eBay是如何进行大数据集元数据发现的
很多大数据系统每天都会收集数PB的数据。这类系统通常主要用于查询给定时间范围内的原始数据记录,并使用了多个数据过滤器。但是,要发现或识别存在于这些大型数据集中的唯一属性可能很困难。
在大型数据集上执行运行时聚合(例如应用程序在特定时间范围内记录的唯一主机名),需要非常巨大的计算能力,并且可能非常慢。对原始数据进行采样是一种发现属性的办法,但是,这种方法会导致我们错过数据集中的某些稀疏或稀有的属性。
介绍
我们在内部实现了一个元数据存储,可以保证实时发现大量来自不同监控信号源的所有唯一属性(或元数据)。它主要依赖于后端的Elasticsearch和RocksDB。Elasticsearch让聚合可以查找在一个时间范围内的唯一属性,而RocksDB让我们能够对一个时间窗口内具有相同哈希的数据进行去重,避免了冗余写入。
我们提供了三种监控信号源的元数据发现:指标、日志和事件。
指标
指标是周期性的时间序列数据,包含了指标名称、源时间戳、map形式的维度和长整型数值,例如http.hits 123456789034877 host=A。
在上面的示例中,http.hits是指标名称,1234567890是EPOC UTC时间戳,34877是长整型数值,host=A是维度{K,V}键值对。我们支持发现指标名称和带有维度map的名称空间。
日志
日志是来自各种应用程序或软件/硬件基础设施的日志行。
我们用以下格式表示日志:
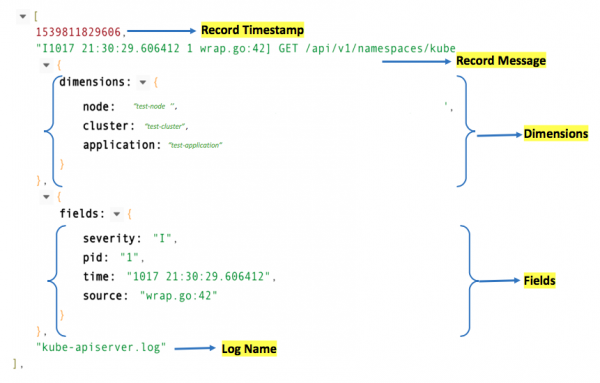
日志对用例(也称为名称空间)来说总是可发现的。每个日志行都可以是某种特定类型,例如stdout或stderr。
日志信号的类型(也称为名称)也是可发现的,如上例所示,键值map也是可发现的。
事件
事件类似于日志和指标。它们可以被视为一种稀疏指标,表示为系统内的事件。它们是非周期性的。例如,路由器交换机变为不可用时会被记录为事件。此外,它们可能会有点冗长,可能会包含大量的文本信息用以说明事件期间发生了什么。
事件的一个简单示例:
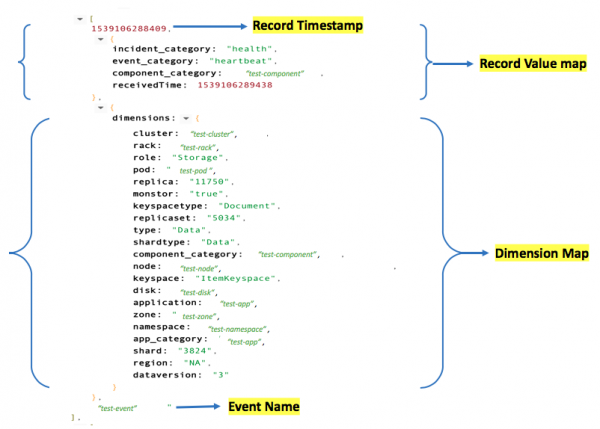
与日志和指标类似,事件也有名称空间和名称,两者都是可发现的。可发现的字段键让我们能够在已知字段上执行聚合操作,例如MIN、MAX和COUNT。
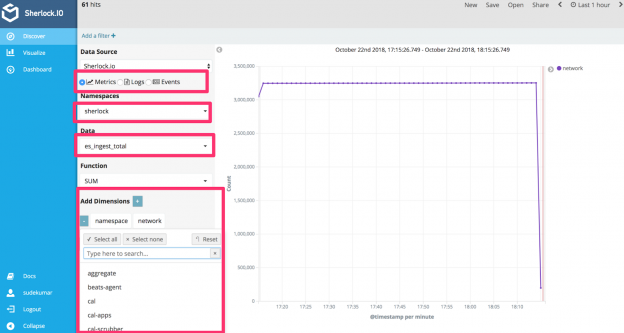
下面的截图突出显示了我们的产品控制台中的发现属性:
方法和设计
所有监控信号最初都由我们的ingress服务实例负责接收。这些服务节点使用自定义分区逻辑将不同的输入监控信号(日志、指标和事件)推送到Kafka数据总线主题上。元数据存储ingress守护程序负责消费这些监控信号,然后将它们写入到后端Elasticsearch。
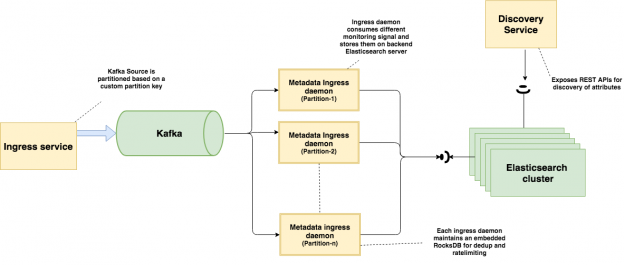
我们收集的监控信号被推送到Kafka总线上,它们是我们的源数据流。Kafka的一个优点是它提供了持久存储,即使下游管道处于维护或不可用状态。我们还在入口服务上使用自定义Kafka分区器,以确保具有相同哈希值的键始终位于相同的Kafka分区上。不同的监控信号内部使用不同的哈希值。例如,我们使用基于名称空间+名称的哈希值来表示指标信号,而日志信号则使用了基于“名称空间+维度{K,V}”的哈希值。这种分组有助于降低下游Kafka消费者需要处理的数据量基数,从而有效地减少内存占用总量。
与我们的元数据存储入口守护进程类似,还有其他一些消费者将原始监控信号写入到后端存储,如Hadoop、HBase、Druid等。单独的发现管道可以在随后将这些原始监控信号输出,而无需执行昂贵的运行时聚合。
我们使用RocksDB作为元数据存储的嵌入式数据缓存,避免了对后端Elasticsearch数据接收器的重复写入。我们之所以选择RocksDB,是因为它的基准测试结果非常令人满意,并且具有很高的配置灵活性。
元数据存储入口守护程序在处理记录时,会将记录的键哈希与高速缓存中已存在的哈希进行对比。如果该记录尚未加载到缓存中,就将它写入Elasticsearch,并将其哈希键添加到缓存中。如果记录已存在于缓存中,则不执行任何操作。
RocksDB缓存偏重于读取,但在刚开始时(重置缓存)时出现了一连串写入。对于当前负载,读取超过了50亿,以及数千万的写入,大部分写入发生在前几分钟。因此,在刚开始时可能存在消费者滞后的情况。对于较低的读写延迟,我们努力将所有缓存数据保存在RocksDB的内存中,以避免二次磁盘存储查找。我们还禁用了预写日志(WAL)和压缩。在基准测试中,我们发现16GB的内存就足以存储哈希值。
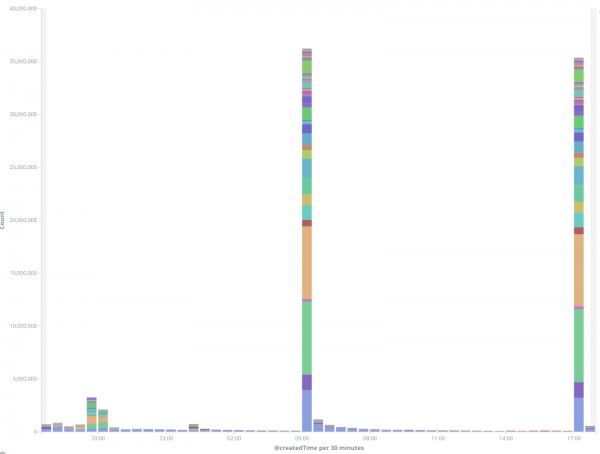
上图表示写入后端Elasticsearch的文档数。峰值对应于重置高速缓存之后的那段时间。
出于监控的目的,我们将所有rocksDB统计数据作为指标发送到我们的监控平台中。
我们使用Elasticsearch 6.x为后端聚合提供支持,用以识别监控信号中的不同属性。我们构建了一个包含30个节点的Elasticsearch集群,这些节点运行在配备了SSD和64 GB RAM的主机上,并通过我们的内部云平台来管理它们。我们为Elasticsearch JVM进程分配了30 GB内存,其余的留给操作系统。在摄取数据期间,基于监控信号中的不同元数据对文档进行哈希,以便唯一地标识文档。例如,根据名称空间、名称和不同的维度{K,V}对日志进行哈希处理。文档模型采用了父文档与子文档的格式,并按照名称空间和月份创建Elasticsearch索引。
我们根据{K,V}维度对根文档或父文档的document_id进行哈希处理,而子文档则根据名称空间、名称和时间戳进行哈希处理。我们为每一个时间窗口创建一个子文档,这个时间窗口也称为去抖动时段。去抖动时间戳是去抖动时段的开始时间。如果在去抖动期间发现了一个子文档,这意味着子文档的名称空间和名称的唯一组合与其父文档拓扑会一起出现。去抖动时间越短,发现唯一属性的时间近似就越好。Elasticsearch索引中的父文档和子文档之间存在1:N的关联关系。
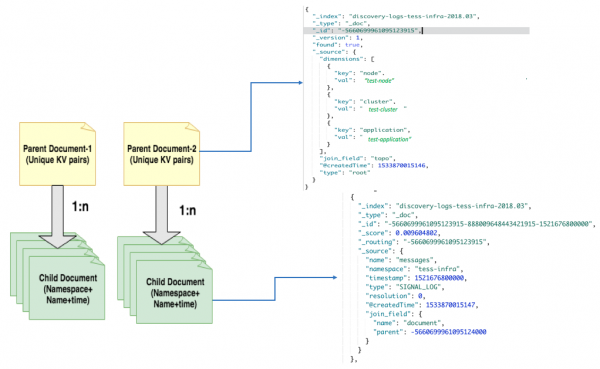
Elasticsearch中的父子文档动态模板是这样的:
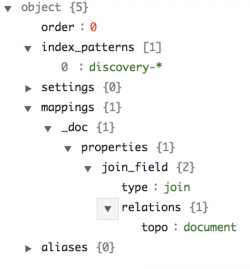
子文档的模板是这样的:

我们为Elasticsearch集群维护了两个负载均衡器(LB)。READ LB IP(VIP)用于客户端节点,负责所有的读取操作,WRITE LB VIP则用于数据节点。这样有助于我们在不同的客户端节点上执行基于聚合的计算,而不会给数据节点造成太大压力。
如果你要频繁更新同一个文档,那么Elasticsearch不是最好的选择,因为文档的片段合并操作非常昂贵。在出现高峰流量时,后台的文档片段合并会极大地影响索引和搜索性能。因此,我们在设计文档时将其视为不可变的。
我们使用以下的命名法为Elasticsearch集群创建索引:

例如,以下是后端Elasticsearch服务器的索引:

我们按照月份来维护索引,并保留三个月的索引。如果要清除索引,就直接删除它们。
我们的发现服务是一个作为Docker镜像进行部署的Web应用程序,它公开了REST API,用于查询后端元数据存储。
发现服务提供的关键REST API包括:
在不同的监控信号(日志/事件/指标)上查找名称空间(或用例);
查找给定时间范围内名称空间的所有名称;
根据输入的名称空间、名称列表或给定的时间范围查找所有监控信号的维度键值;
根据输入的名称空间和给定时间范围查找值键;
根据输入维度{K,V}过滤器查找所有名称空间或名称;
对于给定的名称空间、名称和不同的维度过滤器,还可以根据该唯一输入组合找到其他关联维度。
我们的元数据存储入口守护程序部署和托管在内部Kubernetes平台(也称为Tess.io)上。元数据存储入口守护程序的应用程序生命周期在Kubernetes上作为无状态应用程序进行管理。我们的托管Kubernetes平台允许在部署期间自定义指标注解,我们可以在Prometheus格式的已知端口上发布健康指标。监控仪表盘和警报是基于这些运行状况指标进行设置的。我们还在发现服务上公开了类似的指标,以捕获错误/成功率和平均搜索延迟。
性能
我们能够在10个元数据入口守护进程节点(下游Kafka消费者)上每分钟处理160万个指标信号而不会出现任何性能问题;
可以在几秒钟之内发现任何唯一的元数据属性;
在我们的生产环境中,我们的去抖动窗口间隔设置为12小时,在每个去抖动期间,我们拥有约4,000万的唯一基数(最多可达6000万)。
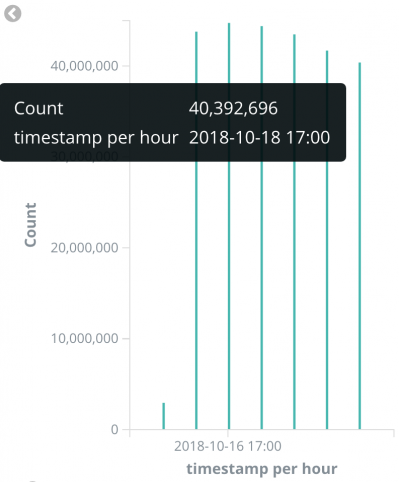
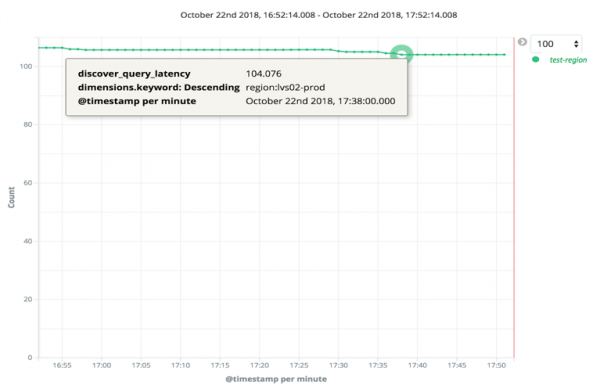
目前,我们发现生产环境中触发的大多数查询的平均延迟为100毫秒。而且我们发现,跨名称空间触发的查询比基于目标名称空间的查询要慢得多。
结论
将发现功能与实际数据管道分离让我们能够快速深入了解原始监控数据。元数据存储有助于限制需要查询的数据范围,从而显著提高整体搜索吞吐量。这种方法还可以保护原始数据存储免受发现服务的影响,从而为后端存储节省了大量的计算资源。
查看英文原文:https://www.ebayinc.com/stories/blogs/tech/an-approach-for-metadata-store-on-large-volume-data-sets/
eBay是如何进行大数据集元数据发现的相关推荐
- centos7 ambari2.6.1.5+hdp2.6.4.0 大数据集群安装部署
2019独角兽企业重金招聘Python工程师标准>>> 转载请务必注明原创地址为:http://dongkelun.com/2018/04/25/ambariConf/ 前言 本文是 ...
- 大数据集群搭建全部过程(Vmware虚拟机、hadoop、zookeeper、hive、flume、hbase、spark、yarn)
大数据集群搭建进度及问题总结 所有资料在评论区那里可以得到 第一章: 1.网关配置(参照文档) 注意事项:第一台虚拟机改了,改为centos 101 ,地址为192.168.181.130 网关依然是 ...
- 【大数据集群搭建-Apache】Apache版本进行大数据集群各组件环境部署
[大数据集群搭建-Apache]Apache版本进行大数据集群各组件环境部署 1)大数据环境统一 1.1.设置主机名和域名映射 1.2.关闭服务器防火墙和Selinux 1.3.服务器免密登陆 1.4 ...
- 那些年,我们迁移过的大数据集群
大数据集群迁移这件事,不知道有多少同学做过.我说的不是把一个集群的数据备份到另一个集群上.我指的是整个数据平台与大数据相关的所有集群及业务的迁移工作,从一个机房到另一个机房. 具体范围可能包括:从离线 ...
- 数据蒋堂 | 大数据集群该不该透明化?
作者:蒋步星 来源:数据蒋堂 本文约1500字,建议阅读5分钟. 通过本文为大家解读大数据集群透明化的利弊! 这好像是个多余的问题,大部分大数据平台都把集群透明化作为一个基本目标在努力实现. 所谓集群 ...
- 阿里云TSDB在大数据集群监控中的方案与实战
目前大部分的互联网企业基本上都有搭建自己的大数据集群,为了能更好让我们的大数据集群更加高效安全的工作,一个优秀的监控方案是必不可少的:所以今天给大家带来的这篇文章就是讲阿里云TSDB在上海某大型互联网 ...
- 大数据集群跨多版本升级、业务0中断,只因背后有TA
摘要:2021年4月21日,中国太平洋保险集团联合华为云完成了全球首例大数据集群跨多版本的大数据集群滚动升级. 本文分享自华为云社区<华为云FusionInsight助力太保跨多版本升级业务0中 ...
- 一篇运维老司机的大数据平台监控宝典(1)-联通大数据集群平台监控体系进程详解
一篇运维老司机的大数据平台监控宝典(1)-联通大数据集群平台监控体系进程详解 "如果你是一个经验丰富的运维开发人员,那么你一定知道ganglia.nagios.zabbix.elastics ...
- 小知识点:ARM 架构 Linux 大数据集群基础环境搭建(Hadoop、MySQL、Hive、Spark、Flink、ZK、Kafka、Nginx、Node)
换了 M2 芯片的 Mac,以前 x86 版本的 Linux 大数据集群基础环境搭建在 ARM 架构的虚拟机集群上有些用不了了,现在重新写一份基于 ARM 架构的,少数不兼容之外其他都差不多,相当 ...
最新文章
- 如何卸载office201032位_Office 2010如何手动卸载?
- Error: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-965200530-172.21.
- DM6467之视频采集(Linux)下MMAP
- Codeforces Round #632 (Div. 2) E. Road to 1600 构造好题
- Codeforces Round #498 (Div. 3) F. Xor-Paths
- os-enviroment
- jpa 托管_java – jpa非托管实体
- elasticsearch新增_SpringBoot 使用JestClient操作Elasticsearch
- 大学课程很少有教怎么设计单片机开发板,进阶板更不用说
- EXPLAIN查看SQL执行计划
- 【转】Excel表格的35招必学秘技
- erp352产品安装手册
- Word:外国人名字字母上加撇,怎么输入
- 爱奇艺连续三年独家直播中网赛事 打造高端体育赛事生态矩阵
- CAD地形图!DWG格式的等高线地形图下载教程
- 碎影录·番外·梦之章济南 by郝宗铎
- kaggle数据集下载步骤
- 全球投资移民青睐低气候风险地,最具气候韧性国家排名前五都在北半球 | 美通社头条...
- QCustomplot笔记(二)之QCustomplot 坐标轴属性设置
- ie11 java8 nc_IE8的项目在IE11下 一些功能无法实现的解决方案