大数据全体系年终总结
到年底了,想着总结下所有知识点好了~今年应用的知识点还是很多的~
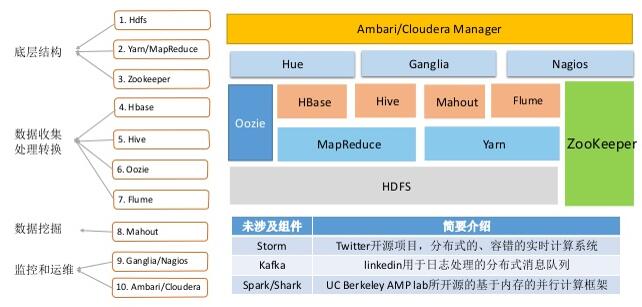
Hadoop生态圈:
1、文件存储当然是选择Hadoop的分布式文件系统HDFS,当然因为硬件的告诉发展,已经出现了内存分布式系统Tachyon,不论是Hadoop的MapReduce,Spark的内存计算、hive的MapReuduce分布式查询等等都可以集成在上面,然后通过定时器再写入HDFS,以保证计算的效率,但是毕竟还没有完全成熟。
2、那么HDFS的文件存储类型为SequenceFile,那么为什么用SequenceFile呢,因为SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件,能够加速MapReduce文件的读写。但是有个问题,SequenceFile文件并不保证其存储的key-value数据是按照key的某个顺序呢存储的,同时不支持append操作。
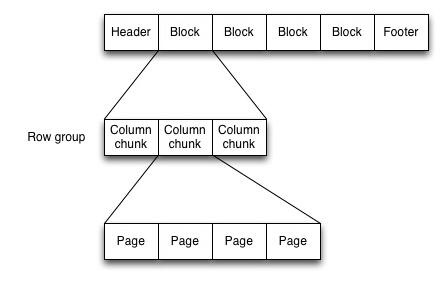
当然,如果选择Spark的话,文件存储格式首选为列式存储parquet,因为一个Parquet文件是由一个header以及一个或多个block块组成,以一个footer结尾。header中只包含一个4个字节的数字PAR1用来识别整个Parquet文件格式。文件中所有的metadata都存在于footer中。footer中的metadata包含了格式的版本信息,schema信息、key-value paris以及所有block中的metadata信息。footer中最后两个字段为一个以4个字节长度的footer的metadata,以及同header中包含的一样的PAR1。不像sequence files以及Avro数据格式文件的header以及sync markers是用来分割blocks。Parquet格式文件不需要sync markers,因此block的边界存储与footer的meatada中,查询效率非常快。
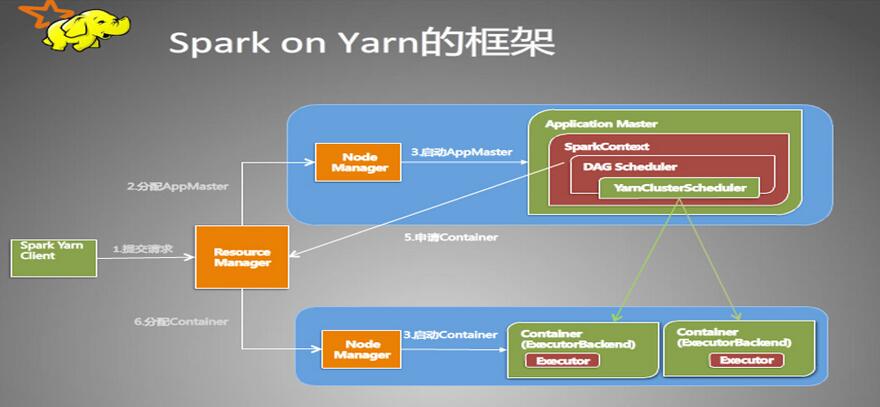
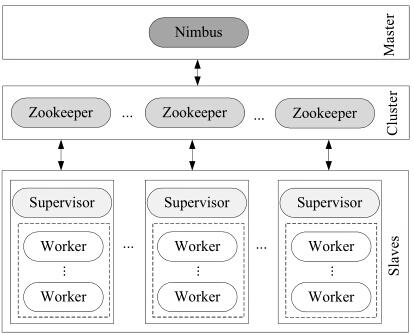
3、zookeeper的作用帮助Yarn实现HA机制,它的主要作用是:
(1)创建锁节点,创建成功的ResourceManager节点会变成Active节点,其他的切换为StandBy.
(2)主备切换,当Active的ResourceManager节点出现异常或挂掉时,在zookeeper上创建的临时节点也会被删除,standy的ResourceManager节点检测到该节点发生变化时,会重新发起竞争,直到产生一个Active节点。(这里会有个脑裂问题,后续说明),那么zookeeper的参数包含在zoo.cfg中(具体参考本博客中的zookeeper配置)
大数据全体系年终总结相关推荐
- 如何快速全面建立自己的大数据知识体系? 大数据 ETL 用户画像 机器学习 阅读232 作者经过研发多个大数据产品,将自己形成关于大数据知识体系的干货分享出来,希望给大家能够快速建立起大数据
如何快速全面建立自己的大数据知识体系? 大数据 ETL 用户画像 机器学习 阅读232 作者经过研发多个大数据产品,将自己形成关于大数据知识体系的干货分享出来,希望给大家能够快速建立起大数据产品的体 ...
- 【大数据】企业级大数据技术体系概述
目录 产生背景 常见应用场景 企业级大数据技术框架 数据收集层 数据存储层 资源管理与服务协调层 计算引擎层 数据分析层 数据可视层 企业级大数据技术实现方案 Google 大数据技术栈 Hadoop ...
- 收藏!一张图帮你快速建立大数据知识体系
简介: 对海量数据进行存储.计算.分析.挖掘处理需要依赖一系列的大数据技术,而大数据技术又涉及了分布式计算.高并发处理.高可用处理.集群.实时性计算等,可以说是汇集了当前 IT 领域热门流行的 IT ...
- 沣西新城大数据产业园:打造大数据全生态链
据测算,到2020年,我国大数据产业的产值将超过两万亿元.大数据已经是陕西西咸新区信息产业的先导.位于西咸新区信息产业园内的国内首个专业大数据产业园区沣西新城大数据产业园正在如火如荼地建设中.该园区面 ...
- 第一章 阿里大数据产品体系
1.大数据基础知识 什么是数据分析? 数据分析是基于商业目的,有目的的进行收集.整理.加工和分析数据,提炼有价值信息的过程. 数据分析流程:需求分析明确目标➡️数据收集加工处理➡️数据分析数据展现➡️ ...
- 【赵渝强老师】阿里云大数据ACP认证之阿里大数据产品体系
阿里大数据产品体系是基于阿里云飞天平台上的数据处理服务.主要分为阿里云大数据基础产品和阿里云数加平台,其产品架构图如下所示: 一.阿里云大数据基础产品 1.云数据库--RDS(ApsaraDB for ...
- 阿里巴巴年薪800k大数据全栈工程师成长记
阿里 大数据全栈工程师一词,最早出现于Facebook工程师Calos Bueno的一篇文章 - Full Stack (需fanqiang).他把全栈工程师定义为对性能影响有着深入理解的技术通才.自 ...
- 大数据治理工程师_大数据治理体系的思考,究竟能为大数据工程师行业带来什么,原来!!!...
[摘要]近几年大数据为人类社会做出了很多贡献,而治理就成为了一个规范大数据发展的准则,其中比较吸引网友注意的就是大数据治理体系的思考,这对于大数据行业究竟意味着什么,是否能成了保证大数据领域安全的一把 ...
- 政府大数据治理体系的框架及其实现的有效路径
政府大数据治理体系的框架及其实现的有效路径 安小米1,2,郭明军1,洪学海3,魏玮1 1 中国人民大学信息资源管理学院,北京 100872 2 数据工程与知识工程教育部重点实验室(中国人民大学),北京 ...
最新文章
- java calendar与date_Java中date和calendar的用法
- oracle job相关
- 第 8 章 容器网络 - 061 - flannel 的连通与隔离
- Taro+react开发(19)--arr声明const报错
- stylus之其余参数(Rest Params)
- as my sql 后面加表达式_SQL.WITH AS.公用表表达式(CTE)(转)
- 【Rényi差分隐私和零集中差分隐私(差分隐私变体)代码实现】差分隐私代码实现系列(九)
- 让现有的Git分支跟踪一个远程分支?
- EasyUI:Tabs 标签页/选项卡
- 牛客网——复杂字符串排序
- AJAX网页抓取工具 Krabber 0.2.9正式发布
- 【逗老师带你学IT】Amazing啊,Zoom落地企业内网IPPBX解决方案,ZOOM可以打国内电话了
- Java操作图片大全
- python价格预测模型_Python 机器学习教程: 预测Airbnb 价格(2)
- 激光测距仪行业报告-产能、产量、销量、销售额、价格及未来趋势
- GitCode 加速同步 GitHub
- cad调了比例因子没反应_CAD制图初学入门技巧:将CAD图形缩放为指定尺寸
- vscode 最详细的调试
- 华为云早报 印度政府拟要求 Google、Facebook 等在本地存储数据
- 跳槽找工作避坑指南(2019最新新版)