ApacheFlink简介
对无界数据集的连续处理
在我们详细介绍Flink之前,让我们从更高的层面上回顾处理数据时可能遇到的数据集的类型以及您可以选择处理的执行模型的类型。这两个想法经常被混淆,清楚地区分它们是有用的。
首先,两种类型的数据集
- 无界:连续追加的无限数据集
- 有界:有限的,不变的数据集
传统上被认为是有限或“批量”数据的许多实际数据集实际上是无界数据集。无论数据是存储在HDFS上的目录序列还是像Apache Kafka这样的基于日志的系统中,都是如此。
无界数据集的例子包括但不限于:
- 最终用户与移动或Web应用程序进行交互
- 物理传感器提供测量
- 金融市场
- 机器日志数据
其次,有两种执行模式
- 流式传输:只要数据正在生成,就会连续执行的处理
- 批处理:在有限的时间内执行处理并运行完成,完成后释放计算资源
尽管不一定是最佳的,但可以用任何一种类型的执行模型来处理任一类型的数据集。例如,尽管在窗口化,状态管理和无序数据方面存在潜在的问题,批处理执行早已应用于无界数据集。
Flink依赖流式执行模型,这是一个直观的适合处理无界数据集的模型:流式执行是连续处理连续产生的数据。数据集类型与执行模型类型之间的对齐在准确性和性能方面提供了许多优点。
特点:为什么Flink?
Flink是一个分布式流处理的开源框架:
- 提供准确的结果,即使在无序或迟到数据的情况下也是如此
- 是有状态和容错的,可以在保持一次性应用程序状态的同时无缝地从故障中恢复
- 大规模执行,在数千个节点上运行,具有非常好的吞吐量和延迟特性
此前,我们讨论了将数据集的类型(有界还是无界)与执行模型的类型(批量与流媒体)进行对齐。下面列出的许多Flink功能 - 状态管理,无序数据的处理,灵活的窗口 - 对于在无界数据集上计算精确的结果非常重要,并且由Flink的流式执行模型来实现。
- Flink保证有状态计算的一次语义。“有状态的”意味着应用程序可以维护一段时间内已经处理的数据的汇总或汇总,并且Flink的检查点设置机制在发生故障时确保应用程序状态的一次语义。
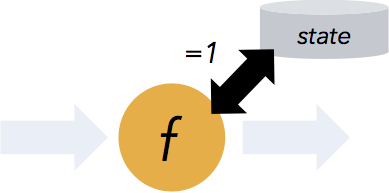
- Flink支持流处理和窗口事件时间语义。事件时间可以轻松计算事件到达顺序不正确,事件可能延迟到达的流的精确结果。
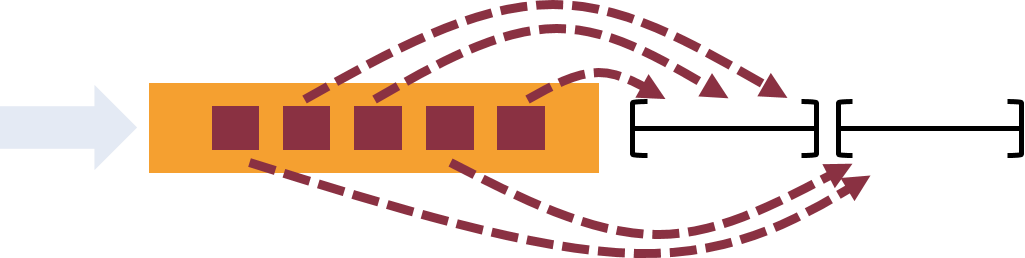
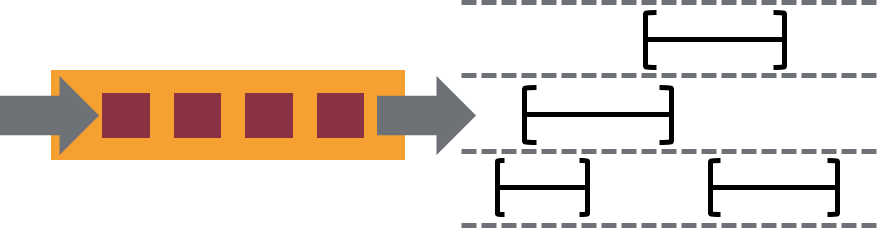
- 除了数据驱动的窗口,Flink还支持基于时间,计数或会话的灵活窗口。Windows可以通过灵活的触发条件进行定制,以支持复杂的流模式。Flink的窗口可以模拟数据创建环境的实际情况。
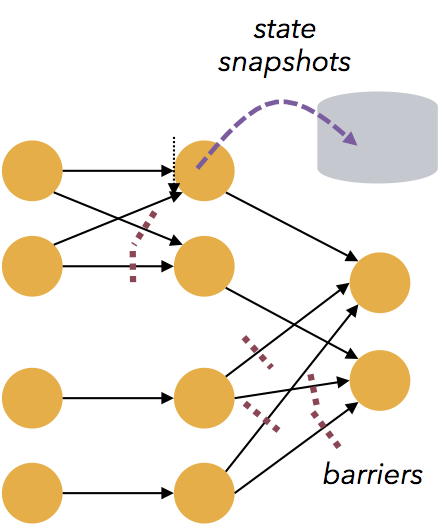
- Flink的容错功能是轻量级的,可以让系统保持高吞吐率,同时提供一次性一致性保证。Flink从零数据丢失的故障恢复,而可靠性和延迟之间的折衷可以忽略不计。
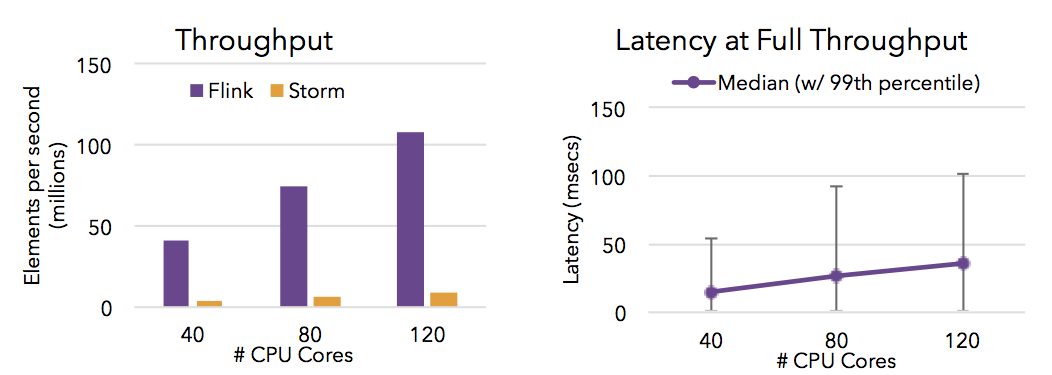
- Flink能够提供高吞吐量和低延迟(快速处理大量数据)。下面的图表显示了Apache Flink和Apache Storm的性能,完成了需要流式数据混洗的分布式项目计数任务。
- Flink的保存点提供了一个状态版本管理机制,可以更新应用程序或重新处理历史数据,而且不会丢失状态,停机时间最短。
- Flink设计用于在数千个节点的大型集群上运行,除了独立集群模式之外,Flink还提供对YARN和Mesos的支持。
Flink,流模型和有界数据集
如果您已经查看过Flink的文档,您可能已经注意到用于处理无界数据的DataStream API以及用于处理有界数据的DataSet API。
在本文前面,我们介绍了流式执行模型(“连续执行的处理,一次一个事件”),直观地适用于无界数据集。那么有界数据集如何与流处理范例相关?
在Flink的情况下,这种关系是相当自然的。一个有界数据集可以简单地看作一个无界特例,所以我们可以将上面所有的流式概念应用到有限数据上。
这正是Flink的DataSet API的行为。有界数据集在Flink内部作为“有限流”进行处理,Flink如何管理有界数据集和无界数据集只有一些细微差异。
所以可以使用Flink来处理有界数据和无界数据,这两个API在相同的分布式流式执行引擎上运行 - 一个简单而强大的体系结构。
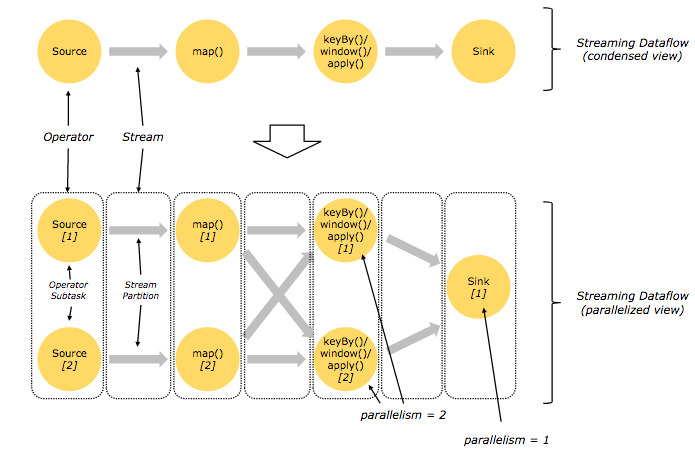
“什么”:从下往上闪烁
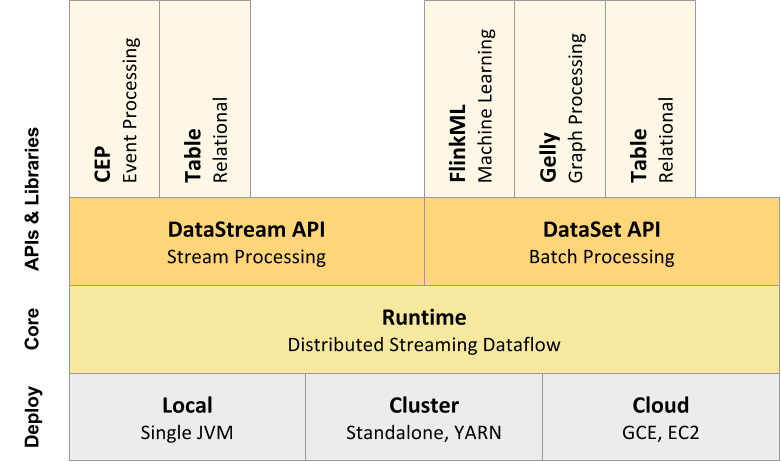
部署模式
Flink可以运行在云环境中,也可以在内部环境中运行,也可以运行在独立的集群上,也可以运行在YARN或Mesos管理的集群上。
运行
Flink的核心是分布式流式数据流引擎,意味着数据一次处理而不是一系列批处理,这是一个重要的区别,因为这是Flink的许多弹性和性能特征.
转载于:https://www.cnblogs.com/wzlbigdata/p/8409601.html
ApacheFlink简介相关推荐
- ApacheCN 大数据译文集 20211206 更新
PySpark 大数据分析实用指南 零.前言 一.安装 Pyspark 并设置您的开发环境 二.使用 RDD 将您的大数据带入 Spark 环境 三.Spark 笔记本的大数据清理和整理 四.将数据汇 ...
- Apache Flink 简介和编程模型
Apache Flink是一个同时支持分布式数据流处理和数据批处理的大数据处理系统. Flink可以表达和执行许多类别的数据处理应用程序,包括实时数据分析,连续数据管道,历史数据处理(批处理)和迭代算 ...
- Flink Sort-Shuffle 实现简介
公众号更名公告 「Flink 中文社区」更名为「Apache Flink」 感谢你们的关注 摘要:本文介绍 Sort-Shuffle 如何帮助 Flink 在应对大规模批数据处理任务时更加游刃有余.主 ...
- etcd 笔记(01)— etcd 简介、特点、应用场景、常用术语、分布式 CAP 理论、分布式原理
1. etcd 简介 etcd 官网定义: A highly-available key value store for shared configuration and service discov ...
- Docker学习(一)-----Docker简介与安装
一.Docker介绍 1.1什么是docker Docker是一个开源的应用容器引擎,基于Go语言并遵从Apache2.0协议开源 Docker可以让开发者打包他们的应用以及依赖包到一个轻量级,可移植 ...
- 【Spring】框架简介
[Spring]框架简介 Spring是什么 Spring是分层的Java SE/EE应用full-stack轻量级开源框架,以IOC(Inverse Of Control:反转控制)和AOP(Asp ...
- TensorRT简介
TensorRT 介绍 引用:https://arleyzhang.github.io/articles/7f4b25ce/ 1 简介 TensorRT是一个高性能的深度学习推理(Inference) ...
- 谷粒商城学习笔记——第一期:项目简介
一.项目简介 1. 项目背景 市面上有5种常见的电商模式 B2B.B2C.C2B.C2C.O2O B2B 模式(Business to Business),是指商家和商家建立的商业关系.如阿里巴巴 B ...
- 通俗易懂的Go协程的引入及GMP模型简介
本文根据Golang深入理解GPM模型加之自己的理解整理而来 Go协程的引入及GMP模型 一.协程的由来 1. 单进程操作系统 2. 多线程/多进程操作系统 3. 引入协程 二.golang对协程的处 ...
最新文章
- (转)OpenSSL命令---pkcs12
- 装饰者模式源码解析(spring-session mybatis jdk servlet)
- linux两个命令一起,paste命令 – 合并两个文件
- 隐藏文件或文件夹属性无法修改解决方案
- html盒子标准模型,CSS——(二)盒子模型与标准流
- shell下将查看大文件有多少行
- LeetCode刷题(26)
- 交比不变性 matlab,高等几何答案
- css3中插入地图,CSS3 地图展开动画
- 重磅!清华大学网上课程面向全国免费开放!无需登录、注册!在家上清华!...
- 微信小程序 体验版开启调试模式
- 直流电机驱动模块介绍
- 来自尼古拉斯的编码风格
- 在谷歌Android都有哪些组,谷歌Android阵营引领了哪些主流技术?
- 视频监控SVAC安全控制简介
- 深度学习数据增强数据扩增方法
- From Shadow Generation to Shadow Removal (CVPR2021)阅读笔记
- 怎样存钱力最大c语言,C语言问题 、//14.怎样存钱利最大 //假设银行整存整取存款不同期限的 月息利率 分别为: 0.63% 期限=1年 0....
- JBoot框架定时任务一个注解轻松带你实现
- ffprobe获取视频帧信息中的pkt_pts、pkt_pts_time