linux内核页高速缓存,《Linux内核设计与实现》读书笔记(十六)- 页高速缓存和页回写(示例代码)...
主要内容:
缓存简介
页高速缓存
页回写
1. 缓存简介
在编程中,缓存是很常见也很有效的一种提高程序性能的机制。
linux内核也不例外,为了提高I/O性能,也引入了缓存机制,即将一部分磁盘上的数据缓存到内存中。
1.1 原理
之所以通过缓存能提高I/O性能是基于以下2个重要的原理:
CPU访问内存的速度远远大于访问磁盘的速度(访问速度差距不是一般的大,差好几个数量级)
数据一旦被访问,就有可能在短期内再次被访问(临时局部原理)
1.2 策略
缓存的创建和读取没什么好说的,无非就是检查缓存是否存在要创建或者要读取的内容。
但是写缓存和缓存回收就需要好好考虑了,这里面涉及到「缓存内容」和「磁盘内容」同步的问题。
1.2.1 「写缓存」常见的有3种策略
不缓存(nowrite) :: 也就是不缓存写操作,当对缓存中的数据进行写操作时,直接写入磁盘,同时使此数据的缓存失效
写透缓存(write-through) :: 写数据时同时更新磁盘和缓存
回写(copy-write or write-behind) :: 写数据时直接写到缓存,由另外的进程(回写进程)在合适的时候将数据同步到磁盘
3种策略的优缺点如下:
策略
复杂度
性能
不缓存
简单
缓存只用于读,对于写操作较多的I/O,性能反而会下降
写透缓存
简单
提升了读性能,写性能反而有些下降(除了写磁盘,还要写缓存)
回写
复杂
读写的性能都有提高(目前内核中采用的方法)
1.2.2 「缓存回收」的策略
最近最少使用(LRU) :: 每个缓存数据都有个时间戳,保存最近被访问的时间。回收缓存时首先回收时间戳较旧的数据。
双链策略(LRU/2) :: 基于LRU的改善策略。具体参见下面的补充说明
补充说明(双链策略):
双链策略其实就是 LRU(Least Recently Used) 算法的改进版。
它通过2个链表(活跃链表和非活跃链表)来模拟LRU的过程,目的是为了提高页面回收的性能。
页面回收动作发生时,从非活跃链表的尾部开始回收页面。
双链策略的关键就是页面如何在2个链表之间移动的。
双链策略中,每个页面都有2个标志位,分别为
PG_active - 标志页面是否活跃,也就是表示此页面是否要移动到活跃链表
PG_referenced - 表示页面是否被进程访问到
页面移动的流程如下:
当页面第一次被被访问时,PG_active 置为1,加入到活动链表
当页面再次被访问时,PG_referenced 置为1,此时如果页面在非活动链表,则将其移动到活动链表,并将PG_active置为1,PG_referenced 置为0
系统中 daemon 会定时扫描活动链表,定时将页面的 PG_referenced 位置为0
系统中 daemon 定时检查页面的 PG_referenced,如果 PG_referenced=0,那么将此页面的 PG_active 置为0,同时将页面移动到非活动链表
2. 页高速缓存
故名思义,页高速缓存中缓存的最小单元就是内存页。
但是此内存页对应的数据不仅仅是文件系统的数据,可以是任何基于页的对象,包括各种类型的文件和内存映射。
2.1 简介
页高速缓存缓存的是具体的物理页面,与前面章节中提到的虚拟内存空间(vm_area_struct)不同,假设有进程创建了多个 vm_area_struct 都指向同一个文件,
那么这个 vm_area_struct 对应的 页高速缓存只有一份。
也就是磁盘上的文件缓存到内存后,它的虚拟内存地址可以有多个,但是物理内存地址却只能有一个。
为了有效提高I/O性能,页高速缓存要需要满足以下条件:
能够快速检索需要的内存页是否存在
能够快速定位 脏页面(也就是被写过,但还没有同步到磁盘上的数据)
页高速缓存被并发访问时,尽量减少并发锁带来的性能损失
下面通过分析内核中的相应的结构体,来了解内核是如何提高 I/O性能的。
2.2 实现
实现页高速缓存的最重要的结构体要算是 address_space ,在 中


structaddress_space {struct inode *host; /*拥有此 address_space 的inode对象*/
struct radix_tree_root page_tree; /*包含全部页面的 radix 树*/spinlock_t tree_lock;/*保护 radix 树的自旋锁*/unsignedint i_mmap_writable;/*VM_SHARED 计数*/
struct prio_tree_root i_mmap; /*私有映射链表的树*/
struct list_head i_mmap_nonlinear;/*VM_NONLINEAR 链表*/spinlock_t i_mmap_lock;/*保护 i_map 的自旋锁*/unsignedint truncate_count; /*截断计数*/unsignedlong nrpages; /*总页数*/pgoff_t writeback_index;/*回写的起始偏移*/
const struct address_space_operations *a_ops; /*address_space 的操作表*/unsignedlong flags; /*gfp_mask 掩码与错误标识*/
struct backing_dev_info *backing_dev_info; /*预读信息*/spinlock_t private_lock;/*私有 address_space 自旋锁*/
struct list_head private_list; /*私有 address_space 链表*/
struct address_space *assoc_mapping; /*缓冲*/
struct mutex unmap_mutex; /*保护未映射页的 mutux 锁*/} __attribute__((aligned(sizeof(long))));
View Code
补充说明:
inode - 如果 address_space 是由不带inode的文件系统中的文件映射的话,此字段为 null
page_tree - 这个树结构很重要,它保证了页高速缓存中数据能被快速检索到,脏页面能够快速定位。
i_mmap - 根据 vm_area_struct,能够快速的找到关联的缓存文件(即 address_space),前面提到过, address_space 和 vm_area_struct 是 一对多的关系。
其他字段主要是提供各种锁和辅助功能
此外,对于这里出现的一种新的数据结构 radix 树,进行简要的说明。
radix树通过long型的位操作来查询各个节点, 存储效率高,并且可以快速查询。
linux中 radix树相关的内容参见: include/linux/radix-tree.h 和 lib/radix-tree.c
下面根据我自己的理解,简单的说明一下radix树结构及原理。
2.2.1 首先是 radix树节点的定义
/*源码参照 lib/radix-tree.c*/
structradix_tree_node {
unsignedint height; /*radix树的高度*/unsignedint count; /*当前节点的子节点数目*/
struct rcu_head rcu_head; /*RCU 回调函数链表*/
void *slots[RADIX_TREE_MAP_SIZE]; /*节点中的slot数组*/unsignedlong tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]; /*slot标签*/};
View Code
弄清楚 radix_tree_node 中各个字段的含义,也就差不多知道 radix树是怎么一回事了。
height 表示的整个 radix树的高度(即叶子节点到树根的高度), 不是当前节点到树根的高度
count 这个比较好理解,表示当前节点的子节点个数,叶子节点的 count=0
rcu_head RCU发生时触发的回调函数链表
slots 每个slot对应一个子节点(叶子节点)
tags 标记子节点是否 dirty 或者 wirteback
2.2.2 每个叶子节点指向文件内相应偏移所对应的缓存页
比如下图表示 0x000000 至 0x11111111 的偏移范围,树的高度为4 (图是网上找的,不是自己画的)
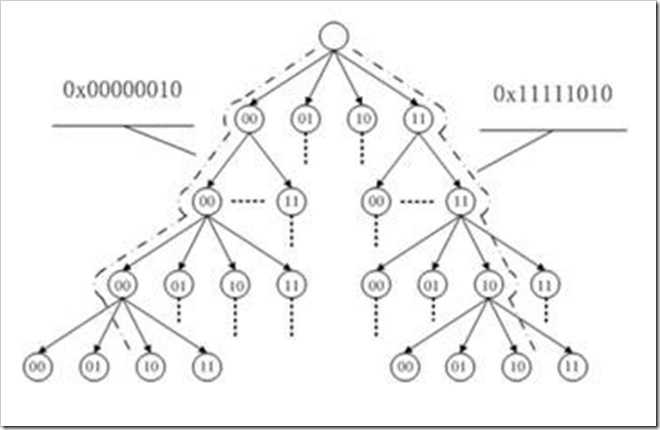
2.2.3 radix tree 的叶子节点都对应一个二进制的整数,不是字符串,所以进行比较的时候非常快
其实叶子节点的值就是地址空间的值(一般是long型)
3. 页回写
由于目前linux内核中对于「写缓存」采用的是第3种策略,所以回写的时机就显得非常重要,回写太频繁影响性能,回写太少容易造成数据丢失。
3.1 简介
linux 页高速缓存中的回写是由内核中的一个线程(flusher 线程)来完成的,flusher 线程在以下3种情况发生时,触发回写操作。
1. 当空闲内存低于一个阀值时
空闲内存不足时,需要释放一部分缓存,由于只有不脏的页面才能被释放,所以要把脏页面都回写到磁盘,使其变成干净的页面。
2. 当脏页在内存中驻留时间超过一个阀值时
确保脏页面不会无限期的驻留在内存中,从而减少了数据丢失的风险。
3. 当用户进程调用 sync() 和 fsync() 系统调用时
给用户提供一种强制回写的方法,应对回写要求严格的场景。
页回写中涉及的一些阀值可以在 /proc/sys/vm 中找到
下表中列出的是与 pdflush(flusher 线程的一种实现) 相关的一些阀值
阀值
描述
dirty_background_ratio
占全部内存的百分比,当内存中的空闲页达到这个比例时,pdflush线程开始回写脏页
dirty_expire_interval
该数值以百分之一秒为单位,它描述超时多久的数据将被周期性执行的pdflush线程写出
dirty_ratio
占全部内存的百分比,当一个进程产生的脏页达到这个比例时,就开始被写出
dirty_writeback_interval
该数值以百分之一秒未单位,它描述pdflush线程的运行频率
laptop_mode
一个布尔值,用于控制膝上型计算机模式
3.2 实现
flusher线程的实现方法随着内核的发展也在不断的变化着。下面介绍几种在内核发展中出现的比较典型的实现方法。
1. 膝上型计算机模式
这种模式的意图是将硬盘转动的机械行为最小化,允许硬盘尽可能长时间的停滞,以此延长电池供电时间。
该模式通过 /proc/sys/vm/laptop_mode 文件来设置。(0 - 关闭该模式 1 - 开启该模式)
2. bdflush 和 kupdated (2.6版本前 flusher 线程的实现方法)
bdflush 内核线程在后台运行,系统中只有一个 bdflush 线程,当内存消耗到特定阀值以下时,bdflush 线程被唤醒
kupdated 周期性的运行,写回脏页。
bdflush 存在的问题:
整个系统仅仅只有一个 bdflush 线程,当系统回写任务较重时,bdflush 线程可能会阻塞在某个磁盘的I/O上,
导致其他磁盘的I/O回写操作不能及时执行。
3. pdflush (2.6版本引入)
pdflush 线程数目是动态的,取决于系统的I/O负载。它是面向系统中所有磁盘的全局任务的。
pdflush 存在的问题:
pdflush的数目是动态的,一定程度上缓解了 bdflush 的问题。但是由于 pdflush 是面向所有磁盘的,
所以有可能出现多个 pdflush 线程全部阻塞在某个拥塞的磁盘上,同样导致其他磁盘的I/O回写不能及时执行。
4. flusher线程 (2.6.32版本后引入)
flusher线程改善了上面出现的问题:
首先,flusher 线程的数目不是唯一的,这就避免了 bdflush 线程的问题
其次,flusher 线程不是面向所有磁盘的,而是每个 flusher 线程对应一个磁盘,这就避免了 pdflush 线程的问题
linux内核页高速缓存,《Linux内核设计与实现》读书笔记(十六)- 页高速缓存和页回写(示例代码)...相关推荐
- JavaScript权威设计--CSS(简要学习笔记十六)
1.Document的一些特殊属性 document.lastModified document.URL document.title document.referrer document.domai ...
- linux 两个驱动 竞争,Linux设备驱动第五章(并发和竞争)读书笔记(国外英文资料).doc...
Linux设备驱动第五章(并发和竞争)读书笔记(国外英文资料) Linux设备驱动第五章(并发和竞争)读书笔记(国外英文资料) The fifth chapter is concurrency and ...
- Redis 设计与实现 读书笔记(菜鸟版)
Redis 设计与实现 读书笔记(简略版) 写在前面 第一章(内部数据结构) SDS List Dictionary Rehash Rehash 与 COW 渐进式Rehash 字典收缩 Skipli ...
- 《Reids 设计与实现》第十六章 集群(下)
<Reids 设计与实现>第十六章 集群(下) 文章目录 <Reids 设计与实现>第十六章 集群(下) 七.复制与故障转移 1.设置从节点 2.故障检测 3.故障转移 4.选 ...
- 领域驱动设计DDD之读书笔记
查看文章 领域驱动设计DDD之读书笔记 转载原地址:http://hi.baidu.com/lijiangzj 2007-08-17 16:53 一.当前Java软件开发中几种认识误区 Hibe ...
- Linux内核设计与实现 读书笔记
第二章 Linux内核 1 内核开发特点 1)内核编译时不能访问C库: 2)浮点数很难使用: 3)内核只有一个定长堆栈: 4)注意同步和并发. 第三章 进程管理 1 current宏:查找当前运行进程 ...
- 《Linux内核设计与实现》读书笔记(六)- 内核数据结构
内核数据结构贯穿于整个内核代码中,这里介绍4个基本的内核数据结构. 利用这4个基本的数据结构,可以在编写内核代码时节约大量时间. 主要内容: 链表 队列 映射 红黑树 1. 链表 链表是linux内核 ...
- linux+模块与设备关系,linux内核设计与实现读书笔记——设备和模块
一.设备类型 1.块设备 blkdev:以块为单位寻址,支持重定位(数据随机访问),通过块设备节点来访问. 2.字符设备cdev:不可寻址,提供数据流访问,通过字符设备节点访问. 3.网络设备:对网络 ...
- 《Linux内核分析与实现》 第五周 读书笔记
第3章 进程管理 20135307张嘉琪 3.1 进程 进程就是处于执行期的程序(目标码存放在某种存储介质上),但进程并不仅仅局限于一段可执行程序代码.通常进程还要包含其他资源,像打开的文件,挂起的信 ...
最新文章
- 怎样通过WireShark抓到的包分析出SIP流程图
- mysql pmm进程_mysql性能监控软件pmm
- angularjs html压缩,Angularjs 依赖压缩及自定义过滤器写法
- PMBOK(第六版) PMP笔记——第十章(项目沟通管理)
- SSM+物业管理系统 毕业设计-附源码310928
- 计算机对口模拟试题,计算机专业对口升学模拟试题
- 玩转接口测试工具fiddler 教程系列1
- HTML-坐标的含义,以及变换的使用
- OMNeT 例程 Tictoc9 学习笔记
- 光子晶体和深度学习结合进行多相流检测
- 股市学习稳扎稳打(四)当宏观经济出现复苏时,不同的行业分别以什么顺序进行轮动上涨
- 跨系统角色转移服务器未响应,王者荣耀:跨系统角色转移真的来了,附详细操作内容注意事项...
- Stata:面板数据,一般加上个体固定效应和时间固定效应
- js仿google+分享新鲜事系统实例源码
- 《python深度学习》学习笔记与代码实现(第六章,6.3 循环神经网络的高级用法)
- 优化嵌入式软件的几点技巧
- java数据透视表插件_纯前端表格控件SpreadJS:新增数据透视表插件等,完美呈现强大的Excel数据分析能力...
- M9ie浏览器-防关联浏览器的开创者
- 学生信息管理系统C语言单链表文件实现
- 数据库-多步操作产生错误,请检查每一步的状态值
热门文章
- 覆盖近2亿篇论文还免费!沈向洋旗下团队「读论文神器」登B站热搜
- 西湖大学三位资深博导自述:我与我的第一位博士生
- 加性注意力机制、训练推理效率优于其他Transformer变体,这个Fastformer的确够快...
- 德国版“非升即走”引发学界震荡!“临时工”干12年也难获教职,网友:全世界都在卷...
- 打造计数君!谷歌提出RepNet:可自动计数视频重复片段 | CVPR 2020
- 干货 | 浅谈 Softmax 函数
- 清晰易懂的Focal Loss原理解释
- 知乎13万赞!为何很多名校毕业生,都输在了人生后半程
- P8可以年入170万,那P10级别的程序猿,每天都在干嘛?
- 数据结构之二分查找(折半查找)