Cassandra数据模型设计最佳实践
2019独角兽企业重金招聘Python工程师标准>>> 
本文是Cassandra数据模型设计第一篇(全两篇),该系列文章包含了eBay使用Cassandra数据模型设计的一些实践。其中一些最佳实践我们是通过社区学到的,有些对我们来说也是新知识,还有一些仍然具有争议性,可能在要通过进一步的实践才能从中获益。
本文中,我将会讲解一些基本的实践以及一个详细的例子。即使你不了解Cassandra,也应该能理解下面大多数内容。
说说Cassandra在ebay的使用情况
我们尝试使用Cassandra已经超过1年时间了。Cassandra现在正在服务一些用例,涉及到的业务从大量写操作的日志记录和跟踪,到一些混合工作。其中一项服务是我们的“Social Signal”项目,支撑着ebay的pruduct pages里like/own/want特性。我们开发的一些用例已经上线运行,但更多的还是处于开发阶段。
我们的Cassandra集群规模并不庞大,但正在稳步的增长中。在过去几个月里,我们共部署了几十个节点,它们分布在几个跨机房的小型集群中。你可能会问,为什么要多个集群?我们通过的职能部门和业务来划分集群。相同职能部门的相同业务的用例共享一个集群,但它们存在于不同的keyspaces中。
RedLaser, Hunch和其它ebay的合作伙伴也在尝试cassandra解决现实中各种问题。除了Cassandra,我们也在使用MongoDB和Hbase,本文中我不会讨论它们,但我相信它们都有各自的优点。
我相信此时你一定有很多问题,在这篇文章里暂时不会一一说明。在即将到来的Cassandra Summit大会,我将更详细的讲解我们每个用例场景,数据模型和多数据中心部署,以及经验教训和其它知识。
本文重点讲述我们在ebay应用的Cassandra数据模型设计最佳实践。下面让我们先看看这系列文章会用到的一些术语。
术语和约定
术语“Column Name” 和 “Column Key”被认为是一样的。同样的,“Super Column Name” 和 “Super Column Key”也认为是相同的。
下图表示一个 Column Family (简称CF)中的一个row

下图表示一个 Super Column Family (简称SCF)中的一个row

下图表示一个Column Family中一个row,它包含Composite Columns。Composite Columns的属性通过分隔符’|’连接。请注意,这里看到的只是数据的表现形式,Cassandra内置了Composite Column,它是一个对象,并不是使用’|’作为属性分隔符的字符串。(顺便说下,本文不要求你掌握Super Column和Composite Column方面知识。)

基于上面的内容,让我们开始第一个实践吧!
不要把Cassandra model想象成关系型数据库table
取而代之,应该把它想象成事一个有序的map结构。
对于一个新手来说,下面关系型数据库术语常常被对应到Cassandra模型
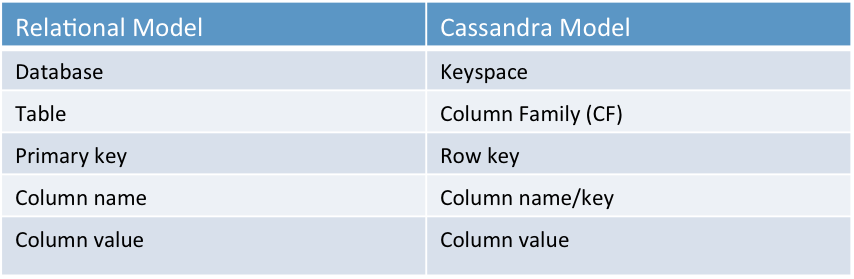
这种对比可以帮助我们从关系型数据库转换到非关系型数据库。但是当设计Cassandra column famiy的时候请不要这样去类比。取而代之,考虑它是一个map中嵌入另一个map:外部map的key为row key,内部map的key为column key,两个map的key都是有序的。如下:
双击代码全选1SortedMap<RowKey, SortedMap<ColumnKey, ColumnValue>>why?
将column family想象成嵌套的并排序的map比关系型数据库table描述的更为准确,它将帮助你正确的进行Cassandra模型设计。

How?
Map可以进行高效查询,同时排序的特性可以进行高效column扫描。在Cassandra中,我们可以使用row key和column key做高效查找和范围扫描
Column key的数量是很庞大的(译者注:目前译者所使用的Cassandra1.2.5版本,每个row支持最多20亿个columns)。换句话说你,你可以拥有一个wide rows。
Column key自身可以存储值,即你可以拥有一个没有值的column。
如果集群使用Order Preserving Partitioner (OOP)策略进行数据存储,就可以对row key进行范围查询。但是OOP大多数情况都不推荐使用(译者注:将rowkey按照顺序存储到节点上,如果分区不均匀,将导致数据读写不均衡),所以你可以认为外部的map是不排序的,如下:
双击代码全选1Map<RowKey, SortedMap<ColumnKey, ColumnValue>>上面提到的”Super Column”,认为它们是一组column,这样的话,两级嵌套map就会像下面展示的一样变为三级嵌套map:
双击代码全选1Map<RowKey, SortedMap<SuperColumnKey,双击代码全选1SortedMap<ColumnKey, ColumnValue>>>注意:
你需要传递timestamp给每个column value,因为Cassandra使用它做内部的冲突处理机制。但在建模过程中你可以忽略它(译者注:在操作column的时候timestamp信息会自动添加到column)。同时,不要考虑在你的程序中使用column的timestamp,因为它不是为你设计的,与Hbase不同,它们不会生成新的version数据(译者注:在Hbase中相同rowkey和column key的数据会保存多个version,而Cassandra会将相同数据覆盖,timestamp只保存最后一次更新的时间)。
因为Super Column的性能问题和缺乏二级索引支持问题,Cassandra社区对它的使用曾有过强烈争议。所以,推荐使用Composite Columns代替Super Column实现功能。(译者注:使用Super Column,如果你要获取其中一个columnvalue,则要扫描整个Super Column,这会导致查询性能很糟糕)
围绕着查询模式进行Column Family建模
建模尽量从实体和它们的关系开始
与关系型数据库不同,在Cassandra中通过创建二级索引或者编写复杂SQL(使用joins, order by, group by)来新建或修改查询不是件容易的事情。因为Cassandra具有很高的分布式特性,所以要先考虑查询模式,然后再设计column family。
牢记前面提到的嵌入排序map数据结构,在考虑如何组织你的数据到map,以满足快速查询/排序/分组/过滤/聚合的要求。
在大部分情况下,实体和它们的关系是很重要的(特殊用例除外,如日志存储或者其它时间序列数据)。如果我给你一个查询模式,用于为一个电子商务网站创建Cassandra模型,但不告诉你任何实体和它们的关系。你会有意或者无意的从查询模式或者从你之前领域对象的理解找出实体和它们之间的关系(因为我们是通过实体和关系来描述真实世界)。在设计数据模型时最好从实体和关系开始,然后使用反范式化和冗余的方式继续围绕查询模式建模。如果这听起来有些让人困惑,通过后面的详细例子就可以理解。
注意:在建模的时候考虑以下几点会很有帮助。区分频次大的查询和频次小的查询,有些查询可能只被查询几千次,其它可能被查询数十亿次;还要考虑哪些查询对数据延迟是敏感的。确保你的模型优先满足查询频次大的查询和重要查询。
为提升读性能进行反范式化(De-normalize)和冗余
根据实际情况,如果不需要就不要反范式化。
在关系型数据库的世界里,范式化的优点是显而易见的:较少的数据冗余,较少的数据修改异常,概念更清晰,更容易维护等等;同样,它的缺点也十分明显:多表join查询会很慢等等。这两方面也会体现在Cassandra中,但是缺点会更明显,因为Cassandra数据是分布式存储,当然它也并不支持join操作。所以,对于一个完全范式化的schema,Cassandra读操作性能可能比RDBMS更糟糕,所以我们通常通过反范式化来提升查询性能。(译者注:Cassandra一次查询可能会请求多个节点并将结果汇总到客户端,而RDBMS查询只需从本地查询即可)。
这个实践和上一个查询建模实践是非常重要的,我会在余下的文章中通过一个详细的例子做进一步说明。
注意:下面我们要讨论的例子只是个演示,它不代表eBayCassandra项目的数据模型。
实战:User和Item中间的’Like’关系
这个示例是关于电子商务系统的一个功能,一个user可以喜欢多个item,同时一个item可以被多个user所喜爱,在关系型数据库中这个关系是通过many-to-many实现的,如下图所示:
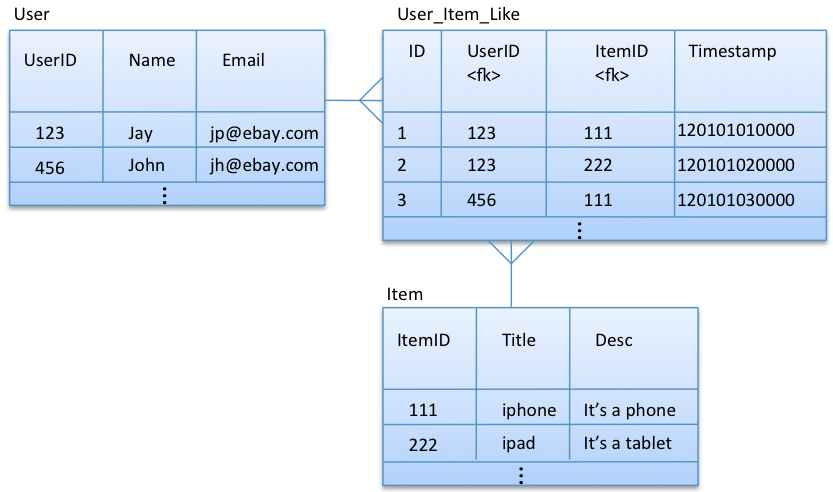
通过上面的模型,我们可以进行如下查询:
通过user id获取user
通过item id获取item
获取指定user喜欢的所有item
查看指定item被那些user所喜爱
下面将介绍几个通过Cassandra建模解决上面问题的现方案,反范式的顺序从低到高。你会发现最佳方案依赖于查询模式。
方案1:完全按照关系数据库模型设计

这个模型支持通过user id查询user和通过item id查询item。但无法简单查询某个user喜爱的所有item或者某个item被那些user所喜爱。
对于这个用例来说,这是最糟糕的设计,主要是因为User_Item_Like没有设计好。
注意:为了简单起见,关系型数据模型中的timestamp字段没有体现到Cassandra模型中(这个字段用于存储user何时喜爱某个item),我会在后面介绍它。
方案2:使用自定义索引范式化实体

这个模型中User和Item是范式化实体,user id 和item id被映射存储两次,第一次是通过item id存储user id(User_By_Item),第二次通过item id存储user id(Item_By_User)。
这样,我们很容易可以通过Item_By_User查询某个user喜欢的全部item,还可以通过User_By_Item查询某个item被哪些user所喜爱。这里我们使用了,Item_By_User和User_By_Item这两个column family作为自定义二级索引。(译者注:Cassandra column family也有二级索引功能,它的作用是通过创建column key索引快速查询到column value)。
有这样一个场景,我们总是希望通过指定user查询其喜爱的item,同时要获取item title信息。在当前模型下,我们首先要通过Item_By_User获取指定user关联的item id,然后根据这些item id依次查询Item模型获取title信息,反之亦然。一个item有可能被几百个user所喜爱,或者一个活跃user可能喜爱许多item,基于当前的模型设计,将会导致很多额外的查询。所以,最好通过反范式‘Item_by_User’ 中的itemtitle和’ User_by_Item’中的username信息来优化查询,方案3将会向大家展示。
注意:即使你可以批量读取(译者注:在Cassandra Java客户端hector中可以MultigetSliceQuery类实现一次查询传入多个rowkey),但它们将仍然很慢,因为Cassandra底层仍然会单独查询每个rowkey,然后通过Coordinator 节点(译者注:Coordinator 节点为Cassandra客户端直接请求的节点,可以理解为它是一个代理)汇总到客户端。批量读取可以避免请求的往返耗时,它是个不错的选择,你可以去尝试它。
方案三:范式化实体,并将它们反范式化到自定义索引
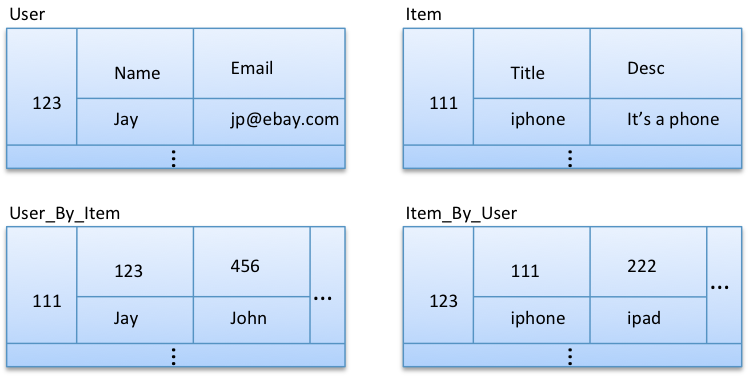
在这个模型中,title和username被分别反范式到User_By_Item和Item_By_User。这样将允许我们高效查询指定user喜爱的所有item,以及喜爱指定item所有的user。这样我们就为整个用例做了很大的反范式化工作。
问题又来了,如何获取指定user喜爱item的具体信息(title,desc,price等等)?首先我们要问问自己我们是否真的需要这个查询。还是上面的例子,当用户希望获取item额外信息的时候,我们可以在页面上展示所有的item title,当点击item title时,在打开的新页面显示这个item的具体信息。所以,在这个用例中我们最好不要极端反范式化。(item title列表中通常还会显示title和price信息,这也很容易实现,这个就留给大家做练习)
让我们考虑下面两个查询:
通过所给item id,获取具体item信息(title, desc等等),并一同查询喜欢这个item的user name
通过所给的user id,获取具体user信息,并一同查询user喜欢的所有item titile
上面两个查询出现在查询item和user的详情页面是很正常的,这些在当前模型中可以很好的实现。两者都需要两次查询,一次查询item(或者user)信息,另一次查询user name(或者item title)。User变得更加活跃的(喜欢上千个items)或者item变得很热门(被几百万user喜爱),查询的次数不会随之增加,仍然为两次。这很好,当我们从方案2到方案3,反范式化并没有让我们变糟糕。让我们看看方案4如何做更进一步的优化。
方案4:范式化部分实体

很明显,方案4看起来有些凌乱。在数据存储结构上,它与方案3也不同。
如果User和Item之间是高度关联的实体(类似ebay),相比当前方案我将更倾向于方案3。
因为我们不打算反范式化所有item属性到User实体或者反范式化所有user属性到Item实体,所以这里我们使用了部分范式化。我不会打算进行极限反范式化(让所有time属性到User实体和所有user属性到Item实体),因为在这个用例中那样做是没有意义的。
注意:这里我使用Super Column只是为了给展示。大多情况,应该倾向于使用composite columns,而不是Super Column。
最佳模型
在本文的用例中方案3是优胜者。上面的方案中我们忽略了timestamp信息,下面我们将把它以timeuuid(type-1 uuid)形式添加到最终模型上。注意,在User_By_Item实体中timeuuid和userid合并为一个composite column key,在Item_By_user实体中timeuuid和item id合并为一个composite column key。
回想一下,column key是有序存储的。这里我们的User_By_Item 和 Item_By_User两个实体的column keys通过timeuid排序后被存储到磁盘,这使得基于时间的范围查询非常高效。在这个模型中,我们不需要读取一个row中所有column,就可以高效的查询某个item最近被哪些user所喜爱,以及某个用户最近喜欢了哪些item。
最终模型如下:

总结
我们通过一些基本的实践和详细例子帮你开启Cassandra数据建模之旅。下面是一些关键点:
当设计Cassandra列族时,不要把它想成是关系表,要把它想成是嵌套的、排序的map数据结构。
要围绕着查询来设计列族,从设计实体及其关系开始。
在需要的时候,通过反范式化和冗余来提升读性能。
记住有多种方式创建模型,最佳的方式依赖于你的用例和查询模式。
这里我没有提到其它常用的用例,如日志记录、监控、实时分析(rollups, counters),或者时间序列。但是,我们讨论的实践也适用于它们。此外,有些众所周知的技术和模式用于时间序列的模型设计。在eBay,我们也使用这些技术,也乐于在后续的文章中分享这些。关于时间序列数据建模,我推荐你阅读 Advanced time series with Cassandra 和 Metric collection and storage,如果你是Cassandra新手,请先阅读DataStax documentation。
1.2文档
http://www.datastax.com/documentation/cassandra/1.2/pdf/cassandra12.pdf
原文链接:http://www.ebaytechblog.com/2012/07/16/cassandra-data-modeling-best-practices-part-1/
转载于:https://my.oschina.net/laigous/blog/167599
Cassandra数据模型设计最佳实践相关推荐
- 【报告分享】中国数据智能应用趋势报告:解码数据中台最佳实践,企业数字化转型新引擎.pdf(附下载链接)...
大家好,我是文文(微信:sscbg2020),今天给大家分享爱分析于2020年10月份发布的报告<中国数据智能应用趋势报告:企业数字化转型新引擎,解码数据中台最佳实践.pdf>,希望对您有 ...
- 学习sql注入:猜测数据库_学习SQL:删除和更新数据SQL最佳实践
学习sql注入:猜测数据库 Deleting and updating data is very common, but if performed without taking care, which ...
- 科大讯飞交通超脑荣获 2019 年大数据应用最佳实践案例 TOP10
12月5日,由中国计算机学会主办,CCF 大数据专家委员会承办的中国大数据技术大会(BDTC 2019)在北京长城饭店隆重举行.会上揭晓了由CCF大数据专家委员会组织评选的大数据应用最佳实践案例TOP ...
- OLTP类系统数据结转最佳实践
本文着重介绍了京东数据结转平台的技术架构,及OLTP类系统数据结转最佳实践,探讨解决大数据背景下的数据结转问题. 一. 背景介绍 业务系统在长期运行的过程中会积累大量的数据,这些数据有些是需要长期保存 ...
- 【TOP100】100个中国大数据应用最佳实践案例—为您打开万亿元大数据产业的财富之门
热门下载(点击标题即可阅读) ☞[下载]2015中国数据分析师行业峰会精彩PPT下载(共计21个文件) 2017年3月28日至29日,由工业和信息化部指导.中国信息通信研究院和数据中心联盟主办的&qu ...
- Kyligence 客户案例“泰康集团精细化经营分析与运营平台”获评数据智能最佳实践案例
近日,"2022 爱分析·中国数据智能最佳实践案例"评选结果正式揭晓.Kyligence 携手泰康集团申报的"泰康集团精细化经营分析与运营平台"项目经过多轮角逐 ...
- 帆软行业总监陈鹏:从500强企业看企业数据应用最佳实践
近日,畅享网携手appcan成功举办企业"移动化"案例分享沙龙.本次沙龙由新城控股集团星翼空间总经理從申主持,精准聚焦"移动化"成功转型案例.会上,各位IT专业 ...
- 数禾云上数据湖最佳实践
简介: 数禾科技从成立伊始就组建了大数据团队并搭建了大数据平台.并在ECS上搭建了自己的Cloudera Hadoop集群.但随着公司互联网金融业务的快速扩张发展,大数据团队承担的责任也越来越重,实时 ...
- UI效率实用素材|WEB数据可视化最佳实践
数据可视化已经迅速成为在web上传播信息的标准.它被广泛应用于从商业智能到新闻业的各个行业,以帮助我们理解和交流数据中的洞察力. 我们的大脑习惯于处理可视化的信息,这使得我们更容易理解图表中的数据,而 ...
最新文章
- deeplearning模型库
- 登上更高峰!颜水成、程明明团队开源ViP,引入三维信息编码机制,无需卷积与注意力...
- vue.js学习系列-第二篇
- pip install 报错:Versioning for this project requires either an sdist tarball, ...
- js 判断变量是否有值返回bool_有没有办法可以获得javascript函数返回值里的bool值,代码如下:...
- 单片机最小系统制作记录
- 从NBear到ADO.NET Entity Framework让我迷惑了
- 时光机穿梭---管理修改
- 【kafka】记一次线上kafka一直rebalance故障 消费慢 数据积压
- 设置VS2015背景图片(转载)
- 数据结构与算法python—5.队列及python实现与leetcode总结
- 三步教你配置Java环境
- 中继段光缆测试与用户光缆测试有什么区别?
- 小爱音箱mini系统故障怎么办_小编处理win7系统连接小爱音箱mini的解决教程
- netkeeper客户端_Netkeeper校园客户端(创翼客户端)下载
- linux 重命名文件夹
- 计算机社团感恩节免费维修周策划书,【关于感恩节的活动策划】大学感恩节活动策划案_早教感恩节活动策划方案_(2)_亲亲宝贝网...
- WPF制作表示透明区域的马赛克画刷
- 动态红包封面来了,特效拉满超炫酷
- 俄罗斯 搜索引擎 邮箱创建