作为数据科学家,我都有哪些弱点
如果现代工作面试教会了我们什么,那就是关于“你最大的弱点是什么?”这个问题,正确答案是“我工作太努力了。”显然,说出自己的弱点是很可笑的。虽然在个人简历中列出弱点不太好,但是如果不承认自己的不足,我们就无法采取措施改善它们。
做出改进的方法很简单:
● 明确现在的位置:找出弱点
● 想变成什么样:制定实现的计划
● 执行计划:一步步改进
我们很少能跨越第一步,特别是对于在技术领域工作的人群。我们埋头苦干,不断工作,使用已掌握的技能,而不是学习能让我们工作更轻松或能带来新机会的新技能。自我反省,客观地评估自己,这似乎是一个陌生的概念。但若能够退后一步,弄清我们哪些方面能做得更好,从而在该领域取得进步,这是至关重要的。
考虑到这一点,我试着客观地评价自己,并总结了目前自己的三个弱点,改善以下这几点能让我成为更出色的数据科学家:
● 软件工程
● 扩展数据科学
● 深度学习
本文中我列出这些弱点主要的目的在于:首先,我非常想提高自己的能力,通过列出自己的不足以及如何解决它们,希望能够激励自己继续学习,完成目标。
其次,我希望鼓励其他人思考自己有哪些没掌握的技能,以及该如何获取这些技能。
最后,我想告诉你,成为出色的数据科学并不需要做到无所不知。关于数据科学和机器学习的知识是无尽的,你能够掌握的则很有限。我常常听到初学者抱怨,要掌握的知识太多了,我给出的建议就是:从基础开始,你并不需要掌握所有内容。
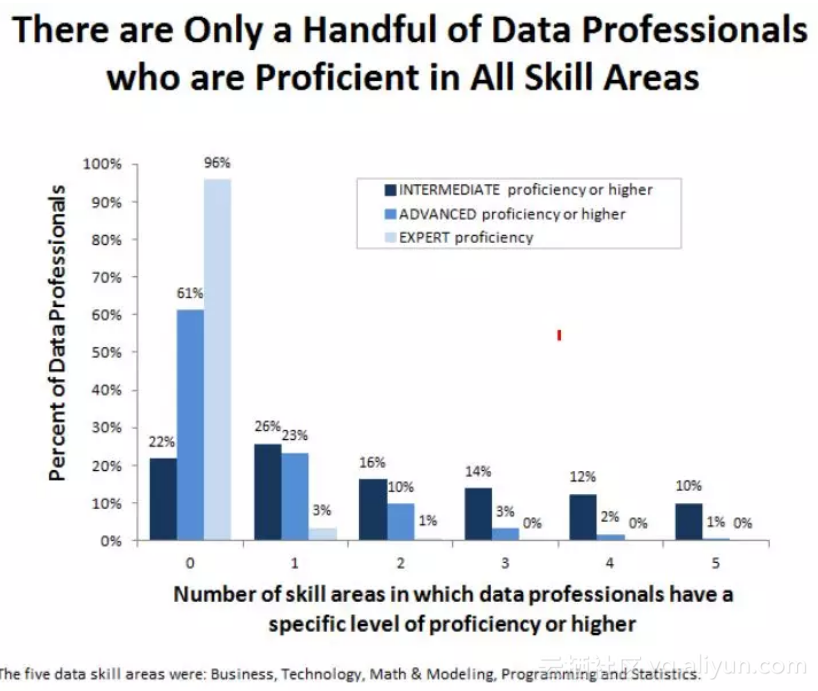
只有极少的数据科学家能够掌握全部知识
对于每个弱点,我都列出了具体的问题,以及我目前在做什么进行改进。发现自己的不足很重要,但制定改进计划也同样重要。学习一项新技能需要时间,但计划好一步步的具体步骤会大大增加你成功的几率。
1. 软件工程
在大学时进行我的第一个数据科学项目后,我开始试着避免一些数据科学方法中的坏习惯。其中包括编写仅运行一次的代码,缺少文档,没有一致性且难阅读的代码,硬编码特定值等。这些都是写论文所带来的,为了写一篇论文,开发针对特定数据集且只能运行一次的解决方案。
其中一个典型的例子是,我们有个项目使用建筑能源数据,最初每隔15分钟获取一次数据。当我们把时间增加为20分钟时,数据管道完全崩溃了,因为许多地方已明确将时间编为15分钟。我们不能进行简单的查找和替换,因为该参数被设定为多个名称,如electricity_intervaltimeBetweenMeasurementsdataFreq。我们当中没有人想过让代码更易阅读或能够灵活改变输入。
相比之下,从软件工程的角度来看,代码必须使用大量不同的输入进行测试,在现有框架内工作,并遵守编程标准,以便其他开发人员能够理解。尽管我的初衷是好的,但我偶尔会像数据科学家那样写代码,而不是像软件工程师那样。现在我正在训练自己像计算机科学家一样思考。
我在做什么
学习技能没有比练习更好的方法。幸运的是,在我目前的工作中,我能够为内部工具和开源库(Featuretools)做出贡献。这迫使我学习了很多技能,包括:
● 编写单元测试
● 遵循编码风格
● 编写接受更改参数的函数
● 彻底记录代码
● 让他人检查代码
● 重构代码,使其更简单、更易于阅读
对于还未工作的数据科学家,你也可以通过参与开源项目获得这些经验。除此之外,你还可以通过查看GitHub上流行库的源代码。
像软件工程师一样思考需要改变思维模式,但做到这一点并不难。例如,每当我发现自己在Jupyter Notebook中复制和粘贴代码并更改一些值时,我就会停下来,并意识到从长远的角度看用函数会更高效。
总有需要改进的地方(在Sublime Text 3中使用pylint)。
我还想研究计算机科学的许多其他方面,例如编写有效的实现,而不是用蛮力方法(例如使用矢量化而不是循环)。同时要注意想一下子全部改变是不显示的,这也是我为什么专注于一些实践,并将其融入到我的工作流程中。
虽然数据科学自成一体,但从业者仍可以通过借鉴软件工程等领域的最佳实践从中受益。
2. 扩展数据科学
虽然你可以自学数据科学中的所有内容,但要将其应用到实践中还是存在一些限制。一个是难以将分析或预测模型扩展到大型数据集。我们中大多数人无法访问计算集群,也不想为一台个人超级计算机掏钱。这意味着当我们学习新方法时,我们倾向于将它们应用于小型且表现良好的数据集。
然而在现实情况中,数据集并不符合一定的大小或干净程度,你需要用不同的方法来解决问题。首先,你可能需要打破个人计算机的安全限制,使用远程实例(例如通过AWS EC2)甚至多台计算机。
在学习数据科学时,我尝试在EC2机器上练习,这有助于让我熟悉命令行,但是,我仍然没有解决当数据集大于机器的内存情况。最近,我意识到这一点限制了我的前进,是时候学习如何处理更大数据集的了。
我在做什么
即使不在计算资源上花费大量金钱,就可以实践超出内存限制的数据集的处理方法。其中包括每次迭代数据集的一部分,将大型数据集分成较小的数据集,或者使用Dask这样的工具来处理大数据。
我目前采用的方法是将数据集分为多个子集,开发能够处理每个部分的管道,然后使用Dask或Spark,与PySpark并行地运行管道中的子集。这种方法不需要用到超级计算机或集群,你可以在个人计算机上并行操作。
此外,由于像Kaggle等数据存储库,我能够找到一些大型的数据集,并查看其他数据科学家的处理它们的方法。我已经学到了很多有用的技巧,例如通过更改数据框中的数据类型来减少内存消耗。这些方法有助于更有效地处理任何大小的数据集。
虽然我还没处理过TB级的数据集,但这些方法帮助我学习了处理大数据的基本方法。对于最近的一些项目,我能够运用目前学到的技能对在AWS上运行的集群进行分析。希望在之后的几个月,我能逐步提高处理数据集的大小。
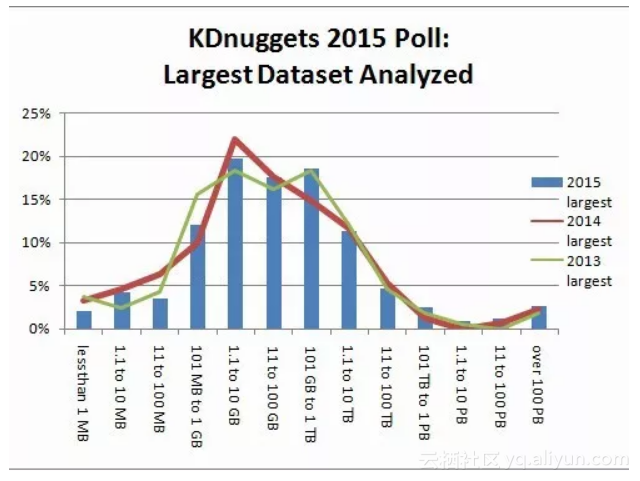
美国国会图书馆“只有”3PB的材料
3. 深度学习
虽然人工智能在繁荣和萧条中更迭,但是它最近在计算机视觉、自然语言处理、深度强化学习等领域的成功应用让我确信基于神经网络的深度学习不是昙花一现。
与软件工程或扩展数据科学不同,我目前的职位不需要用到深度学习,例如随机森林等传统的机器学习技术已经能够解决所有问题。但是,我认识到并非每个数据集都是结构整齐的,而神经网络是目前处理文本或图像项目的最佳选择。
探索和利用的权衡在强化学习和你的生活中的应用
在深度学习中有许多不同的子领域,很难弄清楚哪些方法最终会胜出。尽管如此,我认为熟悉该领域能够让人们能够处理更广泛的问题。
我在做什么
我学习深度学习的方法与成为数据科学家的方法相同:
● 阅读着重部署应用的书籍和教程
● 在实际项目中练习技术和方法
● 通过写作分享和解释我的项目
在学习一项技术时,最有效的方法是边做边学。对我来说,这意味着不是从基础的基础理论开始,而是通过找出如何实现解决问题的方法。这种自上而下的方法意味着我更重视关于动手的书籍,即当中包括许多代码例子。
对于深度学习,我主要看了以下三本书:
● Deep Learning Cookbook,作者:Douwe Osinga
● Deep Learning with Python,作者: Francois Chollet
● Deep Learning,作者:Ian Goodfellow、Yoshua Bengio、Aaron Courville
前两本重点是用神经网络构建实际解决方案,而第三本重点是深入理论。当阅读有关技术主题的书籍时,你需要更主动参与其中,尽可能试着书中的代码。像前两本提供代码例子的书籍很棒,我经常会在Jupyter Notebook中逐行输入代码,弄清当中的原理。
此外,我不仅试着复制这些代码,还会将它们用于自己的项目。这方面的一个应用是我最近构建的图书推荐系统,该系统是根据Deep Learning Cookbook的类似代码改编的。从头开始创建自己的项目可能会令人生畏,但这也是提升自己最好的方法。
最后,学习技术最有效方法之一是教别人。只有当我试着用简单的术语向其他人解释时,我才能我完全理解这个概念。随着学习深度学习的每个知识,我将写下了,分享当中的技术实现细节和概念性解释。
教学是最好的学习方式之一,我打算将其作为学习深度学习的一个重要组成部分。
结语
罗列自己的弱点可能会有点奇怪,但这能让我成为更好的数据科学家。而且我发现有时坦诚自己的弱点,并探讨如何解决它们能够给雇主们留下深刻印象。
缺乏某些技能并不是缺点——真正的缺点是假装你什么都懂,而且没有想改进的意思。
通过发现我在数据科学方面的弱点:软件工程,扩展分析/建模,深度学习,我的目标是提高自己,鼓励其他人思考自己的弱点。要成为出色的数据科学家,你并不需要什么都懂。虽然反思自己的弱点可能是痛苦的,但学习是愉快的。最有成就感的事情莫过于,经过一段时间的持续学习后,你会发现自己比刚开始时已经懂了很多。
原文发布时间为:2018-11-26
本文作者:William Koehrsen
本文来自云栖社区合作伙伴“CDA 数据分析师”,了解相关信息可以关注“CDA 数据分析师”。
作为数据科学家,我都有哪些弱点相关推荐
- 看看数据科学家们都在用什么:Github上的十大深度学习项目
本文作者Matthew May是一位正在进行并行式机器学习算法研究的计算机硕士研究生,同时Matthew也是一位数据挖掘研习者,数据发烧友,热忱的机器学习科学家.开源工具在数据科学工作流中起到了愈发重 ...
- 为什么我劝你不要当数据科学家?
作者丨Chris 译者丨Sambodhi 策划丨陈思 数据科学家这一职位越来越火热,人人都想从事数据科学,这不仅因为这份工作听上去高大上,更重要的是,它真的是一份高薪的工作.但是,数据科学家是人人都能 ...
- 数据科学家需要掌握的10项统计技术,快来测一测吧
摘要: 本文给出了数据科学应用中的十项统计学习知识点,相信会对数据科学家有一定的帮助. 无论你是不是一名数据科学家,都不能忽视数据的重要性.数据科学家的职责就是分析.组织并利用这些数据.随着机器学习技 ...
- kubernetes 数据_为什么数据科学家喜欢Kubernetes
kubernetes 数据 让我们从一个毫无争议的观点开始:软件开发人员和系统操作员喜欢Kubernetes ,它是在Linux容器中部署和管理应用程序的一种方式. Linux容器为可重现的构建和部署 ...
- 不懂数学,照样做数据科学家
不懂数学,照样做数据科学家 AI和机器学习的火热让数据科学家成为近几年热门职业之一.但对于试图从事这一职业的新人来说,数学可能最大的拦路虎之一.不过本文作者认为,当数据科学家并不一定需要坚实的数学基础 ...
- DS/ML:《Top 19 Skills You Need to Know in 2023 to Be a Data Scientist,2023年成为数据科学家需要掌握的19项技能》翻译与解读
DS/ML:<Top 19 Skills You Need to Know in 2023 to Be a Data Scientist,2023年成为数据科学家需要掌握的19项技能>翻译 ...
- 那些经验丰富的数据科学家每天在干什么?
全文共2604字,预计学习时长4分钟 数据科学家也许是"21世纪最性感的工作",但他们每天在做什么?是不是一直在建模?或者将70-80%的时间用于清理数据? 以下列举了五位来自业内 ...
- 抓取近千分领英资料后,我们发现了数据科学家的秘密……
全文共4090字,预计学习时长8分钟 获取数据,以洞悉自己想成为的样子 图片来源:David S.A/Pixabay 一个数据科学家是不是非得成为一个Kaggler大师?神经网络究竟该用于图像识别还是 ...
- 成为数据科学家,需具备这些技能
目前数据科学和数据科学家成为了流行词汇.当有人问你干什么,你回答说数据科学家,对方会恍然大悟,觉得特别高大上,噢,数据科学家啊,听说过.是啊,没听说过数据科学家那就out了.如果接着问,数据科学家具体 ...
- 大咖 | “大数据之父”达文波特:成功的数据科学家不一定要有研究生学位
大数据文摘作品 作者:托马斯·H·达文波特 2006年6月,乔纳森•高德曼(Jonathan Goldman)进入商务社交网站LinkedIn工作.作为斯坦福大学物理学博士,他醉心于无处不在的链接和丰 ...
最新文章
- 基于Eigen库和Matlab计算非线性多元函数最小值
- 语言在msin函数验证_R语言时间序列分析(七):模型准确度估计
- 【报错】no main manifest attribute, in xxxx.jar
- AutoMapper2
- 使用VMware VSphere WebService SDK进行开发 (三)——获取主机(HostSystem)的基本信息
- chromebook刷机_如何从Chromebook上的APK侧面加载Android应用
- linux系统操作大全,Linux系统的常用操作命令大全
- 对c语言字符数组描述错误的是,下述对C语言字符数组的描述中错误的是( )。
- 苏宁css代码生成器,【前端】06 - rem + less + 媒体查询 - 制作苏宁首页
- 数据标记系列——图像分割 Curve-GCN
- GJM:用C#实现网络爬虫(一) [转载]
- SylixOS中AARCH64跳转表实现原理
- Android——RelativeLayout(相对布局)
- 编写可维护的javascript代码--- 2015.11.21(基本格式化)
- vue @blur v-model数据没有更新问题
- \t\t中国机械工程师资格认证中心及各分中心通讯录
- 原来PDF解密有这么多方法,你知道几个?
- c语言打印星号对勾,Intellij常用快捷键记录
- [ROS2基础]launch 文件和多节点进程
- FIDO身份认证应用案例