大数据处理——Hadoop解析(一)
概述
这个时代被称之为大数据时代,各行各业生产的数据量呈现爆发性增长,并且基于这些爆发性增长的数据做深层次的数据挖掘、分析。因此,我们可以很容易的感觉到,在这样一个大数据的时代,我们很多做事情的方法正在发生了改变。例如,基于大数据分析可以做疾病预测控制;基于大数据分析可以做交通流量预测控制;基于大数据分析可以做大型系统故障诊断预测;基于大数据分析可以做客户消费推荐。可以说,大数据时代可以解决很多以前非常难以解决的问题。可以这样讲,在这样一个时代,大数据可以让我们的生活变得更加美好。
突如其来的大数据时代,对技术界产生了巨大冲击。其最大的问题是如何存储如此巨大的数据量?如何处理如此巨大的数据量。针对这个问题,在Google的商业化系统之上,诞生了开源大数据处理系统Hadoop。
2003年Google发表了第一篇关于云计算的核心技术文章GFS,当时,Apache的技术团队意识到,GFS这种架构可以很好的解决网页搜索引擎建立过程中产生的海量文件的难题。因此,参考了GFS的技术架构,完成了一套大数据文件系统,并将之开源。该文件系统后来演变成Hadoop的核心项目HDFS。2004年Google再次发表云计算核心技术文章Mapreduce,解决了大型分布式计算中的编程模型问题。随后,Mapreduce的思想被应用于Hadoop的前身项目,并且开源。2006年,雅虎将Hadoop项目从Nutch搜索引擎项目中独立,成为Apache的一个单独子项目。自此,Hadoop项目得以蓬勃发展。
截止到2013年10月,Hadoop 2.2.0版本已经成功发布。Facebook、阿里巴巴、百度和腾讯都采用Hadoop部署了大数据处理平台。下面对Hadoop项目中的关键系统进行剖析。
分布式文件系统
在大数据应用的背景下,文件存储有以下几个方面的特点:
1,海量数据存储。在大数据应用的环境里,无论是文件的数量还是数据存储规模都是十分巨大的。因此,如果采用传统存储的模式,需要构建十分庞大的系统,并且需要传统存储支持十分灵活的可扩展性。因为,在大数据时代,存储的可扩展性显得十分重要,数据量在不断增加,存储的规模也需要随时跟进,因此,存储的可扩展性是面向海量数据存储的必然选择。传统存储基本都是面向单机高性能、单机高容量。而大数据存储需要面向低成本可扩扩展性,来应对不断增加的海量存储需求。因此,传统存储在大数据环境中遇到了瓶颈,因为客户的需求发生了变化。
2,大文件存储。在大数据应用环境中,存储的文件基本以大文件为主。这是一个十分重要的应用特征。面向Primary Storage领域的传统存储在设计的时候,主要考虑小文件的读写优化,因此,传统存储在大数据应用环境中,显得很是浪费,主要专注的一面没有很好的被应用,而用户需求的一面没有被重视。
3,读多写少的文件存储。在大数据应用环境中,读请求比写请求要多的多。尤其在互联网领域,写请求不是很多,但是读请求的数量十分巨大,因此,在读多写少的应用需求下,如何优化存储设计是需要考虑的。
4,并发访问。在大数据应用环境下,应用客户端的数量是十分巨大的,因此,如何避免文件系统数据访问瓶颈点,增强多客户并发访问的能力是分布式文件系统设计需要考虑的重要问题。
为了满足这种需求,Google提出了GFS的分布式文件系统架构,Hadoop分布式文件系统采用了该架构。这种分布式文件系统的结构如下所示:
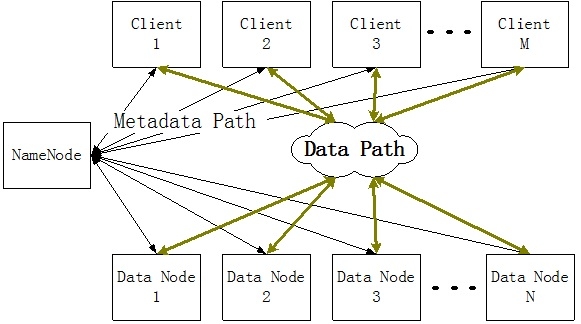
从结构来讲,这种分布式文件系统是比较简单的。其主要分成两大部分,第一部分是用来管理文件目录结构以及文件元数据的控制器,这个控制器被称之为 NameNode;第二部分是用来存储数据的DataNode。当客户端需要访问一个文件的时候,其首先需要访问NameNode获取文件信息以及数据分布特征。从NameNode获取这些信息之后,后期访问文件的数据过程就不会经过NameNode,客户端和DataNode进行直接通信。这种分布式文件系统的数据访问属于“带外模式”,因此,可以具有很高的并发行,不同的客户端可以访问不同的DataNode。
这种分布式文件系统的一个缺点在于处理小文件。因为每次文件访问操作都会访问NameNode。如果处理小文件,那么NameNode将会被经常访问,因此,NameNode将会成为整个系统的瓶颈。幸运的是,在大数据应用环境下,主要的处理的是大文件,因此,这种分布式文件系统架构可以满足大数据应用需求。
这种分布式文件系统具有很强的存储可扩展性。如果用户想要扩展存储容量,只需要增加一个DataNode就可以了,并且将这个DataNode加入到NameNode中进行管理。DataNode的扩展对于客户端而言是透明的。DataNode的扩展一方面会扩展存储容量,另一方面还可以扩展系统整体数据吞吐量。这种架构最大的问题在于拥有潜在瓶颈点NameNode,采用NameNode最大的好处是降低了设计实现的复杂度。
NameNode是整个系统的元数据服务器,因此,性能和单点故障成为NameNode设计过程中需要考虑的首要问题。为了提高性能,NameNode可以采用性能比较高的服务器,并且可以采用集群的方式提高元数据处理的性能。另外,为了避免单点故障,可以采用HA的方式增强NameNode的可靠性。为此,很多厂商提出了各种HA的解决方案,保证NameNode可以在最短的时间内Failover,提高整个系统的服务质量和可靠性。NameNode的设计优化是Hadoop分布式文件系统得以应用的重点。
数据可靠性也是Hadoop分布式文件系统需要考虑的问题。为了降低整个系统的成本,DataNode可以采用成本低廉的服务器搭建。在这些服务器中可以不采用传统存储中的RAID解决方案,这样可以尽最大可能的降低单点存储成本。在这种没有采用RAID的分布式文件存储系统中如何保证数据可靠性呢?Hadoop的思路和GFS是相同的,采用多份复制的策略保证数据可靠性。普通的文件采用3份复制的策略,重要的文件采用6份复制的策略。在写文件的时候,数据被写入一个DataNode,然后这个DataNode再将复制数据写入其他DataNode。多份复制的好处是实现简单,最为重要的是还可以将读写进行分离,并且可以并发读请求。多份复制的缺点也是显而易见的,大量的数据复制导致存储空间的利用率大为降低。为了提高数据存储空间利用率,在分布式存储系统中引入Erasure Code。Erasure Code可以实现类似传统RAID算法效果的数据冗余,但是,需要DataNode具有一定的数据计算能力,因此,该算法的引入会对整个系统的写性能造成一定影响。另外,由于Erasurce Code将数据拆分,采用数据冗余编码的方式达到增强数据可靠性的目的,因此,无法起到多份复制方法中读写分离、读并发的目的,难免对读性能也会造成一定影响。存储空间利用率和性能是互斥的,因此如何平衡这两方面的需求是设计需要考虑的。Facebook在Erasure Code方面做了很多工作,2013年发表了一篇针对Erasurce Code在大数据中应用的一篇文章《XORing Elephants: Novel Erasurce Codes for Big Data》。
Hadoop分布式文件系统是在大数据存储系统中一种常用的结构,参照这种结构,淘宝开发了TFS用于存储淘宝电商系统中的图片、视频文件,并且针对淘宝自身的特点进行了优化。其最大的优化包括:
1)简化NameNode文件目录结构。淘宝的存储文件没有必要采用复杂的目录树去管理,扁平的结构就可以满足要求,每个文件可以使用一个64位的ID来描述即可。
2)淘宝中的图片有大有小,对于这种小文件首先将其合并成一个大文件,最后进行大文件存储。这一个思路和Facebook的Haystack系统是类似的。
Hadoop分布式文件存储系统在大数据处理中起到了一个基石的作用,后面的分布式数据处理和分布式数据库都可以架构在Hadoop FS的基础之上。
<待续>
大数据处理——Hadoop解析(一)相关推荐
- Hadoop系列之二:大数据、大数据处理模型及MapReduce
1.大数据(big data) 什么是大数据?wikipedia上面给出了这样的定义: In information technology, big data is a collection of d ...
- 基础搭建Hadoop大数据处理-编程
Hadoop的编程可以是在Linux环境或Winows环境中,在此以Windows环境为示例,以Eclipse工具为主(也可以用IDEA).网上也有很多开发的文章,在此也参考他们的内容只作简单的介绍和 ...
- 0基础搭建Hadoop大数据处理-初识
在互联网的世界中数据都是以TB.PB的数量级来增加的,特别是像BAT光每天的日志文件一个盘都不够,更何况是还要基于这些数据进行分析挖掘,更甚者还要实时进行数据分析,学习,如双十一淘宝的交易量的实时展示 ...
- 第二章-大数据处理框Hadoop
第二章-大数据处理框Hadoop 文章目录 第二章-大数据处理框Hadoop Hadoop简介 Hadoop概念 Hadoop版本 Hadoop优化与发展 Hadoop生态系统 Hive Pig Ha ...
- 从Hadoop到Spark、Flink,大数据处理框架十年激荡发展史
abstract: 当前这个数据时代,各领域各业务场景时时刻刻都有大量的数据产生,如何理解大数据,对这些数据进行有效的处理成为很多企业和研究机构所面临的问题.本文将从大数据的基础特性开始,进而解释分而 ...
- 大数据处理和编程实践Hadoop
Hadoop是Apache开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用,如亚马逊.Facebook和Yahoo等等.对于我来说,最近的一个使用点就是服务集成平台的日志分析.服务集 ...
- 大数据处理技术之hadoop概览
上两个图,可以对热到极致的大数据处理技术有一个基本的认识 大数据处理技术之演进 大数据处理技术之hadoop软件族: hadoop 1 hadoop2 相关软件下面简介: 1 Ambari:Hadoo ...
- 大数据技术与架构——(二)大数据处理架构Hadoop(上)
文章目录 1.Hadoop概述 1.1Hadoop简介 1.2Hadoop发展简史 1.3Hadoop的特性 1.4Hadoop的应用现状 1.5 Apache Hadoop版本演变 1.6 Hado ...
- 云计算与大数据第15章 分布式大数据处理平台Hadoop习题带答案
第15章 分布式大数据处理平台Hadoop习题 15.1 选择题 1.分布式系统的特点不包括以下的( D ). A. 分布性 B. 高可用性 C. 可扩展性 D.串行 ...
最新文章
- 镁光ssd管理工具 linux,在 SSD 上使用 Btrfs 文件系统的相关优化
- zabbix企业应用之监控oracle
- tomcat-connector-address遇到的问题
- 六、linux虚拟平台设备注册
- 迭代器和生成器的区别
- python吃内存还是cpu_Python2 得到 CPU 和内存信息要怎么实现呢?
- java本地读取文件的io类_Java File类与文件IO流总结
- Docker Compose部署Nexus3时的docker-compose.yml代码
- java1002java,疯狂java学习笔记1002---抽象类及接口
- 关于jdk1.5之后的自定拆装箱
- nginx学习十 ngx_cycle_t 、ngx_connection_t 和ngx_listening_t
- java导出 elsx 文件,如何获取java导出的excel文件,发送请求导出excle文件
- 关于 element 可以被找到但是不能被click()的问题
- 【语义相似度】ESIM:语义相似度领域小模型的尊严
- Jmeter (二十五)逻辑控制器 之 Random Controller and Random order Controller
- CentOS 7安装Teamviewer 12
- POJ 2431 Expedition (贪心+优先队列)
- pyqsplitter 保持一个窗口不能拖动_Axure教程:左侧导航如何自适应浏览器窗口高度?...
- 面向对象,继承封装的应用
- 限制不互素对的排列(构造)
热门文章
- ssh中c3p0连接mysql_JSP+SSH+Mysql+C3P0实现的传智播客网上商城
- oracle 定时器时间分区_oracle分区表按时间自动创建
- mysql本周函数_MySQL的YEARWEEK函数以及查询本周数据_MySQL
- c语言随机函数五位数,【分享代码】弥补c语言随机数不足
- 武汉大专计算机专业分数线,武汉高考分数线最低的大专,2021年武汉大专最低分数线是多少...
- java 必备_Java基础必备
- 大型Web应用的数据库设计与部署
- anaconda学习python,anaconda快速搭建python学习环境-windows
- liferay7.0 mysql_Liferay7 BPM门户开发之6: Activiti数据库换为mysql
- android+3g,不到900的Android+3G手机 TCL A906评测