大数据Scala编程.问题集(02)
大数据Scala编程.问题集(02)
by 高焕堂
洞庭国际智能硬件检测基地 & 中云大数据中心(IDC) 首席架构师
微博:@高焕堂_台北
Q-02: Scala语言的trait具有什么设计涵意?
Answer:
大家都知道接口(Interface)的概念,也知道一个类(Class)或一个模块(Module)能实现多个接口。就像一个房间可以有多个门,或一座四合院可以有多个门口一样。如下图:
将四合院的概念对应到软件上,一个软件的类可以实践多个接口,如下图:
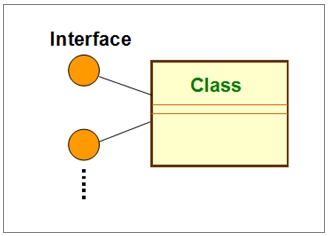
现在,先拿一个类和一个接口的设计架构来看看,如下图:
在一般软件设计上,接口(Interface)意味着:它就是一个纯粹抽象类(Pure abstract class)。也就是说,它内含一个或多个抽象函数(Abstract function),而且是公用(Public)的函数。Gamma等人在其所着 Design Patterns书里主张:
"Program to an interface, not an implementation."
(针对接口而写编程,不要针对实现。)
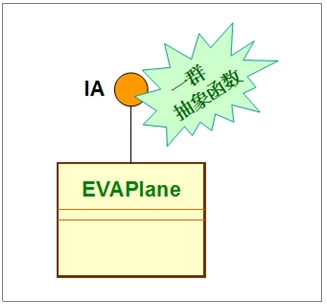
这意味了,通常架构师(团队)会先设计好接口,然后工程师(团队)再依循接口的定义而开发实现代码。于是,架构师团队与工程师团队,两个团队之间是相互分工合作(Collaboration)的。
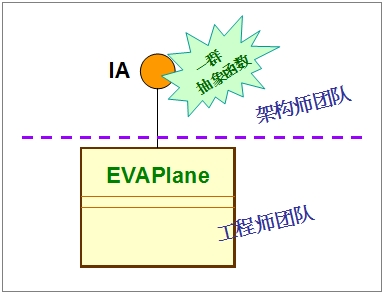
由于架构师团队里,也常常含有开发者(或架构师兼工程师),因而也常常会去写一些代码,来实现接口里的抽象函数,提供一些接口的默认行为(Default behavior)。此时,所设计的架构会变成为:
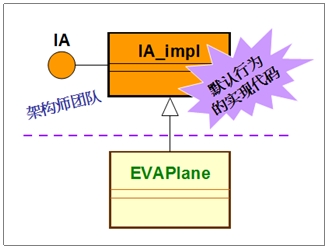
将上图里的IA接口和IA_impl类,看成一个整体,特别称之为特性(Trait),如下图:
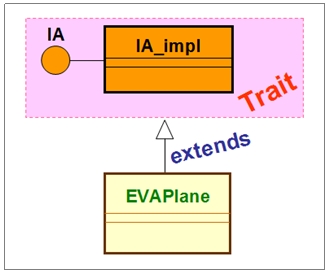
以上是从架构设计的角度来思考的,若对应到Scala代码,可表示如下:
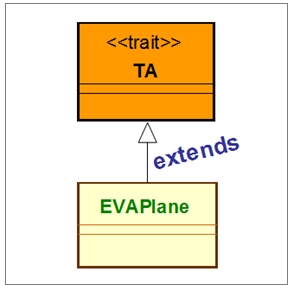
// trait的定义
trait TA {
def transact(){ //默认行为代码
onTransact // 调用抽象函数
}
def onTransact // 抽象函数
}
// class的定义
class EVAPlane extends TA {
var manufacturer : String = ""
var capacity : Int = 0
var mfr_date : String = ""
def pr_capacity {
println(capacity)
}
def onTransact {
println("this is onTransact.")
}
}
// myApp
object myApp {
def main( args: Array[String] ) {
val p1 = new EVAPlane
val p2 = new EVAPlane
p1.transact
p2.transact
}
由于Scala代码编译(Compile)时,会转换成为JVM引擎可执行的ByeCode,其受限于JVM引擎的单继承(Single inheritance)的限制。在Scala语言里,无法实践架构师的多重接口及其默认行为的架构设计,如下:
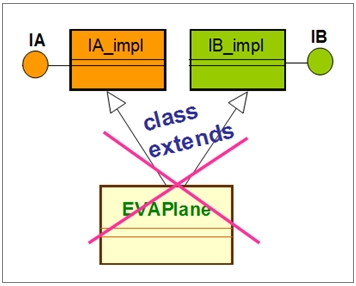
但是,却能善用Scala的Trait来实践之,如下:
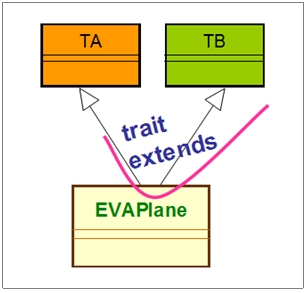
Scala借重JVM引擎的多重接口实现(Implement)机制,以及对象委托(Delegation)机制来实践上图的trait extends机制;而不是依赖 JVM引擎原有的class extends机制。如下图:
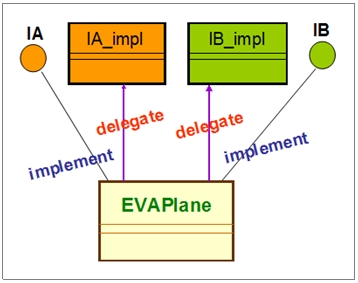
运用了JVM引擎级别的Implement和Delegation机制来实践Scala源代码级别的trait extends机制。如下图:
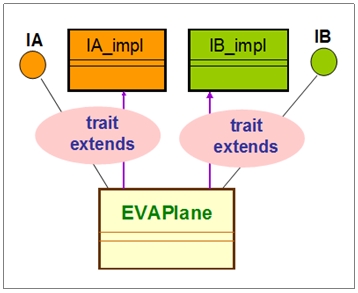
这样,一方面架构师团队可以定义其接口(Interface),例如设计出下图里的IA和IB,并撰写其接口的默认行为(Default behavior)代码,如下图里的IA_impl和IB_impl类,并以Scala的trait形式表达出来。
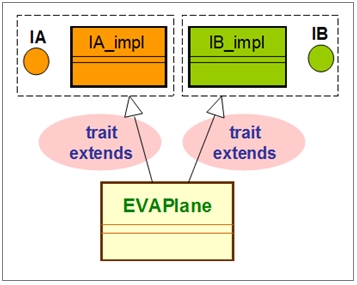
然后,将该trait交给工程师团队去撰写EVAPlane类或其子类的实现代码。达成了架构师团队与工程师团队的美好分工合作了;也实践了 "Program to an interface, not an implementation."(针对接口而写编程,不要针对实现。)的设计原则。
高老师陪您成长...

請繼續學習:高老師的相關視頻
相关文章:大数据Scala编程问题集(01)
相关文章:大数据Scala编程问题集(03)
~ end ~
大数据Scala编程.问题集(02)相关推荐
- 尚硅谷大数据技术Spark教程-笔记02【SparkCore(核心编程,map、mapPartitions、mapPartitionsWithIndex、flatMap、glom、groupBy)】
视频地址:尚硅谷大数据Spark教程从入门到精通_哔哩哔哩_bilibili 尚硅谷大数据技术Spark教程-笔记01[Spark(概述.快速上手.运行环境.运行架构)] 尚硅谷大数据技术Spark教 ...
- 大数据平台搭建及集群规划
CDH大数据平台搭建之集群规划_码上_成功的博客-CSDN博客_cdh集群规划 大数据Hadoop分布式集群部署(详细版)_arnoldmp的博客-CSDN博客_分布式集群部署 大数据平台的硬件规划. ...
- 《深入理解Hadoop(原书第2版)》——1.3大数据的编程模型
本节书摘来自华章计算机<深入理解Hadoop(原书第2版)>一书中的第1章,第1.3节,作者 [美]萨米尔·瓦德卡(Sameer Wadkar),马杜·西德林埃(Madhu Siddali ...
- 大数据之路读书笔记-02日志采集
大数据之路读书笔记-02日志采集 数据采集作为阿里大数据系统体系的第 环尤为重要.因此阿里巴巴建立了一套标准的数据采集体系方案,致力全面.高性能.规范地完成海量数据的采集,并将其传输到大数据平台.本章 ...
- 尚硅谷大数据技术Hadoop教程-笔记02【Hadoop-入门】
视频地址:尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优) 尚硅谷大数据技术Hadoop教程-笔记01[大数据概论] 尚硅谷大数据技术Hadoop教程-笔记02[Hadoop-入 ...
- 大数据Hadoop教程-学习笔记02【Apache Hadoop、HDFS】
视频教程:哔哩哔哩网站:黑马大数据Hadoop入门视频教程 教程资源:https://pan.baidu.com/s/1WYgyI3KgbzKzFD639lA-_g 提取码: 6666 [P001-P ...
- 大数据基础编程第二版(林子雨)官网,代码与软件资源
官网:大数据基础编程.实验和案例教程(第2版)教材官网_厦门大学数据库实验室 (xmu.edu.cn) 教材对应使用软件.代码,百度网盘:百度网盘 请输入提取码 (baidu.com) 提取码请至官网 ...
- CDH大数据平台搭建之集群规划
CDH大数据平台搭建之集群规划 前言 一.集群规模 二.集群规划 总结 前言 话说无规矩不成方圆,搭建CDH大数据平台之前需要的工作很多,首先,你需要计算公司每日的数据量,来确定需要多少服务器,确定好 ...
- 【大数据数仓项目集群配置 一】
本文用于记录我的第一次内网大数据集群配置过程. 本篇主要实现基础配置. 配置使用的软件版本和脚本参考自尚硅谷,链接如下: 链接: https://www.bilibili.com/video/BV1r ...
最新文章
- 离线轻量级大数据平台Spark之MLib机器学习库概念学习
- 京东智能巡检机器人问世 京东金融进军企业服务新蓝海
- access 查找工龄大于30_同济大学大学计算机access作业答案
- 机器学习如何选择模型 机器学习与数据挖掘区别 深度学习科普
- 牛客网暑期ACM多校训练营(第一场)J Different Integers
- Android集成三方浏览器之Crosswalk
- P2754 [CTSC1999]家园 / 星际转移问题(网络流)
- vector 清空 Linux,STL容器vector基础用法小结
- 牛客网暑期ACM多校训练营(第三场): C. Chiaki Sequence Reloaded(数位DP)
- 杭电oj1257最少拦截系统(贪心)
- r语言集合补集_极速统计教程之八 | 概率和集合
- 基于Netty和Java的GUI界面实现在线聊天室软件
- word怎么显示左边目录?目录大纲(视图 --> 导航窗格)
- Win7旗舰版 安装步骤
- c语言水仙花数7位数,C语言水仙花数的实现
- 84键键盘没有insert键
- 地图做显示定位蓝点时遇到的问题
- 什么是增值税的进项税和销项税?
- 在外企当程序员是怎样的体验?
- C# 打印照片和文档