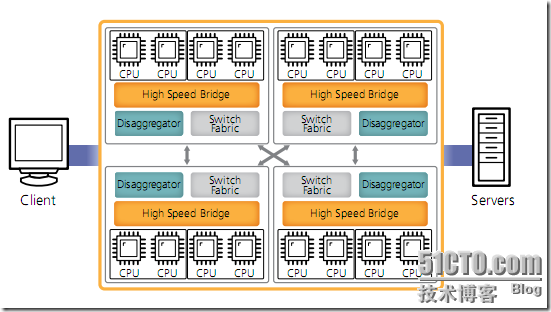
F5 CMP architecture
转载于:https://blog.51cto.com/ipneter/370040
F5 CMP architecture相关推荐
- project web architecture
http://www.alexa.com/topsites 2012中国软件开发者大会(SDCC) http://www.csdn.net/article/a/2012-09-08/2809730 于 ...
- 【论文阅读】ICLR 2022: Scene Transformer: A unified architecture for predicting future trajectories of ...
ICLR 2022: Scene Transformer: A unified architecture for predicting future trajectories of multiple ...
- 激光雷达Lidar Architecture and Lidar Design(下)
激光雷达Lidar Architecture and Lidar Design(下) Considerations on Lidar Design 双基地还是单基地? 双轴还是同轴? 几何重叠 向上还 ...
- 激光雷达Lidar Architecture and Lidar Design(上)
激光雷达Lidar Architecture and Lidar Design(上) 介绍 激光雷达结构: 基本条件 构型和基本布置 激光雷达设计: 基本思想和基本原则 总结 介绍 激光雷达结构是激光 ...
- NVIDIA Turing Architecture架构设计(下)
NVIDIA Turing Architecture架构设计(下) GDDR6 内存子系统 随着显示分辨率不断提高,着色器功能和渲染技术变得更加复杂,内存带宽和大小在 GPU 性能中扮演着更大的角色. ...
- NVIDIA Turing Architecture架构设计(上)
NVIDIA Turing Architecture架构设计(上) 在游戏市场持续增长和对更好的 3D 图形的永不满足的需求的推动下, NVIDIA ®已经将 GPU 发展成为许多计算密集型应用的世界 ...
- ffmpeg architecture(下)
ffmpeg architecture(下) 第3章-转码 TLDR:给我看代码和执行. $ make run_transcoding 我们将跳过一些细节,但是请放心:源代码可在github上找到. ...
- ffmpeg architecture(中)
ffmpeg architecture(中) 艰苦学习FFmpeg libav 您是否不奇怪有时会发出声音和视觉? 由于FFmpeg作为命令行工具非常有用,可以对媒体文件执行基本任务,因此如何在程序中 ...
- ffmpeg architecture(上)
ffmpeg architecture(上) · 视频-您看到的是什么! · 如果您有一系列图像序列,并以给定的频率(例如每秒24张图像)进行更改,则会产生运动的错觉.总之,这是视频背后的基本概念:一 ...
最新文章
- 老李推荐:第5章5节《MonkeyRunner源码剖析》Monkey原理分析-启动运行: 获取系统服务引用 1...
- 【中继协助频谱切换】基于中继协助的频谱切换机制的MATLAB仿真
- Visual Studio 2013开发 mini-filter driver step by step 内核中使用线程(7)
- android11开启无线调试
- 数据分析与挖掘-python常用数据预处理函数
- sublime用cmd窗口调试python_如何使用xdebug和sublime调试python脚本
- seata分布式事务原理_又见分布式事务之Seata
- 软工作业4:词频统计
- jQuery常用工具方法
- python必备基础代码-python基础知识和练习代码
- 一起学JAVA 接口 面向接口开发
- 502 Bad Gateway错误
- uni-app 小程序后端返回二进制流图片显示
- 理想主义者与现实主义者的差别
- Windows7使用inter7代cpu更新补丁问题
- es高级客户端聚合查询api快速入门
- 苹果怎么设置下载软件不要密码?手机技巧分享
- Dubbo 的集群容错模式:Failover Cluster
- 在Windows上抓取Android手机的网络流量(另类用法-使用CainAbel + WireShark)
- 八道二叉树基础程序面试题