大数据教程(13.6)sqoop使用教程
2019独角兽企业重金招聘Python工程师标准>>> 
上一章节,介绍了sqoop数据迁移工具安装以及简单导入实例的相关知识;本篇博客,博主将继续为小伙伴们分享sqoop的使用。
一、sqoop数据导入
(1)、导入关系表到HIVE
./sqoop import --connect jdbc:mysql://centos-aaron-03:3306/test --username root --password 123456 --table emp --hive-import --m 1执行报错
[hadoop@centos-aaron-h1 bin]$ ./sqoop import --connect jdbc:mysql://centos-aaron-03:3306/test --username root --password 123456 --table emp --hive-import --m 1
Warning: /home/hadoop/sqoop/bin/../../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/bin/../../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/bin/../../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/bin/../../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/03/18 18:46:49 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
19/03/18 18:46:49 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/03/18 18:46:49 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override
19/03/18 18:46:49 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc.
19/03/18 18:46:49 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
19/03/18 18:46:49 INFO tool.CodeGenTool: Beginning code generation
19/03/18 18:46:49 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 18:46:49 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 18:46:49 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/apps/hadoop-2.9.1
注: /tmp/sqoop-hadoop/compile/b0cd7f379424039f4df44ee2b703c3d0/emp.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
19/03/18 18:46:51 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/b0cd7f379424039f4df44ee2b703c3d0/emp.jar
19/03/18 18:46:51 WARN manager.MySQLManager: It looks like you are importing from mysql.
19/03/18 18:46:51 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
19/03/18 18:46:51 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
19/03/18 18:46:51 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
19/03/18 18:46:51 INFO mapreduce.ImportJobBase: Beginning import of emp
19/03/18 18:46:51 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
19/03/18 18:46:52 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
19/03/18 18:46:52 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
19/03/18 18:46:54 INFO mapreduce.JobSubmitter: number of splits:1
19/03/18 18:46:54 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
19/03/18 18:46:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552898029697_0003
19/03/18 18:46:54 INFO impl.YarnClientImpl: Submitted application application_1552898029697_0003
19/03/18 18:46:54 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1552898029697_0003/
19/03/18 18:46:54 INFO mapreduce.Job: Running job: job_1552898029697_0003
19/03/18 18:47:06 INFO mapreduce.Job: Job job_1552898029697_0003 running in uber mode : false
19/03/18 18:47:06 INFO mapreduce.Job: map 0% reduce 0%
19/03/18 18:47:13 INFO mapreduce.Job: map 100% reduce 0%
19/03/18 18:47:13 INFO mapreduce.Job: Job job_1552898029697_0003 completed successfully
19/03/18 18:47:13 INFO mapreduce.Job: Counters: 30File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=206933FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=87HDFS: Number of bytes written=151HDFS: Number of read operations=4HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Launched map tasks=1Other local map tasks=1Total time spent by all maps in occupied slots (ms)=3950Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=3950Total vcore-milliseconds taken by all map tasks=3950Total megabyte-milliseconds taken by all map tasks=4044800Map-Reduce FrameworkMap input records=5Map output records=5Input split bytes=87Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=65CPU time spent (ms)=680Physical memory (bytes) snapshot=135651328Virtual memory (bytes) snapshot=1715556352Total committed heap usage (bytes)=42860544File Input Format Counters Bytes Read=0File Output Format Counters Bytes Written=151
19/03/18 18:47:13 INFO mapreduce.ImportJobBase: Transferred 151 bytes in 21.0263 seconds (7.1815 bytes/sec)
19/03/18 18:47:13 INFO mapreduce.ImportJobBase: Retrieved 5 records.
19/03/18 18:47:13 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table emp
19/03/18 18:47:13 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 18:47:13 WARN hive.TableDefWriter: Column salary had to be cast to a less precise type in Hive
19/03/18 18:47:13 INFO hive.HiveImport: Loading uploaded data into Hive
19/03/18 18:47:13 ERROR hive.HiveConfig: Could not load org.apache.hadoop.hive.conf.HiveConf. Make sure HIVE_CONF_DIR is set correctly.
19/03/18 18:47:13 ERROR tool.ImportTool: Import failed: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConfat org.apache.sqoop.hive.HiveConfig.getHiveConf(HiveConfig.java:50)at org.apache.sqoop.hive.HiveImport.getHiveArgs(HiveImport.java:392)at org.apache.sqoop.hive.HiveImport.executeExternalHiveScript(HiveImport.java:379)at org.apache.sqoop.hive.HiveImport.executeScript(HiveImport.java:337)at org.apache.sqoop.hive.HiveImport.importTable(HiveImport.java:241)at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:537)at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628)at org.apache.sqoop.Sqoop.run(Sqoop.java:147)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConfat java.net.URLClassLoader$1.run(URLClassLoader.java:366)at java.net.URLClassLoader$1.run(URLClassLoader.java:355)at java.security.AccessController.doPrivileged(Native Method)at java.net.URLClassLoader.findClass(URLClassLoader.java:354)at java.lang.ClassLoader.loadClass(ClassLoader.java:425)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)at java.lang.ClassLoader.loadClass(ClassLoader.java:358)at java.lang.Class.forName0(Native Method)at java.lang.Class.forName(Class.java:190)at org.apache.sqoop.hive.HiveConfig.getHiveConf(HiveConfig.java:44)... 12 more解决方案:
# 查看HiveConf.class类是否存在
[hadoop@centos-aaron-h1 lib]$ jcd /home/hadoop/apps/apache-hive-1.2.2-bin/lib
[hadoop@centos-aaron-h1 lib]$ jar tf hive-common-1.2.2.jar |grep HiveConf.class
org/apache/hadoop/hive/conf/HiveConf.class
[hadoop@centos-aaron-h1 lib]$
查看到HiveConf.class类明明存在,只是环境没有找到。修改环境配置,将hive的lib添加HADOOP_CLASSPATH中
#编辑环境变量,并且添加以下内容
vi /etc/profile
export HADOOP_CLASSPATH=/home/hadoop/apps/hadoop-2.9.1/lib/*
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/home/hadoop/apps/apache-hive-1.2.2-bin/lib/*
#生效环境变量
source /etc/profile
再次执行,报错之前导入emp的临时目录已经存在,需要删除
[hadoop@centos-aaron-h1 bin]$ ./sqoop import --connect jdbc:mysql://centos-aaron-03:3306/test --username root --password 123456 --table emp --hive-import --m 1
Warning: /home/hadoop/sqoop/bin/../../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/bin/../../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/bin/../../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/bin/../../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/03/18 19:13:03 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
19/03/18 19:13:03 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/03/18 19:13:03 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override
19/03/18 19:13:03 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc.
19/03/18 19:13:03 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
19/03/18 19:13:03 INFO tool.CodeGenTool: Beginning code generation
19/03/18 19:13:04 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 19:13:04 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 19:13:04 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/apps/hadoop-2.9.1
注: /tmp/sqoop-hadoop/compile/d1c8de7d06b0dc6c09379069fe10322a/emp.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
19/03/18 19:13:07 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/d1c8de7d06b0dc6c09379069fe10322a/emp.jar
19/03/18 19:13:07 WARN manager.MySQLManager: It looks like you are importing from mysql.
19/03/18 19:13:07 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
19/03/18 19:13:07 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
19/03/18 19:13:07 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
19/03/18 19:13:07 INFO mapreduce.ImportJobBase: Beginning import of emp
19/03/18 19:13:08 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
19/03/18 19:13:08 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
19/03/18 19:13:08 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
19/03/18 19:13:09 ERROR tool.ImportTool: Import failed: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://centos-aaron-h1:9000/user/hadoop/emp already existsat org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:279)at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:145)at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1570)at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1567)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1889)at org.apache.hadoop.mapreduce.Job.submit(Job.java:1567)at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1588)at org.apache.sqoop.mapreduce.ImportJobBase.doSubmitJob(ImportJobBase.java:200)at org.apache.sqoop.mapreduce.ImportJobBase.runJob(ImportJobBase.java:173)at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:270)at org.apache.sqoop.manager.SqlManager.importTable(SqlManager.java:692)at org.apache.sqoop.manager.MySQLManager.importTable(MySQLManager.java:127)at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:520)at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628)at org.apache.sqoop.Sqoop.run(Sqoop.java:147)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
解决方案:
hdfs dfs -rm -r /user/hadoop/emp再次执行,成功
[hadoop@centos-aaron-h1 bin]$ ./sqoop import --connect jdbc:mysql://centos-aaron-03:3306/test --username root --password 123456 --table emp --hive-import --m 1
Warning: /home/hadoop/sqoop/bin/../../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/bin/../../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/bin/../../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/bin/../../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/03/18 19:15:15 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
19/03/18 19:15:15 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/03/18 19:15:15 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override
19/03/18 19:15:15 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc.
19/03/18 19:15:15 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
19/03/18 19:15:15 INFO tool.CodeGenTool: Beginning code generation
19/03/18 19:15:15 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 19:15:15 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 19:15:15 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/apps/hadoop-2.9.1
注: /tmp/sqoop-hadoop/compile/e3a407469bc365c026d8fabf4e264f38/emp.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
19/03/18 19:15:17 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/e3a407469bc365c026d8fabf4e264f38/emp.jar
19/03/18 19:15:17 WARN manager.MySQLManager: It looks like you are importing from mysql.
19/03/18 19:15:17 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
19/03/18 19:15:17 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
19/03/18 19:15:17 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
19/03/18 19:15:17 INFO mapreduce.ImportJobBase: Beginning import of emp
19/03/18 19:15:18 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
19/03/18 19:15:18 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
19/03/18 19:15:19 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
19/03/18 19:15:20 INFO db.DBInputFormat: Using read commited transaction isolation
19/03/18 19:15:20 INFO mapreduce.JobSubmitter: number of splits:1
19/03/18 19:15:20 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
19/03/18 19:15:21 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552898029697_0004
19/03/18 19:15:21 INFO impl.YarnClientImpl: Submitted application application_1552898029697_0004
19/03/18 19:15:21 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1552898029697_0004/
19/03/18 19:15:21 INFO mapreduce.Job: Running job: job_1552898029697_0004
19/03/18 19:15:28 INFO mapreduce.Job: Job job_1552898029697_0004 running in uber mode : false
19/03/18 19:15:28 INFO mapreduce.Job: map 0% reduce 0%
19/03/18 19:15:34 INFO mapreduce.Job: map 100% reduce 0%
19/03/18 19:15:34 INFO mapreduce.Job: Job job_1552898029697_0004 completed successfully
19/03/18 19:15:34 INFO mapreduce.Job: Counters: 30File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=206933FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=87HDFS: Number of bytes written=151HDFS: Number of read operations=4HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Launched map tasks=1Other local map tasks=1Total time spent by all maps in occupied slots (ms)=3734Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=3734Total vcore-milliseconds taken by all map tasks=3734Total megabyte-milliseconds taken by all map tasks=3823616Map-Reduce FrameworkMap input records=5Map output records=5Input split bytes=87Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=59CPU time spent (ms)=540Physical memory (bytes) snapshot=129863680Virtual memory (bytes) snapshot=1715556352Total committed heap usage (bytes)=42860544File Input Format Counters Bytes Read=0File Output Format Counters Bytes Written=151
19/03/18 19:15:34 INFO mapreduce.ImportJobBase: Transferred 151 bytes in 15.9212 seconds (9.4842 bytes/sec)
19/03/18 19:15:34 INFO mapreduce.ImportJobBase: Retrieved 5 records.
19/03/18 19:15:34 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table emp
19/03/18 19:15:34 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 19:15:34 WARN hive.TableDefWriter: Column salary had to be cast to a less precise type in Hive
19/03/18 19:15:34 INFO hive.HiveImport: Loading uploaded data into HiveLogging initialized using configuration in jar:file:/home/hadoop/apps/apache-hive-1.2.2-bin/lib/hive-common-1.2.2.jar!/hive-log4j.properties
OK
Time taken: 2.138 seconds
Loading data to table default.emp
Table default.emp stats: [numFiles=1, totalSize=151]
OK
Time taken: 0.547 seconds查看结果:
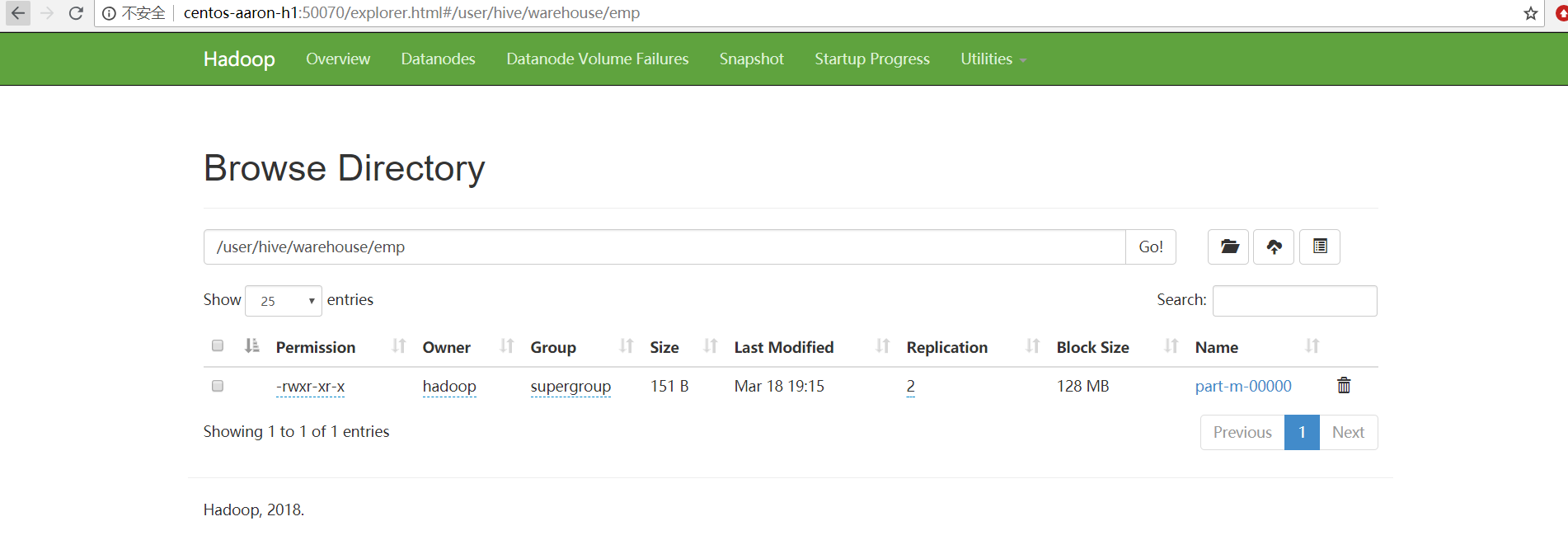
hive> [hadoop@centos-aaron-h1 bin]$ hadoop fs -cat /user/hive/warehouse/emp/part-m-00000
1gopalmanager50000.00TP
2manishaProof reader50000.00TP
3khalilphp dev30000.00AC
4prasanthphp dev30000.00AC
5kranthiadmin20000.00TP(2)、指定行分隔符和列分隔符,指定hive-import,指定覆盖导入,指定自动创建hive表,指定表名,指定删除中间结果数据目录
./sqoop import \
--connect jdbc:mysql://centos-aaron-03:3306/test \
--username root \
--password 123456 \
--table emp \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--hive-overwrite \
--create-hive-table \
--delete-target-dir \
--hive-database mydb_test \
--hive-table emp执行到最后报错hive库找不到
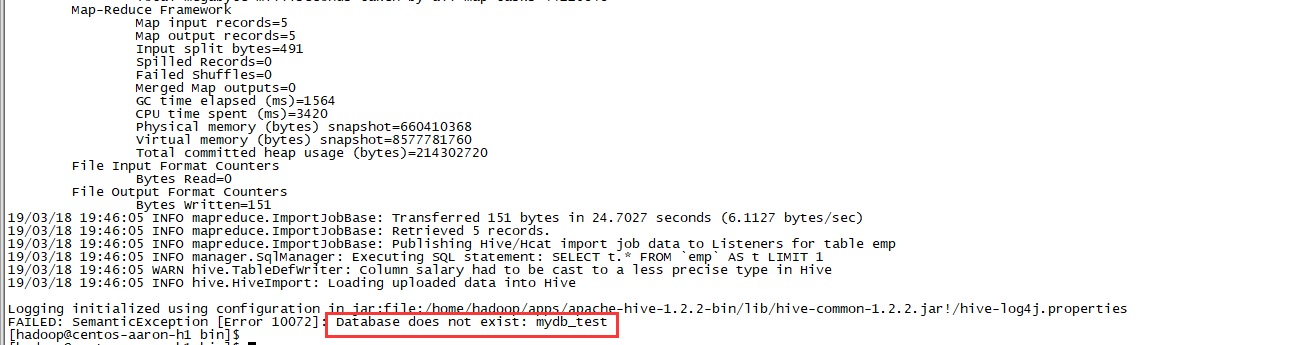
手动创建mydb_test数据块
hive> create database mydb_test;
OK
Time taken: 0.678 seconds
hive>再次执行,依然报错找不到hive库,用命令查看数据库是存在的;
解决方法:复制hive/conf下的hive-site.xml到sqoop工作目录的conf下,实际上该database是在hive中存在的,由于sqoop下的配置文件太旧引起的,一般会出现在,换台机器执行sqoopCDH 默认路径在sqoop下: /etc/hive/conf/hive-site.xml copy到 /etc/sqoop/conf/hive-site.xm
再次执行,成功
hive> [hadoop@centos-aaron-h1 bin]$ cd ~/sqoop/bin
[hadoop@centos-aaron-h1 bin]$ ./sqoop import \
> --connect jdbc:mysql://centos-aaron-03:3306/test \
> --username root \
> --password 123456 \
> --table emp \
> --fields-terminated-by "\t" \
> --lines-terminated-by "\n" \
> --hive-import \
> --hive-overwrite \
> --create-hive-table \
> --delete-target-dir \
> --hive-database mydb_test \
> --hive-table emp
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/03/18 20:49:59 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
19/03/18 20:49:59 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/03/18 20:49:59 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
19/03/18 20:49:59 INFO tool.CodeGenTool: Beginning code generation
19/03/18 20:50:00 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 20:50:00 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 20:50:00 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/apps/hadoop-2.9.1
注: /tmp/sqoop-hadoop/compile/7a157b339316952d30024e165d5db00d/emp.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
19/03/18 20:50:01 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/7a157b339316952d30024e165d5db00d/emp.jar
19/03/18 20:50:03 INFO tool.ImportTool: Destination directory emp deleted.
19/03/18 20:50:03 WARN manager.MySQLManager: It looks like you are importing from mysql.
19/03/18 20:50:03 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
19/03/18 20:50:03 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
19/03/18 20:50:03 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
19/03/18 20:50:03 INFO mapreduce.ImportJobBase: Beginning import of emp
19/03/18 20:50:03 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
19/03/18 20:50:03 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
19/03/18 20:50:03 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
19/03/18 20:50:04 INFO mapreduce.JobSubmitter: number of splits:5
19/03/18 20:50:04 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
19/03/18 20:50:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552898029697_0016
19/03/18 20:50:05 INFO impl.YarnClientImpl: Submitted application application_1552898029697_0016
19/03/18 20:50:05 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1552898029697_0016/
19/03/18 20:50:05 INFO mapreduce.Job: Running job: job_1552898029697_0016
19/03/18 20:50:12 INFO mapreduce.Job: Job job_1552898029697_0016 running in uber mode : false
19/03/18 20:50:12 INFO mapreduce.Job: map 0% reduce 0%
19/03/18 20:50:18 INFO mapreduce.Job: map 20% reduce 0%
19/03/18 20:50:21 INFO mapreduce.Job: map 40% reduce 0%
19/03/18 20:50:22 INFO mapreduce.Job: map 100% reduce 0%
19/03/18 20:50:23 INFO mapreduce.Job: Job job_1552898029697_0016 completed successfully
19/03/18 20:50:23 INFO mapreduce.Job: Counters: 31File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=1034665FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=491HDFS: Number of bytes written=151HDFS: Number of read operations=20HDFS: Number of large read operations=0HDFS: Number of write operations=10Job Counters Killed map tasks=1Launched map tasks=5Other local map tasks=5Total time spent by all maps in occupied slots (ms)=32416Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=32416Total vcore-milliseconds taken by all map tasks=32416Total megabyte-milliseconds taken by all map tasks=33193984Map-Reduce FrameworkMap input records=5Map output records=5Input split bytes=491Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=1240CPU time spent (ms)=3190Physical memory (bytes) snapshot=660529152Virtual memory (bytes) snapshot=8577761280Total committed heap usage (bytes)=214302720File Input Format Counters Bytes Read=0File Output Format Counters Bytes Written=151
19/03/18 20:50:23 INFO mapreduce.ImportJobBase: Transferred 151 bytes in 20.6001 seconds (7.3301 bytes/sec)
19/03/18 20:50:23 INFO mapreduce.ImportJobBase: Retrieved 5 records.
19/03/18 20:50:23 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table emp
19/03/18 20:50:23 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 20:50:23 WARN hive.TableDefWriter: Column salary had to be cast to a less precise type in Hive
19/03/18 20:50:23 INFO hive.HiveImport: Loading uploaded data into HiveLogging initialized using configuration in jar:file:/home/hadoop/apps/apache-hive-1.2.2-bin/lib/hive-common-1.2.2.jar!/hive-log4j.properties
OK
Time taken: 1.131 seconds
Loading data to table mydb_test.emp
Table mydb_test.emp stats: [numFiles=5, numRows=0, totalSize=151, rawDataSize=0]
OK
Time taken: 0.575 seconds
[hadoop@centos-aaron-h1 bin]$ 查看结果数据:
[hadoop@centos-aaron-h1 bin]$ hiveLogging initialized using configuration in jar:file:/home/hadoop/apps/apache-hive-1.2.2-bin/lib/hive-common-1.2.2.jar!/hive-log4j.properties
hive> show databases;
OK
default
mydb_test
wcc_log
Time taken: 0.664 seconds, Fetched: 3 row(s)
hive> use mydb_test;
OK
Time taken: 0.027 seconds
hive> show tables;
OK
emp
Time taken: 0.038 seconds, Fetched: 1 row(s)
hive> select * from emp;
OK
1 gopal manager 50000.0 TP
2 manisha Proof reader 50000.0 TP
3 khalil php dev 30000.0 AC
4 prasanth php dev 30000.0 AC
5 kranthi admin 20000.0 TP
Time taken: 0.634 seconds, Fetched: 5 row(s)
hive> 上面的语句等价于:
sqoop import \
--connect jdbc:mysql://centos-aaron-03:3306/test \
--username root \
--password 123456 \
--table emp \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--hive-overwrite \
--create-hive-table \
--hive-table mydb_test.emp \
--delete-target-dir(3)、导入到HDFS指定目录
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。以下是指定目标目录选项的Sqoop导入命令的语法:
--target-dir <new or exist directory in HDFS>下面的命令是用来导入emp表数据到'/queryresult'目录。./sqoop import \
--connect jdbc:mysql://centos-aaron-03:3306/test \
--username root \
--password 123456 \
--target-dir /queryresult \
--table emp --m 1执行效果
[hadoop@centos-aaron-h1 bin]$ ./sqoop import \
> --connect jdbc:mysql://centos-aaron-03:3306/test \
> --username root \
> --password 123456 \
> --target-dir /queryresult \
> --table emp --m 1
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/03/18 21:00:59 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
19/03/18 21:00:59 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/03/18 21:00:59 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
19/03/18 21:00:59 INFO tool.CodeGenTool: Beginning code generation
19/03/18 21:00:59 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 21:00:59 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 21:00:59 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/apps/hadoop-2.9.1
注: /tmp/sqoop-hadoop/compile/433dbe7d1d24f817e00a85bf0d78eb42/emp.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
19/03/18 21:01:01 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/433dbe7d1d24f817e00a85bf0d78eb42/emp.jar
19/03/18 21:01:01 WARN manager.MySQLManager: It looks like you are importing from mysql.
19/03/18 21:01:01 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
19/03/18 21:01:01 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
19/03/18 21:01:01 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
19/03/18 21:01:01 INFO mapreduce.ImportJobBase: Beginning import of emp
19/03/18 21:01:01 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
19/03/18 21:01:02 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
19/03/18 21:01:02 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
19/03/18 21:01:04 INFO mapreduce.JobSubmitter: number of splits:1
19/03/18 21:01:04 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
19/03/18 21:01:04 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552898029697_0017
19/03/18 21:01:04 INFO impl.YarnClientImpl: Submitted application application_1552898029697_0017
19/03/18 21:01:04 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1552898029697_0017/
19/03/18 21:01:04 INFO mapreduce.Job: Running job: job_1552898029697_0017
19/03/18 21:01:11 INFO mapreduce.Job: Job job_1552898029697_0017 running in uber mode : false
19/03/18 21:01:11 INFO mapreduce.Job: map 0% reduce 0%
19/03/18 21:01:17 INFO mapreduce.Job: map 100% reduce 0%
19/03/18 21:01:17 INFO mapreduce.Job: Job job_1552898029697_0017 completed successfully
19/03/18 21:01:17 INFO mapreduce.Job: Counters: 30File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=206929FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=87HDFS: Number of bytes written=151HDFS: Number of read operations=4HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Launched map tasks=1Other local map tasks=1Total time spent by all maps in occupied slots (ms)=3157Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=3157Total vcore-milliseconds taken by all map tasks=3157Total megabyte-milliseconds taken by all map tasks=3232768Map-Reduce FrameworkMap input records=5Map output records=5Input split bytes=87Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=60CPU time spent (ms)=530Physical memory (bytes) snapshot=133115904Virtual memory (bytes) snapshot=1715552256Total committed heap usage (bytes)=42860544File Input Format Counters Bytes Read=0File Output Format Counters Bytes Written=151
19/03/18 21:01:17 INFO mapreduce.ImportJobBase: Transferred 151 bytes in 14.555 seconds (10.3744 bytes/sec)
19/03/18 21:01:17 INFO mapreduce.ImportJobBase: Retrieved 5 records.查看数据结果:
[hadoop@centos-aaron-h1 bin]$ hdfs dfs -ls /queryresult
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2019-03-18 21:01 /queryresult/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 151 2019-03-18 21:01 /queryresult/part-m-00000
[hadoop@centos-aaron-h1 bin]$ hdfs dfs -cat /queryresult/part-m-00000
1,gopal,manager,50000.00,TP
2,manisha,Proof reader,50000.00,TP
3,khalil,php dev,30000.00,AC
4,prasanth,php dev,30000.00,AC
5,kranthi,admin,20000.00,TP
[hadoop@centos-aaron-h1 bin]$ (4)、导入表数据子集
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下:
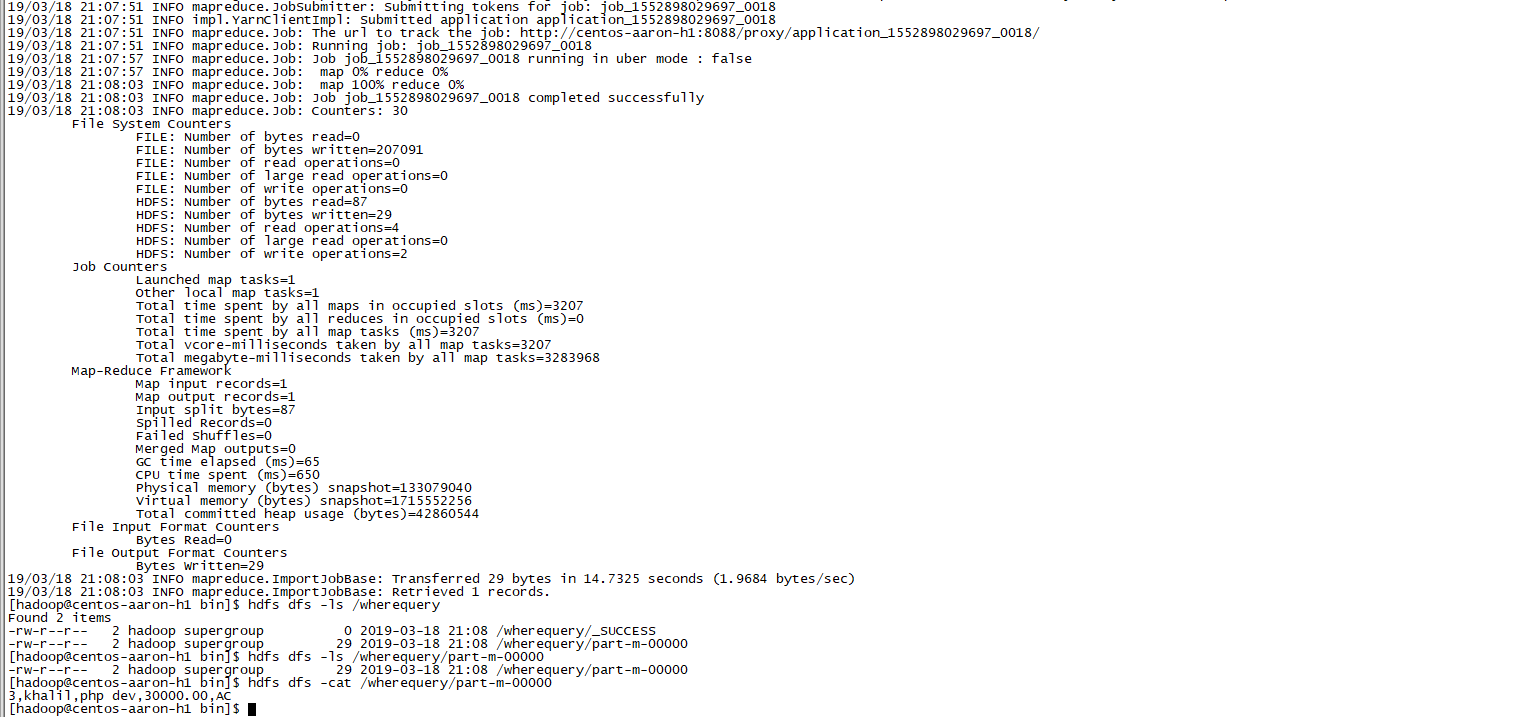
--where <condition>下面的命令用来导入emp表数据的子集。子集查询检索员工ID为3,
./sqoop import \
--connect jdbc:mysql://centos-aaron-03:3306/test \
--username root \
--password 123456 \
--where "id =3 " \
--target-dir /wherequery \
--table emp --m 1
执行效果
(5)、按需导入
./sqoop import \
--connect jdbc:mysql://centos-aaron-03:3306/test \
--username root \
--password 123456 \
--target-dir /wherequery2 \
--query 'select id,name,deg from emp WHERE id>2 and $CONDITIONS' \
--split-by id \
--fields-terminated-by '\t' \
--m 1
执行效果
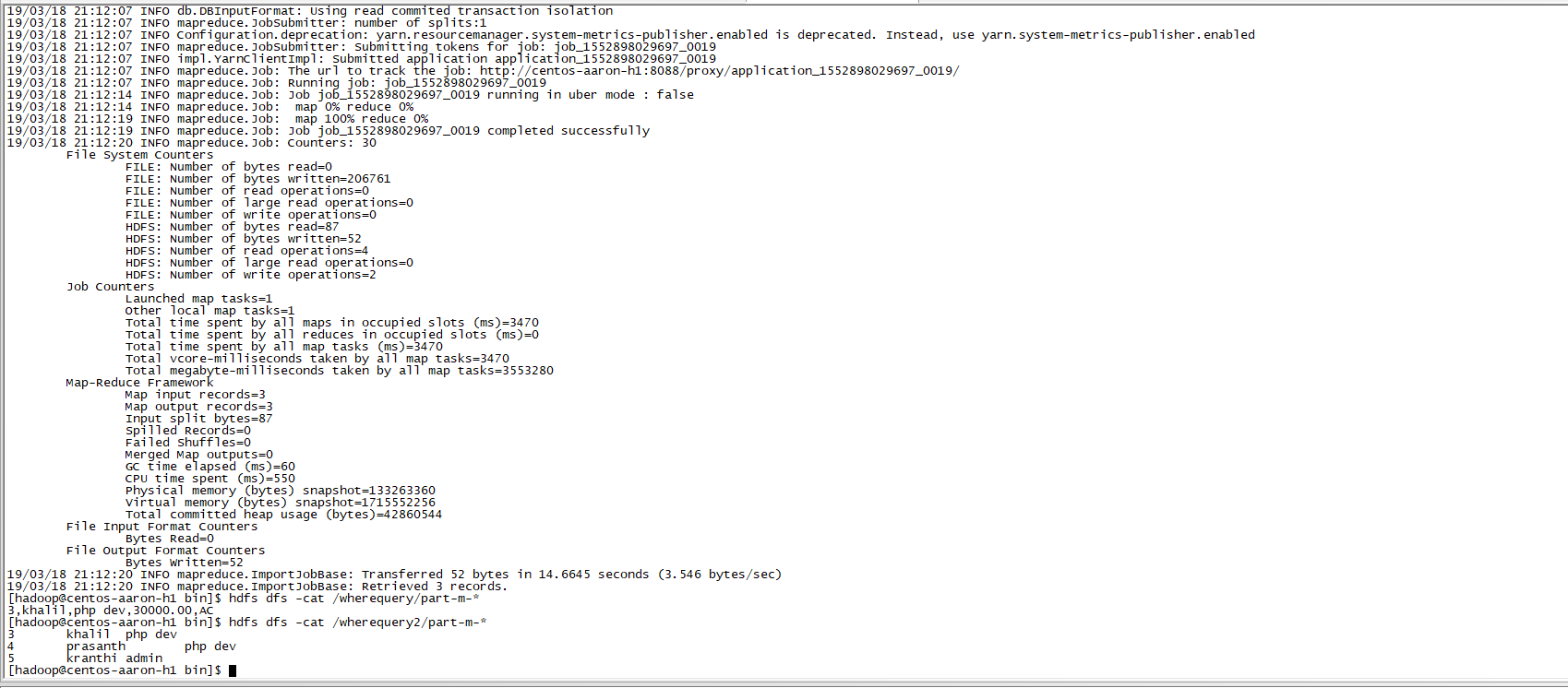
(6)、增量导入
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。增量导入是仅导入新添加的表中的行的技术。它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项:
--incremental <mode>
--check-column <column name>
--last value <last check column value>假设新添加的数据转换成emp表如下:
6, satish p, grp des, 20000, GR下面的命令用于在emp表执行增量导入:
./sqoop import \
--connect jdbc:mysql://centos-aaron-03:3306/test \
--username root \
--password 123456 \
--table emp --m 1 \
--target-dir /wherequery \
--incremental append \
--check-column id \
--last-value 5执行效果:
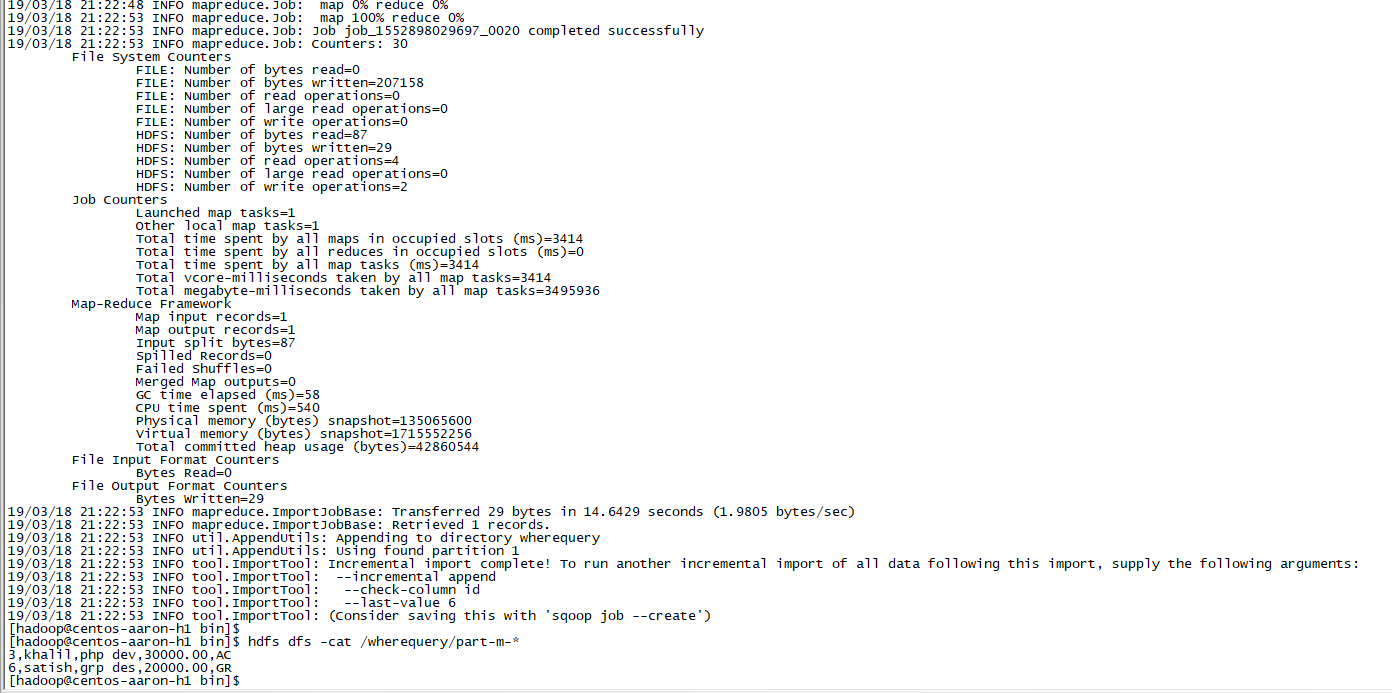
二、Sqoop的数据导出
将数据从HDFS导出到RDBMS数据库;导出前,目标表必须存在于目标数据库中;默认操作是将文件中的数据使用INSERT语句插入到表中;更新模式下,是生成UPDATE语句更新表数据;
语法:
以下是export命令语法
sqoop export (generic-args) (export-args) 示例:
数据是在HDFS 中“/queryresult ”目录的hdfs dfs -cat /queryresult/part-m-00000文件中。所述hdfs dfs -cat /queryresult/part-m-00000如下:
1,gopal,manager,50000.00,TP
2,manisha,Proof reader,50000.00,TP
3,khalil,php dev,30000.00,AC
4,prasanth,php dev,30000.00,AC
5,kranthi,admin,20000.00,TP(1)、首先需要手动创建mysql中的目标表
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| azkaban |
| hive |
| hivedb |
| mysql |
| performance_schema |
| test |
| urldb |
| web_log_wash |
+--------------------+
9 rows in set (0.00 sec)mysql> use test;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> CREATE TABLE employee ( -> id INT NOT NULL PRIMARY KEY, -> name VARCHAR(20), -> deg VARCHAR(20),-> salary INT,-> dept VARCHAR(10));
Query OK, 0 rows affected (0.02 sec)
Aborted(2)、然后执行导出命令
./sqoop export \
--connect "jdbc:mysql://centos-aaron-03:3306/test?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--table employee \
--fields-terminated-by "," \
--export-dir /queryresult/part-m-00000 \
--columns="id,name,deg,salary,dept"
报错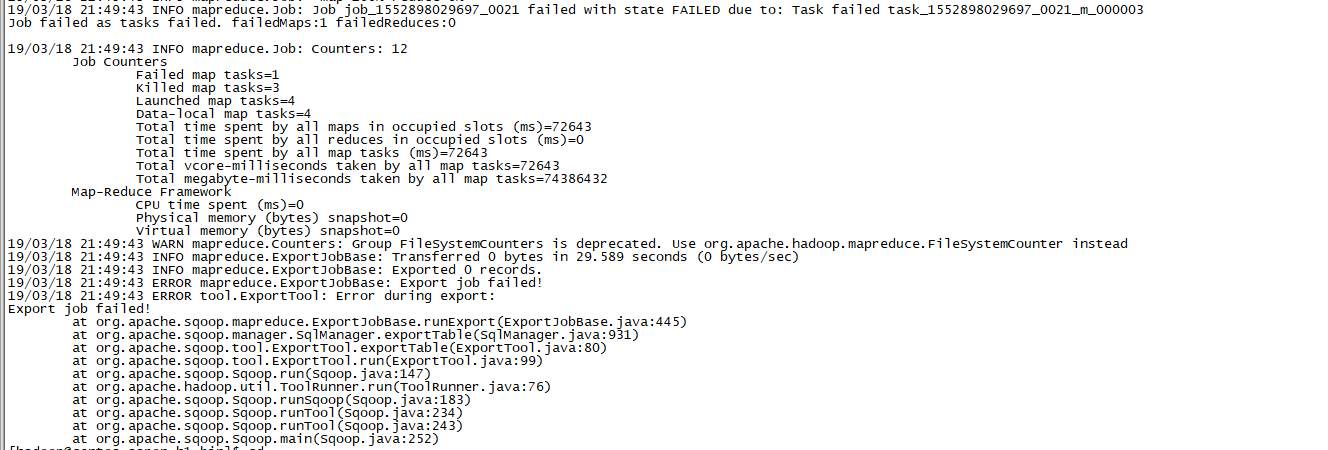
具体问题是数据中有中文,而数据库表编码不支持
解决方案如下:
将表的数据导出,删除表后重新创建表,指定编码DEFAULT CHARSET=utf8
继续报错,分析确认hdfs上数据内容与建表时的int字段不匹配,需要将表的int改为decimal类型
继续执行,成功
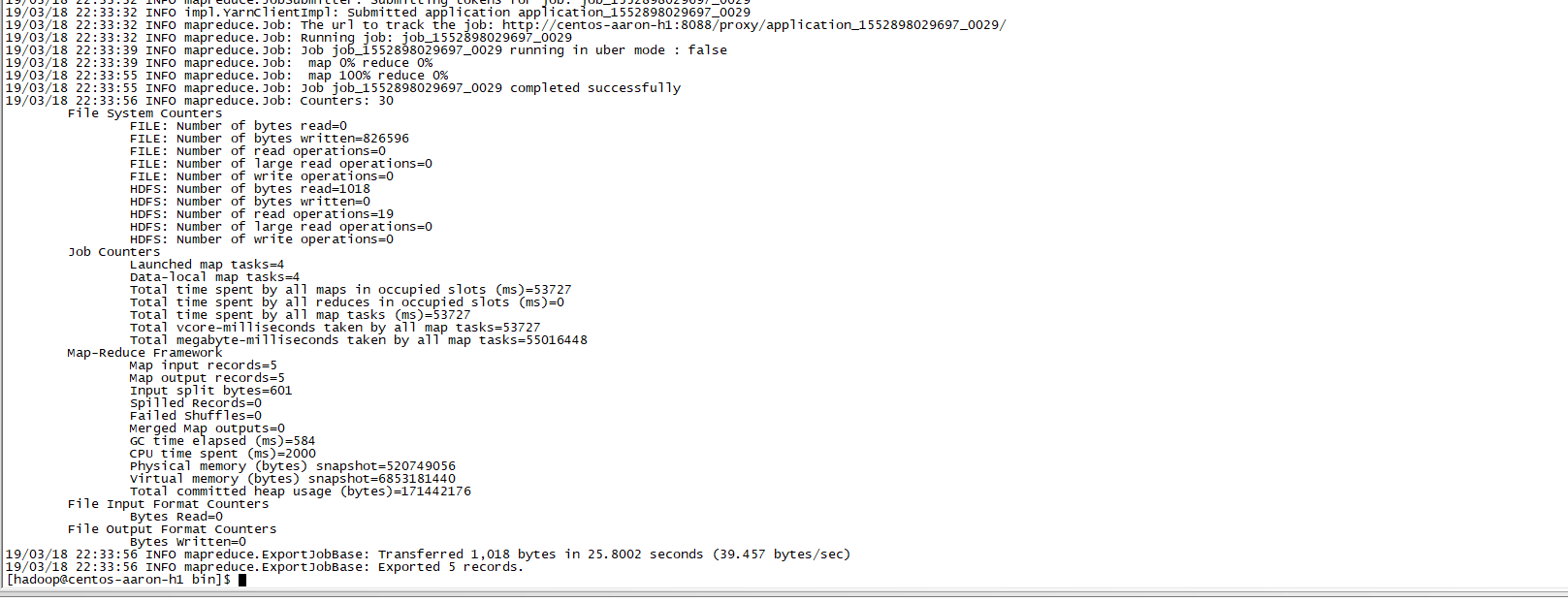
验证效果:
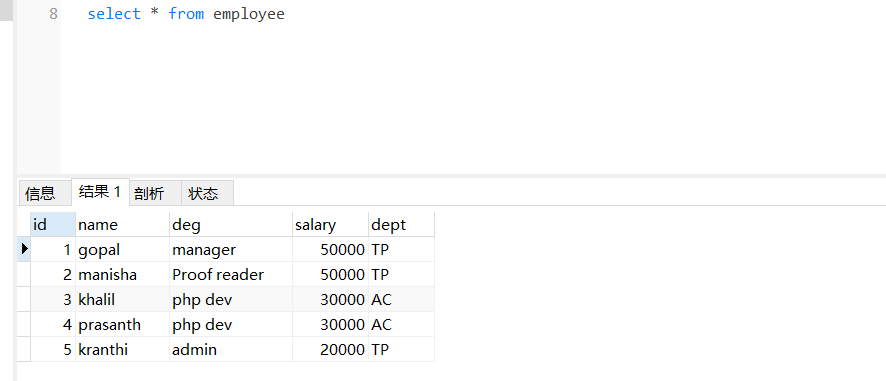
三、Sqoop作业
注:Sqoop作业——将事先定义好的数据导入导出任务按照指定流程运行
语法:
以下是创建Sqoop作业的语法
$ sqoop job (generic-args) (job-args)[-- [subtool-name] (subtool-args)]
创建作业(--create)
在这里,我们创建一个名为myjob,这可以从RDBMS表的数据导入到HDFS作业
#该命令创建了一个从db库的employee表导入到HDFS文件的作业
./sqoop job --create myimportjob -- import --connect jdbc:mysql://centos-aaron-03:3306/test --username root --password 123456 --table emp --m 1验证作业 (--list)
‘--list’ 参数是用来验证保存的作业。下面的命令用来验证保存Sqoop作业的列表。
#它显示了保存作业列表。
sqoop job --list
检查作业(--show)
‘--show’ 参数用于检查或验证特定的工作,及其详细信息。以下命令和样本输出用来验证一个名为myjob的作业。
#它显示了工具和它们的选择,这是使用在myjob中作业情况。
sqoop job --show myjob[hadoop@centos-aaron-h1 bin]$ sqoop job --show myimportjob
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/03/18 22:46:25 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Enter password:
Job: myimportjob
Tool: import
Options:
----------------------------
verbose = false
hcatalog.drop.and.create.table = false
db.connect.string = jdbc:mysql://centos-aaron-03:3306/test
codegen.output.delimiters.escape = 0
codegen.output.delimiters.enclose.required = false
codegen.input.delimiters.field = 0
split.limit = null
hbase.create.table = false
mainframe.input.dataset.type = p
db.require.password = true
skip.dist.cache = false
hdfs.append.dir = false
db.table = emp
codegen.input.delimiters.escape = 0
accumulo.create.table = false
import.fetch.size = null
codegen.input.delimiters.enclose.required = false
db.username = root
reset.onemapper = false
codegen.output.delimiters.record = 10
import.max.inline.lob.size = 16777216
sqoop.throwOnError = false
hbase.bulk.load.enabled = false
hcatalog.create.table = false
db.clear.staging.table = false
codegen.input.delimiters.record = 0
enable.compression = false
hive.overwrite.table = false
hive.import = false
codegen.input.delimiters.enclose = 0
accumulo.batch.size = 10240000
hive.drop.delims = false
customtool.options.jsonmap = {}
codegen.output.delimiters.enclose = 0
hdfs.delete-target.dir = false
codegen.output.dir = .
codegen.auto.compile.dir = true
relaxed.isolation = false
mapreduce.num.mappers = 1
accumulo.max.latency = 5000
import.direct.split.size = 0
sqlconnection.metadata.transaction.isolation.level = 2
codegen.output.delimiters.field = 44
export.new.update = UpdateOnly
incremental.mode = None
hdfs.file.format = TextFile
sqoop.oracle.escaping.disabled = true
codegen.compile.dir = /tmp/sqoop-hadoop/compile/e0ba9288d4916ac38fdbbe98737f9829
direct.import = false
temporary.dirRoot = _sqoop
hive.fail.table.exists = false
db.batch = false
[hadoop@centos-aaron-h1 bin]$ 执行作业 (--exec)
‘--exec’ 选项用于执行保存的作业。下面的命令用于执行保存的作业称为myjob
sqoop job --exec myjob
#正常情况它会显示下面的输出。
10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation 报错:
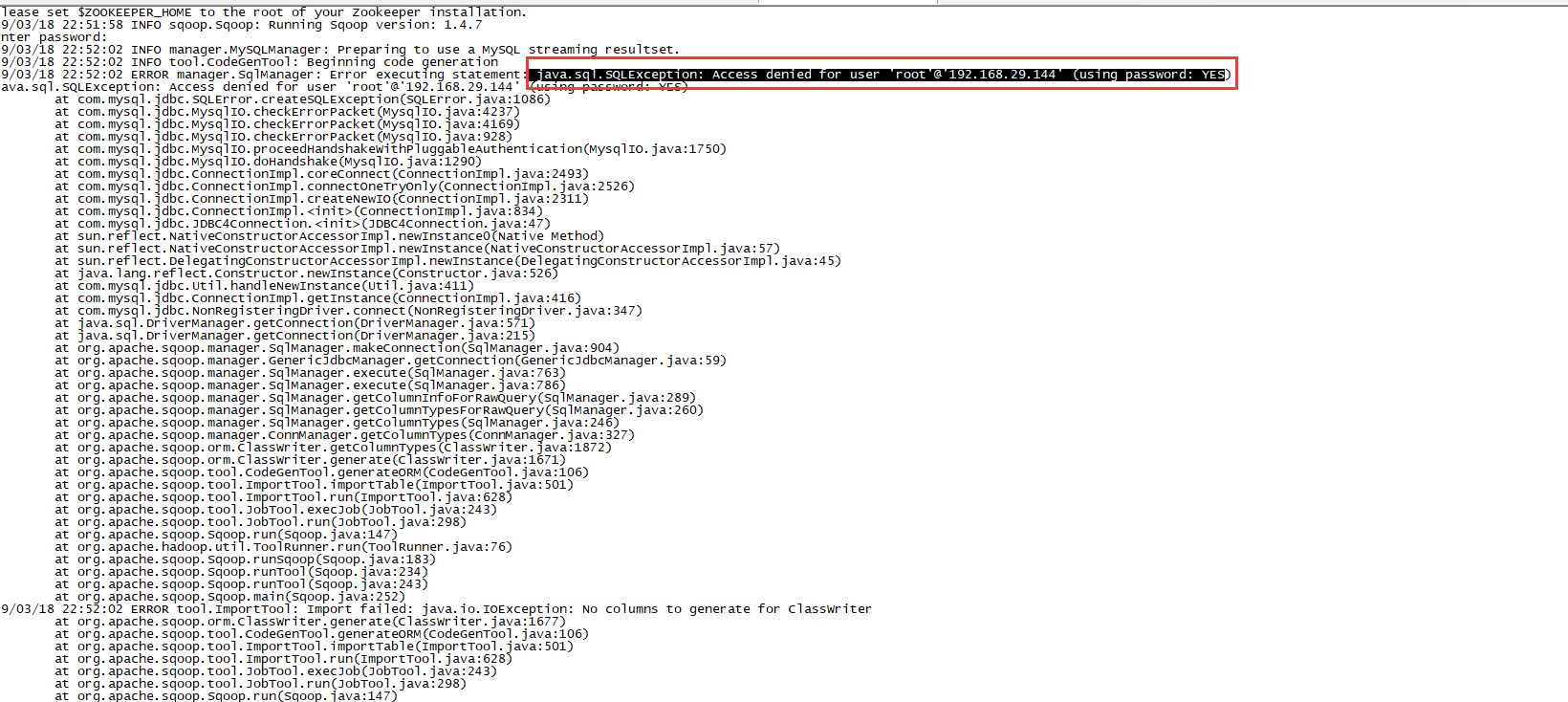
分析是由于mysql访问权限引起,需要修改数据库权限:
#123456表示数据库连接密码
grant all privileges on *.* to root@'%' identified by '123456' ;
FLUSH PRIVILEGES;再次执行sqoop job,成功
[hadoop@centos-aaron-h1 bin]$ sqoop job --exec myimportjob
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/03/18 23:02:08 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Enter password:
19/03/18 23:02:11 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
19/03/18 23:02:11 INFO tool.CodeGenTool: Beginning code generation
19/03/18 23:02:12 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 23:02:12 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 23:02:12 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/apps/hadoop-2.9.1
注: /tmp/sqoop-hadoop/compile/ea795ab1037c940352cf3f7d5af2728f/emp.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
19/03/18 23:02:13 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/ea795ab1037c940352cf3f7d5af2728f/emp.jar
19/03/18 23:02:13 WARN manager.MySQLManager: It looks like you are importing from mysql.
19/03/18 23:02:13 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
19/03/18 23:02:13 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
19/03/18 23:02:13 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
19/03/18 23:02:13 INFO mapreduce.ImportJobBase: Beginning import of emp
19/03/18 23:02:14 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
19/03/18 23:02:14 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
19/03/18 23:02:14 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
19/03/18 23:02:16 INFO db.DBInputFormat: Using read commited transaction isolation
19/03/18 23:02:16 INFO mapreduce.JobSubmitter: number of splits:1
19/03/18 23:02:16 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
19/03/18 23:02:16 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552898029697_0030
19/03/18 23:02:17 INFO impl.YarnClientImpl: Submitted application application_1552898029697_0030
19/03/18 23:02:17 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1552898029697_0030/
19/03/18 23:02:17 INFO mapreduce.Job: Running job: job_1552898029697_0030
19/03/18 23:02:24 INFO mapreduce.Job: Job job_1552898029697_0030 running in uber mode : false
19/03/18 23:02:24 INFO mapreduce.Job: map 0% reduce 0%
19/03/18 23:02:30 INFO mapreduce.Job: map 100% reduce 0%
19/03/18 23:02:30 INFO mapreduce.Job: Job job_1552898029697_0030 completed successfully
19/03/18 23:02:30 INFO mapreduce.Job: Counters: 30File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=207365FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=87HDFS: Number of bytes written=180HDFS: Number of read operations=4HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Launched map tasks=1Other local map tasks=1Total time spent by all maps in occupied slots (ms)=3466Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=3466Total vcore-milliseconds taken by all map tasks=3466Total megabyte-milliseconds taken by all map tasks=3549184Map-Reduce FrameworkMap input records=6Map output records=6Input split bytes=87Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=63CPU time spent (ms)=590Physical memory (bytes) snapshot=132681728Virtual memory (bytes) snapshot=1715552256Total committed heap usage (bytes)=42860544File Input Format Counters Bytes Read=0File Output Format Counters Bytes Written=180
19/03/18 23:02:30 INFO mapreduce.ImportJobBase: Transferred 180 bytes in 15.5112 seconds (11.6045 bytes/sec)
19/03/18 23:02:30 INFO mapreduce.ImportJobBase: Retrieved 6 records.
[hadoop@centos-aaron-h1 bin]$ 四、Sqoop的原理
概述:Sqoop的原理其实就是将导入导出命令转化为mapreduce程序来执行,sqoop在接收到命令后,都要生成mapreduce程序;使用sqoop的代码生成工具可以方便查看到sqoop所生成的java代码,并可在此基础之上进行深入定制开发。
代码定制:
以下是Sqoop代码生成命令的语法
$ sqoop-codegen (generic-args) (codegen-args)
示例:以USERDB数据库中的表emp来生成Java代码为例。
下面的命令用来生成导入
sqoop codegen --connect jdbc:mysql://centos-aaron-03:3306/test --username root --password 123456 --table emp -bindir .如果命令成功执行,那么它就会产生如下的输出
[hadoop@centos-aaron-h1 bin]$ sqoop codegen --connect jdbc:mysql://centos-aaron-03:3306/test --username root --password 123456 --table emp -bindir .
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/03/18 23:21:24 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
19/03/18 23:21:24 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/03/18 23:21:24 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
19/03/18 23:21:24 INFO tool.CodeGenTool: Beginning code generation
19/03/18 23:21:24 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 23:21:24 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
19/03/18 23:21:24 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/apps/hadoop-2.9.1
注: ./emp.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
19/03/18 23:21:26 INFO orm.CompilationManager: Writing jar file: ./emp.jar
[hadoop@centos-aaron-h1 bin]$ ll验证: 查看输出目录下的文件
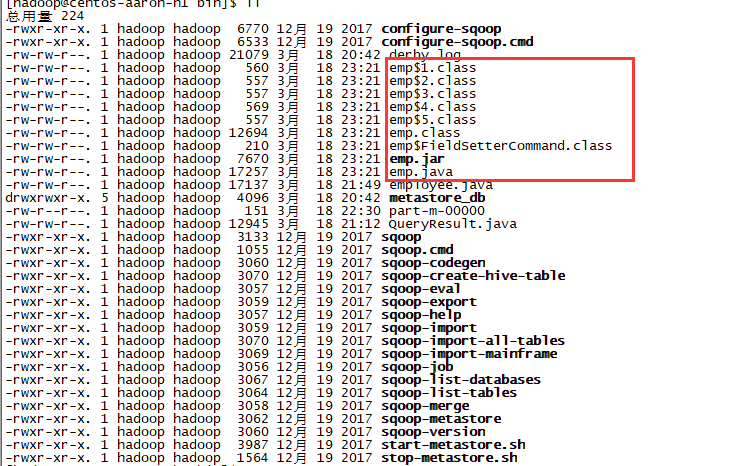
如果想做深入定制导出,则可修改上述代码文件。
最后寄语,以上是博主本次文章的全部内容,如果大家觉得博主的文章还不错,请点赞;如果您对博主其它服务器大数据技术或者博主本人感兴趣,请关注博主博客,并且欢迎随时跟博主沟通交流。
转载于:https://my.oschina.net/u/2371923/blog/3024291
大数据教程(13.6)sqoop使用教程相关推荐
- 急性子的开源大数据,第 1 部分: Hadoop 教程:Hello World 与 Java、Pig、Hive、Flume、Fuse、Oozie,以及 Sqoop 与 Informix、DB2 和
如何开始使用 Hadoop 和自己喜欢的数据库 本文的重点是解释大数据,然后在 Hadoop 中提供简单的工作示例,Hadoop 是在大数据领域的主要开源选手.您会很高兴地听到,Hadoop 并不是 ...
- VR三维数字沙盘电子沙盘大数据可视化交互GIS系统开发教程第15课
VR三维数字沙盘电子沙盘大数据可视化交互GIS系统开发教程第15课:现在不管什么GIS平台首先要解决的就是数据来源问题,因为没有数据的GIS就是一个空壳,下面我就目前一些主流的数据获取 方式了解做如下 ...
- 电子沙盘数字沙盘大数据可视化交互地理信息系统开发教程第8课
多点触摸三维电子沙盘可视化交互地理信息系统(M3D GIS)(平衡+极简+实用)TREND MTOUCH 3D GIS(English)自主知识产权的通过手势多点触摸控制的大型二.三维一体化地理信息系 ...
- 大数据开发之入门java基础教程
什么是编程思想? 所谓的编程思想,简单的说,就是程序员的思考方式.程序员在编程的时候,需要按照一定的思考方式,把需求变成具体的代码,这种思考方式,就是编程思想. 如何转变思想? 例如:去饭店吃饭,饭店 ...
- 大数据存储引擎 NoSQL极简教程 An Introduction to Big Data: NoSQL
本文路线图: NoSQL简介 文档数据库 键值数据库 图数据库 Here's the roadmap for this fourth post on NoSQL database: Introduct ...
- 大数据学习--kafka+flume++sqoop+hadoop+zookeeper+spark+flink
大数据工程师 学习指南 一必备技能 Zookeeper.Hadoop.Hive.HBase.Flume.Sqoop.Flink 等等 1定义(from百度百科) 1.1Zookeeper 百度百科-验 ...
- 大数据:13个真实世界情景中的数据科学应用
现在让我们看看13个在真实世界情景下的例子,了解现代数据科学家可以帮助我们做些什么.这些例子将有助于你学习如何专注于一个问题和如何形式化一个问题,以及如何仔细评估所有潜在问题--总之,是学习数据科学家 ...
- 大数据-安装 Hadoop3.1.3 详细教程-单机/伪分布式配置(Centos)
Centos 7 安装 Hadoop3.1.3 详细教程 前言 00 需准备 01 需掌握 一.准备工作 00 环境 01 创建 hadoop 用户 02 修改 hadoop 用户权限 03 切换为 ...
- 进入hbase shell速度很慢_HBase——大数据平台之分布式NoSQL数据库教程
1.1 HBase下载:CDH(网站不显示,可以直接下载) http://archive.cloudera.com/cdh5/cdh/5/hbase-1.2.0-cdh5.9.0.tar.gz 1.2 ...
- 大数据开发之windows安装hadoop教程
第一步 安装JDK 第二步 安装Hadoop 下载hadoop地址:http://archive.apache.org/dist/hadoop/common/hadoop-3.2.2/ 2. 下载ha ...
最新文章
- 37.递推:Pell数列
- neo4j查询节点与相应的边的方法
- Java语言语法语义分析器设计与实现
- LeetCode之Island Perimeter
- Java中接口、抽象类与内部类学习
- java注解 源码_详解Java注解教程及自定义注解
- sql生成(查询数据的存储过程)代码的存储过程
- reset.css下载
- 《数学建模与数学实验》第5版 作图 习题2.6
- 如何绘制一幅优雅的列线图
- 处理团队中的消极情绪
- 王立军 - 民警维权工作
- b365老掉线 h3c路由器_H3C路由器PPP连接的常见故障及解决方法
- 网页图片不能显示怎么办
- Netflix时代之后Spring Cloud微服务的未来
- 虚拟云服务器能调用本地摄像头,云服务器本地摄像头
- signature=b4b1c7e18770785c0aa672d85aa24d2b,Surveying Extended GMSB Models with mh=125 GeV
- SQLServer还原数据库
- Alpha-Beta 剪枝
- MFC打印及打印预览