详解基于朴素贝叶斯的情感分析及 Python 实现
相对于「 基于词典的分析 」,「 基于机器学习 」的就不需要大量标注的词典,但是需要大量标记的数据,比如:
还是下面这句话,如果它的标签是:
服务质量 - 中 (共有三个级别,好、中、差)
╮(╯-╰)╭,其是机器学习,通过大量已经标签的数据训练出一个模型,
然后你在输入一条评论,来判断标签级别
宁馨的点评 国庆活动,用62开头的信用卡可以6.2元买一个印有银联卡标记的冰淇淋, 有香草,巧克力和抹茶三种口味可选,我选的是香草口味,味道很浓郁。 另外任意消费都可以10元买两个马卡龙,个头虽不是很大,但很好吃,不是很甜的那种,不会觉得腻。 标签:服务质量 - 中
朴素贝叶斯
1、贝叶斯定理
假设对于某个数据集,随机变量C表示样本为C类的概率,F1表示测试样本某特征出现的概率,套用基本贝叶斯公式,则如下所示:
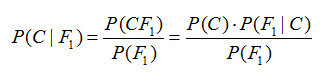
上式表示对于某个样本,特征F1出现时,该样本被分为C类的条件概率。那么如何用上式来对测试样本分类呢?
举例来说,有个测试样本,其特征F1出现了(F1=1),那么就计算P(C=0|F1=1)和P(C=1|F1=1)的概率值。前者大,则该样本被认为是0类;后者大,则分为1类。
对该公示,有几个概念需要熟知:
先验概率(Prior)。P(C)是C的先验概率,可以从已有的训练集中计算分为C类的样本占所有样本的比重得出。
证据(Evidence)。即上式P(F1),表示对于某测试样本,特征F1出现的概率。同样可以从训练集中F1特征对应样本所占总样本的比例得出。
似然(likelihood)。即上式P(F1|C),表示如果知道一个样本分为C类,那么他的特征为F1的概率是多少。
对于多个特征而言,贝叶斯公式可以扩展如下:
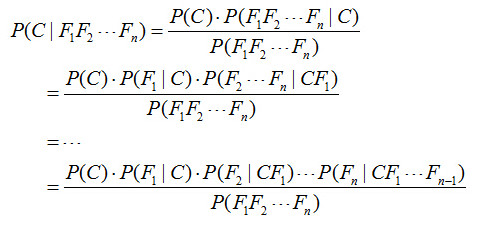
分子中存在一大串似然值。当特征很多的时候,这些似然值的计算是极其痛苦的。现在该怎么办?
2、朴素的概念
为了简化计算,朴素贝叶斯算法做了一假设:“朴素的认为各个特征相互独立”。这么一来,上式的分子就简化成了:
P(C)P(F1|C)P(F2|C)...P(Fn|C)。
这样简化过后,计算起来就方便多了。
这个假设是认为各个特征之间是独立的,看上去确实是个很不科学的假设。因为很多情况下,各个特征之间是紧密联系的。然而在朴素贝叶斯的大量应用实践实际表明其工作的相当好。
其次,由于朴素贝叶斯的工作原理是计算P(C=0|F1...Fn)和P(C=1|F1...Fn),并取最大值的那个作为其分类。而二者的分母是一模一样的。因此,我们又可以省略分母计算,从而进一步简化计算过程。
另外,贝叶斯公式推导能够成立有个重要前期,就是各个证据(evidence)不能为0。也即对于任意特征Fx,P(Fx)不能为0。而显示某些特征未出现在测试集中的情况是可以发生的。因此实现上通常要做一些小的处理,例如把所有计数进行+1(加法平滑 additive smoothing,又叫拉普拉斯平滑 Laplace smothing)。而如果通过增加一个大于 0 的可调参数 alpha 进行平滑,就叫 Lidstone 平滑。
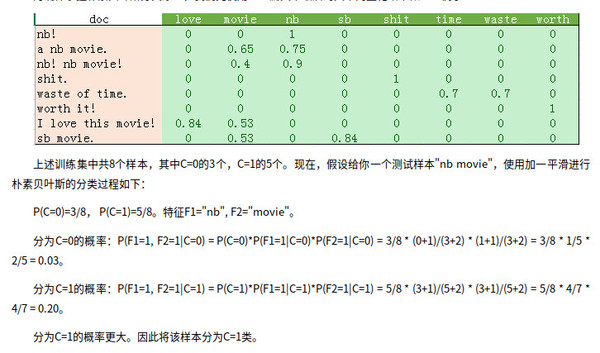
基于朴素贝叶斯的情感分类
原始数据集,只抽了10条

读数据
读取excel文件,用的pandas库的DataFrame的数据类型
分词
对每个评论分词,分词的同时去除停用词,得到如下词表
每个列表是与评论一一对应的

统计
这里统计什么呢?统计两种数据
1. 评论级别的次数
这里有三个级别分别对应 c0 → 好 2 c1 → 中 3 c2 → 差 5
2. 每个词在句子中出现的次数
得到一个字典数据 evalation [2, 5, 3] 半价 [0, 5, 0] 划算 [1, 1, 0] 不错 [0, 2, 0] ········· 不满 [0, 1, 0] 重要 [0, 1, 0] 清楚 [0, 1, 0] 具体 [0, 1, 0] 每个词(特征)后的 list坐标位:0,1,2分别对应好,中,差
以上工作完成之后,就是把模型训练好了,只不过数据越多越准确
测试
比如输入一个句子
世纪联华(百联西郊购物中心店)的点评 一个号称国际大都市,收银处的人服务态度差到极点。银联活动30-10,还不可以连单。
得到结果
c2-差
作者:静静曰
来源:51CTO
详解基于朴素贝叶斯的情感分析及 Python 实现相关推荐
- 朴素贝叶斯情感分析评分python_详解基于朴素贝叶斯的情感分析及 Python 实现
相对于「 基于词典的分析 」,「 基于机器学习 」的就不需要大量标注的词典,但是需要大量标记的数据,比如: 还是下面这句话,如果它的标签是: 服务质量 - 中 (共有三个级别,好.中.差) �r(�s ...
- 朴素贝叶斯情感分析评分python_详解基于朴素贝叶斯的情感分析及Python实现
朴素贝叶斯 1.贝叶斯定理 假设对于某个数据集,随机变量C表示样本为C类的概率,F1表示测试样本某特征出现的概率,套用基本贝叶斯公式,则如下所示: 上式表示对于某个样本,特征F1出现时,该样本被分为C ...
- 基于snownlp及朴素贝叶斯的情感分析——以大众点评网评论为例
「情感分析」是对带有感情色彩的主观性文本进行分析.处理.归纳和推理的过程.按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析.其中,前者多用于舆情监控和信息预测,后者可帮助用 ...
- 基于朴素贝叶斯的垃圾分类算法(Python实现)
有代码和数据集的 https://blog.csdn.net/weixin_33734785/article/details/91428991 附有git库代码的 https://www.cnblog ...
- Java实现基于朴素贝叶斯的情感词分析
朴素贝叶斯(Naive Bayesian)是一种基于贝叶斯定理和特征条件独立假设的分类方法,它是基于概率论的一种有监督学习方法,被广泛应用于自然语言处理,并在机器学习领域中占据了非常重要的地位.在之前 ...
- 基于朴素贝叶斯和预训练Bert模型的中文句子情感分类实践
基于朴素贝叶斯和预训练Bert模型的中文句子情感分类实践 1.任务介绍 本次实践选题为AI研习社2019年9月份举办的中文对话情感分析任务,并在原任务基础上进行了拓展.任务首先给定一中文语句数据集 ...
- NLP之NBGBT:基于朴素贝叶斯(count/tfidf+网格搜索+4fCrva)、梯度提升树(w2c+网格搜索+4fCrva)算法对IMDB影评数据集进行文本情感分析(情感二分类预测)
NLP之NB&GBT:基于朴素贝叶斯(count/tfidf+网格搜索+4fCrva).梯度提升树(w2c+网格搜索+4fCrva)算法对IMDB影评数据集进行文本情感分析(情感二分类预测) ...
- 从爬取豆瓣影评到基于朴素贝叶斯的电影评论情感分析(下)
基于朴素贝叶斯的电影评论情感分析 用到的包:pandas.jieba(分词工具) file=open(r"review.txt",'r',encoding='utf-8') rev ...
- 基于Python的情感极性判断(基于规则、基于逻辑回归、基于朴素贝叶斯)
资源下载地址:https://download.csdn.net/download/sheziqiong/85734418 资源下载地址:https://download.csdn.net/downl ...
最新文章
- C++中关于配置文件的问题
- 程序员面试100题之八:不要被阶乘吓倒(二进制表示中最低位1的位置 )
- java class 转 字节_[转]JAVA字节数据与JAVA类型的转换
- zabbix远程mysql_zabbix action 执行远程命令
- 搭建express框架
- 龙芯.NET正式发布 开源共享与开发者共成长
- sql express 无法启动服务_在Windows2012下安装SQL Server 2005无法启动服务的解决办法...
- Axure的一些入门小案例
- 中国顶级程序员有多牛?一个弄哭韩国,一个堪称阿里“扫地僧”
- XJOI一级二段题解(g++,即C++),也可视作C++算法竞赛教程
- python的多行注释
- 单自由度振动系统 matlab,单自由度系统的振动及matlab分析
- 微信小程序通过微信群发消息(订阅消息)
- 计算机无法打开这个应用,win10照片应用打不开提示“无法打开这应用”如何解决...
- python指纹识别_python之图片指纹(唯一性的)
- Zabbix使用SMTP发送邮件报警并且制定报警内容
- 数据结构(王道版本,主讲人:闲鱼学长)P19-P31
- php opcahe的弊端
- 微信小程序自动连接蓝牙电子秤
- Android5.1.+ getRunningAppProcesses()获取运行中进程(第三方开源库)