《CUDA C编程权威指南》——3.4 避免分支分化
本节书摘来自华章计算机《CUDA C编程权威指南》一书中的第3章,第3.4节,作者 [美] 马克斯·格罗斯曼(Max Grossman),译 颜成钢 殷建 李亮,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.4 避免分支分化
有时,控制流依赖于线程索引。线程束中的条件执行可能引起线程束分化,这会导致内核性能变差。通过重新组织数据的获取模式,可以减少或避免线程束分化。在本节里,将会以并行归约为例,介绍避免分支分化的基本技术。
3.4.1 并行归约问题
假设要对一个有N个元素的整数数组求和。使用如下的串行代码很容易实现算法:
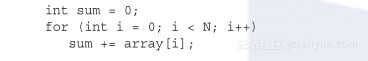
如果有大量的数据元素会怎么样呢?如何通过并行计算快速求和呢?鉴于加法的结合律和交换律,数组元素可以以任何顺序求和。所以可以用以下的方法执行并行加法运算:
- 将输入向量划分到更小的数据块中。
- 用一个线程计算一个数据块的部分和。
- 对每个数据块的部分和再求和得出最终结果。
并行加法的一个常用方法是使用迭代成对实现。一个数据块只包含一对元素,并且一个线程对这两个元素求和产生一个局部结果。然后,这些局部结果在最初的输入向量中就地保存。这些新值被作为下一次迭代求和的输入值。因为输入值的数量在每一次迭代后会减半,当输出向量的长度达到1时,最终的和就已经被计算出来了。
根据每次迭代后输出元素就地存储的位置,成对的并行求和实现可以被进一步分为以下两种类型:
- 相邻配对:元素与它们直接相邻的元素配对
- 交错配对:根据给定的跨度配对元素
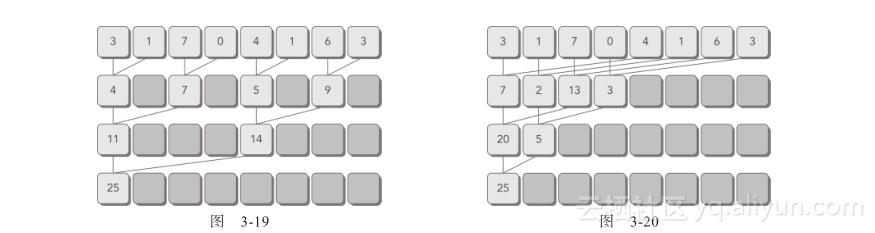
图3-19所示为相邻配对的实现。在每一步实现中,一个线程对两个相邻元素进行操作,产生部分和。对于有N个元素的数组,这种实现方式需要N―1次求和,进行log2 N步。
图3-20所示为交错配对的实现。值得注意的是,在这种实现方法的每一步中,一个线程的输入是输入数组长度的一半。
下列的C语言函数是一个交错配对方法的递归实现:


尽管以上代码实现的是加法,但任何满足交换律和结合律的运算都可以代替加法。例如,通过调用max代替求和运算,就可以计算输入向量中的最大值。其他有效运算的例子有最小值、平均值和乘积。
在向量中执行满足交换律和结合律的运算,被称为归约问题。并行归约问题是这种运算的并行执行。并行归约是一种最常见的并行模式,并且是许多并行算法中的一个关键运算。
在本节里,会实现多个不同的并行归约核函数,并且将测试不同的实现是如何影响内核性能的。
3.4.2 并行归约中的分化
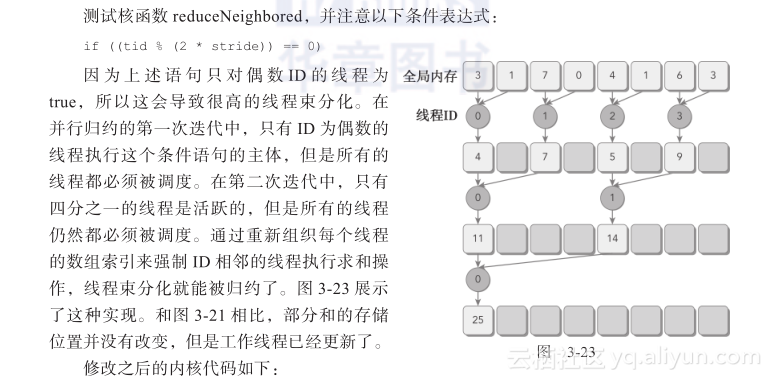
图3-21所示的是相邻配对方法的内核实现流程。每个线程将相邻的两个元素相加产生部分和。
在这个内核里,有两个全局内存数组:一个大数组用来存放整个数组,进行归约;另一个小数组用来存放每个线程块的部分和。每个线程块在数组的一部分上独立地执行操作。循环中迭代一次执行一个归约步骤。归约是在就地完成的,这意味着在每一步,全局内存里的值都被部分和替代。__syncthreads语句可以保证,线程块中的任一线程在进入下一次迭代之前,在当前迭代里每个线程的所有部分和都被保存在了全局内存中。进入下一次迭代的所有线程都使用上一步产生的数值。在最后一个循环以后,整个线程块的和被保存进全局内存中。
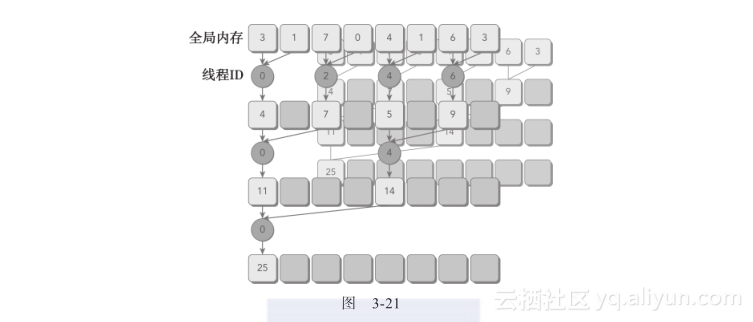

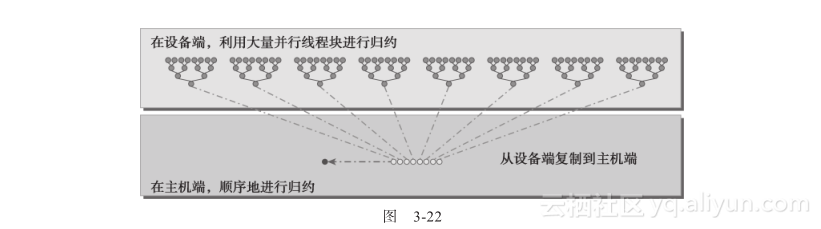
两个相邻元素间的距离被称为跨度,初始化均为1。在每一次归约循环结束后,这个间隔就被乘以2。在第一次循环结束后,idata(全局数据指针)的偶数元素将会被部分和替代。在第二次循环结束后,idata的每四个元素将会被新产生的部分和替代。因为线程块间无法同步,所以每个线程块产生的部分和被复制回了主机,并且在那儿进行串行求和,如图3-22所示。
从Wrox.com上可以找到reduceInteger.cu完整的源代码。代码清单3-3只列出了主函数。


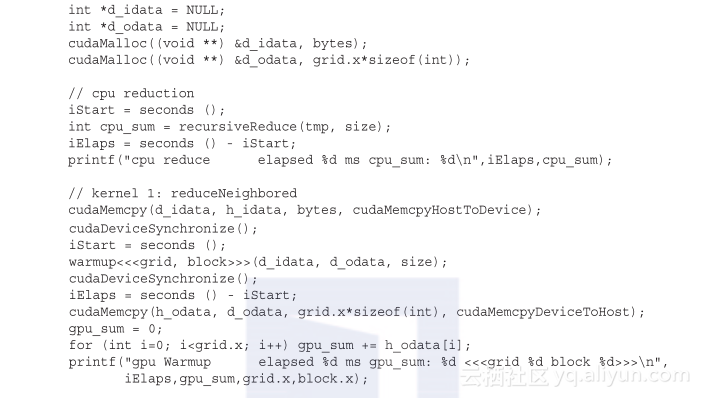


初始化输入数组,使其包含16M元素:
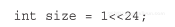
然后,内核被配置为一维网格和一维块:

用以下的命令编译文件:

运行可执行文件,以下是运行结果。

在接下来的一节中,这些结果将会被作为性能调节的基准。
3.4.3 改善并行归约的分化

注意内核中的下述语句,它为每个线程设置数组访问索引:

因为跨度乘以了2,所以下面的语句使用线程块的前半部分来执行求和操作:

对于一个有512个线程的块来说,前8个线程束执行第一轮归约,剩下8个线程束什么也不做。在第二轮里,前4个线程束执行归约,剩下12个线程束什么也不做。因此,这样就彻底不存在分化了。在最后五轮中,当每一轮的线程总数小于线程束的大小时,分化就会出现。在下一节将会介绍如何处理这一问题。
在主函数里调用基准内核之后,通过以下代码段可以调用这个新内核。

用reduceNeighboredLess函数测试,较早的核函数将产生如下报告:

新的实现比原来的快了1.26倍。
可以通过测试不同的指标来解释这两个内核之间的不同行为。用inst_per_warp指标来查看每个线程束上执行指令数量的平均值。
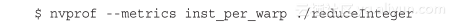
结果总结如下,原来的内核在每个线程束里执行的指令数是新内核的两倍多,它是原来实现高分化的一个指示器:

用gld_throughput指标来查看内存加载吞吐量:

结果总结如下,新的实现拥有更高的加载吞吐量,因为虽然I/O操作数量相同,但是其耗时更短:

3.4.4 交错配对的归约
与相邻配对方法相比,交错配对方法颠倒了元素的跨度。初始跨度是线程块大小的一半,然后在每次迭代中减少一半(如图3-24所示)。在每次循环中,每个线程对两个被当前跨度隔开的元素进行求和,以产生一个部分和。与图3-23相比,交错归约的工作线程没有变化。但是,每个线程在全局内存中的加载/存储位置是不同的。
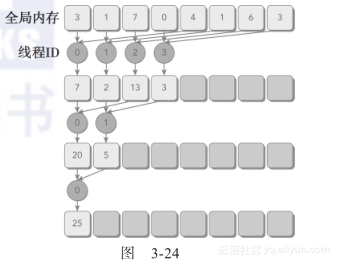
交错归约的内核代码如下所示:


注意核函数中的下述语句,两个元素间的跨度被初始化为线程块大小的一半,然后在每次循环中减少一半:

下面的语句在第一次迭代时强制线程块中的前半部分线程执行求和操作,第二次迭代时是线程块的前四分之一,以此类推:

下面的代码增加到主函数中,执行交错归约的代码:

用reduceInterleaved函数进行测试,较早的内核函数将产生如下报告:

交错实现比第一个实现快了1.69倍,比第二个实现快了1.34倍。这种性能的提升主要是由reduceInterleaved函数里的全局内存加载/存储模式导致的。在第4章里会介绍更多有关于全局内存加载/存储模式对内核性能的影响。reduceInterleaved函数和reduceNeigh-boredLess函数维持相同的线程束分化。
《CUDA C编程权威指南》——3.4 避免分支分化相关推荐
- 《CUDA C编程权威指南》——1.5节总结
本节书摘来自华章社区<CUDA C编程权威指南>一书中的第1章,第1.5节总结,作者[美] 马克斯·格罗斯曼(Max Grossman) ,更多章节内容可以访问云栖社区"华章社区 ...
- c cuda 指定gpu_《CUDA C编程权威指南》——1.3 用GPU输出Hello World-阿里云开发者社区...
本节书摘来自华章计算机<CUDA C编程权威指南>一书中的第1章,第1.3节,作者 [美] 马克斯·格罗斯曼(Max Grossman),译 颜成钢 殷建 李亮,更多章节内容可以访问云栖社 ...
- 《CUDA C编程权威指南》——2.2 给核函数计时
本节书摘来自华章计算机<CUDA C编程权威指南>一书中的第2章,第2.2节,作者 [美] 马克斯·格罗斯曼(Max Grossman),译 颜成钢 殷建 李亮,更多章节内容可以访问云栖社 ...
- 《CUDA C编程权威指南》——2.4节设备管理
本节书摘来自华章社区<CUDA C编程权威指南>一书中的第2章,第2.4节设备管理,作者[美] 马克斯·格罗斯曼(Max Grossman) ,更多章节内容可以访问云栖社区"华章 ...
- CUDA C 编程权威指南 Grossman 第4章 全局内存
4.1 CUDA内存模型概述 内存访问和管理是所有编程语言的重要部分. 因为多数工作负载被加载和存储数据的速度所限制,所以有大量低延迟.高带宽的内存对性能是十分有利的. 大容量.低延迟的内存造价高且不 ...
- cuda C 编程权威指南 Grossman 第2章 CUDA编程模型
2.1 CUDA编程模型概述 CUDA编程模型提供了一个计算机架构抽象作为应用程序和其可用硬件之间的桥梁. 通信抽象是程序与编程模型实现之间的分界线,它通过专业的硬件原语和操作系统的编译器或库来实现. ...
- 《CUDA C编程权威指南》——导读
###前 言 欢迎来到用CUDA C进行异构并行编程的奇妙世界! 现代的异构系统正朝一个充满无限计算可能性的未来发展.异构计算正在不断被应用到新的计算领域-从科学到数据库,再到机器学习的方方面面.编程 ...
- CUDA C编程权威指南 第二章 CUDA编程模型
CUDA6.0开始 有"统一寻址"(Unified Memory)编程模型,可以用单个指针访问CPU和GPU内存,无须手动拷贝 主机启动内核后,管理权立刻返回给主机(类似启动线程后 ...
- CUDA C 编程权威指南 Grossman 第9章 多GPU编程
在一个计算节点内或者跨多个GPU加速节点实现跨GPU扩展应用. CUDA提供了大量实现多GPU编程的功能,包括:在一个或多个进程中管理多设备,使用统一的虚拟寻址(Unifined Virtual Ad ...
最新文章
- psp用ps1模拟器_电脑上ps1和fc模拟器资源下载,包含当年ps1上的西游记和霸王的大陆复刻版...
- ios 处理WKContentView的crash
- 刀片服务器 如何增加硬盘,IBM为刀片服务器添加新SAS及固态硬盘
- Django中related_name的作用
- 用servlet设计OA管理系统时遇到问题
- [css] 为什么float会导致父元素塌陷
- Linux学习笔记(四)之查看登录用户
- 推荐一款好用的加密软件 filepackage 文件加密 U盘加密 移动硬盘加密
- 开发板 linux 同步时间,arm开发板使用ntp与服务器同步时间
- OpenHarmony2.0 一站式编译烧录Hi3516标准系统
- Oracle 常用 语句
- 嵌入式Uboot,通过tftp进行内核镜像的加载及flash写入
- 在电商平台落地大数据应用的6个场景、2类服务、12个框架
- C语言矩阵运算器,实现矩阵加法、减法、乘法、转置和退出。
- matlab中图像压缩
- 机器学习中的独立同分布(I.I.D.)假设
- 关于MySQL认证的东东
- 01背包问题【回溯法求解】通俗易懂,适合小白
- 问答网站Quora副总裁杨蕾博士:让知识改变世界
- Linux 安装FastDFS 图解教程