几十条业务线日志系统如何收集处理?
在互联网迅猛发展的今天 各大厂发挥十八般武艺的收集用户的各种信息,甚至包括点击的位置,我们也经常发现自己刚搜完一个东西,再打开网页时每个小广告都会出现与之相关联的商品或信息,在感叹智能的同时不惊想 什么时候泄露的行踪。
许多公司的业务平台每天都会产生大量的日志数据。收集业务日志数据,供离线和在线的分析系统使用,正是日志收集系统的要做的事情。
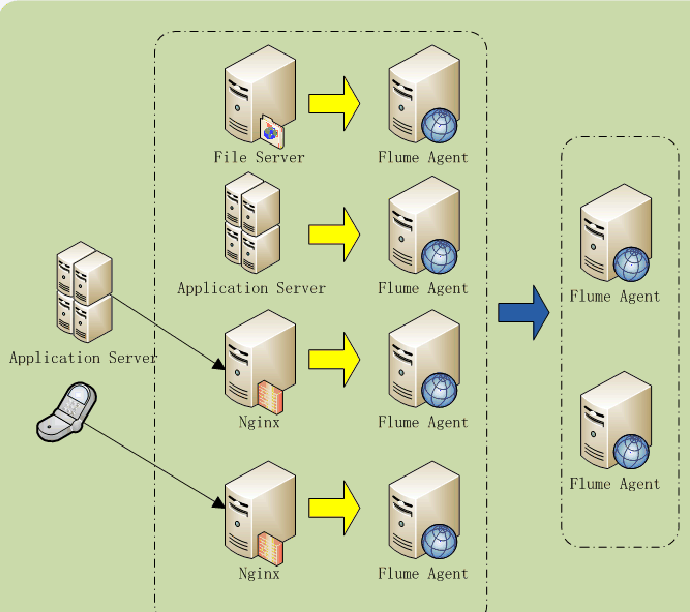
用户的数据除了这种后台默默的收集外,还有各种运行的日志数据和后台操作日志,因此每个业务可以算是一种类型的日志,那稍大点的公司就会有几十种日志类型要收集,而且业务都分布到不同的服务器上,这就导致了日志的汇集的困难,
在此可以用Flume来解决此类问题,参考以下架构。
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,目前已经是Apache的一个子项目。
Flume作为一个日志收集工具,非常轻量级,基于一个个Flume Agent,能够构建一个很复杂很强大的日志收集系统,它的灵活性和优势, 高可用性,高可靠性和可扩展性是日志收集系统所具有的基本特征。主要体现在如下几点:
- 模块化设计:在其Flume Agent内部可以定义三种组件:Source、Channel、Sink
- 组合式设计:可以在Flume Agent中根据业务需要组合Source、Channel、Sink三种组件,构建相对复杂的日志流管道
- 插件式设计:可以通过配置文件来编排收集日志管道的流程,减少对Flume代码的侵入性
- 可扩展性:我们可以根据自己业务的需要来定制实现某些组件(Source、Channel、Sink)
- 支持集成各种主流系统和框架:像Hadoop、HBase、Hive、Kafka、ElasticSearch、Thrift、Avro等,都能够很好的和Flume集成
- 高级特性:Failover、Load balancing、Interceptor等
Flume的优势
1. Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
2. 当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供一共平稳的数据.
3. 提供上下文路由特征
4. Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
5. Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
Flume具有的特征:
1. Flume可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中
2. 使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中
3. 除了日志信息,Flume同时也可以用来接入收集规模宏大的社交网络节点事件数据,比如facebook,twitter,电商网站如亚马逊,flipkart等
4. 支持各种接入资源数据的类型以及接出数据类型
5. 支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
6. 可以被水平扩展
Flume的结构
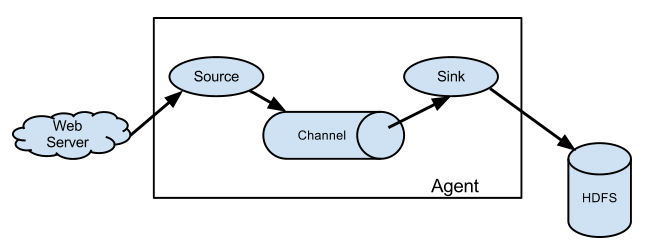
Agent主要由:source,channel,sink三个组件组成.
Source:
从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channal,Flume提供多种数据接收的方式,比如Avro,Thrift,twitter1%等
Channel:
channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel , Memort channel等.
sink:
sink将数据存储到集中存储器比如Hbase和HDFS,它从channals消费数据(events)并将其传递给目标地. 目标地可能是另一个sink,也可能HDFS,HBase.
它的组合形式举例:
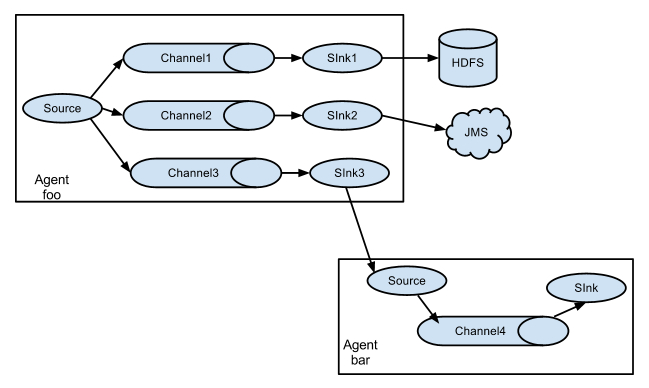
以上介绍的flume的主要组件
下面介绍一下Flume插件:
1. Interceptors拦截器
用于source和channel之间,用来更改或者检查Flume的events数据
2. 管道选择器 channels Selectors
在多管道是被用来选择使用那一条管道来传递数据(events). 管道选择器又分为如下两种:
默认管道选择器: 每一个管道传递的都是相同的events
多路复用通道选择器: 依据每一个event的头部header的地址选择管道.
3.sink线程
用于激活被选择的sinks群中特定的sink,用于负载均衡.
由于Flume的日志源可以来自另外一个Flume,可以同时发送给多个目标,且Flume自身可以做负载,由此可以设计出高可用,可扩展,高负载的日志架构。
应用场景
比如我们在做一个电子商务网站,然后我们想从消费用户中访问点特定的节点区域来分析消费者的行为或者购买意图. 这样我们就可以更加快速的将他想要的推送到界面上,实现这一点,我们需要将获取到的她访问的页面以及点击的产品数据等日志数据信息收集并移交给Hadoop平台上去分析.而Flume正是帮我们做到这一点。现在流行的内容推送,比如广告定点投放以及新闻私人定制也是基于次,不过不一定是使用FLume,毕竟优秀的产品很多,比如facebook的Scribe,还有Apache新出的另一个明星项目chukwa,还有淘宝Time Tunnel。
flume+kafka+storm+mysql构建大数据实时系统
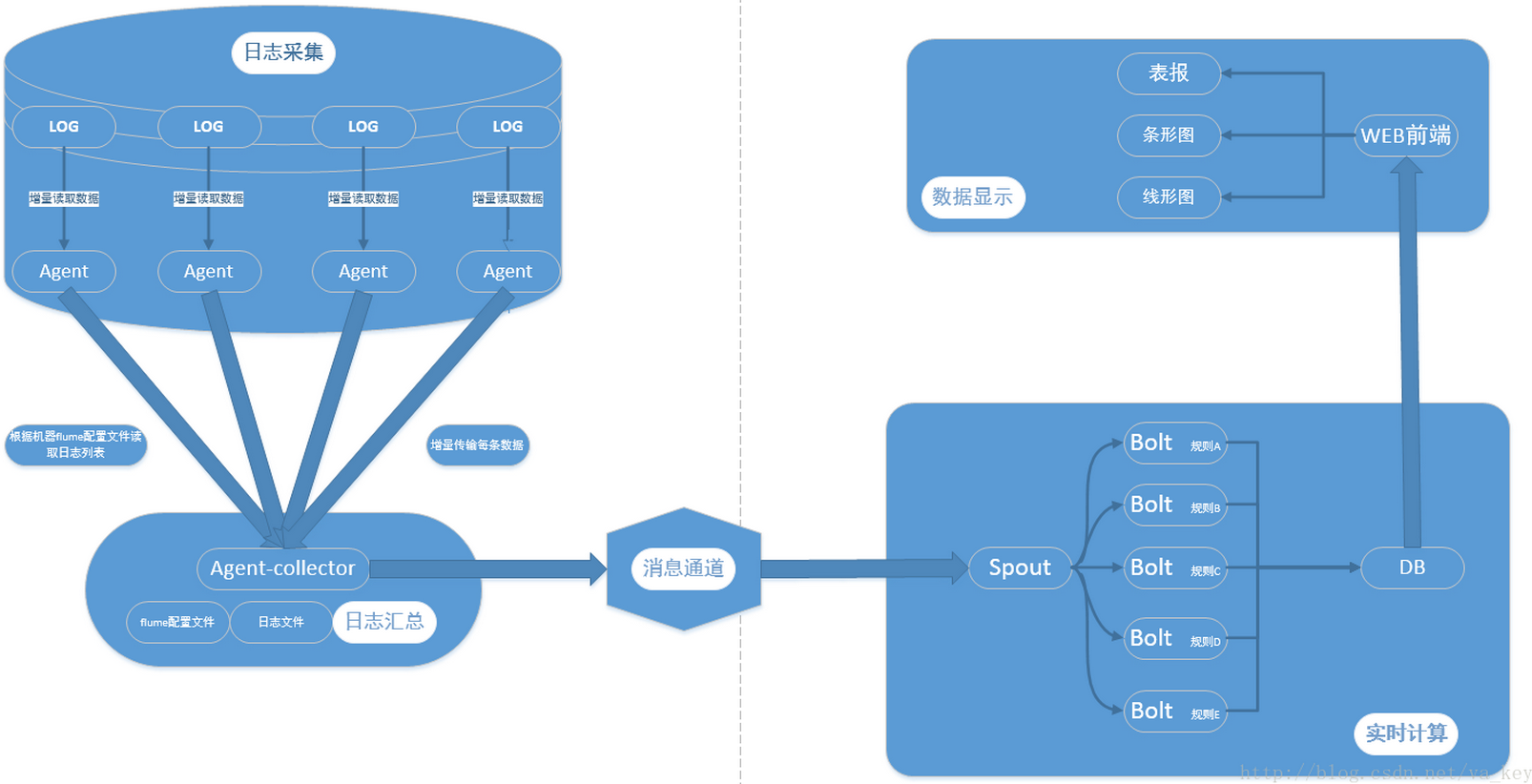
Flume+HDFS+KafKa+Strom实现实时推荐,反爬虫服务等服务在美团的应用
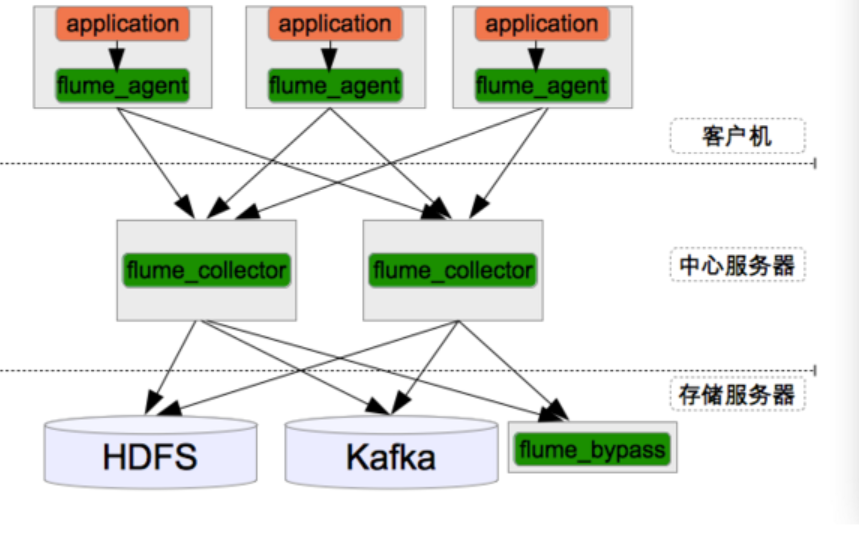
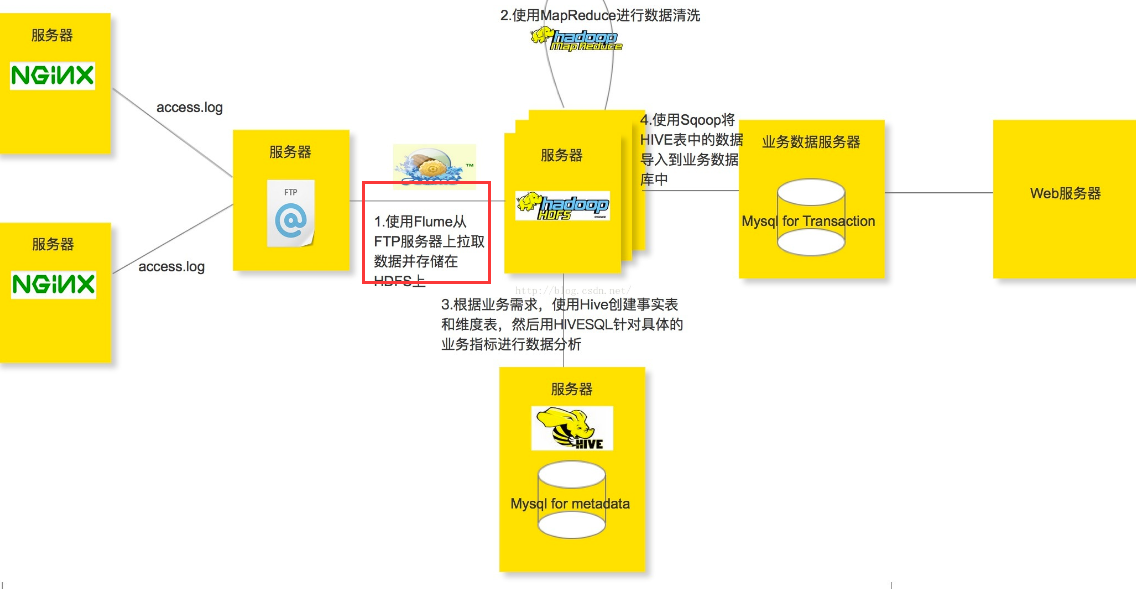
Flume+Hadoop+Hive的离线分析网站用户浏览行为路径
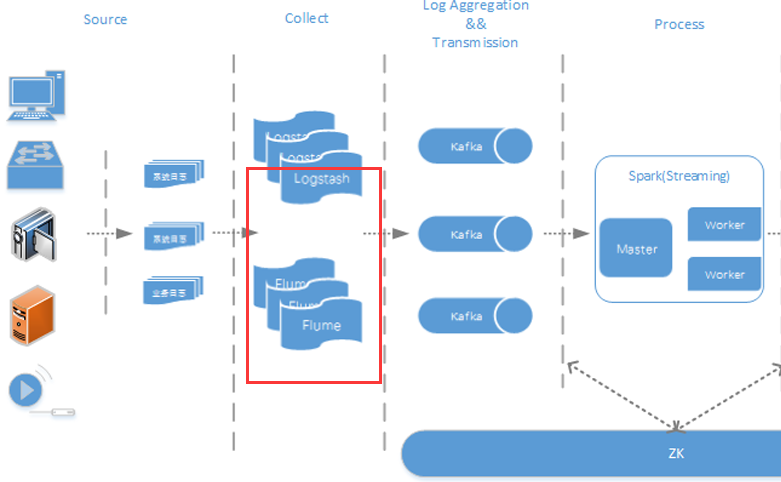
Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析
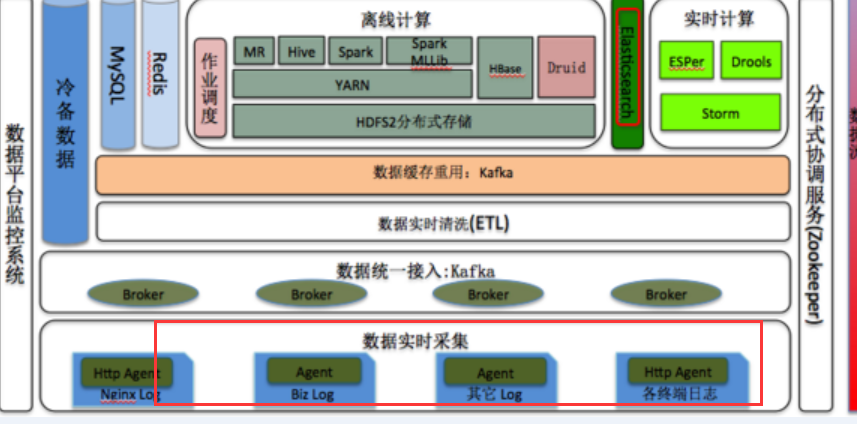
Flume+Spark + ELK新浪数据系统实时监控平台
列举不完了 ……………………………………………………………………
几十条业务线日志系统如何收集处理?相关推荐
- 教你一步搭建Flume分布式日志系统
在前篇几十条业务线日志系统如何收集处理?中已经介绍了Flume的众多应用场景,那此篇中先介绍如何搭建单机版日志系统. 环境 CentOS7.0 Java1.8 下载 官网下载 http://flume ...
- 使用XLog、Spring-Boot、And-Design-Pro搭建日志系统
一.前言:移动端为什么要三方日志系统 日志系统用于记录用户行为和数据以及崩溃时的线程调用栈,以帮助程序员解决问题,优化用户体验. iOS系统就有自带Crash收集应用程序"ReportCra ...
- 从零搭建一个基于 ELK 的日志、指标收集与监控系统
在需要私有化部署的系统中,大部分系统仅提供系统本身的业务功能,例如用户管理.财务管理.客户管理等.但是系统本身仍然需要进行日志的采集.应用指标的收集,例如请求速率.主机磁盘.内存使用量的收集等.同时方 ...
- 一些高大上的日志系统收集
日志系统基本可以分为两类:传统日志系统和分布式日志系统,本节我们研究分布式日志系统的相关开源实现,主要分析facebook的scribe和apache的机遇Hadoop的chukwa. faceboo ...
- 用Kibana和logstash快速搭建实时日志查询、收集与分析系统
Logstash是一个完全开源的工具,他可以对你的日志进行收集.分析,并将其存储供以后使用(如,搜索),您可以使用它.说到搜索,logstash带有一个web界面,搜索和展示所有日志. kibana ...
- ELK学习2_用Kibana和logstash快速搭建实时日志查询、收集与分析系统
Logstash是一个完全开源的工具,他可以对你的日志进行收集.分析,并将其存储供以后使用(如,搜索),您可以使用它.说到搜索,logstash带有一个web界面,搜索和展示所有日志. kibana ...
- 浪潮服务器系统下收集日志,浪潮:打卡了解Venus 详解这款OpenStack日志管理项目...
(全球TMT2021年5月24日讯)Venus是什么?初见还要追溯到去年11月召开的浪潮云海创新论坛2020.会上不仅分享了浪潮云海对于前沿科技的创新洞见以及扎实可靠的落地实践,更重要的是TA,一个开 ...
- HAProxy + Keepalived + Flume 构建高性能高可用分布式日志系统
一.HAProxy简介 HAProxy提供高可用性.负载均衡以及基于TCP和HTTP应用的代 理,支持虚拟主机,它是免费.快速并且可靠的一种解决方案.HAProxy特别适用于那些负载特大的web站点, ...
- 006.不浅谈,数十条业务线以上的,前端小团队瞎逼基础服务思路
!!!高能预警,长文,我都不知道多少字. 背景 我嘛,虽然不是出身bat,写了三年多业务代码,18年开始带团队至今,从toB的pc.管理台.小程序.微信公众号.app.活动.服务端,都有涉猎.当然公司 ...
最新文章
- xlsx to html c,js-xlsx使用
- jQuery.sap.require
- SQL 查询数据库中包含指定字符串的相关表和相关记录
- 【Python】base64模块对图片进行base64编码和解码
- 使软件可二次开发_RobotStudio二次开发:Smart组件I/O信号声明
- 【博客项目】—数据分页(十)
- java 线性的排序算法_数据结构之排序算法Java实现(9)—— 线性排序之 基数排序算法...
- c++ 单引和双引的区别
- 代码自动生成:Github Copilot
- matlab磁盘内存,Matlab内存不足问题的解决【转】
- STP协议:生成树协议(二层防环机制:防止网桥网络中冗余链路形成环路工作)
- ct扫描方式有哪些_日联科技x-ray:工业CT是怎么进行X射线的断层扫描的
- 强化学习之AC、A2C和A3C
- 拷贝控制示例——Message和Folder
- WCDMA中的CQI
- 【20191025】考试
- 上海淘融网络致广大客户的致歉信
- 【蓝桥杯考前一天总结PYthon终结篇】
- 【ES8系列】String 补白、格式化
- 网易考拉Android客户端网络模块设计