【Spark亚太研究院系列丛书】Spark实战高手之路-第3章Spark架构设计与编程模型第1节 ①...
2019独角兽企业重金招聘Python工程师标准>>> 
一、MapReduce已死,Spark称霸
由于Hadoop的MapReduce高延迟的死穴,导致Hadoop无力处理很多对时间有要求的场景,人们对其批评越来越多,Hadoop无力改变现在而导致正在死亡。正如任何领域一样,死亡是一个过程,Hadoop正在示例这样的一个过程,Hadoop的死亡过程在2012年已经开始
1,原先支持Hadoop的四大商业机构纷纷宣布支持Spark;
2,Mahout前一阶段表示从现在起他们将不再接受任何形式的以MapReduce形式实现的算法,另外一方面,Mahout宣布新的算法基于Spark;
3,Cloudera的机器学习框架Oryx的执行引擎也将由Hadoop的MapReduce替换成Spark;
4,Google已经开始将负载从MapReduce转移到Pregel和Dremel上;
5,FaceBook则将负载转移到Presto上;
现在很多原来使用深度使用Hadoop的公司都在纷纷转向Spark,国内的淘宝是典型的案例。在此,我们以使用世界上使用Hadoop最典型的公司Yahoo!为例,大家可以看一下其数据处理的架构图:

而使用Spark后的架构如下:
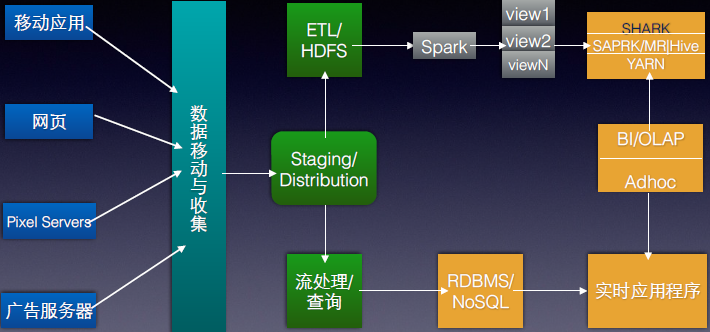
大家可以看出,现阶段的Yahoo!是使用Hadoop和Spark并存的架构,而随着时间的推进和Spark本身流处理、图技术、机器学习、NoSQL查询的出色特性,最终Yahoo!可能会完成Spark全面取代Hadoop,而这也代表了所有做云计算大数据公司的趋势。
或许有朋友会问,Hadoop为何不改进自己?
其实,Hadoop社区一直在改进Hadoop本身,但事实是无力回天:
1,Hadoop的改进基本停留在代码层次,也就是修修补补的事情,这就导致了Hadoop现在具有深度的“技术债务”,负载累累;
2,Hadoop本身的计算模型决定了Hadoop上的所有工作都要转化成Map、Shuffle和Reduce等核心阶段,由于每次计算都要从磁盘读或者写数据,同时真个计算模型需要网络传输,这就导致了越来越不能忍受的延迟性,同时在前一个任务运行完之前,任何一个任务都不可以运行,这直接导致了其无力支持交互式应用;
那么,为什么不全部重新写一个更好的Hadoop呢?答案是Spark的出现使得没有必要这样做了。
Spark是继Hadoop之后,成为替代Hadoop的下一代云计算大数据核心技术,目前SPARK已经构建了自己的整个大数据处理生态系统,如流处理、图技术、机器学习、NoSQL查询等方面都有自己的技术,并且是Apache顶级Project,可以预计的是2014年下半年到2015年在社区和商业应用上会有爆发式的增长。
国外一些大型互联网公司已经部署了Spark。甚至连Hadoop的早期主要贡献者Yahoo现在也在多个项目中部署使用Spark;国内的淘宝、优酷土豆、网易、Baidu、腾讯等已经使用Spark技术用于自己的商业生产系统中,国内外的应用开始越来越广泛。Spark正在逐渐走向成熟,并在这个领域扮演更加重要的角色。
二、企业为什么需要Spark;
1,现在很多原来使用深度使用Hadoop的公司都在纷纷转向Spark,国内的淘宝是典型的案例。在此,我们以使用世界上使用Hadoop最典型的公司Yahoo!为例,大家可以看一下其数据处理的架构图:
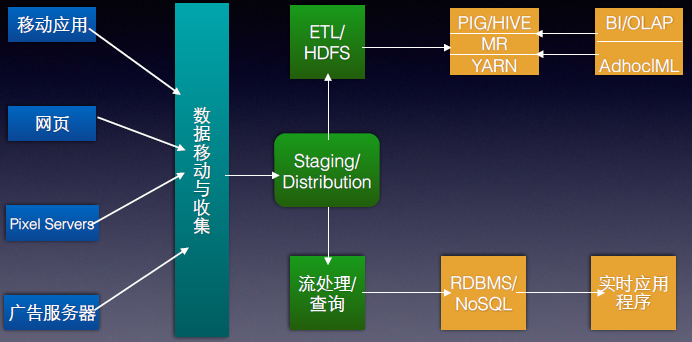
而使用Spark后的架构如下:
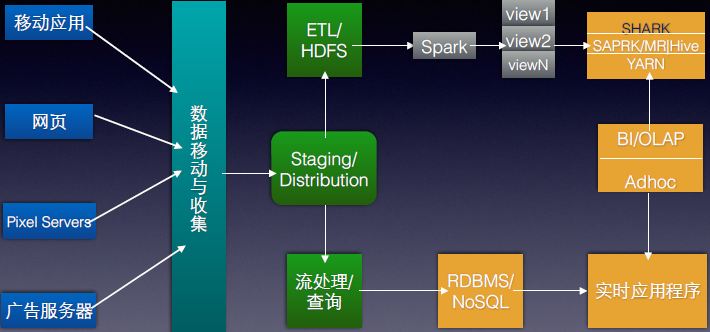
大家可以看出,现阶段的Yahoo!是使用Hadoop和Spark并存的架构,而随着时间的推进和Spark本身流处理、图技术、机器学习、NoSQL查询的出色特性,最终Yahoo!可能会完成Spark全面取代Hadoop,而这也代表了所有做云计算大数据公司的趋势。
2,Spark是可以革命Hadoop的目前唯一替代者,能够做Hadoop做的一切事情,同时速度比Hadoop快了100倍以上:
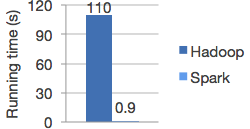
Logistic regression in Hadoop and Spark
可以看出在Spark特别擅长的领域其速度比Hadoop快120倍以上!
,3,原先支持Hadoop的四大商业机构纷纷宣布支持Spark,包含知名Hadoop解决方案供应商Cloudera和知名的Hadoop供应商MapR;
4,Spark是继Hadoop之后,成为替代Hadoop的下一代云计算大数据核心技术,目前SPARK已经构建了自己的整个大数据处理生态系统,如流处理、图技术、机器学习、NoSQL查询等方面都有自己的技术,并且是Apache顶级Project,可以预计的是2014年下半年到2015年在社区和商业应用上会有爆发式的增长。
5,国外一些大型互联网公司已经部署了Spark。甚至连Hadoop的早期主要贡献者Yahoo现在也在多个项目中部署使用Spark;国内的淘宝、优酷土豆、网易、Baidu、腾讯等已经使用Spark技术用于自己的商业生产系统中,国内外的应用开始越来越广泛。Spark正在逐渐走向成熟,并在这个领域扮演更加重要的角色。
6,不得不提的是Spark的“One stack to rule them all”的特性,Spark的特点之一就是用一个技术堆栈解决云计算大数据中流处理、图技术、机器学习、交互式查询、误差查询等所有的问题
7,Mahout前一阶段表示从现在起他们将不再接受任何形式的以MapReduce形式实现的算法,另外一方面,Mahout宣布新的算法基于Spark;
8,如果你已经使用了Hadoop,就更加需要Spark。Mahout前一阶段表示从现在起他们将不再接受任何形式的以MapReduce形式实现的算法,另外一方面,Mahout宣布新的算法基于Spark,同时,这几年来,Hadoop的改进基本停留在代码层次,也就是修修补补的事情,这就导致了Hadoop现在具有深度的“技术债务”,负载累累;
8,,此时我们只需要一个技术团队通过Spark就可以搞定一切问题,而如果基于Hadoop就需要分别构建实时流处理团队、数据统计分析团队、数据挖掘团队等,而且这些团队之间无论是代码还是经验都不可相互借鉴,会形成巨大的成本,而使用Spark就不存在这个问题;
9,百亿美元市场,教授为之辞职,学生为止辍学,大势所趋!
10,Life is short!
转载于:https://my.oschina.net/u/1791057/blog/355657
【Spark亚太研究院系列丛书】Spark实战高手之路-第3章Spark架构设计与编程模型第1节 ①...相关推荐
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第3章Spark架构设计与编程模型第2节②...
2019独角兽企业重金招聘Python工程师标准>>> 三, Spark的RDD 在Spark中一切都是以RDD为基础和核心的: 每个RDD的API如下所示: Spark官方文档中给 ...
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第2章动手实战Scala第3小节(2)
2019独角兽企业重金招聘Python工程师标准>>> 3,动手实战Scala中的泛型 泛型泛型类和泛型方法,也就是我们实例化类或者调用方法的时候可以指定其类型,由于Scala的泛型 ...
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第二步)(4)...
2019独角兽企业重金招聘Python工程师标准>>> 4.测试Hadoop分布式集群环境: 首先在通过Master节点格式化集群的文件系统: 输入"Y"完成格式 ...
- 【Spark亚太研究院系列丛书】Spark实战高手之-构建Spark集群-安装Ubuntu系统(3)
2019独角兽企业重金招聘Python工程师标准>>> 启动虚拟机,正是开启Ubuntu系统的安装! 点击"Power on this virtual machine&qu ...
- Hbase高手之路 -- 第五章 -- HBase的Java API编程
Hbase高手之路 – 第五章 – HBase的Java API编程 一. 需求与数据集 某自来水公司,需要存储大量的缴费明细数据,以下截取了缴费明细的一部分内容: 因为缴费明细的数据记录非常庞大,该 ...
- 王家林 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程...
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第五讲Hadoop图文训练课程:解决典型Hadoop分布式集群环境搭建问题
王家林的"云计算分布式大数据Hadoop实战高手之路---从零开始"的第五讲Hadoop图文训练课程:解决典型Hadoop分布式集群环境搭建问题 参考文章: (1)王家林的&quo ...
- Rasa 3.X 智能对话机器人案例开发硬核实战高手之路 (7大项目Expert版本)
课程标题:Rasa 3.X 智能对话机器人案例开发硬核实战高手之路(7大项目Expert版本) 课程关键字:Rasa Application.Debugging.E-commerce.Retail.C ...
- 知识图谱实战应用9-基于neo4j的知识图谱框架设计与类模型构建
大家好,我是微学AI,今天给大家介绍一下知识图谱实战应用9-基于neo4j的知识图谱框架设计与类模型构建.我将构建KnowledgeGraphs的类,用于操作Neo4j图数据库中的知识图谱数据.方便管 ...
最新文章
- CSS布局之-水平垂直居中
- 新技能 Get,使用直方图处理进行颜色校正
- 慎用url重写(转)
- Redirecting to binsystemctl start crond.service
- 归约操作java8_使用Java 8进行分组,转换和归约
- C#关于base64图片字符串的压缩方法
- RDLC之自定義數據集二
- NYOJ水题--最短街区问题
- 网站限制IP访问应该怎么办
- 动态包含与静态包含的区别
- AXURE9最全的WEB设计元件库(分享版).rplib
- deepin linux安装微信,Ubuntu20.04安装Deepin-wine,微信,Tim
- kubernetes-kube-scheduler进程源码分析
- andriod中3g模块没有mac地址的原因
- 星期五五–大数据,Doppio和假Linus Torvalds
- 小米笔记本U盘win10换win7系统操作教程
- 认识 Arduino 开发板
- 采购招标系统源码 一站式全流程采购招标系统
- OpenCV基础矩阵求解解析笔记
- android列表倒计时,RecyclerView实现列表倒计时