为什么 Biopython 的在线 BLAST 这么慢?
用过网页版本 BLAST 的童鞋都会发现,提交的序列比对往往在几分钟,甚至几十秒就可以得到比对的结果;而通过调用 API 却要花费几十分钟或者更长的时间!这到底是为什么呢?

NCBIWWW 基本用法
首先,我们来看一下提供了基于 API 在线比对的 Biopython 模块。
Biopython 中的 BLAST 提供了 over the Internet 和 locally 两种选择:Bio.Blast.NCBIWWW 主要是基于 NCBI BLAST API 用于在线比对;Bio.Blast.Applications 模块则是调用本地安装好的 BLAST 程序以及数据库执行比对。在这里我们来重点看一下 Bio.Blast.NCBIWWW 。
Bio.Blast.NCBIWWW 模块中主要是通过 qblast() 函数来调用 BLAST 的在线版本。它具有三个非可选参数:
第一个参数是用于搜索的 blast 程序,为小写字符串。目前,
qblast(biopython==1.7.4)仅适用于 blastn,blastp,blastx,tblast 和 tblastx。第二个参数指定要搜索的数据库。关于这个选项,在 NCBI Guide to BLAST 上有详细的描述。
第三个参数是包含查询序列的字符串。这可以是序列本身,也可以是 fasta 格式的序列,或者是诸如 GI 号之类的标识符。
qblast 函数还接受许多其他选项参数,这些参数基本上类似于我们可以在 BLAST 网页上设置的不同参数。我们在这里只重点介绍其中一些:
参数
url_base是设置用于在 Internet 上运行 BLAST 的基本 URL。默认情况下,它连接到 NCBI(即 url_base='https://blast.ncbi.nlm.nih.gov/Blast.cgi'),但是可以使用它连接到云端运行的 NCBI BLAST 实例。更多详细信息请参阅 qblast 功能的文档。qblast 函数可以返回各种格式的 BLAST 结果,您可以使用可选的
format_type关键字进行选择:“HTML”,“Text”,"ASN.1” 或 "XML"。默认值为 “XML”,因为这是解析器期望的格式。参数
expect用于设置期望值或 e-value 阈值。
有关可选的 BLAST 参数的更多信息,请参考 NCBI 自己的文档或 Biopython 内置的文档:
>>> from Bio.Blast import NCBIWWW>>> help(NCBIWWW.qblast)请注意,NCBI BLAST 网站上的默认设置与 qblast 上的默认设置不太相同。如果获得不同的结果,则需要检查参数(例如,e-value 值和 gap 值)。
例如,如果您要使用 BLASTN 在核苷酸数据库(nt)中搜索核苷酸序列,并且知道查询序列的 GI 号,则可以使用:
>>> from Bio.Blast import NCBIWWW>>> result_handle = NCBIWWW.qblast("blastn", "nt", "8332116")另外,如果我们的查询序列已经存在于 FASTA 格式的文件中,则只需打开文件并以字符串形式读取此记录,然后将其用作查询参数:
>>> from Bio.Blast import NCBIWWW>>> fasta_string = open("m_cold.fasta").read()>>> result_handle = NCBIWWW.qblast("blastn", "nt", fasta_string)我们还可以将 FASTA 文件作为 SeqRecord 对象进行读取,然后仅提供序列本身进行比对:
>>> from Bio.Blast import NCBIWWW>>> from Bio import SeqIO>>> record = SeqIO.read("m_cold.fasta", format="fasta")>>> result_handle = NCBIWWW.qblast("blastn", "nt", record.seq)仅提供序列意味着 BLAST 将自动为您的序列分配一个标识符。您可能更喜欢使用 SeqRecord 对象的 format 方法来制作 FASTA 字符串(其中将包含现有标识符):
>>> from Bio.Blast import NCBIWWW>>> from Bio import SeqIO>>> record = SeqIO.read("m_cold.fasta", format="fasta")>>> result_handle = NCBIWWW.qblast("blastn", "nt", record.format("fasta"))无论给 qblast() 函数提供什么参数,都应在 handle 对象(默认为 XML 格式)中返回结果。下一步是将 XML 输出解析为表示搜索结果的 Python 对象,但是您可能想先保存输出文件的本地副本。在调试从 BLAST 结果中提取信息的代码时,我发现这特别有用(因为重新运行在线搜索速度很慢,并且浪费了 NCBI 计算机时间)。
我们需要小心一点,因为我们只能使用 result_handle.read() 读取一次 BLAST 输出——再次调用 result_handle.read() 会返回一个空字符串。
>>> with open("my_blast.xml", "w") as out_handle:... out_handle.write(result_handle.read())...>>> result_handle.close()完成上面的操作后,结果将保存在文件 my_blast.xml 中,并且原始句柄已提取了所有数据(因此我们将其关闭了)。但是,BLAST 解析器的解析功能采用了类似于文件句柄的对象,因此我们可以打开保存的文件进行输入:
>>> result_handle = open("my_blast.xml")现在我们已经将 BLAST 结果重新放回了句柄中,下一步,如果我们准备对它们进行处理,我们可以参考 Biopython 中 Parsing BLAST output 部分的内容,这里不再说明。
NCBIWWW 实现
在了解 NCBIWWW 的实现前,我们先来看一下 NCBI BLAST 对于 API 使用的一些说明:
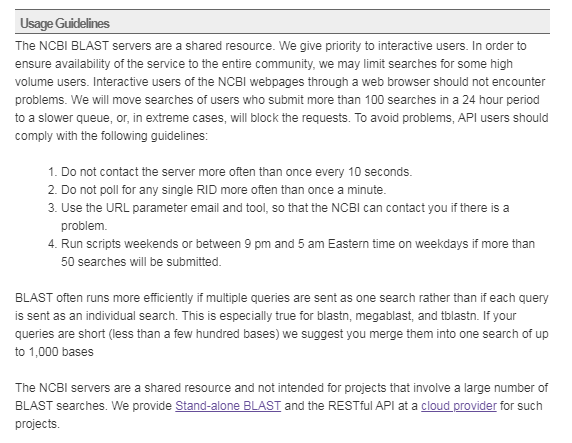
NCBI BLAST 服务器是共享资源。为了确保整个社区都能使用该服务,他们可能会限制某些高流量用户的搜索。
他们会将在 24 小时内提交 100 次以上搜索的用户的搜索移到较慢的队列中,或者在极端情况下将阻止请求。
NCBI BLAST 优先考虑互动的用户,通过网络浏览器的 NCBI 网页的交互式用户不会遇到以上的问题。
对于 API 的使用准则:
与服务器联系的频率不要超过每 10 秒一次。
不要轮询每一个 RID(Request ID) 多于一分钟一次。
使用 URL 参数电子邮件和工具,以便 NCBI 在出现问题时可以与您联系。
如果将提交超过 50 个搜索,则在周末或东部时间东部时间晚上 9 点至凌晨 5 点之间运行脚本。
我们再来看一下 NCBIWWW 在源码层面的处理:
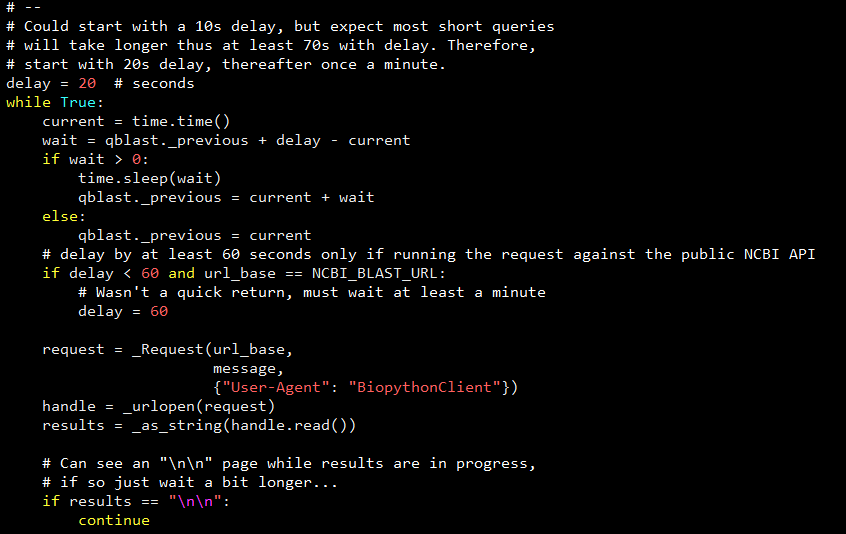
可以看到 NCBIWWW 从 20 秒的延迟开始,然后开始每隔一分钟执行一次 request 轮询,直至任务完成或者任务出现异常。
所以,总的来说,NCBI BLAST API 的使用准则,加上 NCBI BLAST 对用户请求的任务队列处理,甚至 NCBI BLAST 服务器共享资源的限制,以及总用户请求数,这些都可能成为 NCBIWWW.qblast() 异常耗时的原因,这其中还不算个人服务器的网络影响。综上种种原因,如果考虑使用 NCBIWWW.qblast() 执行频繁的序列在线批处理,或许不是一个好的解决方案。
最后,基于 Python 的 NCBI BLAST 在线批处理,如果你有更好的方法,欢迎留言交流。

本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
为什么 Biopython 的在线 BLAST 这么慢?相关推荐
- ncbi blast MATLAB,NCBI在线BLAST使用方法与结果详解
<NCBI在线BLAST使用方法与结果详解>由会员分享,可在线阅读,更多相关<NCBI在线BLAST使用方法与结果详解(5页珍藏版)>请在人人文库网上搜索. 1.NCBI在线B ...
- 4、在线blast比对结果解析(保守结构域)
转载:http://www.bio1000.com/experiment/fenzi/237846.html 标签: NCBI Blast LASTP 摘要 : NCBI BLAST比对结果报告分析: ...
- 用 Python 帮运营妹纸快速搞定 Excel 文档
Microsoft Office 被广泛用于商务和运营分析中, 其中 Excel 尤其受欢迎.Excel 可以用于存储表格数据.创建报告.图形趋势等.在深入研究用 Python 处理 Excel 文档 ...
- pip 20.3 新版本发布!即将抛弃 Python 2.x
据 Python 软件基金会消息,Python Packaging Authority 和 pip 团队于北美时间11月30日宣布发布 pip 20.3版本,开发者可以通过运行 python -m p ...
- 跨界 Bio+IT,推文汇总(推荐收藏)
"BioIT爱好者" 致力于 BIO 生物信息学和 IT 互联网技术的分享和推广,如果你喜欢生信,爱好 IT,乐于分享,欢迎关注并加入我们,一起跨界 Bio+IT. 部分历史推文梳 ...
- 生信入门:序列比对之blast在线和本地使用
主要内容 1 背景 2 在线blast 3 本地blast 3.1 老版本blast 3.2 新版本blast 背景 序列比对(Sequence Alignment)的基本问题是比较两个或两个以上序列 ...
- 序列比对在biopython中的处理
欢迎关注"生信修炼手册"! 序列比对是生物信息学分析中的常见任务,包含局部比对和全局比对两大算法,局部比对最经典的代表是blast, 全局比对则用于多序列比对.在biopython ...
- python 生信分析_安利一款生信分析神器:Biopython之分析环境搭建
当然作为入门,python语言基础还是要会一点点的,不过不需要很深.工具嘛,我们只用关心怎么用得溜,平时也没人追究勺子咋造的只管拿来用,是吧~Biopython是一个包含大量实用功能模块的集合,它支持 ...
- 生信分析-本地BLAST
一. 本地blast简介 本地Blast(Basic Local Alignment Search Tool),是基于本地的比对搜索工具,可以在自己建立的数据库进行blast搜索,与NCBI的在线bl ...
最新文章
- 【青少年编程】【三级】青蛙捕虫
- 智在生活 自在慵懒 科沃斯机器人X京东大牌秒杀日主题展亮相无锡
- 关于在Webservice里使用LinqToSQL遇到一对多关系的父子表中子表需要ToList输出泛型而产生循环引用错误的解决办法!(转)...
- iOS_9_scrollView分页
- Calendar是日历类
- 新闻发布项目——访问温馨提示
- 4线电子围栏安装示意图_知识积累|周界防护-脉冲电子围栏的安装
- static函数与普通函数区别
- 开源压缩算法brotli_Brotli:一种新的压缩算法,可加快互联网速度
- N皇后问题(暴力法、回溯法)
- 数据结构:哈希表设计(c++)
- 希望自己活成什么样的人
- win7系统打不开chrome浏览器的一个真实有效解决办法
- 信息检索与利用(第三版)第一章
- 联想ThinkPad笔记本Fn键关闭与启用方法
- 数据导入与预处理实验一---KETTLE数据处理
- Android VideoView播放 项目中的 视频文件 自动横屏 全屏播放
- 处理solr时遇到的问题
- java类型转换的例子
- 2G、3G要退出历史舞台了?为何3G比2G淘汰更快?