UNICODE编码细节与个人使用总结
最近做了一个需要支持Unicode的项目,现在把编程中一些心得总结一下。
1、TCHAR ,UNICODE,CHAR,wchar_t 之间的关系
经常发现有的人爱用strcpy等标准ANSI函数,有的人爱用_tXXXX函数,这个问题曾经搞的很混乱。为了统一,有必要搞清楚它们之间的关系。
为了搞清这些函数,就必须理请几种字符类型的写法。char就不用说了,先说一些wchar_t。wchar_t是Unicode字符的数据类型,它实际定义在<string.h>里:
typedef unsigned short wchar_t;
不能使用类似strcpy这样的ANSI C字符串函数来处理wchar_t字符串,必须使用wcs前缀的函数,例如wcscpy。为了让编译器识别Unicode字符串,必须以在前面加一个“L”,例如:
wchar_t *szTest=L"This is a Unicode string.";
下面在看看TCHAR。如果你希望同时为ANSI和Unicode编译的源代码,那就要include TChar.h。TCHAR是定义在其中的一个宏,它视你是否定义了_UNICODE宏而定义成char或者wchar_t。如果你使用了TCHAR,那么就不应该使用ANSI的strXXX函数或者Unicode的wcsXXX函数了,而必须使用TChar.h中定义的_tcsXXX函数。另外,为了解决刚才提到带“L”的问题,TChar.h中定义了一个宏:“_TEXT”。
以strcpy函数为例子,总结一下:
.如果你想使用ANSI字符串,那么请使用这一套写法:
char szString[100];
strcpy(szString,"test");
.如果你想使用Unicode字符串,那么请使用这一套:
wchar_t szString[100];
wcscpyszString,L"test");
.如果你想通过定义_UNICODE宏,而编译ANSI或者Unicode字符串代码:
TCHAR szString[100];
_tcscpy(szString,_TEXT("test"));
2、增加Unicode宏定义 UNICODE,_UNICODE
3、如何在调式程序中显示Unicode字符,需要在VC开发工具“Tools”—>“Options”à“Debug”页中勾选“Display Unicode strings”选项。如图
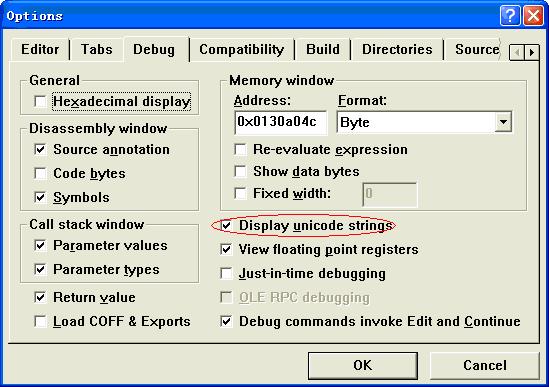
4、使用Unicode的问题 wWinMainCRTStartup设定程序入口
project-> settings->Link在category:选择output在Entry point symbol:加上wWinMainCRTStartup
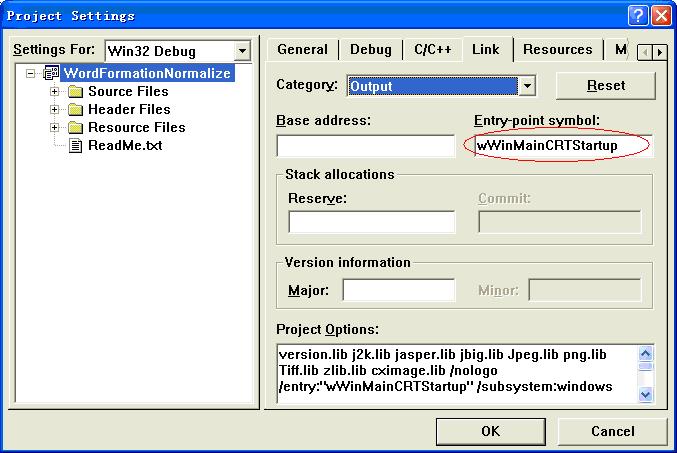
5、几种编码之间的转换
//UTF8格式转换成GB格式
CString ConvertUTF8ToGBK(CString strUtf8)
{
int len=MultiByteToWideChar(CP_UTF8, 0, (LPCSTR)strUtf8.GetBuffer(0), -1, NULL,0);
unsigned short * wszGBK = new unsigned short[len+1];
memset(wszGBK, 0, len * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, (LPCSTR)strUtf8.GetBuffer(0), -1, wszGBK, len);
len = WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, NULL, 0, NULL, NULL);
char *szGBK=new char[len + 1];
memset(szGBK, 0, len + 1);
WideCharToMultiByte (CP_ACP, 0, wszGBK, -1, szGBK, len, NULL,NULL);
CString strGBK;
strGBK = szGBK;
delete[] szGBK;
delete[] wszGBK;
return strGBK;
}
//GB格式转换成UTF8格式
CString ConvertGBKToUTF8(CString strGBK)
{
int len=MultiByteToWideChar(CP_ACP, 0, (LPCSTR)strGBK.GetBuffer(0), -1, NULL,0);
unsigned short * wszUtf8 = new unsigned short[len+1];
memset(wszUtf8, 0, len * 2 + 2);
MultiByteToWideChar(CP_ACP, 0, (LPCSTR)strGBK.GetBuffer(0), -1, wszUtf8, len);
len = WideCharToMultiByte(CP_UTF8, 0, wszUtf8, -1, NULL, 0, NULL, NULL);
char *szUtf8=new char[len + 1];
memset(szUtf8, 0, len + 1);
WideCharToMultiByte (CP_UTF8, 0, wszUtf8, -1, szUtf8, len, NULL,NULL);
CString sUTF_8;
sUTF_8=szUtf8;
delete[] szUtf8;
delete[] wszUtf8;
return sUTF_8;
}
//字符串转换float
float strtofloat(CString str)
{
char a[MAX_PATH];
memset(a, 0, MAX_PATH);
WideCharToMultiByte(CP_ACP, 0,(LPCWSTR)str, -1, a, MAX_PATH, NULL, NULL);
float f = (float)atof(a);
return f;
}
//UTF8转换成UNICDOE
wchar_t* U8ToUnicode(const char* szU8)
{
int wcsLen = ::MultiByteToWideChar(CP_UTF8, NULL, szU8, strlen(szU8), NULL, 0);
wchar_t* wszString = new wchar_t[wcsLen + 1];
::MultiByteToWideChar(CP_UTF8, NULL, szU8, strlen(szU8), wszString, wcsLen);
wszString[wcsLen] = '/0';
return wszString;
}
//UNICODE转换成UTF8
char* UnicodeToU8(wchar_t* wszString)
{
int u8Len = ::WideCharToMultiByte(CP_UTF8, NULL, wszString, wcslen(wszString), NULL, 0, NULL, NULL);
char* szU8 = new char[u8Len + 1];
::WideCharToMultiByte(CP_UTF8, NULL, wszString, wcslen(wszString), szU8, u8Len, NULL, NULL);
szU8[u8Len] = '/0';
return szU8;
}
//UNICODE转换成ANSI
char* UnicodeToAnsi(wchar_t* wszString)
{
int ansiLen = ::WideCharToMultiByte(CP_ACP, NULL, wszString, wcslen(wszString), NULL, 0, NULL, NULL);
char* szAnsi = new char[ansiLen + 1];
::WideCharToMultiByte(CP_ACP, NULL, wszString, wcslen(wszString), szAnsi, ansiLen, NULL, NULL);
szAnsi[ansiLen] = '/0';
return szAnsi;
}
转载于:https://www.cnblogs.com/qitian1/archive/2009/07/01/6462096.html
UNICODE编码细节与个人使用总结相关推荐
- 程序员趣味读物:谈谈Unicode编码
2019独角兽企业重金招聘Python工程师标准>>> 这是一篇程序员写给程序员的趣味读物.所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级.整 ...
- [转]程序员趣味读物:谈谈Unicode编码
from : http://pcedu.pconline.com.cn/empolder/gj/other/0505/616631_all.html#content_page_1 这是一篇程序员写给程 ...
- 谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
这是一篇程序员写给程序员的趣味读物.所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级.整理这篇文章的动机是两个问题: 问题一: 使用Windows记事本的&quo ...
- 【转】谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
这是一篇程序员写给程序员的趣味读物.所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级.整理这篇文章的动机是两个问题: 问题一: 使用Windows记事本的&quo ...
- 转:谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
一篇程序员写给程序员的趣味读物.所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级.整理这篇文章的动机是两个问题: 问题一: 使用Windows记事本的" ...
- gb2312编码表_程序员趣味读物:谈谈Unicode编码
点击上方"智能与算法之路",选择"星标"公众号 资源干货,第一时间送达 这是一篇程序员写给程序员的趣味读物.所谓趣味是指可以比较轻松地了解一些原来不清楚的概念, ...
- Unicode编码规范(摘抄)
http://www.aoxiang.org 2006-4-2 10:48:02 Unicode是一种字符编码规范 . 先从ASCII说起.ASCII是用来表示英文字符的一种编码规范,每个ASCII字 ...
- 关于unicode编码
最初的unicode编码是固定长度的,16位,也就是2两个字节代表一个字符,这样一共可以表示65536个字符.显然,这样要表示各种语言中所有的字符是远远不够的.Unicode4.0规范考虑到了这种情况 ...
- Unicode编码完全探究(二)
一.文章来由 上一篇文章我们已经探究了基本的Unicode编码,这一篇继续来探究Unicode编码~~~ 二.字符简史 很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示 ...
最新文章
- 697. Degree of an Array 频率最高元素的最小覆盖子数组
- 文件签名魔塔50层android反编译破解
- git的使用学习(三)时光机穿梭
- java读取pi_(树莓派csi相机)使用Java从raspivid-stdout读取h...
- 扫描器scanner的源代码
- CentOS 桌面启动无登录界面
- Response.Redirect ,Server.Excute和Server.Transfer区别详解
- 【Python学习】 - sklearn学习 - 交叉验证中的常用函数
- oracle批量联机,Oracle 12.2 使用联机重定义对表进行多处改变
- 做到阿里P7和考上985/211哪个更难?
- vsphere6.0故障:关于vCenter Appliance6.0磁盘爆满和WEB503错误问题
- 发表email所需要
- Linux Performance Observability Tools
- 让你口水不停的最新台湾美食推荐
- 入口函数ufusr()与ufsta()的区别
- OSI七层模型与TCP/IP五层模型
- 微信小程序可视化开发工具之动态数据
- 11岁的Tumblr:开启艰难禁黄之路
- 华为MA5626 ONU配置成交换机及开启POE指令教程
- magento 货币换算
热门文章
- c+和python的区别-python和c先学哪个
- python序列类型-Python序列类型
- python学费多少-python培训学费一般多少?
- python主要运用于-Python八大主要应用领域,你都知道吗?
- python培训班一般多少钱-报一个python培训班多少钱?
- python快速编程入门教程-python从入门到精通之30天快速学python视频教程
- python中文件读写位置的作用-Python中文件的读写
- python3语法错误-使用Python 3打印时出现语法错误
- python中常见的流程结构-【Python2】04、Python程序控制结构
- 想学python有什么用-学python日常工作有什么用?