python训练数据集_Python——sklearn提供的自带的数据集
sklearn提供的自带的数据集
sklearn 的数据集有好多个种
自带的小数据集(packaged dataset):sklearn.datasets.load_
可在线下载的数据集(Downloaded Dataset):sklearn.datasets.fetch_
计算机生成的数据集(Generated Dataset):sklearn.datasets.make_
svmlight/libsvm格式的数据集:sklearn.datasets.load_svmlight_file(...)
从买了data.org在线下载获取的数据集:sklearn.datasets.fetch_mldata(...)
①自带的数据集
其中的自带的小的数据集为:sklearn.datasets.load_
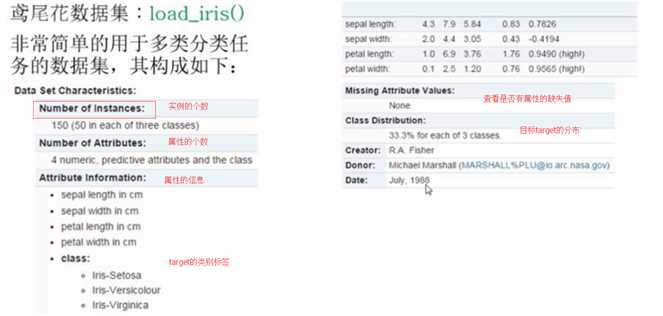
1 from sklearn.datasets importload_iris2 #加载数据集
3 iris=load_iris()4 iris.keys() #dict_keys([‘target‘, ‘DESCR‘, ‘data‘, ‘target_names‘, ‘feature_names‘])
5 #数据的条数和维数
6 n_samples,n_features=iris.data.shape7 print("Number of sample:",n_samples) #Number of sample: 150
8 print("Number of feature",n_features) #Number of feature 4
9 #第一个样例
10 print(iris.data[0]) #[ 5.1 3.5 1.4 0.2]
11 print(iris.data.shape) #(150, 4)
12 print(iris.target.shape) #(150,)
13 print(iris.target)14 """
15
16 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 017 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 118 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 219 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 220 2]21
22 """
23 importnumpy as np24 print(iris.target_names) #[‘setosa‘ ‘versicolor‘ ‘virginica‘]
25 np.bincount(iris.target) #[50 50 50]
26
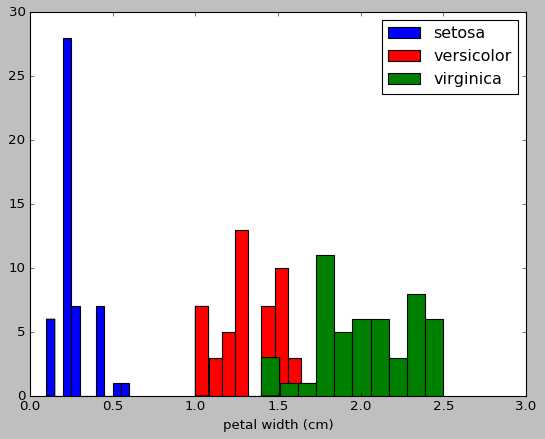
27 importmatplotlib.pyplot as plt28 #以第3个索引为划分依据,x_index的值可以为0,1,2,3
29 x_index=3
30 color=[‘blue‘,‘red‘,‘green‘]31 for label,color inzip(range(len(iris.target_names)),color):32 plt.hist(iris.data[iris.target==label,x_index],label=iris.target_names[label],color=color)33
34 plt.xlabel(iris.feature_names[x_index])35 plt.legend(loc="Upper right")36 plt.show()37
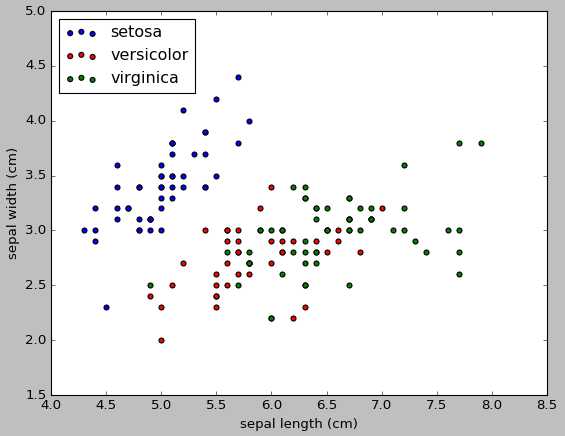
38 #画散点图,第一维的数据作为x轴和第二维的数据作为y轴
39 x_index=040 y_index=1
41 colors=[‘blue‘,‘red‘,‘green‘]42 for label,color inzip(range(len(iris.target_names)),colors):43 plt.scatter(iris.data[iris.target==label,x_index],44 iris.data[iris.target==label,y_index],45 label=iris.target_names[label],46 c=color)47 plt.xlabel(iris.feature_names[x_index])48 plt.ylabel(iris.feature_names[y_index])49 plt.legend(loc=‘upper left‘)50 plt.show()
手写数字数据集load_digits():用于多分类任务的数据集
1 from sklearn.datasets importload_digits2 digits=load_digits()3 print(digits.data.shape)4 importmatplotlib.pyplot as plt5 plt.gray()6 plt.matshow(digits.images[0])7 plt.show()8
9 from sklearn.datasets importload_digits10 digits=load_digits()11 digits.keys()12 n_samples,n_features=digits.data.shape13 print((n_samples,n_features))14
15 print(digits.data.shape)16 print(digits.images.shape)17
18 importnumpy as np19 print(np.all(digits.images.reshape((1797,64))==digits.data))20
21 fig=plt.figure(figsize=(6,6))22 fig.subplots_adjust(left=0,right=1,bottom=0,top=1,hspace=0.05,wspace=0.05)23 #绘制数字:每张图像8*8像素点
24 for i in range(64):25 ax=fig.add_subplot(8,8,i+1,xticks=[],yticks=[])26 ax.imshow(digits.images[i],cmap=plt.cm.binary,interpolation=‘nearest‘)27 #用目标值标记图像
28 ax.text(0,7,str(digits.target[i]))29 plt.show()


乳腺癌数据集load-barest-cancer():简单经典的用于二分类任务的数据集
糖尿病数据集:load-diabetes():经典的用于回归任务的数据集,值得注意的是,这10个特征中的每个特征都已经被处理成0均值,方差归一化的特征值
波士顿房价数据集:load-boston():经典的用于回归任务的数据集
体能训练数据集:load-linnerud():经典的用于多变量回归任务的数据集,其内部包含两个小数据集:Excise是对3个训练变量的20次观测(体重,腰围,脉搏),physiological是对3个生理学变量的20次观测(引体向上,仰卧起坐,立定跳远)
svmlight/libsvm的每一行样本的存放格式:
:: ....
这种格式比较适合用来存放稀疏数据,在sklearn中,用scipy sparse CSR矩阵来存放X,用numpy数组来存放Y
1 from sklearn.datasets importload_svmlight_file2 x_train,y_train=load_svmlight_file("/path/to/train_dataset.txt","")#如果要加在多个数据的时候,可以用逗号隔开
②生成数据集
生成数据集:可以用来分类任务,可以用来回归任务,可以用来聚类任务,用于流形学习的,用于因子分解任务的
用于分类任务和聚类任务的:这些函数产生样本特征向量矩阵以及对应的类别标签集合
make_blobs:多类单标签数据集,为每个类分配一个或多个正太分布的点集
make_classification:多类单标签数据集,为每个类分配一个或多个正太分布的点集,提供了为数据添加噪声的方式,包括维度相关性,无效特征以及冗余特征等
make_gaussian-quantiles:将一个单高斯分布的点集划分为两个数量均等的点集,作为两类
make_hastie-10-2:产生一个相似的二元分类数据集,有10个维度
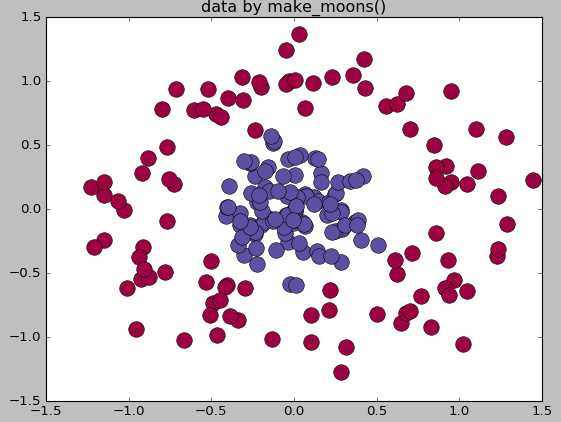
make_circle和make_moom产生二维二元分类数据集来测试某些算法的性能,可以为数据集添加噪声,可以为二元分类器产生一些球形判决界面的数据
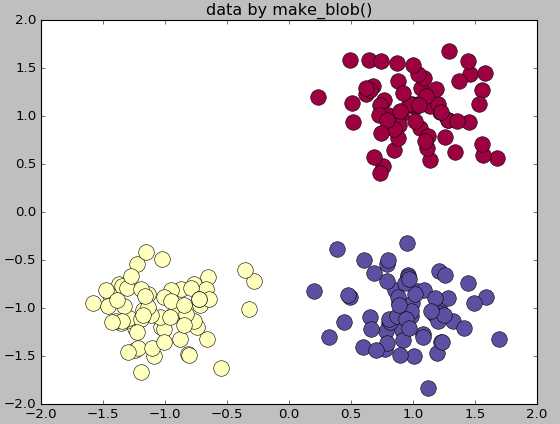
1 #生成多类单标签数据集
2 importnumpy as np3 importmatplotlib.pyplot as plt4 from sklearn.datasets.samples_generator importmake_blobs5 center=[[1,1],[-1,-1],[1,-1]]6 cluster_std=0.3
7 X,labels=make_blobs(n_samples=200,centers=center,n_features=2,8 cluster_std=cluster_std,random_state=0)9 print(‘X.shape‘,X.shape)10 print("labels",set(labels))11
12 unique_lables=set(labels)13 colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))14 for k,col inzip(unique_lables,colors):15 x_k=X[labels==k]16 plt.plot(x_k[:,0],x_k[:,1],‘o‘,markerfacecolor=col,markeredgecolor="k",17 markersize=14)18 plt.title(‘data by make_blob()‘)19 plt.show()20
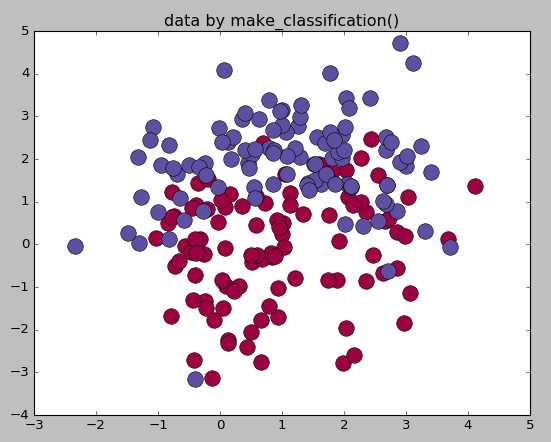
21 #生成用于分类的数据集
22 from sklearn.datasets.samples_generator importmake_classification23 X,labels=make_classification(n_samples=200,n_features=2,n_redundant=0,n_informative=2,24 random_state=1,n_clusters_per_class=2)25 rng=np.random.RandomState(2)26 X+=2*rng.uniform(size=X.shape)27
28 unique_lables=set(labels)29 colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))30 for k,col inzip(unique_lables,colors):31 x_k=X[labels==k]32 plt.plot(x_k[:,0],x_k[:,1],‘o‘,markerfacecolor=col,markeredgecolor="k",33 markersize=14)34 plt.title(‘data by make_classification()‘)35 plt.show()36
37 #生成球形判决界面的数据
38 from sklearn.datasets.samples_generator importmake_circles39 X,labels=make_circles(n_samples=200,noise=0.2,factor=0.2,random_state=1)40 print("X.shape:",X.shape)41 print("labels:",set(labels))42
43 unique_lables=set(labels)44 colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))45 for k,col inzip(unique_lables,colors):46 x_k=X[labels==k]47 plt.plot(x_k[:,0],x_k[:,1],‘o‘,markerfacecolor=col,markeredgecolor="k",48 markersize=14)49 plt.title(‘data by make_moons()‘)50 plt.show()
原文地址:https://www.cnblogs.com/yxh-amysear/p/9463775.html
python训练数据集_Python——sklearn提供的自带的数据集相关推荐
- python的自带数据集_Python——sklearn提供的自带的数据集
sklearn提供的自带的数据集 sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_ 可在线下载的数据集(Downlo ...
- python的自带数据集_sklearn提供的自带的数据集
sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_ 可在线下载的数据集(Downloaded Dataset):skl ...
- python决策树分类 导入数据集_python+sklearn实现决策树(分类树)
整理今天的代码-- 采用的是150条鸢尾花的数据集fishiris.csv # 读入数据,把Name列取出来作为标签(groundtruth) import pandas as pd data = p ...
- python 密度 语音_Python+sklearn机器学习应该了解的33个基本概念
封面图片:<Python程序设计实验指导书>,董付国编著,清华大学出版社 ================ 机器学习(Machine Learning)根据已知数据来不断学习和积累经验,然 ...
- python最佳身高_Python+sklearn使用线性回归算法预测儿童身高
原标题:Python+sklearn使用线性回归算法预测儿童身高 问题描述:一个人的身高除了随年龄变大而增长之外,在一定程度上还受到遗传和饮食以及其他因素的影响,本文代码中假定受年龄.性别.父母身高. ...
- python混淆矩阵函数_Python sklearn.metrics模块混淆矩阵常用函数
from sklearn import metrics 1.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None) 参数分 ...
- 【ML】机器学习数据集:sklearn中分类数据集介绍
目录 1.乳腺癌分类数据集(二分类) 2.鸢尾花分类数据集(三分类) 3.葡萄酒分类数据集(三分类) 4.手写数字分类数据集(十分类) 5.其他数据集 参考资料 在机器学习的教程中,我们会看到很多的d ...
- python kfold交叉验证_Python sklearn KFold 生成交叉验证数据集的方法
源起: 1.我要做交叉验证,需要每个训练集和测试集都保持相同的样本分布比例,直接用sklearn提供的KFold并不能满足这个需求. 2.将生成的交叉验证数据集保存成CSV文件,而不是直接用sklea ...
- python的自带数据集_Python的Sklearn库中的数据集
一.Sklearn介绍 scikit-learn是Python语言开发的机器学习库,一般简称为sklearn,目前算是通用机器学习算法库中实现得比较完善的库了.其完善之处不仅在于实现的算法多,还包括大 ...
最新文章
- 标准日本语 09_002
- Keil MDK在个别电脑上下载程序失败的解决办法
- java ee基础知识_Java EE:基础知识
- python连接oracle报错dpi 1047_python连接Oracle的方式以及过程中遇到的问题
- Spring Security 用户登录实战
- 解决An attempt was made to load a program with an incorrect format.问题
- Java打印的几种方法
- cnpm : 无法加载文件 C:\Users\zsl\AppData\Roaming\npm\cnpm.ps1,因为在此系统上禁止运行脚本
- 模拟网络延迟抖动测试
- 【杂记】01:王者荣耀,再见?
- vmbox主机和虚拟机无法共通网络服务 主机无法使用虚拟机的网络服务 虚拟机无法使用主机的网络服务
- AndroidStudio|读取SD卡中的sqlite数据
- linux之mysql基础
- 三个月时间,如何成就自己成为一名数据分析师
- 宏旺半导体为你解释手机内存不够用的原因
- 统计之 - 离均差平方和
- 堆漏洞挖掘——fastbin attack漏洞
- 爱剪辑怎么制作淘宝视频?详细的制作技巧,教你快速搞定淘宝主图视频
- 并发导致java对象错乱
- 惠普HP LaserJet Enterprise 500 M551xh 打印机驱动