tensorflow 1.0 学习:十图详解tensorflow数据读取机制
本文转自:https://zhuanlan.zhihu.com/p/27238630
在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解。确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料。今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下tensorflow的数据读取机制,文章的最后还会给出实战代码以供参考。
一、tensorflow读取机制图解
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
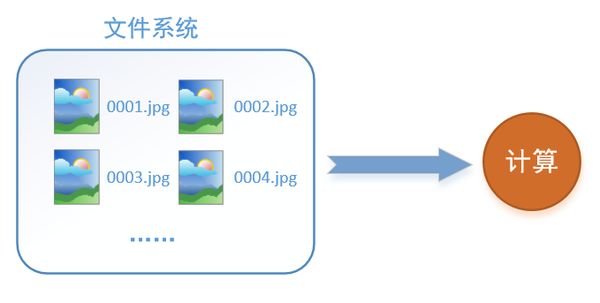
假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
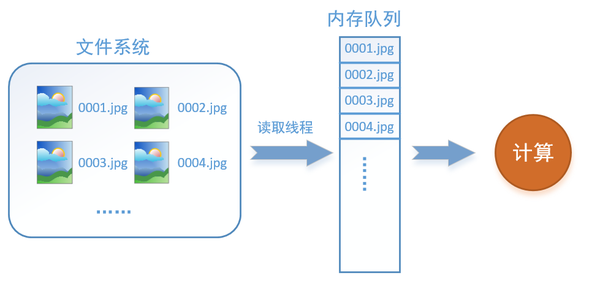
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
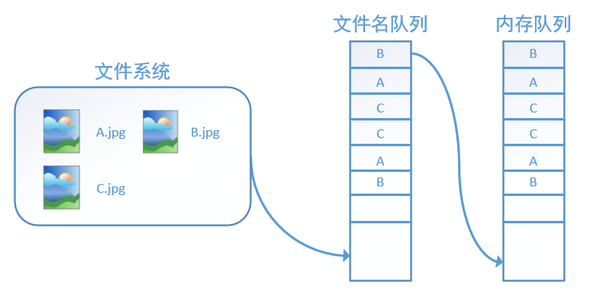
tensorflow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么我们就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束。
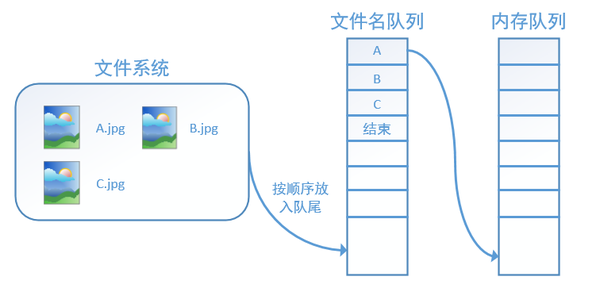
程序运行后,内存队列首先读入A(此时A从文件名队列中出队):
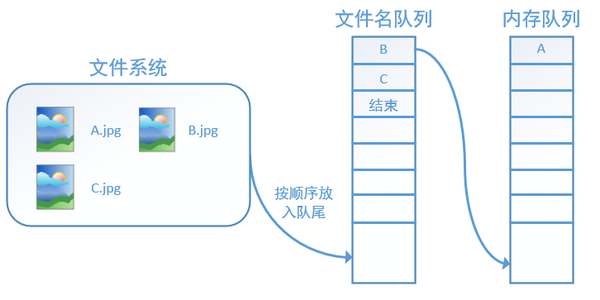
再依次读入B和C:
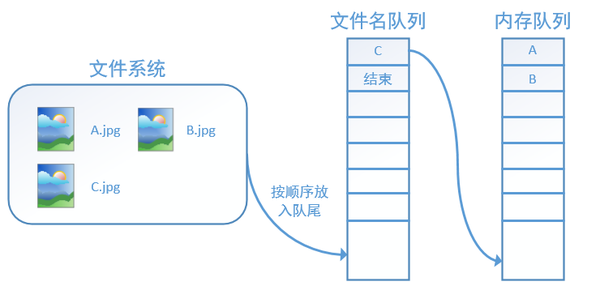
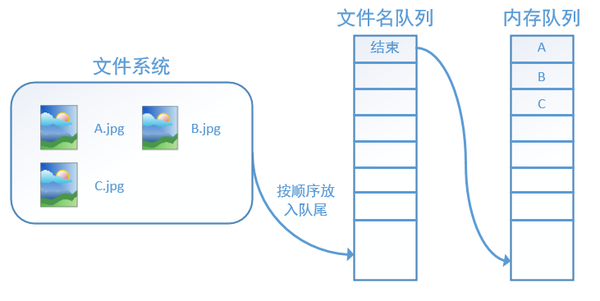
此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。如果我们要跑2个epoch而不是1个epoch,那只要在文件名队列中将A、B、C依次放入两次再标记结束就可以了。
二、tensorflow读取数据机制的对应函数
如何在tensorflow中创建上述的两个队列呢?
对于文件名队列,我们使用tf.train.string_input_producer函数。这个函数需要传入一个文件名list,系统会自动将它转为一个文件名队列。
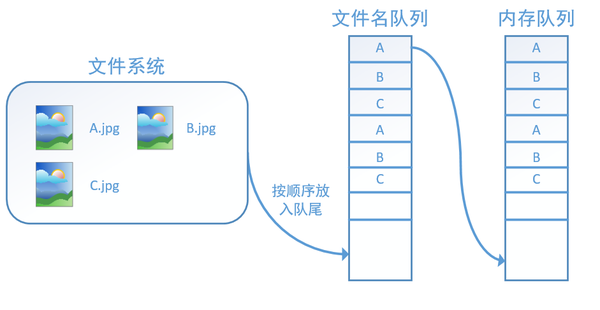
此外tf.train.string_input_producer还有两个重要的参数,一个是num_epochs,它就是我们上文中提到的epoch数。另外一个就是shuffle,shuffle是指在一个epoch内文件的顺序是否被打乱。若设置shuffle=False,如下图,每个epoch内,数据还是按照A、B、C的顺序进入文件名队列,这个顺序不会改变:
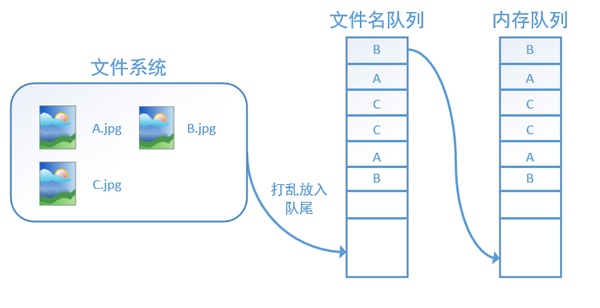
如果设置shuffle=True,那么在一个epoch内,数据的前后顺序就会被打乱,如下图所示:
在tensorflow中,内存队列不需要我们自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了,具体实现可以参考下面的实战代码。
除了tf.train.string_input_producer外,我们还要额外介绍一个函数:tf.train.start_queue_runners。初学者会经常在代码中看到这个函数,但往往很难理解它的用处,在这里,有了上面的铺垫后,我们就可以解释这个函数的作用了。
在我们使用tf.train.string_input_producer创建文件名队列后,整个系统其实还是处于“停滞状态”的,也就是说,我们文件名并没有真正被加入到队列中(如下图所示)。此时如果我们开始计算,因为内存队列中什么也没有,计算单元就会一直等待,导致整个系统被阻塞。
而使用tf.train.start_queue_runners之后,才会启动填充队列的线程,这时系统就不再“停滞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了,这就是函数tf.train.start_queue_runners的用处。
三、实战代码
我们用一个具体的例子感受tensorflow中的数据读取。如图,假设我们在当前文件夹中已经有A.jpg、B.jpg、C.jpg三张图片,我们希望读取这三张图片5个epoch并且把读取的结果重新存到read文件夹中。

对应的代码如下:
# 导入tensorflow
import tensorflow as tf # 新建一个Session
with tf.Session() as sess:# 我们要读三幅图片A.jpg, B.jpg, C.jpgfilename = ['A.jpg', 'B.jpg', 'C.jpg']# string_input_producer会产生一个文件名队列filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)# reader从文件名队列中读数据。对应的方法是reader.readreader = tf.WholeFileReader()key, value = reader.read(filename_queue)# tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化
tf.local_variables_initializer().run()# 使用start_queue_runners之后,才会开始填充队列threads = tf.train.start_queue_runners(sess=sess)i = 0while True:i += 1# 获取图片数据并保存image_data = sess.run(value)with open('read/test_%d.jpg' % i, 'wb') as f:f.write(image_data)我们这里使用filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)建立了一个会跑5个epoch的文件名队列。并使用reader读取,reader每次读取一张图片并保存。
运行代码后,我们得到就可以看到read文件夹中的图片,正好是按顺序的5个epoch:

如果我们设置filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)中的shuffle=True,那么在每个epoch内图像就会被打乱,如图所示:

我们这里只是用三张图片举例,实际应用中一个数据集肯定不止3张图片,不过涉及到的原理都是共通的。
tensorflow 1.0 学习:十图详解tensorflow数据读取机制相关推荐
- 十图详解TensorFlow数据读取机制(附代码)
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下 ...
- 转:跟我学机器视觉-HALCON学习例程中文详解-QQ摄像头读取条码
跟我学机器视觉-HALCON学习例程中文详解-QQ摄像头读取条码 跟我学机器视觉-HALCON学习例程中文详解-QQ摄像头读取条码 第一步:插入QQ摄像头,安装好驱动(有的可能免驱动) 第二步:打开H ...
- tensorflow对应的python版本_详解Tensorflow不同版本要求与CUDA及CUDNN版本对应关系
参考官网地址: Windows端:https://tensorflow.google.cn/install/source_windows CPU Version Python version Comp ...
- 面渣逆袭:MySQL六十六问,两万字+五十图详解!
不知不觉,面渣逆袭系列已经肝了差不多十篇,每一篇都是上万字,几十图,基本上涵盖了面试的主要知识点,这期MySQL结束之后,这个系列可能会暂时告一段落,作为面渣逆袭系列第一阶段的收官之作,大家多多点赞收 ...
- 面渣逆袭:MySQL六十六问,两万字+五十图详解
大家好,我是三鸽,这期继续更新面渣逆袭系列,主角是MySQL. 不知不觉,面渣逆袭系列已经肝了差不多十篇,每一篇都是上万字,几十图,基本上涵盖了面试的主要知识点,这期MySQL结束之后,这个系列可能会 ...
- MySQL六十六问,两万字+五十图详解含(答案解析)
不知不觉,面渣逆袭系列已经肝了差不多十篇,每一篇都是上万字,几十图,基本上涵盖了面试的主要知识点,这期MySQL结束之后,这个系列可能会暂时告一段落,作为面渣逆袭系列第一阶段的收官之作,大家多多点赞收 ...
- 面渣逆袭:Spring三十五问,四万字+五十图详解
基础 1.Spring是什么?特性?有哪些模块? 一句话概括:Spring 是一个轻量级.非入侵式的控制反转 (IoC) 和面向切面 (AOP) 的框架. 2003年,一个音乐家Rod Johnson ...
- 面渣逆袭:Spring三十五问,四万字+五十图详解 。不要错过
基础 1.Spring是什么?特性?有哪些模块? Spring Logo 一句话概括:Spring 是一个轻量级.非入侵式的控制反转 (IoC) 和面向切面 (AOP) 的框架. 2003年,一个音乐 ...
- 三万字,七十图详解计算机网络六十二问(建议收藏)
基础 1.说下计算机网络体系结构 计算机网络体系结构,一般有三种:OSI 七层模型.TCP/IP 四层模型.五层结构. 简单说,OSI 是一个理论上的网络通信模型,TCP/IP 是实际上的网络通信模型 ...
最新文章
- 阿里云 OSS+CDN
- 【C#】C#创建Windows Service服务
- python给函数设置超时时间_在 Linux/Mac 下为Python函数添加超时时间
- Script Lab 续:为 Officejs 开发配置 VSCode 环境
- 给tomcat 配置https
- 基于JAVA+SpringBoot+Mybatis+MYSQL的共享自习室预约管理系统
- js定位div坐标存入mysql_js实现获取div坐标的方法
- Aiiage Camp Day3 B Bipartite
- js || 和 的高级运用
- 史上最完美将windows键盘映射成mac键盘,绝对不需要买HHKB了
- MacOS与Windows快捷键对照
- 【原创】LabView制作实时读取Excel正态分布图
- 第2次作业——时事点评
- Vulkan Samples 阅读 -- Basics(四): Texture Arrays Cube Map Textures 3D Textures
- 双击桌面的计算机图标后会,win10更新完2018年5月累计更新后双击桌面图标出现奇怪异常...
- jquery UI 跟随学习笔记——拖拽(Draggable)
- idea 关于自动导包的设置
- Java并发编程与技术内幕:线程池深入理解
- 青少年编程python一级真题_青少年编程能力等级测评试卷二及答案 Python编程(一级)...
- Git 工作中怎么用?