python爬取贴吧所有帖子-通过python爬取贴吧数据并保存为word
前言
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
日前,在学习中思考,如何整理一份贴吧历史数据出来,从中找寻当年玩贴吧的回忆呢。
于是就有了想从贴吧爬取数据的想法,此代码的由来就是如此。
事前准备
应先安装pycharm,此处使用的是社区版用于个人学习。如商业行为请支持正版pycharm套件。
检查需求
获取贴吧列表的真实链接
分析锁定回复量为筛选值,筛选出指定回复量以上的帖子
将指定帖子的URL导出为表格形式保存
通过URL读取帖子数据,保存一楼数据并存为word文件命名为帖子名(前5个字符).docx
开工
特别注意本文使用的是python3.7,无法直接从pycharm中add进docx包,否则会报错,请务必使用手动下载安装,原因及解决方法如下
解决方法:
1.命令行 卸载docx,pip uninstall docx
2.下载 python_docx-0.8.10-py2.py3-none-any.whl 下载地址
3. 命令行输入pip install python_docx-0.8.10-py2.py3-none-any.whl使用新的docx包
文件名应与下载的时候一致,也许之后会再进行更新
代码部分
获取链接模板及输出贴吧列表
打开浏览器,按下F12,打开贴吧,搜索一个贴吧,这边以"希灵帝国"为例
打开后可以看到,该帖吧首页的地址是:https://tieba.baidu.com/f?ie=utf-8&kw=%E5%B8%8C%E7%81%B5%E5%B8%9D%E5%9B%BD&fr=search
通过浏览器的翻译,我们可以得知:希灵帝国被浏览器翻译成%E5%B8%8C%E7%81%B5%E5%B8%9D%E5%9B%BD,所以这串其实就是希灵帝国四个字的unicode显示,所以得出了贴吧名字在贴吧链接里占用的模块。
该贴吧第四页的地址是:https://tieba.baidu.com/f?kw=%E5%B8%8C%E7%81%B5%E5%B8%9D%E5%9B%BD&ie=utf-8&pn=150
重新点回第一页:https://tieba.baidu.com/f?kw=%E5%B8%8C%E7%81%B5%E5%B8%9D%E5%9B%BD&ie=utf-8&pn=0
点第二页:https://tieba.baidu.com/f?kw=%E5%B8%8C%E7%81%B5%E5%B8%9D%E5%9B%BD&ie=utf-8&pn=50
得出规律:https://tieba.baidu.com/f?kw=贴吧名字&ie=utf-8&pn=页码
并且页码是0开始,50为一跳
所以这边可以定义读取的URL模板是:"https://tieba.baidu.com/f?kw=" + 贴吧名字 + "&ie=utf-8&pn={}"
{}是代表占位符,后续读取不同页面的时候就占用该占位符位置
然后我们就可以进行爬取页面数据的函数编写了
此处这个函数,主要功能是用来获取到贴吧列表页面的数据# -*- coding:UTF-8 -*-
#设置间隔的
import time
#抓数据的
import requests
from bs4 import BeautifulSoup
#把数据弄能看的
import numpy as np
import pandas as pd
import docx
import xlrd
#上述是后面会用到的所有包,后续代码中不再另外列出
tiebaname = str(input("请输入贴吧名:")) #定义贴吧名字,用户直接输入
template_url = "https://tieba.baidu.com/f?kw=" + tiebaname + "&ie=utf-8&pn={}" #生成get请求的URL模板
def search_n_pages(n):
#爬取n页的数据,确认爬取页数
target = []
#发起n次的get请求
for i in range(n):
#跟踪进度
print('页数:',i+1)
#按照浏览贴吧的自然行为,每一页50条
target_url = template_url.format(50*(i))
res = requests.get(target_url)
#转为bs对象
soup = BeautifulSoup(res.text,'html.parser')
#获取该页帖子列表
page_lst = soup.find_all(class_='j_thread_list clearfix')
#该页信息保存到target里
target.extend(extra_from_one_page(page_lst))
#休息2秒再访问
time.sleep(2)
return target
分析筛选关键词及生成表单
然后有了贴吧页面的数据以后,就需要对页面数据进行筛选,筛选出需要的数据。
对应需求,筛选的关键词应是:回复量
所以这边,打开一个贴吧列表页面,对着回复量进行右键--审查元素可以找到对应的
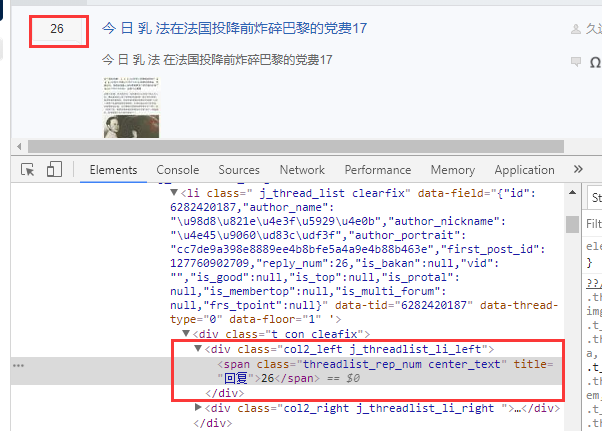
找到class值 这边看到class值是 class="threadlist_rep_num center_text" 记录下来备用,待会抓取数据的时候就要使用到这个
再然后,要抓取对应的标题和URL,右键帖子标题,审查元素,就显示出了具体的细节
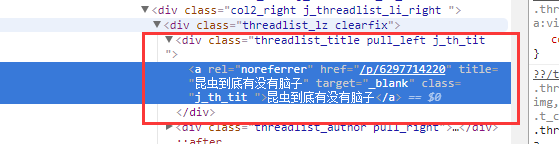
其中可以看到class值为class="j_th_tit ",而悄咪咪打开帖子对比一下,你会发现,帖子地址其实就是贴吧前缀+href的值 如图打开就是https://tieba.baidu.com/p/6297714220,其实就是https://tieba.baidu.com + a['href']
于是,回复量、标题、URL都获取到了,接下来就是将他们的数据爬取下来保存了
则这一段大概可以这么写:# 设置回复量阈值 判断输入的回复量是否为int类型,不是的话重新要求输入
while True:
try:
clicknum = int(input("请输入要爬取的回复数(超过该回复数的才会被爬取):"))
break
except ValueError:
print("请输入数字!")
M = clicknum
def extra_from_one_page(page_lst):
'''从一页中提取 帖子'''
# 临时列表保存字典数据,每一个帖子都是一个字典数据
tmp = []
for i in page_lst:
#判断是否超过阈值(这边的“threadlist_rep_num”实际上是页面上显示的回复量)
if int(i.find(class_='threadlist_rep_num center_text').text) > M:
dic = {}
#点击量
dic['num'] = int(i.find(class_='col2_left j_threadlist_li_left').text)
#帖子名称
dic['name'] = i.find(class_='j_th_tit').text
#帖子地址
dic['address'] = 'https://tieba.baidu.com' + i.find(class_='j_th_tit').a['href']
tmp.append(dic)
return tmp
#爬取贴吧前n页数据 如果输入的不是int类型 则要求重新输入
while True:
try:
num = int(input("请输入要爬取的页数:"))
break
except ValueError:
print("请输入数字!")
d = search_n_pages(num)
# 转化为pandas.DataFrame对象
data = pd.DataFrame(d)
# 导出到excel表格
xlsxname = tiebaname + '.xlsx'
data.to_excel(xlsxname)
这样就是生成了表格文件了
从表单中读取URL并生成保存为WORD文档
接下来是要从表格中读取URL,然后去打印到word里并保存文件
首先先读取上一步骤生成的表单'xlsxname',从中筛选出关键列'address',然后读取整列,并保存为列表(execl_list)#从生成的表格中读取url列表,使url_write_word函数可以有读取用的url_list
def execl_read_url(execl_list):
#打开指定表格
rbook = xlrd.open_workbook(execl_list)
rbook.sheets()
rsheet = rbook.sheet_by_index(0)
tmp = []
#遍历表格每一行
for row in rsheet.get_rows():
#保留指定的列数数据
product_column = row[3]
product_value = product_column.value
#去掉标题栏,将剩下的url保存为一个列表
if product_value != 'address':
r = str(row[3])
r1 = r[6:-1]
tmp.append(r1)
return tmp
#读取表格,生成url列表
execl_list = xlsxname
#将url列表保存到url_list
url_list = execl_read_url(execl_list)
手中有一批的URL可以直接读取了,那接着要怎么去获取他们的页面里的数据呢?
当然是通过访问他们来获得数据。
打开随便一个帖子,对着标题进行审查元素,如下图
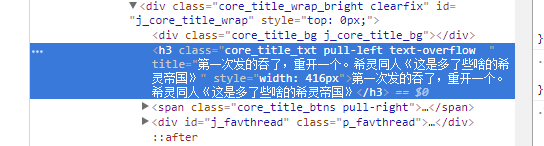
可以看到
而抓取数据的话,就先抓取一楼就好,对着一楼进行审查元素,如下图

抓取到的class值是class="d_post_content j_d_post_content " 留存备用
接着有了这两个值,就可以将网页数据中想要的部分筛选出来并保存了
调取之前生成的url列表,然后遍历列表的每个URL,逐一访问筛选出要保存的数据,通过docx库进行创建word文档并写入保存,这部分就完成了#遍历url列表,访问并读取数据保存为word
def url_write_word(url_list):
tmp = '文件生成完成'
s = 1
#遍历URL列表
for i in url_list:
tmp1 = []
print('生成文件',s)
s += 1
i = str(i)
#读取网页
res = requests.get(i)
soup = BeautifulSoup(res.text,'html.parser')
url_title = soup.find(class_='core_title_txt pull-left text-overflow').text
t1 = url_title
t1 = t1[0:7] + '.docx'
#创建一个word文档
doc = docx.Document()
url_word = soup.find(class_='d_post_content j_d_post_content').text
t2 = url_word
#将数据写入word
doc.add_paragraph(i)
doc.add_paragraph(t2)
#保存文档
doc.save(t1)
return tmp
#生成word文档
url_write_word(url_list)
小结
本文使用了如下几个知识点:使用time模块进行程序间隔循环
使用requests包进行get网页数据
使用BeautifulSoup库进行整理筛选网页数据
使用pandas包进行整理数据
使用xlrd模块进行读取表格
使用docx包进行创建保存文档
参考资料
python爬取贴吧所有帖子-通过python爬取贴吧数据并保存为word相关推荐
- python爬贴吧回复_通过python爬取贴吧数据并保存为word
前言 Python是一种跨平台的计算机程序设计语言.是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的.大型项目的开发 ...
- python百度贴吧怎么爬取最早的帖子_Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python #_*_coding:utf-8_*_ import urllib import ur ...
- python爬取贴吧所有帖子-Python爬虫实例(一)爬取百度贴吧帖子中的图片
程序功能说明:爬取百度贴吧帖子中的图片,用户输入贴吧名称和要爬取的起始和终止页数即可进行爬取. 思路分析: 一.指定贴吧url的获取 例如我们进入秦时明月吧,提取并分析其有效url如下 ?后面为查询字 ...
- Python爬虫实战之爬取百度贴吧帖子
Python爬虫实战之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的 ...
- python爬虫(13)爬取百度贴吧帖子
爬取百度贴吧帖子 一开始只是在网上看到别人写的爬取帖子的文章,然后自己就忍不住手痒自己锻炼一下, 然后照着别人的写完,发现不太过瘾, 毕竟只是获取单个帖子的内容,感觉内容稍显单薄,然后自己重新做了修改 ...
- python爬取虎扑论坛帖子数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 python免费学习资 ...
- python百度贴吧怎么爬取最早的帖子_【Python爬虫教学】百度篇·手把手教你抓取百度贴吧任意贴吧指定范围页数内的源代码...
开门见山. 懒癌一犯,能拖一天是一天. 好了,亲爱的小伙伴们,我又回来了!今天带来的是抓取输入的任意贴吧,抓取指定范围页数内的源代码. 工具: 依旧是 PyCharm 和 Google 浏览器,pyt ...
- Python爬虫: 单网页 所有静态网页 动态网页爬取
Python爬虫: 单网页 所有静态网页 动态网页爬取 前言:所有页代码主干均来自网上!!!感谢大佬们. 其实我对爬虫还挺感兴趣的,因为我玩instagram(需要科学上网),上过IG的人都知道IG虽 ...
- java 百度贴吧 爬虫,爬取百度贴吧帖子
依然是参考教程 Python爬虫实战一之爬取百度贴吧帖子.作者崔庆才写了很多关于Python爬虫的文章,大家有兴趣的话可以去他的个人博客静觅学习. 这次将爬取的数据写入了文本文件中,并用到了re模块中 ...
最新文章
- VirtualBox Ubuntu虚拟机串口编程
- python中for x in range_python教程:对 [lambda x: x*i for i in range(4)] 理解
- VC 打开目录对话框
- 前端学习(221):字体属性
- 怎么设置linux端口权限,Linux下设置端口权限的系统调用—ioperm和iopl
- 一张图来帮你理解 SOA(转发)
- 【干货】Python玩转各种多媒体,视频、音频到图片
- 使用 IntraWeb (10) - CSS
- mysql损坏打不开_mysql 断电导致表打不开解决方案
- vfp邮件.html格式,VFP 实现自动发邮件代码
- xilinx低延时视频编解码方案
- 语法长难句-----状语与状语从句
- 数据可视化-制作交易收盘价
- 硬件电路设计之如何设计一个STM32最小系统?
- java银联在线支付开发_银联在线支付案例代码
- VMware虚拟机运行时报The CPU has been disabled by the guest operating system错误的解决方法
- 预警|使用方维、微吼等系统直播平台警惕××××××
- 【每日早报】20200113
- 传奇如何读取服务器信息,传奇服务器修改之命令服务脚本详细使用方法介绍
- Android中文API文档