visual-reasoning 笔记
目录
整理最近学习 visual-reasoning的笔记
1. 关注 ACL、EMNLP、NAACLI等会议文章
未开始
2. Cyc项目
2.1 cyc知识库介绍:
该知识库包含了320w条人类断言,30w概念,15000谓词。
Cyc知识库中表示的知识一般形如“每棵树都是植物”、“植物最终都会死亡”。当提出“树是否会死亡”的问题时,推理引擎可以得到正确的结论,并回答该问题。
cyc中的概念被称为常量,主要有以下几种常量。
个体
集合
真值函数
函数
谓词
- 最重要的谓词是#isa 以及 #genls。 #isa 表示某个对象是某个集合的个体,#genls表示某个集合是另一个集合的子集。
句子中可以包含变量,变量字符串以 "?"开头,这些句子被称为“规则”。
2.2 对Cyc项目的批评:(我们可以借鉴吸收的经验)
- 该系统具有创建百科全书式知识库的野心,但却手动添加所有的知识到系统中
- 我们是否可以通过程序、脚本等辅助工具尽量自动化完成这一工作
- 其他都是一些技术难点,比如对物质概念的解释难以令人满意,缺乏测试系统,该系统在广度和深度上都有待完善。
3. WordNet
3.1 介绍
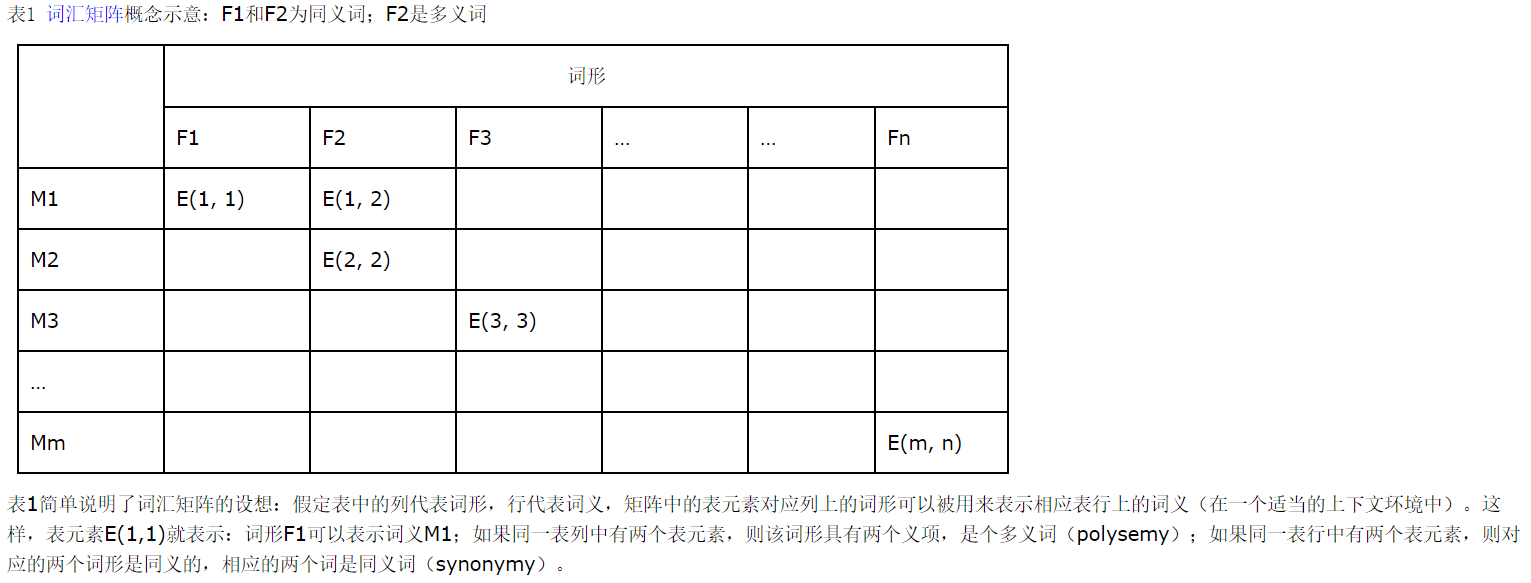
常规词典忽略了词典中同义信息的组织问题。WordNet将词汇分成五个大类:名词、动词、形容词、副词和虚词。 特色之处在于根据词义来组织词汇信息,按照词汇的矩阵模型组织的。
WordNet中单词关系包括如下几种:同义关系、反义关系、上下位关系、部分关系。
词形之间的词汇关系:同义关系、反义关系
词义之间的语义关系:上位关系(父集)、下位关系(子集)
WordNet 按照词汇的矩阵模型组织
4. Conceptnet
ConceptNet 是一个大规模的多语言常识知识库,其本质为一个以自然语言的方式描述人类常识的大型语义网络。ConceptNet 起源于一个众包项目 Open Mind Common Sense,自 1999 年开始通过文本抽取、众包、融合现有知识库中的常识知识以及设计一些游戏从而不断获取常识知识。ConceptNet 中共拥有 36 种固定的关系,如 IsA、UsedFor、CapableOf 等,图 4 给出了一个具体的例子,从中可以更加清晰地了解 ConceptNet 的结构。ConceptNet 目前拥有 304 个语言的版本,共有超过 390 万个概念,2800 万个声明(statements,即语义网络中边的数量),正确率约为 81%。另外,ConceptNet 目前支持数据集的完全下载。
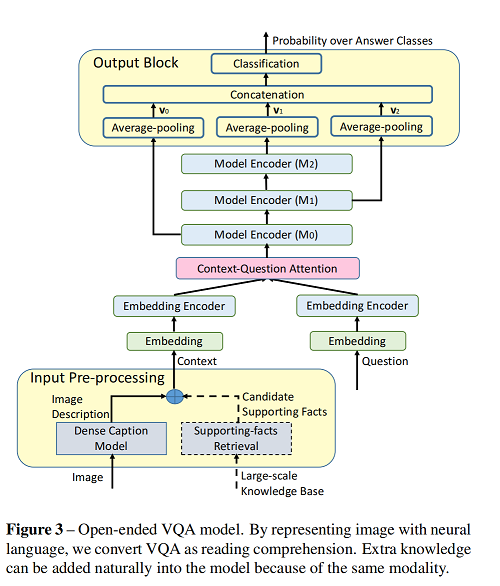
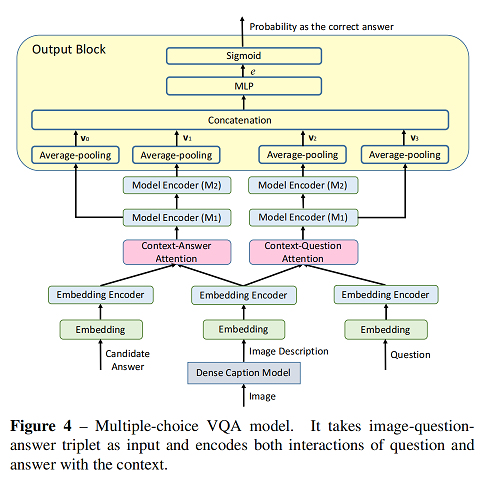
5. visual question answering as reading comprehension 李晖老师文章
main contribution
- 将 vqa 转换为 tqa任务,可以tqa的技术解决问题
- propose two type of vqa model
- it is easy to extend to adress knowledge based vqa
6. From Recognition fo Cognition: Visual Commonsense Reasoning
R2C Model
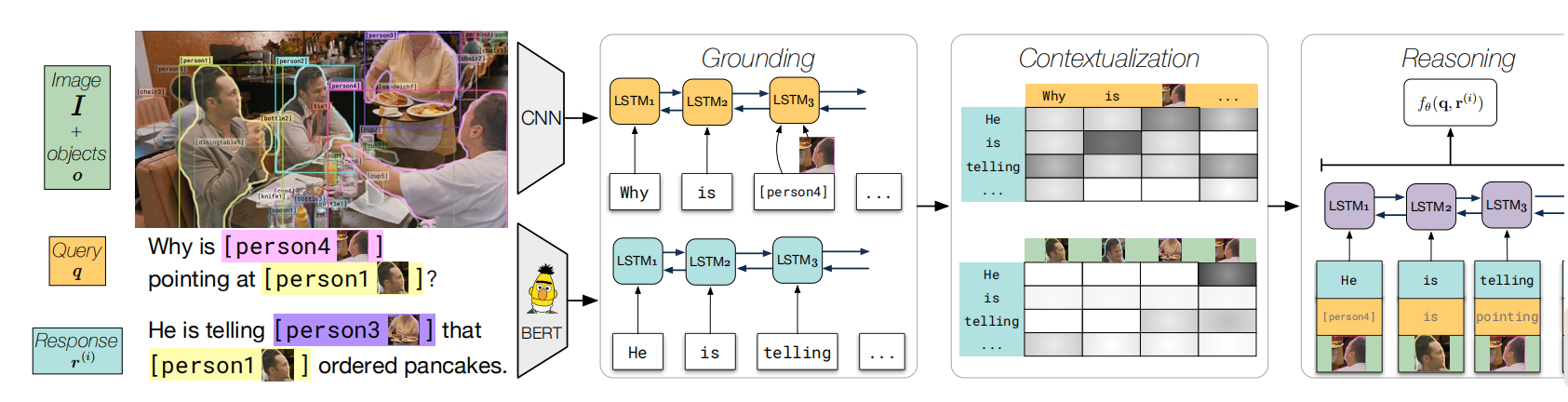
task
- 给定image, objects bbox ,query(question), four responses(answers), rationale,
- task 1:(Q -> A)对于一个query, 从四个候选response 中选择一个
- task 2: (QA -> R)如果选择出正确的response, 从四个候选 retionale中选择一个
可取之处:
- 利用到object bbox
- Grounding 中:把名词对应roi image 的feature 加入 LSTM中,如上图的【person 4】的 object feature
- Contextualization: 让 response 跟所有 object bbox feature 进行attention
不理解的地方:
- BERT 在网络中发挥什么作用?对输入的文本信息进行编码??
- Contextualization输出的是什么信息???
7. FVQA
作者从 coco和imagenet 中挑选了 2190张图片,这些图片主要包含三类 visual concept :
- Object: 图片中的真实实体(例如人、汽车、狗等)。它们是由两个分别在MS-COCO和ImageNet上训练的Fast-RCNN模型得到的。同时还利用了一个image attribute model在没有在图像中定位的情况下标注了92个objects。一共有326个不同的object class。
- Image Scene: 关于图像中的场景信息(例如办公室、卧室、海滩、森林等)。这是通过VGG-16在MIT Place 205-class数据集上训练得到的,同时使用了包含25个scene class的attribute classifier。最终一共包含221个不同的scene class。
- Action: Attribute model提供了24类不同的人或动物的动作,例如走路、跳跃、冲浪、游泳等。
而关于这些visual concept的knowledge则是从DBpedia、ConceptNet、WebChild等已有的外部KB中抽取的:
- DBpedia: 在DBpedia中存储的数据是从Wikipedia中抽取的到的。在这个KB中,concepts根据SKOS Vocabulary被link到它们各自的categories或者super-categories。
- ConceptNet: 这个KB是由几个commonsense关系组成的,例如UsedFor, CreatedBy和IsA。这篇文章中作者使用了11个common relationships来产生问题和答案。
- WebChild: 这个数据库中包含了一些比较级关系,例如Faster、Bigger和Havier。
数据集构造
数据集组成:
- knowledge base
- 提供common sense
- image-question-answer
- multiple-choices or other???
knowledge base中信息 类别
- CV 类
- 获取方式
- 从coco数据集中提取 cv common sense
- 用image captioning 的model生成,输入大量图片, 获取cv commense sense
- 类别:
- 位置常识
- action
- image scene
- 获取方式
- 非 CV类
- 获取方式
- 各种常识性知识从 concept net等 knowledge base中抽取
- 类别:
- object
- action
- scene
- 上述出现的名词从kb中抽取 相关信息
- 获取方式
knowledge base 存储形式:
- 初步想法:
- 三元组形式存储
- 进一步:
- 以图的形式存储(如何存储,如何查询 需要考虑)
转载于:https://www.cnblogs.com/yeran/p/11318135.html
visual-reasoning 笔记相关推荐
- 神经网络也可以有逻辑——解析视觉推理(Visual Reasoning)
本文来源知乎,感谢作者Flood Sung授权转载! 前言 在我们的上一篇文章 最前沿:百家争鸣的Meta Learning/Learning to learn 中,我们谈到了星际2 需要AI具备极好 ...
- 【论文阅读】Interpretable Visual Reasoning via Probabilistic Formulation under Natural Supervision
[论文阅读]Interpretable Visual Reasoning via Probabilistic Formulation under Natural Supervision 目录 [论文阅 ...
- Visual Reasoning(1): CLEVR Dataset
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning Introduction ...
- Visual SLAM笔记
本文转自https://blog.csdn.net/mulinb/article/details/53421864,如有需要请查看原博主. https://blog.csdn.net/MulinB/a ...
- VQA+Visual Reasoning SOTA探索
2014-2019年VQA论文:https://heary.cn/posts/VQA-%E8%BF%91%E4%BA%94%E5%B9%B4%E8%A7%86%E8%A7%89%E9%97%AE%E7 ...
- Visual SLAM 笔记——李群和李代数详解
李群和李代数 问题的引入 当我们估计出相机姿态[R,t][R, t][R,t]了以后,估计的结果和实际的相机姿态肯定会有一些不一致性,因而我们需要对估计出来的结果进行优化.优化方法一般都采用迭代优化的 ...
- Visual Reasoning Strategies for Effect Size Judgments and Decisions
论文传送门 作者 华盛顿大学 Alex Kale Matthew Kay 美国西北大学 Jessica Hullman 摘要 不确定性可视化经常强调点估计,以支持规模估计或通过可视化比较的决策.然而, ...
- Learning Attentions: Residual Attentional Siamese Network for High Performance Online Visual Track笔记
该文是注意力机制应用的巅峰.简单的说本文就是:Siamese+CSR-DCF 该文首先对SRDCF.CSR-DCF等使用了特征加权的非深度学习方法和SimaseFC等的深度学习方法进行了介绍,指出非深 ...
- (VQA)LRTA: A Transparent Neural-Symbolic Reasoning Framework with Modular Supervision for Visual Que
发表于2020年的一篇文章 LRTA神经符号推理框架 视觉问答目前的主要方法依赖于"黑盒"神经编码器()对图像问题进行编码,难以为预测过程提供直观的.人类可读的证明形式, 本文提出 ...
- Learning Visual Commonsense for Robust Scene Graph Generation论文笔记
原论文地址:https://link.springer.com/content/pdf/10.1007/978-3-030-58592-1_38.pdf 目录 总体结构: 感知模型GLAT: 融合感知 ...
最新文章
- [linux][c语言]用socket实现简单的服务器客户端交互
- C语言面试算法题(一)
- 区块链是什么?白话解读入门必须了解的概念
- 声明:此资源由本博客收集整理于网络,只用于交流学习,请勿用作它途。如有侵权,请联系, 删除处理。...
- Android零基础入门第81节:Activity数据传递
- update 千万数据_mysql学习(四)数据库
- distributed crawl
- vue 组件中的钩子函数 不能直接写this
- TreeMap1.8源码
- Excel 如何锁定表头
- JavaSSM接入支付宝当面付(扫码支付)
- web前端网页设计与制作:HTML+CSS旅游网页设计——桂林旅游(3页) web前端旅游风景网页设计与制作 div静态网页设计
- Centos7安装uwsgi出现关于SSL错误的问题
- Java设计登录界面——GUI
- 随手记,python3.7 做的简单爬虫,爬取百度p2p论坛的数据到自己服务器的Oracle数据库
- 基于JAVA社区疫情防控系统设计与实现 毕业设计开题报告
- Java 9、10、11,谁才是Java程序员的本命?
- 深信服2020校招前端一面面经
- ubuntu root初始密码设置
- navicat for mysql 10.1.7注册码
热门文章
- juery mobile select下来菜单选项提交form问题
- 向访客和爬虫显示不同的内容
- Codeforces Round #417:E. FountainsSagheer and Apple Tree(树上博弈)
- java的移植性_详细介绍JAVA的可移植性
- greenplum 数据库如何增加列_Greenplum行存与列存的选择以及转换方法-阿里云开发者社区...
- 计算机一级多选题没有选分,计算机一级多选题
- halcon与QT联合:(5.3)瓶盖检测以及QT界面搭建
- C指针7:指针作为函数返回值
- 1.(基于欧式距离聚类实现的点云分割)
- 和12岁小同志搞创客开发:如何选择合适的传感器?