如何评估AI在医学影像识别中的应用效果?
基于人工智能(AI)技术的医学影像识别越来越受到社会各界的重视。而人工智能技术的进步,往往被归纳为几个性能指标,这样一来,AI技术的性能指标自然也就成为大家谈论和关注的焦点之一。实践中存在多种衡量AI算法性能的指标,本文尝试解释其中常见的几种指标的含义,以及它们在不同场景下的适用性和局限性,希望能够帮助大家更好地理解指标背后AI技术的进展。
医疗影像识别中有哪些常用指标?
为简化讨论,本文均以“二分类问题”为例,即对影像判断的结果只有两种:要么是阳性(positive),要么是阴性(negative)。这样的简化也符合大部分医学影像识别问题的实际情况。
二分类问题,如果不能被AI模型完美解决,那么模型预测结果的错误大概有两类:一类是把阴性误报为阳性(把没病说成了有病),另一类是把该报告的阳性漏掉(即把有病看成了没病)。优化模型的过程,是同时减少这两类错误的过程,至少是在两类错误之间进行适当折中的过程。不顾一类错误,而单纯减少另一类错误,一般是没有意义的。比如,我们为了不犯“漏”的错误,最简单的办法就是把所有的图像都报告称阳性(有病)。
1. 常用术语解释
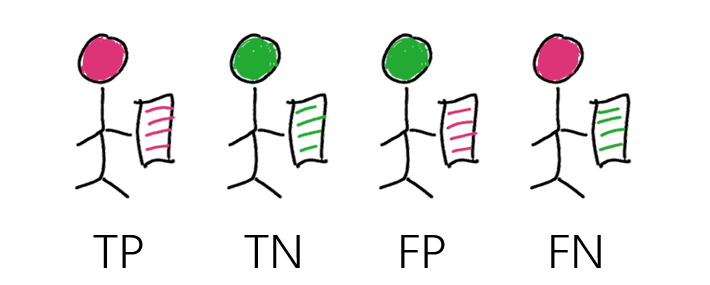
在二分类的条件下,AI的预测结果存在下列4种情形:
真阳性(True Positive,TP):预测为阳性,实际为阳性;
真阴性(True Negative,TN):预测为阴性,实际为阴性;
假阳性(False Positive,FP):预测为阳性,实际为阴性;
假阴性(False Negative,FN):预测为阴性,实际为阳性。
其中,FP也称为误报(False alarm),FN也称为漏报(miss detection)。
上文4种名称中的“真”(True)和“假”(False)表示预测结果是否正确。名称中的“阳性”(Positive)和“阴性”(Negative)表示预测结果。例如,对于一个特定的测试样本,真阳性的含义为“AI预测正确,且AI预测结果为阳性”,那么就可以推断到:预测为阳性,实际结果为阳性。假阴性的含义为“AI错判为阴性”,那么就可以推断到:预测为阴性,实际结果为阳性。
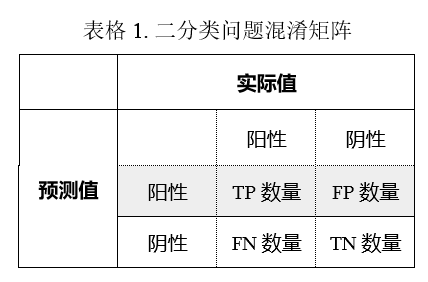
通常我们会用一个矩阵来展示预测结果和实际情况的差异,称为混淆矩阵 (confusion matrix)。二分类的混淆矩阵为2x2的,见表1。为表述方便起见,接下来我们就以TP代指真阳性的数量,TN代指真阴性的数量,FP代指假阳性的数量,FN代指假阴性的数量。
2. 可以由混淆矩阵得到的指标
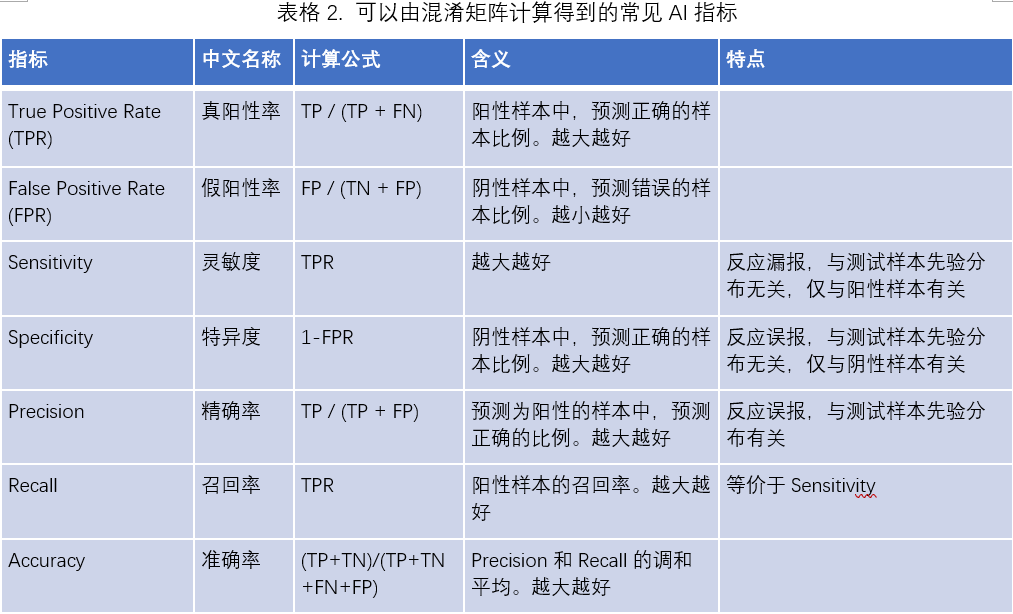
表2中涉及到的指标,取值范围均是0至1。由于上述两类错误的存在,通常这些指标需要成对地报告,成对地去考察。
例如,如果我们只关心AI模型的灵敏度(Sensitivity),那么我们就只需要把所有的样本预测为阳性,那么Sensitivity就等于1。显然,这不是一个好的模型,因为它会将阴性样本误报为阳性,使得它的特异度(Specificity)为0。因此,需要同时报告Sensitivity和Specificity。
精确率(Precision)和召回率(Recall)、真阳性率(TPR)和假阳性率(FPR)也存在类似的此消彼长的关系,我们不再对这些指标单独讨论。准确率(Accuracy)通常也会和其它指标一起报告,我们会在下文各指标使用场景具体讲到。
当同时报告两个指标(例如Sensitivity和Specificity)时,我们通常还会报告二者的“平均值”,使得模型的指标归为一个点,以便比较两个模型的好坏。这里我们通常使用二者的调和平均数,称为F1-measure。选调和平均数的原因是调和平均数相比于算数平均数和几何平均数,更加偏向小的那个数。给定两个指标,它们的各种平均数之间存在如下关系:
调和平均数 ≤ 几何平均数 ≤ 算数平均数
当且仅当两个指标相等时,上述等式成立。这就要求我们找到这样一个模型,使得两个指标尽量均衡。
3. 不能由混淆矩阵得到的指标
一个AI模型通常不是直接得到阳性或者阴性的结果的。它输出的是阳性(或者阴性)的得分(也可被称为阳性的“概率”或者“置信度”,尽管它实际上和概率或者置信度并无关系)。通常是得分越大,表明模型越肯定这是一个阳性病例。为了把得分转化为阳性-阴性的二分类,我们会认为设置一个决策阈值(decision threshold)。当模型关于某个样本的阳性得分大于该阈值时,该样本被预测为阳性,反之则为阴性。
例如,当阈值设为0.5时,模型输出的样本1的得分为0.7,则样本1被预测为阳性。模型输出的样本2的得分为0.1,则样本2会被预测为阴性。上述二分类的过程实质上就是将模型给出的连续得分量化为阳性、阴性这两个离散值之一。阈值一旦确定,就可以计算相应的混淆矩阵。
因此,上一节讲到的所有指标,都是可能随着阈值变动而改变的。例如,将阈值由0.5提高到0.6时,预测为阳性的样本有很大可能会减少,由此导致误报减少而漏报增多,相应的指标也随之变动,具体表现为Sensitivity下降而Specificity提升。
为方便起见,我们假设所有的得分均在0和1之间。
(1)ROC曲线和AUC
随着阈值的降低,预测的阳性病例增加,预测的阴性病例减少,即TPR上升,FPR上升,以TPR为纵坐标,FPR为横坐标画出ROC曲线,如图1所示。可以看出,ROC曲线是TPR关于FPR的不减函数。
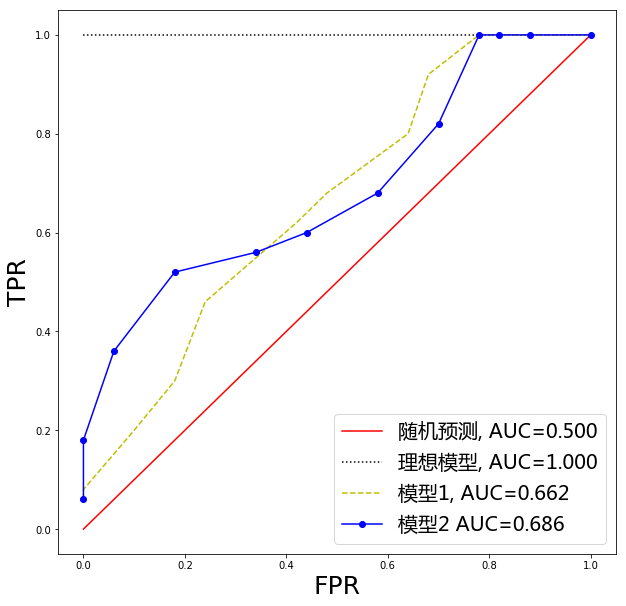
回顾表1,可知TPR就是Sensitivity,而 FPR等于1-Specificity。因此,也可以认为ROC曲线的横坐标是1-Specificity,纵坐标是Sensitivity。
ROC曲线起始点对应的阈值为1,即将所有样本均预测为阴性,此时阳性样本全被误报为阴性(TP=0),而阴性样本没有被误报(FP=0),因此有TPR=FPR=0。ROC曲线终点对应的阈值为0,即所有样本均预测为阳性,此时TPR=FPR=1。
当模型1的ROC曲线被算法2的ROC曲线严格包围时,意味着在相同的FPR(或Specificity)要求下,模型2的TPR(或Sensitivity)更高,可以认为模型2优于模型1,如图1中的模型1就优于随机预测。
当不存在某条ROC曲线被另一条完全包围时,如图1中模型1和模型2的所示,我们通常使用ROC曲线下的面积作为度量指标,称之为AUC。
(2)Precision-Recall曲线(P-R曲线)和Average Precision(AP)
除了ROC曲线,另一种常用的是Precision-Recall曲线,简称P-R曲线。随着阈值的降低,预测的阳性病例增加,预测的阴性病例减少。模型将更多的它认为“不那么确定是阳性” 的样本判断为阳性,通常 Precision 会降低。并且 Recall 不减。以Precision为纵坐标,Recall为横坐标画出P-R曲线,如图2。
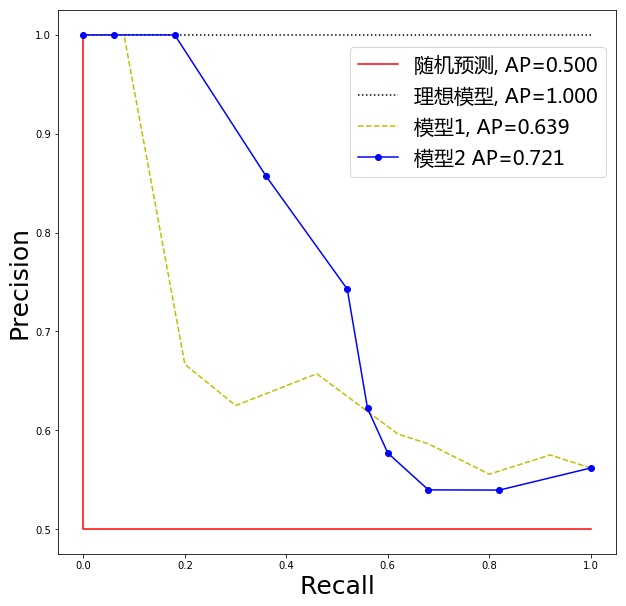
P-R曲线起点对应的阈值为所有预测样本得分的最大值,即只将模型认为最有可能是阳性的那一个测试样本预测为阳性,其余全预测为阴性,如果这一个阳性预测正确,那么Precision=1,Recall=1/所有阳性病例数,否则Precision=Recall=0。P-R曲线终点对应的阈值是0,即将所有样本预测为阳性,此时Precision=所有阳性病例数/总病例数,Recall=1。同样我们使用P-R曲线下的面积作为度量指标,称为AP。
AP和AUC与具体的阈值无关,可以认为是对模型性能的一个总体估计,因此通常作为更普适的指标来衡量模型的好坏。
不同指标在实际场景下的应用
我们用一个简单的图来帮助理解,如图3,红色代表阳性,绿色代表阴性,小人头的颜色代表实际类别,手中拿的诊断颜色代表模型预测的类别。
1. 理想的AI模型
所有的阳性都被预测为阳性,所有的阴性都被预测为阴性。如图4。
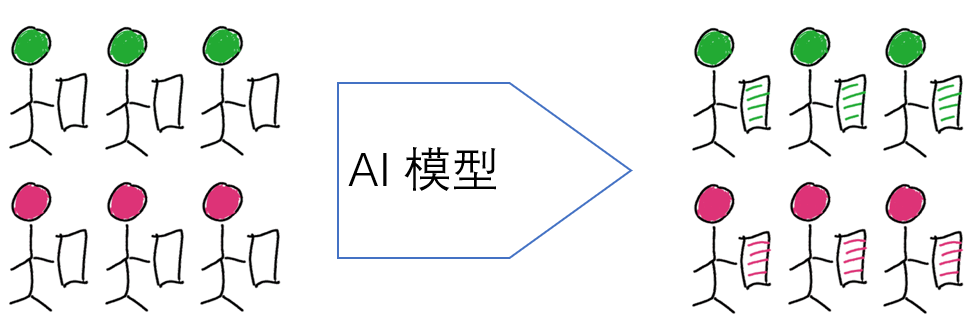
在这种情形下,Sensitive=Specificity=Precision=Recall=1。
2. 实际的AI模型
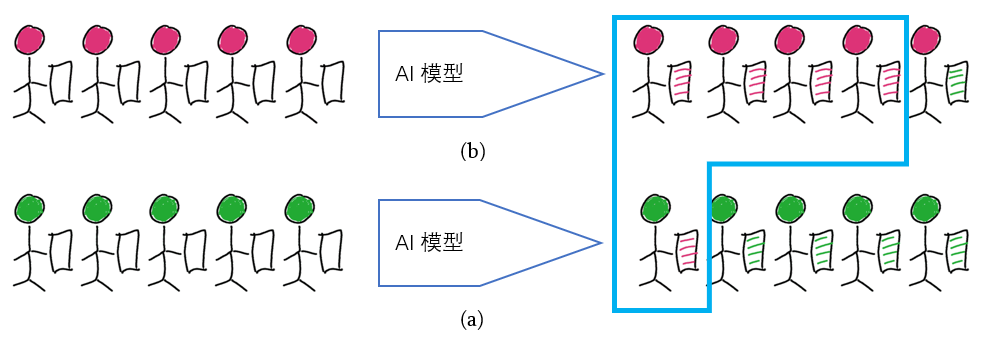
实际中,模型不可能做到完全正确。第一种情况,如图5。图5(a)中5个阳性中有4个被正确预测为阳性,Sensitive=4/5=0.8。图5(b)中5个阴性中有4个被正确预测为阴性, Specificity=4/5=0.8。一共5个病例被预测为阳性(蓝框),其中4个正确,Precision=4/5=0.8。
第二种情况,如图6所示,相对于第一种情况,我们将阴性的样本量增加两倍,Sensitive和Specificity不变。但是此时预测为阳性的病例数为7,其中只有4个正确,Precision=4/7=0.571。
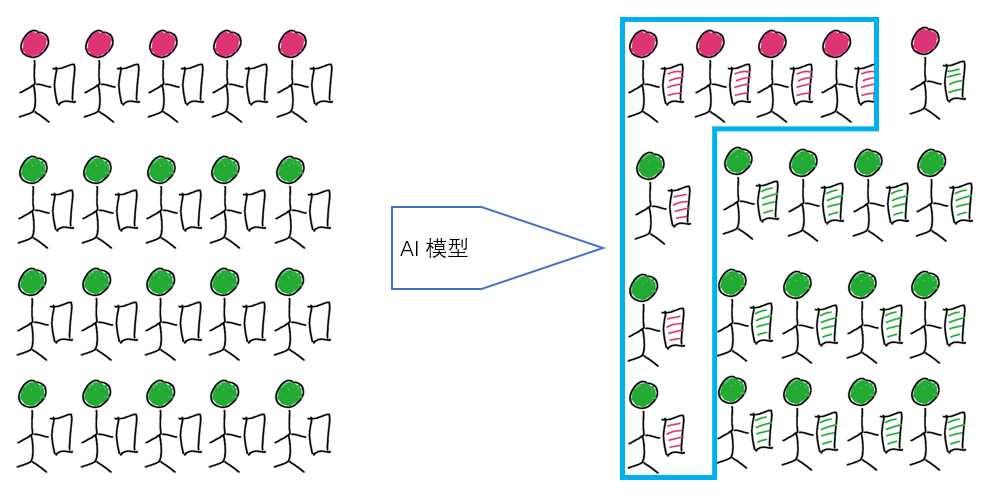
如果我们的阴性样本继续增加,保持Sensitive和Specificity不变,Precision还将继续下降。若将阴性样本数量变为第一种情况的100倍,保持Sensitive和Specificity不变,Precision=4/104=0.04。
当面对极不均衡数据时,通常是阴性样本远多于阳性样本,我们发现Specificity常常会显得虚高。就好像上述的例子,Sensitive和Specificity均为0.8,但Precision仅有0.04,即预测出的阳性中,有96%都是假阳性,这样就会带来用户的实际观感非常差。Specificity虚高同时带来的影响是AUC也会显得虚高。同样,这个例子中的 Accuracy 也会显得很高,因为里面 TN 占了很大比例。
更加极端的例子,在阴性样本数量为阳性样本数量的 100 倍时,即使模型只预测阴性,它的Accuracy 也大于 0.99。所以在数据极其不均衡时,我们选取Precision、Recall和AP值能够更好的反应模型的效果,同时也能更好的反应用户实际使用的体验。
实例解析
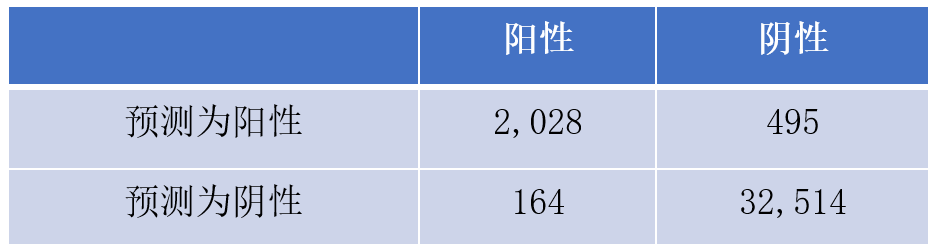
中山眼科发表了一篇糖网筛查的文章(http://care.diabetesjournals.org/content/early/2018/09/27/dc18-0147) ,文中提到模型的AUC=0.955,Sensitive=0.925,Specificity=0.985。
通过文中对数据集的描述,我们知道测试集总共有35,201张图片(14,520只眼),其中904只眼是阳性,按照比例估算,得阳性的图片约为35201 * 904 / 14520 = 2192张,阴性图片约为35201-2192=33009张,所以TP=21920.925=2028,TN=330090.985=32514张,FP=33009-32514-495张,FN=2192-2028=164张。混淆矩阵如表3所示,可算得Precision=2028/(2028+495)=0.804。比Specificity有明显差距。
总结
Sensitivity 和Specificity因为统计上与测试数据的先验分布无关,统计上更加稳定,而被广泛使用。但是当测试数据不平衡时(阴性远多于阳性),Specificity不能很好地反应误报数量的增加,同时AUC也会显得虚高,这时引入Precision和AP值能更好的反应模型的效果和实际使用的观感。
如何评估AI在医学影像识别中的应用效果?相关推荐
- 医学影像识别中的常用AI指标
作者:魏奇杰 丁大勇 李锡荣 本文目标 基于人工智能(AI)技术的医学影像识别越来越受到社会各界的重视.人工智能技术的进步,往往被归纳为几个性能指标,这样AI技术的性能指标也就成为大家谈论和关注的一个 ...
- Lesson 18 Kaggle医学影像识别 PART 1
#环境设置 import os import re import torch import warnings os.environ["KMP_DUPLICATE_LIB_OK"] ...
- 深度学习实战39-U-Net模型在医学影像识别分割上的应用技巧,以细胞核分割任务为例
大家好,我是微学AI,今天给大家介绍一下深度学习实战39-U-Net模型在医学影像识别分割上的应用技巧,以细胞核分割任务为例.本文将介绍在医学影像分割领域中应用U-Net模型的方法.我们将从U-Net ...
- LEADTOOLS V20,医学影像浏览器中3D体积渲染控件
2018 年 9 月 ,LEAD Technologies 发布了 LEADTOOLS V20 破解版本的更新,对整个产品线进行了许多速度和精度的优化. 除了更高效的 OCR,文件格式编解码器和图像显 ...
- AI解读医学影像能力超越人类?BMJ综述:此类研究大多存在偏差
图片来源:Pixabay 来源:BMJ 翻译:阿金 审校:戚译引 许多研究宣称,人工智能在解读医学影像方面具备和人类专家同等甚至更强的能力.但是,BMJ 近期发表的一篇综述指出,这些研究质量堪忧,有明 ...
- AI+医疗:使用神经网络进行医学影像识别分析 ⛵
- 【28】核心易中期刊推荐——医学影像识别及应用
- 博士申请 | 香港理工大学OIG实验室招收AI医疗/医学影像方向全奖博士生
合适的工作难找?最新的招聘信息也不知道? AI 求职为大家精选人工智能领域最新鲜的招聘信息,助你先人一步投递,快人一步入职! 香港理工大学 香港理工大学 (The Hong Kong Polytech ...
- 人工智能在医学影像中的研究与应用
人工智能在医学影像中的研究与应用 韩冬, 李其花, 蔡巍, 夏雨薇, 宁佳, 黄峰 沈阳东软医疗系统有限公司,辽宁 沈阳 110167 慧影医疗科技(北京)有限公司,北京 100192 东软集团股份有 ...
最新文章
- 我是如何自学 Python 的
- 遇到网络问题你是怎么解决的?安琪拉有二招
- mysql主从读写Windows_Windows操作系统下的MySQL主从复制及读写分离
- MIT发布“全球最快AutoML”,刷新DARPA比赛成绩
- PAT甲级1056 Mice and Rice:[C++题解]模拟、排名
- mysql 在大型应用中的架构演变
- Jquery Datatable的使用样例(ssm+bootstrsp框架下)服务器端分页
- (35) css企业命名规范
- 一加Ace渲染图曝光:大眼三摄+150W超快闪充
- 使用FileUpload上传图片到数据库
- 数据结构与算法-进阶(十二)最短路径Dijkstra 算法
- RuntimeError: The size of tensor a (4) must match the size of tensor b (3)
- 爱荷华州立大学计算机科学,2019上海软科世界一流学科排名计算机科学与工程专业排名爱荷华州立大学排名第301-400...
- 虚拟机突然没网了,虚拟机突然鼠标失灵
- [易飞]指定日期结存
- 从零开始写Python爬虫---1.1 requests库的安装与使用
- ios IDP/IEP证书申请测试用
- 机器学习预测结果评估展示_评估通用社区测试计划的性能并预测结果
- CSDN 如何设置博客名、博客简介及描述?
- onMeasure()和onSizeChanged()