【算法】快速排序算法的编码和优化
参考资料
快速排序算法的编码描述
快排的基本思路

- 先通过第一趟排序,将数组原地划分为两部分,其中一部分的所有数据都小于另一部分的所有数据。原数组被划分为2份
- 通过递归的处理, 再对原数组分割的两部分分别划分为两部分,同样是使得其中一部分的所有数据都小于另一部分的所有数据。 这个时候原数组被划分为了4份
- 就1,2被划分后的最小单元子数组来看,它们仍然是无序的,但是! 它们所组成的原数组却逐渐向有序的方向前进。
- 到最后, 数组被划分为多个由一个元素或多个相同元素组成的单元, 这时候整个数组就有序了
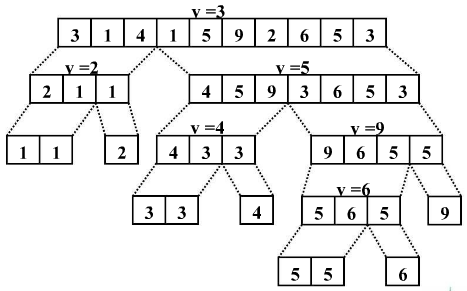
3 1 4 1 5 9 2 6 5 3
1 1 2 3 3 4 5 5 6
快排的实现步骤

下面我就只讲解1和2步骤, 而在1,2中,关键在于如何实现“划分”
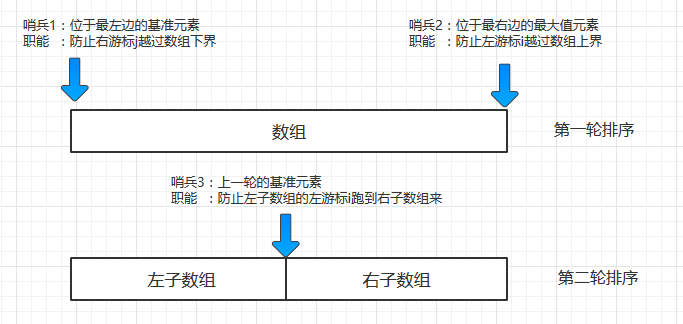
切分的关键点: 基准元素, 左游标和右游标
划分的过程有三个关键点:“基准元素”, “左游标” 和“右游标”。
- 基准元素:它是将数组划分为两个子数组的过程中, 用于界定大小的值, 以它为判断标准, 将小于它的数组元素“划分”到一个“小数值数组”里, 而将大于它的数组元素“划分”到一个“大数值数组”里面。这样,我们就将数组分割为两个子数组, 而其中一个子数组里的元素恒小于另一个子数组里的元素
- 左游标: 它一开始指向待分割数组最左侧的数组元素。在排序过程中,它将向右移动
- 右游标: 它一开始指向待分割数组最右侧的数组元素。在排序过程中,它将向左移动
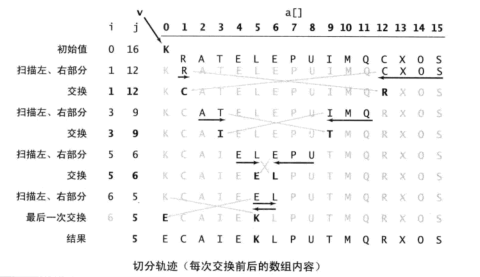
一趟切分的具体过程
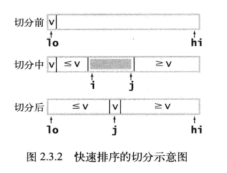
- “基准元素v是怎么选的?”
- 游标i,j的移动的过程中发生了什么事情(比如元素交换)?,
- 为什么左右游标相遇时一趟切分就完成了?
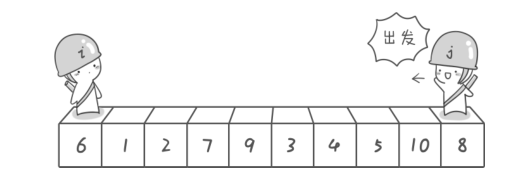
- 左游标向右扫描, 跨过所有小于基准元素的数组元素, 直到遇到一个大于或等于基准元素的数组元素, 在那个位置停下。
- 右游标向左扫描, 跨过所有大于基准元素的数组元素, 直到遇到一个大于或等于基准元素的数组元素,在那个位置停下
- 左右游标没有相遇
- 左右游标相遇了
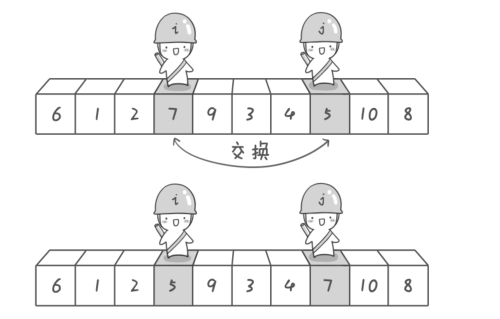
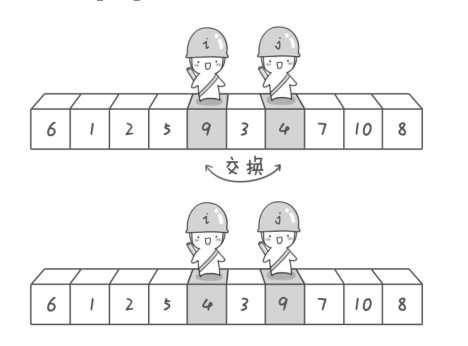
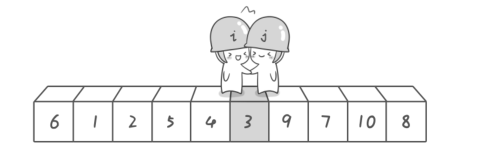
【注意】这里你可能会问: 在我们制定的规则里, 左游标先扫描和右游标先扫描有区别吗? (如果你这样想的话就和我想到一块去了...嘿嘿),因为就上图而言,两种情况下一趟排序中两个游标相遇的位置是不同的(一般而言,除非相遇位置的下方的元素刚好和基准元素相同):
- 如果右游标先扫描,左右游标相遇的位置应该是3上方(图示)
- 但如果左游标先扫描, 左右游标相遇的位置却是9上方
6 1 2 5 4 3 9 7 10 8
1 2 5 4 3 6 9 7 10 8

总结一趟排序的过程
快速排序代码展示
具体的代码
// 交换两个数组元素
private static void exchange(int [] a , int i, int j) {int temp = a[i];a[i] = a[j];a[j] = temp;
}private static int partition (int[] a, int low, int high) {int i = low, j = high+1; // i, j为左右扫描指针 PS: 思考下为什么j比i 多加一个1呢?int pivotkey = a[low]; // pivotkey 为选取的基准元素(头元素)while(true) { while (a[--j]>pivotkey) { if(j == low) break; } // 右游标左移while(a[++i]<pivotkey) { if(i == high) break; } // 左游标右移if(i>=j) break; // 左右游标相遇时候停止, 所以跳出外部while循环else exchange(a,i, j) ; // 左右游标未相遇时停止, 交换各自所指元素,循环继续
}exchange(a, low, j); // 基准元素和游标相遇时所指元素交换,为最后一次交换return j; // 一趟排序完成, 返回基准元素位置
}private static void sort (int [] a, int low, int high) {if(high<= low) { return; } // 终止递归int j = partition(a, low, high); // 调用partition进行切分sort(a, low, j-1); // 对上一轮排序(切分)时,基准元素左边的子数组进行递归sort(a, j+1, high); // 对上一轮排序(切分)时,基准元素右边的子数组进行递归
}对切分函数partition的解读
while (a[--j]>pivotkey) { ... }先将右游标左移一位,然后判断指向的数组元素和基准元素pivotkey比较大小, 如果该元素大于基准元素, 那么循环继续,j再次减1,右游标再次左移一位...... (循环体可以看作是空的)
if(i>=j) break;
从i < j到 i == j 代表了“游标未相遇”到“游标相遇”的过度过程,此时跳出外部循环, 切分已接近完成,紧接着通过 exchange(a, low, j) 交换基准元素和相遇游标所指元素的位置, low是基准元素的位置(头部元素), j是当前两个游标相遇的位置
while (a[--j]>pivotkey) { if(j == low) break; } // 右游标左移中,当随着右游标左移,到j = low + 1的时候,有 a[--j] == pivotkey为true(两者都是基准元素),自动跳出了while循环,所以就不需要在循环体里再判断 j == low 了
int i = low, j = high+1
结合下面两个While循环中的判断条件:
while (a[--j]>pivotkey) { ... }
while (a[++i]<pivotkey) { ... } 可知道, 左游标 i 第一次自增的时候, 跳过了对基准元素 a[low] 所执行的 a[low] < pivotkey判断, 这是因为在我们当前的算法方案里,基准元素和左游标初始所指的元素是同一个,所以没有执行a[low]>pivotke这个判断的必要。所以跳过( 一开始a[low] == pivotkey,如果执行判断那么一开始就会跳出内While循环,这显然不是我们希望看到的)
对主体函数sort的解读
sort(a, low, j-1); sort(a, j+1, high);
进行下一轮递归,设置j -1 和j + 1 是因为上一轮基准元素的位置已经是有序的了,不要再纳入下一轮递归里
public class QuickSort {// 交换两个数组元素private static void exchange(int [] a , int i, int j) {int temp = a[i];a[i] = a[j];a[j] = temp;}private static int partition (int[] a, int low, int high) {int i = low, j = high+1; // i, j为左右扫描指针 PS: 思考下为什么j比i 多加一个1呢?int pivotkey = a[low]; // pivotkey 为选取的基准元素(头元素)while(true) { while (a[--j]>pivotkey) { if(j == low) break; } // 右游标左移while(a[++i]<pivotkey) { if(i == high) break; } // 左游标右移if(i>=j) break; // 左右游标相遇时候停止, 所以跳出外部while循环else exchange(a,i, j) ; // 左右游标未相遇时停止, 交换各自所指元素,循环继续
}exchange(a, low, j); // 基准元素和游标相遇时所指元素交换,为最后一次交换return j; // 一趟排序完成, 返回基准元素位置
}private static void sort (int [] a, int low, int high) {if(high<= low) { return; } // 当high == low, 此时已是单元素子数组,自然有序, 故终止递归int j = partition(a, low, high); // 调用partition进行切分sort(a, low, j-1); // 对上一轮排序(切分)时,基准元素左边的子数组进行递归sort(a, j+1, high); // 对上一轮排序(切分)时,基准元素右边的子数组进行递归
}public static void sort (int [] a){ //sort函数重载, 只向外暴露一个数组参数sort(a, 0, a.length - 1);}
}public class Test {public static void main (String [] args) {int [] array = {4,1,5,9,2,6,5,6,1,8,0,7 };QuickSort.sort(array);for (int i = 0; i < array.length; i++) {System.out.print(array[i]);}}
}01124556789
优化点一 —— 切换到插入排序
if(high<= low) { return; }if(high<= low + M) { Insertion.sort(a,low, high) return; } // Insertion表示一个插入排序类 private static void sort (int [] a, int low, int high) {if(high<= low + 10) { Insertion.sort(a,low, high) return; } // Insertion表示一个插入排序类int j = partition(a, low, high); // 调用partition进行切分sort(a, low, j-1); // 对上一轮排序(切分)时,基准元素左边的子数组进行递归sort(a, j+1, high); // 对上一轮排序(切分)时,基准元素右边的子数组进行递归}优化点二 —— 基准元素选取的随机化
- 排序前打乱数组的顺序
- 通过随机数保证取得的基准元素的随机性
- 三数取中法取得基准元素(推荐)
public static void sort (int [] a){StdRandom.shuffle(a) // 外部导入的乱序算法,打乱数组的分布sort(a, 0, a.length - 1);
} private static int getRandom (int []a, int low, int high) {int RdIndex = (int) (low + Math.random()* (high - low)); // 随机取出其中一个数组元素的下标exchange(a, RdIndex, low); // 将其和最左边的元素互换return a[low];
}private static int partition (int[] a, int low, int high) {int i = low, j = high+1; // i, j为左右扫描指针 PS: 思考下为什么j比i 多加一个1呢?int pivotkey = getRandom (a, low, high); // 基准元素随机化while(true) { while (a[--j]>pivotkey) { if(j == low) break; } // 右游标左移while(a[++i]<pivotkey) { if(i == high) break; } // 左游标右移if(i>=j) break; // 左右游标相遇时候停止, 所以跳出外部while循环else exchange(a,i, j) ; // 左右游标未相遇时停止, 交换各自所指元素,循环继续
}exchange(a, low, j); // 基准元素和游标相遇时所指元素交换,为最后一次交换return j; // 一趟排序完成, 返回基准元素位置}package mypackage;public class QuickSort {// 交换两个数组元素private static void exchange(int [] a , int i, int j) {int temp = a[i];a[i] = a[j];a[j] = temp;}// 选取左中右三个元素,求出中位数, 放入数组最左边的a[low]中private static int selectMiddleOfThree(int[] a, int low, int high) {int middle = low + (high - low)/2; // 取得位于数组中间的元素middle if(a[low]>a[high]) { exchange(a, low, high); //此时有 a[low] < a[high]
}if(a[middle]>a[high]){ exchange(a, middle, high); //此时有 a[low], a[middle] < a[high]
}if(a[middle]>a[low]) {exchange(a, middle, low); //此时有a[middle]< a[low] < a[high]
}return a[low]; // a[low]的值已经被换成三数中的中位数, 将其返回
}private static int partition (int[] a, int low, int high) {int i = low, j = high+1; // i, j为左右扫描指针 PS: 思考下为什么j比i 多加一个1呢?int pivotkey = selectMiddleOfThree( a, low, high);while(true) { while (a[--j]>pivotkey) { if(j == low) break; } // 右游标左移while(a[++i]<pivotkey) { if(i == high) break; } // 左游标右移if(i>=j) break; // 左右游标相遇时候停止, 所以跳出外部while循环else exchange(a,i, j) ; // 左右游标未相遇时停止, 交换各自所指元素,循环继续
}exchange(a, low, j); // 基准元素和游标相遇时所指元素交换,为最后一次交换return j; // 一趟排序完成, 返回基准元素位置
}private static void sort (int [] a, int low, int high) {if(high<= low) { return; } // 当high == low, 此时已是单元素子数组,自然有序, 故终止递归int j = partition(a, low, high); // 调用partition进行切分sort(a, low, j-1); // 对上一轮排序(切分)时,基准元素左边的子数组进行递归sort(a, j+1, high); // 对上一轮排序(切分)时,基准元素右边的子数组进行递归
}public static void sort (int [] a){ //sort函数重载, 只向外暴露一个数组参数sort(a, 0, a.length - 1);}
}优化点三 —— 去除不必要的边界检查
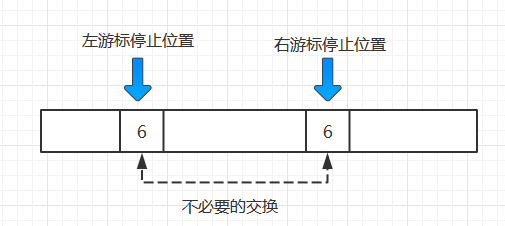
while(a[++i]<pivotkey) { if(i == high) break; }我们只要尝试把这一作用交给a[++i]<pivotkey去完成, 不就可以把 if(i == high) break; 给去掉了吗?
public class QuickSort {// 交换两个数组元素private static void exchange(int [] a , int i, int j) {int temp = a[i];a[i] = a[j];a[j] = temp;}//将原数组里最大的元素移到最右边, 构造“哨兵”private static void Max(int [] a) {int max = 0; for(int i = 1; i<a.length;i++) {if(a[i]>a[max]) {max = i;}}exchange(a, max, a.length -1);}private static int partition (int[] a, int low, int high) {int i = low, j = high+1; // i, j为左右扫描指针 PS: 思考下为什么j比i 多加一个1呢?int pivotkey = a[low]; // pivotkey 为选取的基准元素(头元素)while(true) { while (a[--j]>pivotkey) { } // 空的循环体while(a[++i]<pivotkey) { } // 空的循环体if(i>=j) break; // 左右游标相遇时候停止, 所以跳出外部while循环else exchange(a,i, j) ; // 左右游标未相遇时停止, 交换各自所指元素,循环继续 }exchange(a, low, j); // 基准元素和游标相遇时所指元素交换,为最后一次交换return j; // 一趟排序完成, 返回基准元素位置
}private static void sort (int [] a, int low, int high) {if(high<= low) { return; } // 当high == low, 此时已是单元素子数组,自然有序, 故终止递归int j = partition(a, low, high); // 调用partition进行切分sort(a, low, j-1); // 对上一轮排序(切分)时,基准元素左边的子数组进行递归sort(a, j+1, high); // 对上一轮排序(切分)时,基准元素右边的子数组进行递归
}public static void sort (int [] a){ //sort函数重载, 只向外暴露一个数组参数Max(a); // 将原数组里最大元素移到最右边, 构造“哨兵”sort(a, 0, a.length - 1);}
}
优化点四 —— 三切分快排(针对大量重复元素)
- 左游标向右扫描, 跨过所有小于基准元素的数组元素, 直到遇到一个大于或等于基准元素的数组元素, 在那个位置停下。
- 右游标向左扫描, 跨过所有大于基准元素的数组元素,直到遇到一个大于或等于基准元素的数组元素,在那个位置挺停下
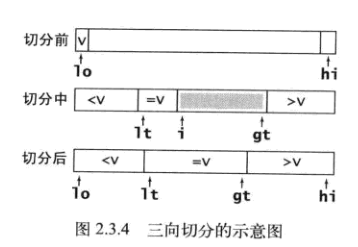
package mypackage;public class Quick3way {public static void exchange(int [] a , int i, int j) {int temp = a[i];a[i] = a[j];a[j] = temp;}public static void sort (int [] a, int low, int high) {if(low>=high) { return; }int lt = low, gt = high, i =low+1;int v = a[low];while(i<=gt) {int aValue = a[i];if(aValue>v) { exchange(a, i, gt--); }else if(aValue<v) { exchange(a, i++, lt++); }else{ i++; }}sort(a, low, lt-1);sort(a, gt+1, high);}public static void sort (int [] a) {sort(a, 0, a.length - 1);}
}

其实啊,我只是把你们喝咖啡的时间,都用来喝啤酒而已
【算法】快速排序算法的编码和优化相关推荐
- 十大经典排序算法-快速排序算法详解
十大经典排序算法 十大经典排序算法-冒泡排序算法详解 十大经典排序算法-选择排序算法详解 十大经典排序算法-插入排序算法详解 十大经典排序算法-希尔排序算法详解 十大经典排序算法-快速排序算法详解 十 ...
- 用openAI写个js的排序算法(快速排序算法)
文章目录 一.生成JS快速排序算法 二.openai还会给出调用方法 一.生成JS快速排序算法 这是一个通用的 JavaScript 排序算法.它使用的是快速排序算法. function sort(a ...
- 排序算法 | 快速排序算法原理及实现和优化(一)
快速排序是对冒泡排序的一种改进,由 C.A.R.Hoare(Charles Antony Richard Hoare,东尼·霍尔)在 1962 年提出. 快速排序的基本思想是:通过一趟排序将要排序的数 ...
- 排序算法——快速排序算法
快速排序的基本思想: 通过一趟排序将待排记录分隔成独立的两部分,一部分记录的关键字比基准值小,一部分记录的关键字比基准值大,然后再对这两部分进行同样操作. 1.快速排序递归算法 //快速排序,递归 i ...
- 快速排序 算法 详解 及 深度优化
下面简介经典算法 快速排序算法 实现及优化. (欢迎大家指点,继续提出优化的方法,共同提高) 基本思想:(以按从小到大排序为例说明)通过多次的排序,每次的排序均将要排序的数组分为两部分,前一部分均比 ...
- 快速排序算法(基于Java实现)
title: 快速排序算法(基于Java实现) tags: 快速排序算法 快速排序算法的原理与代码实现: 一.快速排序算法的原理 快排算法的思想是: 如果需要排序数组中下标从p到r之间的一组数据,我们 ...
- python实现快排算法_Python实现快速排序算法
Python实现快速排序算法 快速排序算法是一种基于交换的高效的排序算法,由C.R.A.Hoare于1962年提出,是一种划分交换排序.它采用了一种分治的策略,通常称其为分治法(Divide and ...
- python快速排序代码_Python实现快速排序算法
原标题:Python实现快速排序算法 Python实现快速排序算法 快速排序算法是一种基于交换的高效的排序算法,由C.R.A.Hoare于1962年提出,是一种划分交换排序.它采用了一种分治的策略,通 ...
- Go语言编程:Go语言实现快速排序算法
前言 今天用Go语言实现下经典排序算法--快速排序算法.主要是学习了Go语言,得用它来干点事情嘛,就用快速排序来练手.在Go语言语法方面,主要用到 切片数组,for循环(Go语言没有while循环), ...
- 排序算法:快速排序算法实现及分析(递归形式和非递归形式)
快速排序算法介绍 从名字上就可以看出快速排序算法很嚣张,直接以快速命名.确实快速排序 的确很快速,被列为20世纪十大算法之一.程序员难道不应该掌握么.快速排序(Quick Sort)的基本思想是:通过 ...
最新文章
- OC学习篇之---对象的拷贝
- boost::make_tuple用法的测试程序
- python islower函数_python字符串是否是小写-python 字符串小写-python islower函数-python islower函数未定义-嗨客网...
- 0004-Median of Two Sorted Arrays(寻找两个正序数组的中位数)
- 服务器(Windows镜像)自建git服务器超详细教程
- mysql+修改字段长度语句,mysql修改字段长度的sql语句分享
- 利用PYTHON计算偏相关系数(Partial correlation coefficient)
- U盘数据丢失后怎样恢复
- LFI获取WENSHELL
- 【论文解读】MacBERT: 中文自然语言预训练模型
- Design Compiler工具学习笔记(7)
- linux 获取当前工作路径
- wps批量将文档括号内的字符串修改颜色
- 餐饮app开发市场前景如何?行业竞争激烈吗?
- 力扣904(滑动窗口、哈希)
- 1024凑数篇之程序员职业生涯问答
- %在c语言中起什么作用
- 跨平台框架这么多, 老夫无可奈何!
- jquery 同源下载图片到本地
- Jetson-Xavier-NX使用教程(这里说插上烧好镜像的SD卡上电就可以直接用了)