴素贝叶斯算法,逻辑回归,决策树算法以及随机森林;回归算法:线性回 ...
- python 分类_简单机器学习入门教程:用Python解决简单的水果分类问题
在这篇机器学习入门教程中,我们将使用Python中最流行的机器学习工具scikit- learn,在Python中实现几种机器学习算法.使用简单的数据集来训练分类器区分不同类型的水果. 这篇文章的目的 ...
- Python零基础入门教程( 快速入门)
前言 学无止境,无止境学. 今天要给大家分享的是<Python零基础入门教程01 快速入门>,这是一个系列的教程,从零基础到项目实战.在本教程中,我会给大家介绍Python入门的一些基础知 ...
- go语言源自python语言_别再用Python编写机器学习基础设施啦,Go语言它不香吗?...
Go 是一种静态强类型.编译型.并发型且具有垃圾回收功能的编程语言,其优点包括部署简单.并发性好.语言设计良好.执行性能好等等.Python 是机器学习项目中最流行的语言,几乎在每个机器学习项目中都能 ...
- Python新手基础入门教程:如何像面试官展示你的coding能力
Python新手基础入门教程:如何像面试官展示你的coding能力 作为程序员,我们通常在面试的时候面试官会出一些题来让你解决,作为优秀的程秀员,除了需要具备解决问题的思路以外,代码的质量也很关键.因 ...
- python自然语言处理入门教程(一)
1.NLTK自然语言处理工具包 1.1 NLTK简介 NLTK是构建Python程序与人类语言数据工作的主要平台.它提供了易于使用的界面,以超过50语料库和词汇资源,如WordNet的,连同一套文字处 ...
- python 科学计算基础教程电子版-终于领会python科学计算入门教程
PyQt5是基于Digia公司强大的图形程式框架Qt5的python接口,由一组python模块构成.PyQt5本身拥有超过620个类和6000函数及方法.在可以运行于多个平台.PyQt5拥有双重协议 ...
最新文章
- junit 静态方法_预期异常规则和模拟静态方法– JUnit
- Vi和Vim的区别和联系
- 内温的整体优先效应实验_[心理学复习.doc
- java 类一定要声明成public_java测试题(四)--答案
- mysql事务和锁 SELECT FOR UPDATE
- 孙鑫VC学习笔记:第十七讲 (四) 用邮槽实现进程间的通信
- 为什么 我的博客还没文章?
- “理论上如何”其实是主观上如何
- win7旗舰版梦幻桌面高清视频下载
- pyqgis iface AttributeError: ‘NoneType‘ object has no attribute ‘mapCanvas‘
- 使用Python进行数独求解(二)
- 如何用树莓派借用计算机的显示屏,树莓派4寸A显示屏使用教程
- html做一个条码扫描页面,vue h5页面如何实现扫一扫功能,扫条形码获取编码
- win10如何共享整个D盘
- 机器学习-白板推导系列(一)-绪论(机器学习的MLE(最大似然估计)和MAP(最大后验估计))
- 求vector向量中的最大值与最小值
- Echarts 图表制作建议指南思维导图,教你什么数据画什么图
- 万字长文拆解Notion
- Android Studio:non-static method cannot be referenced ......的解决办法
- Revit插件的【快速视图样板】视图设置保存